1.本发明涉及图像识别技术领域,具体涉及一种明厨亮灶场景下工作人员着装规范检测方法及装置。
背景技术:
2.明厨亮灶,是指餐饮服务提供者采用透明玻璃、视频等方式,向社会公众展示餐饮服务相关过程的一种形式,通过摄像头、电子显示屏等设备,将餐饮服务的关键部位与环节置于社会监督之下。
3.在厨房里,工作人员的着装规范程度会直接影响到食品安全。然而,面对数量庞大的餐饮点,24小时人工监督显得难以为继。因此,需要一种智能检测方法,在无人情况下对不达标行为进行监督和告警。
4.目前,已有一些基于机器学习的着装规范检测方法,相比这些案例,本任务由于在明厨亮灶场景中,因此具有其特殊性,主要表现为以下几点因素:1.边缘端部署,同时处理多路摄像头,对告警鲁棒性和准确性要求较高。
5.2.摄像头拍摄角度、高度不确定,室内场景差异化大,数据分布复杂。
6.3.工作人员在图像中的姿态与位置多变、较密集,遮挡较严重,标注较困难。
7.4.工作服颜色、款式差异较大,纹理、颜色等简单特征无法表征着装是否符合规范。
8.一般地,基于机器学习的算法能力很大程度上依赖训练数据的质量和数量,考虑到上述因素,大型明厨亮灶场景下的数据集构建具有较大困难,这又进一步限制了一般方法的精确性和鲁棒性。
9.综上所述,面对明厨亮灶场景,如何提高告警信息的准确性和鲁棒性是亟待解决的技术问题。
技术实现要素:
10.针对现有技术中的缺陷,本发明的目的是提供一种明厨亮灶场景下工作人员着装规范检测方法及装置,以提高在明厨亮灶场景下,告警信息的准确性和鲁棒性。
11.根据本发明的第一个方面,提供一种明厨亮灶场景下工作人员着装规范检测方法,包括训练阶段,所述训练阶段包括以下步骤:s1、通过摄像头获取输入图像;s2、对所述输入图像中的目标行人框进行识别,获取所述目标行人框的行人位置信息、行人姿态信息和行人服饰信息,所述行人位置信息包括位置点数据、遮挡情况和密集情况,所述行人姿态信息包括体位情况、头部可见情况和人体与摄像头之间的朝向情况,所述行人服饰信息包括帽子穿戴情况和围裙穿戴情况;s3、对获取到的所述目标行人框的行人位置信息、行人姿态信息和行人服饰信息进行标注,形成数据集,上述信息全部规范者标定为着装规范,上述信息有任一不规范者标
定为着装不规范、并发出警示信息,上述信息有任一不确定者标定为无法判断。
12.进一步地,所述遮挡情况包括被没有遮挡和遮挡,所述密集情况包括不密集和密集,所述体位情况包括坐姿、站立和其他,所述头部可见情况包括可以观察到头部、不可以观察到头部和其他,所述人体与摄像头之间的朝向情况包括正面朝向摄像头、背面朝向摄像头和其他,所述帽子穿戴情况包括戴了帽子、没有戴帽子和其他,所述围裙穿戴情况包括穿戴了围裙、没有穿戴围裙和其他。
13.进一步地,所述训练阶段还包括以下步骤:s4、根据s2步骤获取到的数据集以及神经网络训练模型参数训练行人位置模型、行人姿态模型和行人服饰模型,通过上述模型拟合行人,表征出行人的位置特征编码、姿态特征编码和服饰特征编码;s5、对s4步骤表征出的结果进一步编码,得到特定的特征维度;s6、将s5步骤得到的特征维度输入分类器,得到预测的最终告警结果。
14.进一步地,所述训练阶段还包括以下步骤:s7、将模型参数记录于测试设备上,并设定阈值,通过测试数据验证算法给出的告警效果。
15.进一步地,还包括测试阶段,所述测试阶段包括以下步骤:s9、通过摄像头获取场景输入图像;s10、初始化网络结构,初始化测试程序运行环境,初始化训练存储的权重参数;s11、将场景输入图像输入行人位置模型、得到行人位置特征编码,将行人位置特征编码和场景输入图像输入行人姿态模型和行人服饰模型,得到行人姿态特征编码和行人服饰特征编码,采用s5步骤进一步编码,得到特定的特征维度;s12、将s11步骤得到的特征维度输入分类器,获取告警信息。
16.进一步地,采用目标检测算法网络yolox检测行人位置信息,采用分类网络结构swin transformer检测行人姿态信息和行人服饰信息,所述分类器为三分类的svm分类器。
17.进一步地,利用爬虫技术抓取所述摄像头的视频流,对视频抽帧,从而获取到输入图像;或直接获取摄像头拍摄的图像,从而获取到输入图像。
18.根据本发明的第二个方面,提供一种检测装置,包括:标注模块,所述标注模块包括第一单元和第二单元,所述第一单元用于爬取数据、获取真实场景的图像信息,所述第二单元用于将获取到的图像信息标注为对应的格式数据;存储模块,所述存储模块用于存储已标注的数据样本,并将所述数据样本划分为训练数据和测试数据;获取模块,所述获取模块用于利用上述方法对输入图像进行编码,将图像中的行人位置信息、行人姿态信息和行人服饰信息转换为特征向量;以及确认模块,所述确认模块用于最终判断是否给出告警信息。
19.进一步地,还包括构建模块,所述构建模块用于基于数据训练的权重构建算法模型网络。
20.有益效果:本发明提供的一种明厨亮灶场景下工作人员着装规范检测方法,通过将着装规范的复杂问题分解,将行人编码为特定的多维特征,避免了单一模型预测对训练
用样本和算法模型复杂度的要求,提高了输出告警的准确性和鲁棒性。
附图说明
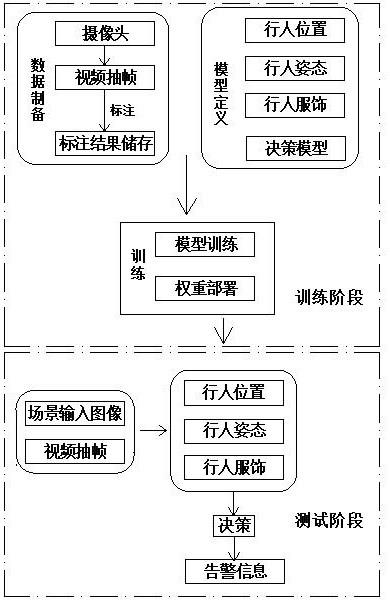
21.图1为svm分类器工作流程框图;图2为本发明的方法流程框图;图3为模型推断流程框图;图4为本发明的装置结构框图。
具体实施方式
22.为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
23.如图1-图4所示,本发明提供一种明厨亮灶场景下工作人员着装规范检测方法,包括训练阶段和测试阶段。
24.训练阶段的具体步骤如下:步骤一、利用爬虫技术抓取所述摄像头的视频流,对视频抽帧,从而获取到输入图像;或直接获取摄像头拍摄的图像,从而获取到输入图像。
25.步骤二、对输入图像中的目标行人框进行识别,获取目标行人框的行人位置信息、行人姿态信息和行人服饰信息,行人位置信息包括坐标数据、宽度数据、高度数据、遮挡情况和密集情况,行人姿态信息包括体位情况、头部可见情况和人体与摄像头之间的朝向情况,行人服饰信息包括帽子穿戴情况和围裙穿戴情况。
26.对获取到的所述目标行人框的行人位置信息、行人姿态信息和行人服饰信息进行标注,形成数据集,上述信息全部规范者标定为着装规范,上述信息有任一不规范者标定为着装不规范、并发出警示信息,上述信息有任一不确定者标定为无法判断。
27.标注格式大致如下表所示。
28.其中,每一行对应输入图像中的一个行人标注结果,其标注可以等价为一个向量:
ꢀꢀ
。
29.参数说明:
ꢀꢀ
表示行人标注结果,x表示左上角所在列,y表示左上角行,w表示行人标注的列宽,h表示行人标注的行高,f0表示遮挡情况,f1表示密集情况,f2表示姿体位情况,f3表示头部可见情况,f4表示朝向情况,f5表示帽子穿戴情况,f6表示围裙穿戴情况,f7表示着装。
30.行人位置信息的标注为:[0]:[5]。
[0031]
具体地,遮挡情况(f0):是否有环境遮挡,0(没有遮挡), 1(遮挡)。
[0032]
具体地,密集情况(f1):是否密集,0(不密集), 1(密集)。
[0033]
行人姿态信息的标注特征维度为:[6]:[8]。
[0034]
具体地,姿态(f2):行人处于坐或站,0(坐姿), 1(站立),2(其他)。
[0035]
具体地,头部(f3):是否包含头部信息,0(可以观察到头部),1(不可以观察到头部),2(其他)。
[0036]
具体地,朝向(f4):人员面对摄像机的正反,0(正面朝向摄像头),1(背面朝向摄像头),2(其他)。
[0037]
行人服饰信息的标记为:[9]:[10]。
[0038]
具体地,帽子(f5):是否佩戴了帽子,0(戴了帽子), 1(没有),2(其他)。
[0039]
具体地,围裙(f6):是否穿戴围裙,0(穿戴围裙),1(没有穿戴),2(其他)。
[0040]
着装规范的标记为[11]。
[0041]
具体地,着装(f7):0(着装规范),1(着装不规范),2(无法判断)。
[0042]
其中,只有标记为1的样本需要给出告警。
[0043]
步骤三、标注数据,存储标注结果,建立现实场景下的数据集。首先标注工作人员位置的位置信息,对位置信息中处于密集、遮挡的行人,直接标定为无法判断,不进行后续标注。随后标记行人的姿态信息,同理地,对于不可以观察到头部、其他等情况,依然标定为无法判断,不进行后续的标注。最后根据行人的服饰信息,标定符合规范和不符合规范的标记结果。
[0044]
步骤四、定义算法模型结构,特别的,针对行人位置的检测,采用业界通用的目标检测算法网络yolox,针对行人姿态与行人服饰的检测采用业界通用的分类网络结构swin transformer,针对着装规范的最终判断,采用支持向量机或随机森林等(svm),共计4个模型。
[0045]
步骤五、利用训练集数据以及神经网络训练模型参数,训练以下3个模型:model_pede(行人位置模型)、model_pose(行人姿态模型)、model_dress(行人服饰模型),以一幅输入图像(image)为例,通过模型拟合行人,表征出行人的位置特征编码、姿态特征编码和服饰特征编码。
[0046]
行人在输入图像中的位置特征编码: ,p_cls, p_c0, p_c1, p_c2];参数说明:p_cls表示行人概率,p_c0表示正常,p_c1表示遮挡行人,p_c2表示密集行人,[xi,yi,wi,hi]表示行人位置。
[0047]
然后,同样地,对行人姿态模型和行人服饰模型进行训练,只采用标记为可用的行人进行训练,行人在输入图像中的姿态特征编码:score_pose = model_pose(box,image),行人在输入图像中的服饰特征编码:score_dress = model_dress(box,image),参数说明;score_pose,score_dress是模型输出的向量,分别表征图像中某行人的姿态特征编码和服饰特征编码, 具体地,score_pose[0:2] 表示行人体位情况;score_pose[3:5] 表示头部可见情况;
score_pose[6:8] 表示人体与摄像头之间的朝向情况;score_dress[0:2] 表示行人服饰的帽子佩戴情况;score_dress[3:5] 表示行人服饰围裙佩戴情况。
[0048]
步骤六、对标注结果进行进一步编码,得到特定的特征维度。
[0049]
其编码规则如下,其中针对行人位置信息的编码特征为:参数说明:表示位置信息特征编码,w表示行人标注的列宽;h表示行人标注的行高。
[0050]
分别计算行人检测结果区域3通道(b,g,r)上的直方图:选定为16维的直方图,每一维的灰度级间隔为256/16 = 16,然后统计整个区域的灰度,得到16维的特征;归一化:将得到的16维特征都除以整个区域的像素点的总数根据类别概率,采用one-hot编码机制,即只有一个维度为1,其余位置为0,形成3维向量:feature_loc_bbx[49-51] = [0,1,0]针对行人姿态信息的特征编码规则采用one-hot编码机制,共计9维,如下feature_pose_bbx[52-60] = [0,1,0....]针对行人服饰信息的特征编码规则,共计6维特征,如下:feature_property_bbx[61-66] = [0,1,0,...]因此,编码的特征维度为1 48 3 9 6=67维。
[0051]
步骤七、利用步骤六提取的特定的特征维度,以及标注的行人姿态特征编码和行人服饰特征编码进行级联,根据标注的标签(0/1/2),训练一个3分类的svm分类器,采用one-vs-one的方式,针对3类标签,需要训练3*2/2个分类器,分别对应(svm1/0 vs 1)、(svm2/0 vs 2)、(svm3/1 vs 2);该分类器输入的特征维度是经过编码器处理后之后的特征,共计有67维,输出为预测的最终告警结果。
[0052]
步骤八、将模型参数记录于测试设备上,并设定和阈值,通过测试数据验证算法给出的告警效果。
[0053]
测试阶段的具体步骤如下:步骤一、获取摄像头视频流,对视频抽帧,获取待测的场景输入图像。
[0054]
步骤二、初始化网络结构,初始化测试程序运行环境,初始化训练存储的权重参数。
[0055]
步骤三、将图像输入model_pede,获取行人位置特征编码,将行人位置特征编码和场景输入图像输入model_pose以及model_dress获取行人的姿态特征编码和服饰特征编码,采用训练步骤六中的方式计算编码,采用one-hot编码机制:hot编码机制:hot编码机制:
参数说明: 表示行人位置模型,表示行人姿态模型,表示行人服饰模型。
[0056]
步骤四、将上述特征级联在一起送入svm分类器,获取告警信息,最终预测的结果可以如图2。
[0057]
本发明是一种基于多特征级联的着装规范检测方法。本发明的优点是:通过将着装规范的复杂问题分解,将行人编码为特定多维特征,避免了单一模型预测对训练用样本和算法模型复杂度的要求,提高了输出告警的准确性和鲁棒性。
[0058]
1.降低了标注样本的困难程度,降低了对于标注数据样本覆盖区域的需求程度,针对工作人员遮挡,不用再标注服装属性,避免对于关键点等的复杂标注。
[0059]
2.具有一定的可解释性,使得模型输出具备更高的可信度,不再是一个黑盒子,其特征输出维度具有一定的物理意义。
[0060]
3.模型给出的告警更加准确,在人员密集、环境遮挡的情况下误报警信息较少,给出的告警较为精确。
[0061]
本发明还提供一种检测装置,包括:标注模块,标注模块包括第一单元和第二单元,第一单元用于爬取数据、获取真实场景的图像信息,第二单元用于将获取到的图像信息标注为对应的格式数据。
[0062]
存储模块,存储模块用于存储已标注的数据样本,并将数据样本划分为训练数据和测试数据。
[0063]
获取模块,获取模块用于利用上述方法对输入图像进行编码,将图像中的行人位置信息、行人姿态信息和行人服饰信息转换为特征向量。
[0064]
确认模块,确认模块用于最终判断是否给出告警信息。
[0065]
构建模块,构建模块用于基于数据训练的权重构建算法模型网络。
[0066]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点,对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
[0067]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。