1.本发明属于智能司法领域,涉及一种辩护意见可采纳性预测方法、 系统、设备及存储介质。
背景技术:
[0002]“智能司法”是非常具有现实意义的研究领域,其主要的研究目 的是辅助司法决策,为司法从业者及案件的参与者提供帮助。而辩护 是司法判决中非常重要的一环,尤其是刑事辩护。
[0003]
然而在目前的“智能司法”研究中,例如罪名预测,法律问题回 答以及类案查询中,并未将辩护意见作为参考因素。例如,基于深度 学习的盗窃罪辅助量刑方法这一专利,是针对盗窃案设计了一系列特 征,抽取特征后再通过深度学习来预测盗窃罪的量刑,但其中并未考 虑辩护意见的影响。另外,基于多维联动的可视化分析方法这一专利, 同样针对判决书做了研究,其将判决书中的主体抽取出来将主体之间 的关系可视化,且将判决书自动地切分成文书头部、文书尾部、综合 评判、指控内容、证据证实以及辩护意见五部分,这一专利虽然考虑 到了辩护意见,但只是浅显地将辩护意见分割出来,并未更进一步地 研究辩护意见的可采纳性以及对判决结果的影响。基于以上原因,我 们提出了辩护意见可采纳性预测这一课题,并提出了相应的研究方案, 来填补“智能司法”领域中的空白。
[0004]
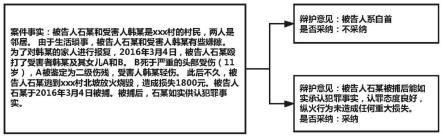
我们提出的问题可以描述为:在给定案件事实的情况下,预测所 对应的辩护意见是否会被采纳。这是因为在判决中的案件事实会描述 重要的案情经过以及被告人身份及认罪表现,从这些描述中我们能发 现与辩护意见有关的情节,从而做出判断。如说明书附图1所示,这 个案件中,辩护律师提出了两条辩护意见,其一是“被告人系自首”, 然而案件事实写道“被告人于3月4日被捕”,没有表现出自首情节, 与辩护意见相背离,因此不能被采纳;而第二条提出的辩护意见写道
ꢀ“
如实供述,纵火未造成重大损失”则与案情描述相符。
[0005]
辩护意见可采纳性任务与自然语言处理领域的自然语言推理任 务非常相似,都是给定两段文本,需要系统判断两段文本之间的关系 是支持还是反对。因此这里我们考虑采用自然语言推理中常用的注意 力机制来建模案件事实和辩护意见之间的语义关系,从而做出预测。
[0006]
然而,我们发现辩护意见可采纳性预测这个任务与自然语言推理 任务最重要的不同点在于,自然语言推理任务给出的前提文本非常短, 只有几句话。当然在已有的自然语言处理任务上,也有一些涉及了长 文本的处理,例如“reinforcedranker-readerforopen-domainquestion answering”等研究,采用了策略梯度的方 式进行长文本的抽取,但网络结构、应用领域和方式都与辩护意见可 采纳性预测不同。我们通过研究数据集发现案件事实的长度基本都在 600个词以上,并且案件事实中只有有限的几句与辩护意见相关。因 此,我们考虑先对案件事实中与辩护意见有关的文本进行抽取,再通 过这些抽取出来的文本段预测辩护意见是否会被采纳。我们结合上述 关键点,提出了一种结合注意力
机制和强化学习的神经网络模型,来 预测辩护意见可采纳性,并可以达到很高的准确率。
技术实现要素:
[0007]
本发明的目的在于克服上述现有技术的缺点,提供了一种辩护意 见可采纳性预测方法、系统、设备及存储介质,该方法、系统、设备 及存储介质能够准确预测辩护意见可采纳性。
[0008]
为达到上述目的,本发明采用如下技术方案:
[0009]
本发明所述的辩护意见可采纳性预测方法包括:
[0010]
采用注意力机制建立辩护意见和案件事实的语义关系;
[0011]
利用强化学习筛选与辩护意见相关的案件事实文本段;
[0012]
利用筛选出来的与辩护意见相关的案件事实文本段进行辩护意 见可采纳性预测。
[0013]
所述采用注意力机制建立辩护意见和案件事实的语义关系的具 体过程为:
[0014]
将辩护意见与案件事实中的单词通过词嵌入技术映射成为数值 表示;
[0015]
获取案件事实与辩护意见中各单词的上下文表示;
[0016]
计算案件事实与辩护意见之间每个词的相关度;
[0017]
获取基于辩护意见感知的案件事实单词表示;
[0018]
获取基于案件事实感知的辩护意见表示;
[0019]
采用所述基于案件事实感知的辩护意见表示及所述基于辩护意 见感知的案件事实单词表示编码案件事实的最终表示。
[0020]
所述利用强化学习筛选与辩护意见相关的案件事实文本段的具 体操作为:
[0021]
将案件事实切分为文本段;
[0022]
计算每个文本段的语义表示;
[0023]
计算每个文本段的相关度;
[0024]
利用强化学习策略筛选文本段;
[0025]
所述利用筛选出来的与辩护意见相关的案件事实文本段进行辩 护意见可采纳性预测的具体过程为:
[0026]
将强化学习策略挑选的文本段的表示按前后顺序连接形成文本 段表示;
[0027]
获取筛选出来的文本段的上下文表示;
[0028]
通过自我注意力机制获取筛选出来的文本段的语义关联;
[0029]
根据文本段表示、文本段的上下文表示及文本段的语义关联预测 辩护意见的可采纳性。
[0030]
利用强化学习筛选与辩护意见相关的案件事实文本段中强化学 习的回报函数为:
[0031][0032]
其中,为模型预测的结果,y为标签。
[0033]
本发明所述的辩护意见可采纳性预测系统包括:
[0034]
建立模块,用于采用注意力机制建立辩护意见和案件事实的语义 关系;
[0035]
筛选模块,用于利用强化学习筛选与辩护意见相关的案件事实文 本段;
[0036]
预测模块,用于利用筛选出来的与辩护意见相关的案件事实文本 段进行辩护意见可采纳性的预测。
[0037]
一种计算机设备,包括存储器、处理器以及存储在所述存储器中 并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机 程序时实现所述辩护意见可采纳性预测方法的步骤。
[0038]
一种计算机可读存储介质,所述计算机可读存储介质存储有计算 机程序,所述计算机程序被处理器执行时实现所述辩护意见可采纳性 预测方法的步骤。
[0039]
本发明具有以下有益效果:
[0040]
本发明所述的辩护意见可采纳性预测方法、系统、设备及存储介 质在具体操作时,采用注意力机制建立辩护意见和案件事实的语义关 系,再利用强化学习筛选与辩护意见相关的案件事实文本段,以提高 模型的透明性,然后利用筛选出来的与辩护意见相关的案件事实文本 段进行辩护意见可采纳性预测,需要说明的是,本发明采用强化学习 与注意力机制相结合,在提高模型透明性的前提下,实现辩护意见可 采纳性的高准确率预测。
附图说明
[0041]
构成本发明的一部分的说明书附图用来提供对本发明的进一步 理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对 本发明的不当限定。在附图中:
[0042]
图1为本发明的流程图;
[0043]
图2为本发明的结构示意图。
具体实施方式
[0044]
为了使本技术领域的人员更好地理解本发明方案,下面将结合本 发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整 地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不 是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没 有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发 明保护的范围。
[0045]
需要说明的是,本发明的说明书和权利要求书及上述附图中的术 语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特 定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互 换,以便这里描述的本发明的实施例能够以除了在这里图
示或描述的 那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任 何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单 元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤 或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品 或设备固有的其它步骤或单元。
[0046]
实施例一
[0047]
本发明所述的辩护意见可采纳性预测方法包括以下步骤:
[0048]
1)采用注意力机制建立辩护意见与案件事实之间的语义关系;
[0049]
步骤1)的具体过程为:
[0050]
11)将中文分词后的案件事实x与辩护意见q中的单词表示为可 计算的数据表示x,q,其中,案件事实的单词数为m,辩护意见的单 词数为n,其中,使用onehot编码或者分布式编码,例如,word2vec, elmo,bert等;
[0051]
12)利用长短期记忆网络获取案件事实和辩护意见的上下文编码 及
[0052][0053][0054]
13)计算案件事实与辩护意见之间每一个词的相关度a
ij
:
[0055][0056]
14)获取基于辩护意见感知的案件事实单词表示;
[0057]
具体的,先根据每个词的相似度,计算案件事实中的任意单词在 辩护意见上所有单词的注意力分布为:
[0058]
λi=softmax(a
i:
)
[0059]
计算具有辩护意见感知的案件事实的表示为:
[0060][0061]
15)获取基于案件事实的辩护意见表示;
[0062]
具体的,考虑每一个案件事实中的第i个单词,辩护意见所有单 词中能给出的最高注意力,即:
[0063]
vi=max(a
i:
)
[0064]
将得到的案件事实每一个单词与辩护意见所有单词的最高注意 力进行归一化,得最终的权重v:
[0065]
v=softmax(v)
[0066]
将得到的注意力和案件事实的上下文表示相乘后累加,得基于案 件事实的辩护意见表示向量即:
[0067][0068]
16)得辩护意见与案件事实语义关系的案件事实表示mi。
[0069][0070]
将案件事实整体的编码了两个文本段的语义关系的案件事实表 示为m。
[0071]
2)采用强化学习的策略梯度算法筛选出案件事实中与辩护意见 相关的文本段;
[0072]
21)将案件事实切分为文本段;
[0073]
具体的,将m切分为自然语句或采用等长的文本段表示,得s个 文本段表示lk,lk为每个文本段的长度。
[0074]
22)计算切分后每个文本段的语义表示。
[0075]
具体的,将切分好的文本段表示mk输入到bilstm中,将其前向 最后一个状态和后向的最后一个状态拼接,以获得每个文本段的语义 表示zk。
[0076][0077][0078][0079]
23)设计网络,计算每个文本段与辩护意见的相关度。
[0080]ek
=tanh(wczk bc)
[0081]
e=[e1,
…
,es]
[0082][0083]
24)利用强化学习策略筛选文本;
[0084]
具体的,使用强化学习中的策略梯度算法来筛选文本,在辩护意 见可采纳性预测问题中,强化学习中的智能体,即为本发明设计的模 型;智能体需要做出的动作是选择与辩护意见相关的文本段。强化学 习的环境为每个文本段与辩护意见之间的相关度。在强化学习中,当 游戏需要智能体走过一定的路径才能到达终点,则智能体走过的路径 上的点称为智能体的状态;在辩护意见可采纳性预测任务中,模型选 择完文本段后进行可采纳性预测,中间不存在其他步骤,因此本发明 不强行定义模型的状态。另外,策略梯度算法不要求对动作的价值进 行计算,只需要对动作被选择的概率进行模拟计算,因此本发明不设 动作价值,只计算文本段被选择的概率。通过神经网络模拟计算案件 事实中相关文本段被选择的概率φ,其中,强化学习中的策略为:
[0085][0086]
其中,π为指强化学习的策略,其依据神经网络中的参数θr和环 境状态e来选择文本段r,即,利用神经网络求取案件事实文本段被选 择的概率在训练和推理过程中,使用文本段的概率选择本文段, 当文本段r的概率的概率越高,则被选择的概率就越大。
[0087]
本发明选择文本段的数量为ss,通过改变ss的值,测试选择一个 或多个文本段的不同效果。另外,在本发明中,强化学习的策略梯度 主要计算的是所有文本段被选择的概率。本发明需要设计选择文本段 r后获得的回报(reward)函数,并根据reinforce算法来近似求导, 具体的求导算法推导以及回报函数均在训练部分探讨。
[0088]
3)使用筛选得到的文本段进行可采纳性预测;
[0089]
31)将强化学习挑选的文本段表示按顺序前后连接起来,以形成 一个文本段表示mg。
[0090]
mg=[m1,
…
,m
ss
]
[0091]
32)获取筛选出来的文本段的上下文表示,获取的文本段的表示 仍然是从第一部分的注意力机制中计算出来的,并没有经过第二部分 强化学习中的通过bilstm获取每个文本段的语义表示,先将拼接好 的文本段表示mg输入到一个bilstm网络中,并将其前向和后向的最 后一个状态拼接起来形成一个文本段语义表示,得到得到
[0092]
33)通过自我注意力机制获取筛选出的文本段之间的语义关联。
[0093]
此时只获得了对于单个文本段的语义表示,但预测采纳结果时, 需要将这几个文本段当作一个整体来看。因此,需要获取挑选出来的 文本段之间的关联。本发明选择自我注意力(self-attention)机制来 计算文本段关联后的语义表示,其中,选择的注意力计算方式为三角 注意力计算方式。只不过从辩护意见和案件事实之间的注意力计算, 转变成挑选出来的文本段矩阵和其本身之间的注意力的计算。另外, 当i=j时,关联度应设置为-∞。
[0094]
设此时获得的第i个文本段语义表示为li代表第i 个文本段中单词的数量。因此,所有筛选出来的文本段的表示为 [0095]
34)利用编码的辩护意见和相关文本段语义关系的表示来预测可 采纳性。
[0096][0097][0098][0099][0100]
最后,通过线性层和归一化函数预测可采纳性标签。
[0101][0102]
需要说明的是,将数据集中“采纳”或者“不采纳”的标签处理 为二维的向量,即[1,0]代表采纳,[0,1]代表不采纳。预测结果输 出维度也2维。因此只需要判断预测结果的最大值所在的下标与标 签最大值所在的下标是否一致即可判断预测是否准确;当两者最大值 下标一致,则预测正确;否则,则预测错误。
[0103]
需要说明的是,本发明采用交叉熵和反向传播进行模型训练。
[0104][0105]
在强化学习阶段,本发明采用策略梯度进行训练,训练过程中的 回报函数为:
[0106][0107]
目标函数为:
[0108][0109]
因此,总的目标函数为:
[0110][0111]
实施例二
[0112]
本发明所述的辩护意见可采纳性预测系统包括:
[0113]
建立模块,用于采用注意力机制建立辩护意见和案件事实的语义 关系;
[0114]
筛选模块,用于利用强化学习筛选与辩护意见相关的案件事实文 本段;
[0115]
预测模块,用于利用筛选出来的与辩护意见相关的案件事实文本 段进行辩护意见可采纳性的预测。
[0116]
实施例三
[0117]
一种计算机设备,包括存储器、处理器以及存储在所述存储器中 并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机 程序时实现所述辩护意见可采纳性预测方法的步骤,其中,所述存储 器可能包含内存,例如高速随机存储器,也可能还包括非易失性存储 器,例如,至少一个磁盘存储器等;处理器、网络接口、存储器通过 内部总线互相连接,该内部总线可以是工业标准体系结构总线、外设 部件互连标准总线、扩展工业标准结构总线等,总线可以分为地址总 线、数据总线、控制总线等。存储器用于存放程序,具体地,程序可 以包括程序代码、所述程序代码包括计算机操作指令。存储器可以包 括内存和非易失性存储器,并向处理器提供指令和数据。
[0118]
实施例四
[0119]
一种计算机可读存储介质,所述计算机可读存储介质存储有计算 机程序,所述计算机程序被处理器执行时实现所述辩护意见可采纳性 预测方法的步骤,具体地,所述计算机可读存储介质包括但不限于例 如易失性存储器和/或非易失性存储器。所述易失性存储器可以包括 随机存储存储器(ram)和/或高速缓冲存储器(cache)等。所述非 易失性存储器可以包括只读存储器(rom)、硬盘、闪存、光盘、磁 盘等。
[0120]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系 统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全 软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术 可采用在一个或多个其中包含有计算机可用程序代码的计算机可用 存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实 施的计算机程序产品的形式。
[0121]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算 机程序产品的流程
图和/或方框图来描述的。应理解可由计算机程序 指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图 和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指 令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理 设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处 理设备的处理器执行的指令产生用于实现在流程图一个流程或多个 流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0122]
这些计算机程序指令也可存储在能引导计算机或其他可编程数 据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计 算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实 现在流程图一个流程或多个流程和/或方框图一个方框或多个方框 中指定的功能。
[0123]
这些计算机程序指令也可装载到计算机或其他可编程数据处理 设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产 生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令 提供用于实现在流程图一个流程或多个流程和/或方框图一个方框 或多个方框中指定的功能的步骤。
[0124]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而 非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属 领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进 行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等 同替换,其均应涵盖在本发明的权利要求保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
