1.本发明属于以太坊键值存储技术领域,尤其涉及一种数据语义分离存储方法及系统。
背景技术:
2.本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
3.作为区块链2.0的代表作之一,以太坊通过支持智能合约拓宽了应用场景,使得任何区块链平台之上的编程成为可能。为更好的服务于不同的应用场景,以太坊内部维护一个全局状态mpt(merkle patricia trie)来管理账户数据,随着交易不断被打包进区块,全局状态被交易不断更新。然而,随着越来越多的应用建立在以太坊上,智能合约复杂的逻辑、日益庞大的数据量使得以太坊的拓展变得日益艰难。
4.以太坊分布式应用(decentralization application,dapp)的拓展需要具备两个基本条件:1)交易打包上链低延迟;2)交易执行高效率。随着以太坊陆续推出的pos(proof of stake)共识协议和分片策略,交易上链的吞吐量问题得到了基本的解决。然而,海量的数据使得交易入库速度得不到保证。同时,受数据库规模过大的影响,低效的数据请求速度也会限制dapp的进一步拓展。
5.为满足以太坊海量的大数据存储和读取需求,以太坊底层使用基于基于日志结构树(log structure merge,lsm)的键值数据库(key-value store,kv store)来处理其写密集型的负载。kv store在内存中维护了一个庞大的缓冲池,通过将大量的随机写转化成顺序写的方式保证数据的写入性能。同时,kv store底层存储被设计为多层,被写入的键值对按照其键的字典序在每一层上全局排序,从而保证较低的查询开销。
6.然而,kv store对海量数据的抵抗性是较弱的,随着海量数据的不断写入,kv store的读写呈现出一种逐渐下滑的趋势。其根本原因在于:(1)随着后续后台合并(compaction)进程对海量数据的排序、重写,它占用了过多的cpu资源和磁盘带宽,这一现象随着数据规模的增大变得更加严重;(2)更倾向于写密集型负载的kv store对于大量的点查询操作表现不佳,由于每一次查询需要按层遍历所有的数据块,因此查询一笔数据变得十分昂贵。针对此类问题,传统的关系型数据库通过分表、分区、分库实现数据的精细化管理。对于以太坊而言,无冗余的对以太坊数据分布式存储势必会降低整个系统的安全性,将数据分散存储是一个代价高昂的办法。
技术实现要素:
7.为了解决上述背景技术中存在的技术问题,本发明提供一种数据语义分离存储方法及系统,将以太坊数据分为弱相关的两类数据,实现了不同类型数据的独立管理和存储,节省了一部分读写放大开销,可以加速数据的入库和检索过程。
8.为了实现上述目的,本发明采用如下技术方案:
9.本发明的第一个方面提供一种数据语义分离存储方法,其包括:
10.获取以太坊数据;
11.根据以太坊数据的类型,将以太坊数据插入内存组件中的相应类型的跳表结构中;
12.其中,跳表结构内存储的以太坊数据达到容量上限时,跳表结构会被冻结,被冻结的跳表结构根据存储的以太坊数据的类型,转换为文件后写入到磁盘组件中相应类型的文件区。
13.进一步地,若跳表结构被冻结,则从内存组件中重新划分一块区域作为新的跳表结构以支持以太坊数据的插入。
14.进一步地,被冻结的跳表结构写入到文件区之前,记录被冻结的跳表结构的最小键和最大键并作为索引驻留内存组件。
15.进一步地,所述以太坊数据的类型包括状态数据和非状态数据;
16.所述状态数据完全由账户数据构成;
17.所述非状态数据包含交易区块以及所有的元数据。
18.进一步地,在请求一笔以太坊数据时,根据待查询以太坊数据的类型,在内存组件中的相应类型的跳表结构中检索,或在磁盘组件中相应类型的文件区中检索。
19.进一步地,若在磁盘组件中相应类型的文件区中检索,具体方法为:基于内存组件中的索引,通过二分查找的方法检索磁盘组件中的文件,以查询请求的以太坊数据。
20.本发明的第二个方面提供一种数据语义分离存储系统,其包括:
21.数据获取模块,其被配置为:获取以太坊数据;
22.数据存储模块,其被配置为:根据以太坊数据的类型,将以太坊数据插入内存组件中的相应类型的跳表结构中;
23.其中,跳表结构内存储的以太坊数据达到容量上限时,跳表结构会被冻结,被冻结的跳表结构根据存储的以太坊数据的类型,转换为文件后写入到磁盘组件中相应类型的文件区。
24.进一步地,被冻结的跳表结构写入到文件区之前,记录被冻结的跳表结构的最小键和最大键并作为索引驻留内存组件。
25.本发明的第三个方面提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的一种数据语义分离存储方法中的步骤。
26.本发明的第四个方面提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的一种数据语义分离存储方法中的步骤。
27.与现有技术相比,本发明的有益效果是:
28.本发明提供了一种数据语义分离存储方法,其从数据和存储的角度分析了以太坊的上层数据类型和底层存储特性,重新定义并将以太坊数据分为弱相关的两类数据,通过分离存储不同类型的数据打通以太坊数据层和存储层的语义桥梁,实现了不同类型数据的独立管理和存储,节省了一部分读写放大开销,可以加速数据的入库和检索过程,进而促进dapp交易的上链和执行,实现以太坊系统的整体优化。
tree实现数据的独立管理。
40.本发明设计了两个数据入库接口,分别为put_s()和put_ns(),前者负责状态数据的写入,而后者负责非状态数据的写入。
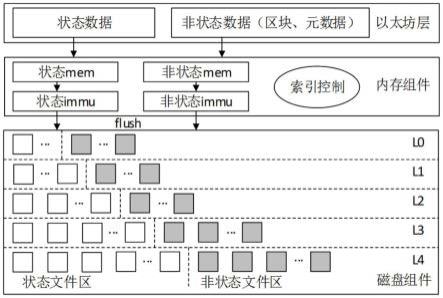
41.当写入一笔状态数据时,状态数据首先通过put_s()被写入到状态mem中,状态mem是一个跳表的结构,写入的键值对会按照其字典序排序。即,每一笔状态数据是一个包含键与值(key,value)的二元组,当一笔新的状态数据到来时,首先会被插入到状态跳表结构——状态mem中,状态mem支持单笔插入和批量插入。当状态mem达到其容量上限时,此状态mem会被冻结变成不可写的状态immu(被冻结的状态跳表结构)并准备序列化。同时,会从内存池中重新划分一块区域用于新的状态mem以支持新的数据插入。当状态immu出现时,运行在后台的flush进程会记录状态immu中的最小键(min key)和最大键(max key)并作为索引驻留内存,然后,将此状态immu转换成sst文件写入到磁盘组件中的状态文件区中。由于状态数据被状态文件区单独管理,因此,当磁盘组件中触发compaction线程时,仅仅只有在同一个文件区的数据会被合并。
42.写入非状态数据的过程与状态数据一致。非状态数据首先通过put_ns()被写入到非状态mem中,非状态mem是一个跳表的结构,写入的键值对会按照其字典序排序。即,每一笔非状态数据是一个包含键与值(key,value)的二元组,当一笔新的非状态数据到来时,首先会被插入到非状态跳表结构——非状态mem中,非状态mem支持单笔插入和批量插入。当非状态mem达到其容量上限时,此非状态mem会被冻结变成不可写的非状态immu(被冻结的非状态跳表结构)并准备序列化。同时,会从内存池中重新划分一块区域用于新的非状态mem以支持新的数据插入。当非状态immu出现时,运行在后台的flush进程会记录非状态immu中的min key和max key并作为索引驻留内存,然后,将此非状态immu转换成sst文件写入到磁盘组件中的非状态文件区中。由于非状态数据被非状态文件区单独管理,因此,当磁盘组件中触发compaction线程时,仅仅只有在同一个文件区的数据会被合并。
43.磁盘组件总体上被划分为两个独立管理的区域,分别是状态文件区和非状态文件区,这两个区是互相透明的。因此,对于某一个区发生的compaction过程,参与compaction的数据文件被限制为同一类型。因此,整个系统逻辑上被分为两个独立管理的子系统,每一个子系统只管理同一类型的数据。借助于这一点,更小的数据范围、更小的数据量实现了数据写入过程中更小的写放大,增快了以太坊系统的整体写入吞吐量。
44.经过状态分离,原来的一个大的系统被划分为两个小的子系统,且两个子系统彼此透明。因此,在任一子系统发生的读操作也是互相透明的。在请求一笔以太坊数据,根据待查询以太坊数据的类型,在内存组件中的相应类型的跳表结构中检索,或在磁盘组件中相应类型的文件区中检索。若在磁盘组件中相应类型的文件区中检索,具体方法为:基于内存组件中的索引,通过二分查找的方法检索磁盘组件中的文件,以查询请求的以太坊数据。
45.数据的请求过程和写入是类似地,本发明实现了两个请求接口,get_s()和get_ns(),用来实现不同类型的以太坊数据的独立检索。
46.当请求一笔账户数据(状态数据)时,首先根据待查询状态数据的key检索位于内存组件的状态mem和状态immu是否存在待查询状态数据的值;如果并未检索到待查询状态数据,则在磁盘组件中的状态文件区进行检索,具体的,由索引(index)控制访问状态文件区并逐层遍历。磁盘组件上的状态文件分区由多个层级组成,单笔数据的查询必须从上往
下逐层查询。驻留在内存的索引控制维护了两个文件分区所有sst文件的元数据(包括min key、max key、filenumber、level等信息),此索引将通过二分查找的方法检索磁盘上对应的sst查询所请求的值。
47.非状态数据的请求与状态数据一致。当请求一笔非状态数据时,首先根据待查询状态数据的key检索位于内存组件的非状态mem和非状态immu是否存在待查询非状态数据的值;如果并未检索到待查询非状态数据,则在磁盘组件中的非状态文件区进行检索,具体的,由index控制访问非状态文件区并逐层遍历,磁盘组件上的非状态文件分区由多个层级组成,单笔数据的查询必须从上往下逐层查询。
48.经状态分离之后,单一数据类型的查询仅仅需要检索一部分的sst文件,而不是遍历全部的文件,即本发明提出的状态分离策略保证一笔交易或者账户的读取仅仅涉及一小部分数据量,这大大降低了在查询过程中的读取放大,提升了整体吞吐量。
49.本发明将以太坊中的数据重新划分两个弱相关的区域并实现独立管理和存储,与当前的以太坊存储方法相比,节省了一部分读写放大开销,可以加速数据的入库和检索过程,进而促进dapp交易的上链和执行,实现以太坊系统的整体优化。
50.实施例二
51.本实施例提供了一种数据语义分离存储系统,其具体包括如下模块:
52.数据获取模块,其被配置为:获取以太坊数据;
53.数据存储模块,其被配置为:根据以太坊数据的类型,将以太坊数据插入内存组件中的相应类型的跳表结构中;
54.其中,跳表结构内存储的以太坊数据达到容量上限时,跳表结构会被冻结,被冻结的跳表结构根据存储的以太坊数据的类型,转换为文件后写入到磁盘组件中相应类型的文件区。被冻结的跳表结构写入到文件区之前,记录被冻结的跳表结构的最小键和最大键并作为索引驻留内存组件。
55.此处需要说明的是,本实施例中的各个模块与实施例一中的各个步骤一一对应,其具体实施过程相同,此处不再累述。
56.实施例三
57.本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的一种数据语义分离存储方法中的步骤。
58.实施例四
59.本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的一种数据语义分离存储方法中的步骤。
60.本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
61.本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序
指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
62.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
63.这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
64.本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random accessmemory,ram)等。
65.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
