一种基于国产cpu的人工智能图片向量存储和检索方法
技术领域
1.本发明涉及图文识别技术领域,尤其涉及一种基于国产cpu的人工智能图片向量存储和检索方法。
背景技术:
2.在国家的大力扶持下,具有自主知识产权的全国产软硬件有了较快的发展,尤其是近年来我国涌现了众多具有自主知识产权的基础软硬件产品。龙芯、飞腾、北大众志等具有自主知识产权的高端通用芯片蓬勃发展,技术水平达到了同类产品的世界先进水平。
3.基于全国产环境的人工智能系统已经在很多地区投入使用,在生产环境中,向量检索扮演者重要的角色,图像检索需要向量检索,视频检索也需要向量检索等等,然而在国产系统和国产cpu的环境下,一些技术和产品不论是兼容性或性能上都不能很好的提供向量的检索技术支持。
技术实现要素:
4.为了解决以上技术问题,本发明提供了一种基于国产cpu的人工智能图片向量存储和检索方法,用来解决向量的存储和实时检索,提高向量数据存储速率和实时数据查询效率。
5.本发明的技术方案是:
6.一种基于国产cpu和操作系统的人工智能图片向量存储和检索方法,充分考虑国产cpu和操作系统环境下性能及兼容性问题对图像检索和存储的影响,具体良好的通用性和移植性,通过搭建faiss模型将所述对象特征向量信息输入所述faiss模型,通过提供请求接口,查询出相似的图片并输出,该方法可以提供图像检索仓库,查询准确率高,速度快,减少了大量的人力成本。
7.1、整体组成方法
8.通过kafka消费采集到的向量数据集,通过分布式数据库clickhous进行数据落地备份,数据落地备份的同时调用人工智能图片向量训练接口把需要训练的数据通过接口传输到训练服务器进行模型训练,生成相应的模型为查询提供数据模型。
9.2、kafka消费数据
10.所述的kafka消费,是通过人工智能提取的向量特征发送到消息队列,提供数据的落地和消费,数据消费后落地到数据库,调用训练数据的接口传输到训练服务器,训练完成后手动提交偏移量。
11.kafka手动提交偏移量,是为了防止因消费kafka数据并没有落地到数据库或者数据没有传输到训练服务器导致数据丢失的一种措施。
12.3、数据存储
13.clickhous数据库是面向列式数据的数据库管理系统,可以并行处理查询,可以分布式处理数据,存储数据量大,能够满足向量数据的落地备份。
14.分布式部署数据库是为了保证大数据量的数据落地,防止后期人工智能图片向量存储方法使用到亿级以及百亿级数据,而导致数据的溢出或者卡死,可以有效的做到数据的分流和高可用。
15.4、数据训练
16.将人工智能图片向量训练接口和人工智能图片向量存储方法提供给用户,用户把需要提供到搜索基库中的特征向量通过该接口进行训练和存储,生成查询基础库模型。
17.向量接口的训练方法,是通过faiss搜索库,用于将所述对象特征向量与属性信息压缩、编码、生成子聚类中心,并落地到文件中,同时存储到内存中为查询提供查询模型库。
18.faiss服务器训练方式采用indexflatl2,这就是基于l2距离(欧式距离)的暴力检索,,indexflatl2索引的结果是精确的,检索结果可靠。
19.接口训练方法的分配是通过zookeeper分布式应用程序进行协调服务,通过zookeeper进行事务性调度和处理,保证了训练服务器调度的合理性和有序性。
20.5、特征检索
21.向量查询接口,查询数据模型是基于上述数据通过训练服务器生成聚类中心,作为查询基础模型,基于该模型提供向量查询方法。
22.向量查询接口,用户只需要提供需要查询的向量值,通过接口传递,可以通过该接口获取到该向量值出现过的地点,时间,等基础信息,方便用户进行向量检索。
23.本发明的有益效果是
24.(1)本发明充分考虑了全国产软硬件环境下,不同操作系统的兼容性。
25.(2)本发明能够支撑亿级数据的插入,数据的备份,数据的查询。
26.(3)本发明能够达到亿级数据查询的支撑。
27.(4)本发明不仅支持图片的插入和查询,同时也可以支持视频的向量插入和查询。
附图说明
28.图1是注册到zookeeper的工作流程示意图;
29.图2是调用插入服务接口的工作流程示意图;
30.图3是调用查询服务接口的工作流程示意图;
31.图4为本发明为向量存储的示例图;
32.图5为本发明向量查询的示例图;
33.图6为本发明的faiss训练服务器工作原理;。
具体实施方式
34.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
35.本发明一种基于国产cpu和操作系统的人工智能图片向量存储和检索方法,它包含一种在任意大小的向量集合中搜索。它还包含用于评估和参数调整的支持代码。faiss是用c 编写的,带有python/numpy的完整封装,并使用gpu来获得更高的内存带宽和计算吞
吐量。
36.本发明基于搭载国产cpu并可运行中标、深度、普华等多种国产操作系统的设备,可同时兼容上述全国产软硬件环境。
37.具体流程如下:
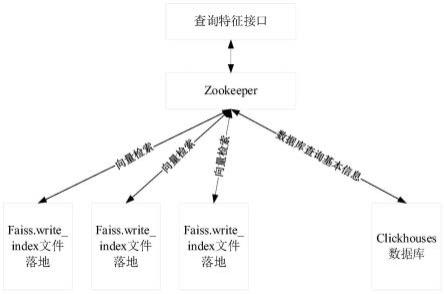
38.(1)启动服务
39.当启动服务的时候的原理如图6所示,首先将全部训练过的数据加载到内存当中,同时处理未保存的数据,处理流程是首先读取配置文件,将已经存入磁盘的训练过的数据读入到内存当中,检查data和log文件夹,处理未存入磁盘的数据。
40.(2)注册到zookeeper
41.将启动的服务注册到zookeeper的/faiss节点,创建以自身ip为名称的临时节点,保存服务的ip和端口信息,当该节点已经创建则不需要保存,当节点没有创建则创建一个新节点并保存信息,如图1所示。
42.(3)调用插入服务接口
43.当收到插入数据的时候,首先将数据存入到index变量当中,同时把数据存入日志,防止数据丢失,同时把数据存入clickhouse数据库当中,当数据量到达规定值,将内存中的数据保存到磁盘当中,同时删除data文件中的日志数据,防止多次读取。
44.首先会向zkclient发送插入请求,zkclient查询有哪些服务注册到zookeeper,获取这些服务的ip和端口信息,向这些ip和端口号发送插入请求,如图2所示。
45.(4)调用查询服务接口
46.当调用查询接口的时候,首先服务zkclient发送查询请求,zkclient查询有哪些服务注册到zookeeper,获取这些服务的ip和端口信息,向这些ip和端口号发送查询请求,得到返回结果,汇总返回结果返回给查询者,如图3所示。
47.以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。