基于改进apriori算法的水利工程安全隐患描述关联规则挖掘方法
技术领域
1.本发明涉及水利工程安全隐患排查技术领域,具体涉及一种基于改进apriori算法的水利工程安全隐患描述关联规则挖掘方法。
背景技术:
2.水利工程点多面广,存在大量的安全隐患,隐患之间常常存在关联性,挖掘各类安全隐患之间的关联关系具有重要意义。apriori算法作为最经典的关联规则挖掘算法,在水利工程领域中已有相关应用。但传统的apriori算法对于较大的数据集存在效率较低、耗时长的技术问题,且对于安全隐患描述这类非结构化文本难以进行准确分析。
3.为了解决上述存在的问题,如黄黎明等在《基于关联规则的水利工程建设质量安全监管数据挖掘与分析》中,根据问题描述将工程所存在技术问题划分为50个问题类别,采用apriori算法对工程属性与问题描述进行关联规则挖掘,该方法对原始隐患数据进行了合并归类的预处理,实现了隐患描述的结构化表达,但该方法处理原始隐患数据需要进行人工操作,对于大量数据需要耗费大量时间,且具有一定的主观性,影响结果的准确性;又如陈述等在《水电工程施工安全隐患关联规则挖掘》中,提出基于短语提取的关联规则优化算法,基于短语提取技术对隐患文本进行关键短语提取,同时将短语度量值作为评价指标,优化apriori算法中的支持度,从而挖掘隐患属性之间的关联规则,该方法通过短语提取技术挖掘文本中的新词,提高了分词质量,同时重新定义支持度,使得关联规则挖掘更加科学,但该方法采取的短语提取技术,所需的规则库搭建及维护需要大量人工成本,挖掘出的新词与水利工程领域的专有名词存在一定偏差,同时存在无明确含义的分词结果,如易造成,未设置等,且在apriori算法迭代方面没有进行改进,运算效率较低。
4.因此,构建一种高效的水利工程安全隐患描述关联规则挖掘方法是必要的,本发明所构建的一种基于改进apriori算法的水利工程安全隐患描述关联规则挖掘方法,与现有方法相比,具有两个显著特征:(1)构建水利工程领域自定义词库对隐患文本进行分词,采用textrank算法进行词性筛选及关键词提取,并基于独热编码将分词结果转换为布尔矩阵,预处理后的隐患文本只保留了一些重要关键词。(2)优化apriori算法,在逐层迭代之前,对布尔矩阵先进行一次频繁项集筛选。在迭代中进行剪枝优化,同时动态缩小数据集,关联规则挖掘运算效率明显得到了提高。
技术实现要素:
5.本发明目的在于提出一种基于改进apriori算法的水利工程安全隐患描述关联规则挖掘方法,解决水利工程安全施工中隐患描述难以结构化表达及关联规则挖掘算法运算效率低下的问题,及时挖掘水利工程施工中安全隐患之间的关联规则,为水利工程安全隐患的预测及排查治理提供辅助支持。
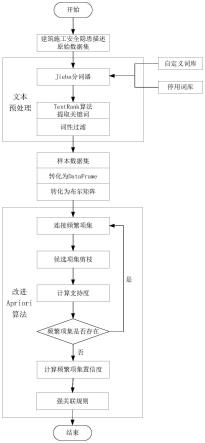
6.本发明的一种基于改进apriori算法的水利工程安全隐患描述关联规则挖掘方
法,包括以下步骤:
7.步骤s1,构建水利工程领域自定义词库,采用jieba分词对隐患数据集进行分词、去停用词,通过textrank算法筛选词性,提取出的关键词作为输入数据集;
8.步骤s2,步骤s2,基于独热one-hot编码对步骤s1得到的输入数据集进行布尔矩阵转换;
9.步骤s3,通过改进apriori算法计算各项集支持度,筛选出不小于最小支持度的项集,即为频繁项集;
10.步骤s4,对得到的频繁项集进行置信度计算,筛选出不小于最小置信度的关联规则,即为强关联规则a=》b,即项集a出现的情况下,项集b也会尽可能出现。
11.优选地,所述步骤s1具体包括:
12.步骤s11,搜集水利工程领域词条,构建水利工程领域自定义词库,采用jieba分词,对隐患数据集进行分词,并标注词性;
13.步骤s12,载入停用词库,剔除分词结果中的语气助词、副词、介词、连接词等通常自身并无明确意义的词;
14.步骤s13,采用textrank算法,对分词重要性进行排序,然后提取分词中词性为名词、动词、动名词、地名的关键词,作为最终的输入数据集。
15.经过上述步骤s11-s13,对数据集中难以结构化表达的隐患描述文本进行了预处理。
16.优选地,所述步骤s2具体包括:
17.步骤s21,首先将输入数据集d={d1,d1…
,dn},转化为dataframe数据框形式的矩阵t,矩阵t的形式为:
[0018][0019]
其中,n为隐患描述数据数量,m为n条数据中最多的分词数量,t
ij
为第i条数据的第j个关键词,若为空则为null;di为数据集中的第i条数据,即集合{t
i1
,t
i2
,
…
,t
in
};
[0020]
步骤s22,对数据框矩阵t进行独热one-hot编码,转换成布尔矩阵m;设i={i1,i2,
…
,i
t
}为数据集d中所有不同的项组成的集合,布尔矩阵m的形式为:
[0021][0022]
其中,t为数据集d中所有不同的关键词的数量,m
ij
为第i条数据对于第j个关键词的布尔值,若di包含ij,即第i条数据包含第j个关键词,则m
ij
的值为1(true),否则为0(false)。
[0023]
通过步骤s2将经步骤s1预处理的中文文本转换为容易识别的布尔矩阵。
[0024]
优选地,所述步骤s3具体包括:
[0025]
步骤s31,在进行迭代之前,对步骤s22转换得到的布尔矩阵,进行一次遍历,对布尔矩阵中的每一列分别进行计数求和,快速挖掘1维频繁项集,删除非频繁项集;
[0026]
步骤s32,在进行迭代时,k-1维频繁项集集合l
k-1
连接形成k维候选项集集合,记作ck;设i1和i2是l
k-1
中的项集,若他们中有k-2个项相同,则i1、i2可连接产生结果项集,该结果
项集为候选项集集合ck之一;
[0027]
步骤s33,对候选项集集合ck进行剪枝,ck为lk的超集;对于l
k-1
中的每个项集t,依次遍历ck中的所有候选项集,并基于布尔矩阵对每个候选项集进行计数。遍历全部结束后,通过计数结果对ck中的每个候选项集进行裁剪,若计数小于k则删除该候选项集,同时删除数据集中所有包含该项集的项集;否则保留并进行下一步;
[0028]
步s34,对剪枝后的每个候选项集进行支持度计算,支持度(support)公式为:
[0029]
support(a=》b)=p(a∪b)
[0030]
式中:a、b为i中任意项组成的项集,即表示数据包含项集a和b中的每个项的概率;
[0031]
若候选项集支持度不小于最小支持度,则为k-频繁项集,并加入lk,否则删除该项集,同时删除数据集中所有包含该项集的项集。筛选完后返回步骤s32,直至找不到k-频繁项集。
[0032]
通过步骤2和s31,在迭代之前,无需对各个关键词进行支持度计算,直接对布尔矩阵中的每一列分别进行计数求和,快速挖掘1维频繁项集,删除非频繁项集;基于布尔矩阵对大量的数据集进行快速筛选,从而大大缩小数据集,提高了迭代初期庞大数据集情况下的迭代运算效率。在进行迭代时,k-1维频繁项集集合l
k-1
连接形成k维候选项集集合ck,对于l
k-1
中的每个项集t,依次遍历ck中的所有候选项集,并基于布尔矩阵对每个候选项集进行计数。遍历全部结束后,通过计数结果对ck中的每个候选项集进行裁剪,若计数小于k则删除该候选项集,同时删除数据集中所有包含该项集的项集。通过步骤s32优化剪枝环节,将时间复杂度从o(n2)降到o(n),提高了整体的迭代运算效率。
[0033]
传统的apriori算法,对于每一个候选项集的k-1维子集,均要重新搜索一遍l
k-1
,这增加了运算时间,影响了算法效率。改进的apriori算法,主要在于迭代之前,先进行快速挖掘频繁项集,在迭代中进行剪枝优化,同时动态缩小数据集,从而显著提高算法的运算效率。
[0034]
与现有技术相比,本发明的有益效果在于:
[0035]
(1)本发明通过构建水利工程领域自定义词库,采用textrank算法进行关键词提取和词性过滤,通过机器自动分词,实现了对于难以结构化表达的隐患描述文本的预处理,克服了现有技术中人工成本高及无法识别水利工程领域性术语的问题。
[0036]
(2)本发明在迭代之前,基于布尔矩阵对大量的数据集进行快速筛选,从而大大缩小数据集,提高了迭代初期庞大数据集情况下的迭代运算效率;在迭代时,通过优化剪枝环节,将时间复杂度从o(n2)降到o(n),提高了整体的迭代运算效率。
[0037]
(3)本发明通过改进迭代前和迭代时的算法,大大提升了apriori算法的运算效率,克服了前述现有技术中庞大数据集情况下算法运算效率较低的问题。
附图说明
[0038]
图1为本发明的整体工作流程图。
具体实施方式
[0039]
下面结合实施例对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
[0040]
实施例1
[0041]
如图1所示,本发明所述方法具体包括以下步骤:
[0042]
步骤s1,构建水利工程领域自定义词库,采用jieba分词对隐患数据集进行分词、去停用词,通过textrank算法筛选词性,提取出的关键词作为输入数据集,具体步骤为:
[0043]
步骤s11,搜集水利工程隐患描述语句1917条作为样本数据集,部分样本数据集样本数据如表1所示,搜集水利工程领域词条7480条,构建水利工程领域自定义词库,采用jieba分词,对样本数据进行分词,并标注词性。
[0044]
部分词条如:暗灯、按地电阻值、暗敷、暗管、暗涵、暗合页、暗间、暗梁、暗炉片、安全出口、安全出口灯、安全出口灯出线口、安全岛、安全阀门调试记录、安全防范设施、安全管理、安全接地、安全警报系统等。
[0045]
表1
[0046][0047]
步骤s12,载入停用词库,剔除分词结果中的语气助词、副词、介词、连接词等通常自身并无明确意义的词,如“@”、“阿”、“而且”、“与”等。
[0048]
步骤s13,采用textrank算法,对分词重要性进行排序,提取分词中词性为名词(n)、动词(v)、动名词(vn)、地名(ns)的关键词。
[0049]
经步骤s11-s13得到如表2所示的最终的分词结果作为输入数据集。
[0050]
表2分词结果
[0051][0052]
步骤s2,对步骤s1得到的输入数据集进行布尔矩阵编码,即对于每条数据,若包含数据集中对应项集,则标记为1(true),否则为0(false),具体步骤为:
[0053]
步骤s21,首先将输入数据集转化为dataframe数据框形式的1917*20矩阵,其中,行数为1917,即隐患描述数据数量,列数为20,即1917条数据中最多的分词数量,第i行第j列个词语即为第i条数据的第j个关键词,若为空则为null,dataframe数据框如表3所示。
[0054]
表3dataframe数据框
[0055][0056]
步骤s22,对dataframe数据框进行独热one-hot编码,转换成布尔矩阵,矩阵为1917*1139,其中,行数为1917,即隐患描述数据数量,列数为1139,即数据集中所有不同的关键词的数量,若i条数据包含第j个关键词,则第i行第j列的值为1(true),否则为0(false)。编码后的布尔矩阵如表4所示。
[0057]
表4布尔矩阵结果
[0058][0059]
步骤s3,通过改进apriori算法计算各项集支持度,筛选出不小于最小支持度的项集即为频繁项集,由于数据量高达1917条,本实施例最小支持度阈值设置为0.01。筛选长度大于等于3的频繁项集,结果如表5所示。
[0060]
表5频繁项集结果
[0061][0062]
通过频繁项集结果反映,在该数据集所对应的水利工程安全施工过程中,拌和站检修车间、砂石加工厂配电室等地点经常出现安全隐患,脚手架密目网脱落、电缆绝缘老化、施工现场人员佩戴等安全隐患问题较为频繁出现。
[0063]
步骤s4,对得到的频繁项集进行置信度计算,筛选出不小于最小置信度的关联规则,即为强关联规则。使用association_rules()函数对步骤s3得到的频繁项集进行进一步关联规则挖掘,以置信度为评价值进行挖掘。设置最低置信度为0.8。强关联规则结果如表6所示。置信度为1则为绝对关联项。
[0064]
表6强关联规则结果
[0065][0066][0067]
通过强关联规则结果反映,在该数据集所对应的水利工程安全施工过程中,脚手架密目网经常出现脱落的安全隐患问题,施工现场的人员经常出现佩戴相关问题,拌合站检修车间是安全隐患较为频繁发生的地方。
[0068]
在本实施例中,本发明的有益效果具体体现在:(1)对于本实施例采用的1917条数据,通过机器代码实现自动分词,分词结果如表2所示,而前述的现有技术中的短语提取技
术由于未引入水利工程领域自定义词库,且未进行词性过滤,产生了如”易造成”、”未要求”、”未设置”等没有明确含义和词性的词语,降低了分词质量,影响关联规则挖掘的准确性。(2)基于本实施例采用的1917条数据,通过pycharm进行代码测试,传统的apriori算法需要花费0.1587965秒,而本发明中提出的改进apriori算法只需要花费0.0328939秒,大大提升了算法的运算效率。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
