1.本发明涉及相似案例检索领域,特别涉及一种基于改进粒子群算法的相似度检索方法。
背景技术:
2.案例相似度检索就是根据目标案例,在已有案例中查找与目标案例相似的案例,通常采用相似度算法进行检索最相似的案例,粒子群算法是较常用的相似度检索算法,传统的粒子群算法易陷入局部最优,导致检索效率差,并且采用固定权重在案例增多时会影响相似度检索效率,而权重需根据案例库进行调整,才能针对不同的适应函数有最佳的适应度。
3.现有技术存在以下问题:
4.1)权重固定不变影响检索性能;
5.2)学习因子不能依照迭代进行更改影响收敛速度。
技术实现要素:
6.本发明针对上述存在的问题,提出了一种基于改进粒子群算法的相似度检索方法。
7.本发明采用的技术方案是:
8.一种基于改进粒子群算法的相似度检索方法,所述方法包括:
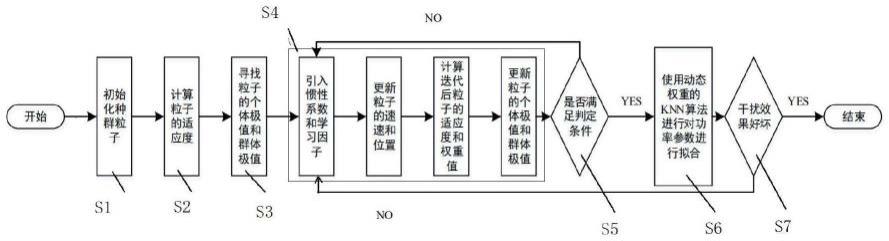
9.步骤s1:初始化种群粒子:所述初始化种群粒子包括设置种群规模n、随机设定每个粒子的初始位置、初始速度,并设置粒子的迭代次数k、最大迭代次数t
max
,设置粒子群算法惯性系数wd范围,随机选择一组惯性系数wd;
10.步骤s2:适应度计算,计算每个粒子的适应度值f(x);
11.步骤s3:寻找粒子的个体最优p
besti
和种群最优g
besti
,记录个体最优和种群最优的粒子位置;
12.步骤s4:采用改进粒子群算法进行粒子位置更新,引入惯性系数wd,更新学习因子,更新粒子位置,计算迭代后的粒子适应度值并排序,更新粒子的个体最优和群体最优,其中,学习因子采用以迭代次数k为自变量的三角函数,粒子群算法的权重采用动态权重;
13.步骤s5:判断条件,迭代次数k是否到达最大迭代次数t
max
,
14.若k小于t
max
,则k 1,并重新进行步骤s4;
15.若k等于t
max
,则输出并保存种群最优的n个粒子位置,作为n个相似案例,记录适应度函数值f
best
(xi);
16.步骤s6:参数拟合,采用knn算法对n个相似案例进行拟合,记录knn算法的权重
17.步骤s7:效果评估,设置评估门限,评估效果满足要求设定评估门限,则结束,不满足,则进行步骤s4,其中步骤s4中的粒子群算法的惯性权重wd采用步骤s6中knn算法的权重
18.进一步,所述步骤s4中改进粒子群算法的学习因子设置为:
[0019][0020][0021]
其中,c
max
=2,c
min
=1,k为迭代次数,t
max
为最大迭代次数, c1和c2在[1,2]之间变化。
[0022]
进一步,步骤s6中knn算法的权重计算采用公式:
[0023][0024]
其中,di目标案例与第i个案例的距离,n是步骤5检索的相似案例,i={1,2,...,n}。
[0025]
进一步,所述步骤s2、步骤s4的适应度计算方法设置为决定系数或均方误差、平均绝对百分比误差或平均误差至少之一。
[0026]
进一步,所述步骤s3、步骤s4寻找粒子的个体最优和种群最优的过程为:
[0027]
个体最优,将每个粒子的适应度函数值f(xi)与之前计算出的最好位置p
besti
的适应度值进行比较,如果当前的适应度函数值f(xi)小于最好位置的适应度值,则更新粒子的位置和适应度值f(xi),更新当前位置值p
besti
和适应度函数值f(xi);
[0028]
群体最优,将单个粒子的适应度函数值f(xi)与所有粒子经过的最好位置g
besti
的适应度值进行比较,如果当前适应度函数值f(xi)更小,则用现在粒子的位置和适应度值f(xi)更新,更新为当前的位置值和适应度值f(xi),记录此位置下的数据集坐标值。
[0029]
改进粒子群算法采用mape、mse、mae、r2四个自适应函数至少其中之一进行适应度评估。如:其它公式参数与mape参数含义一致,不再论述。
[0030][0031]
式中,t
max
是最大迭代次数;
[0032]
x
forecast
(i)改进粒子群算法的预测值;
[0033]
x
real
(i)需要比较的目标案例的实际值;
[0034]
与现有技术相比,本发明具有的有益效果:
[0035]
(1)改进的pso算法采用动态权重,与传统的案例检索不同的是,在每次检索案例的时候所有到的权重都是上一次案例检索后经过功率拟合的权重,有利于提高算法的全局搜索能力,因此检索的相似案例的质量也相应提高。
[0036]
(2)pso算法中的学习因子用于调节粒子群算法在学习过程中的步长,在迭代过程中,c1表示粒子受
″
自我认知经验
″
影响的大小,c2表示粒子受
″
群体社会经验
″
影响的大小,当c1为0 时,说明粒子只受社会经验的影响;当c2为0时,说明粒子只受自我经验的影响。所以c1和c2的选择不应该过大也应该过小,当c1和c2过大时,可能会错过最优解;当c1和c2过小时,无法找到最优解。常规的粒子群算法是将c1和c2设置为定值,粒子在迭代的过程中没
有自适应调节的能力,算法效果不好。本发明将学习因子设置为动态随迭代次数变换的三角函数,在搜索初期,粒子的适应度函数值较小,说明粒子逐步向最优解移动,这时应该增加
″
群体社会经验
″
的影响,即随着学习因子 c2的增加,c1的降低;粒子的适应度函数值随迭代次数的增加而增加,说明粒子逐渐向全局最优解移动,这时应该增加
″
自我认知经验
″
的影响,即随着学习因子c2的降低,c1的增加。因此,可以提高pso算法找到最优解的概率。
附图说明
[0037]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
[0038]
图1为本发明一种基于改进粒子群算法的相似度检索方法;
[0039]
图2传统粒子群算法仿真结果;
[0040]
a)mape评估结果;b)mse评估结果;c)mae评估结果;d) r2评估结果;
[0041]
图3改进的粒子群算法仿真结果;
[0042]
a)mape评估结果;b)mse评估结果;c)mae评估结果;d) r2评估结果;
具体实施方式
[0043]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
[0044]
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0045]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
[0046]
在本发明的描述中,需要说明的是,术语
″
第一
″
、
″
第二
″
、
″
第三
″
等仅用于区分描述,而不能理解为指示或暗示相对重要性,此外,术语
″
水平
″
、
″
竖直
″
等术语并不表示要求部件绝对水平或悬垂,而是可以稍微倾斜。如
″
水平
″
仅仅是指其方向相对
″
竖直
″
而言更加水平,并不是表示该结构一定要完全水平,而是可以稍微倾斜。
[0047]
在本发明的描述中,还需要说明的是,除非另有明确的规定和限定,术语
″
设置
″
、
″
安装
″
、
″
相连
″
、
″
连接
″
应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
[0048]
参照图1~3所示
[0049]
一种基于改进粒子群算法的相似度检索方法,所述方法包括:
[0050]
步骤s1:初始化种群粒子:所述初始化种群粒子包括设置种群规模n、随机设定每个粒子的初始位置、初始速度,并设置粒子的迭代次数k、最大迭代次数t
max
,设置粒子群算法惯性系数wd范围为 0-0.33333,在设定惯性系数中随机选择一组权重wd;
[0051]
步骤s2:适应度计算,计算每个粒子的适应度值f(x);
[0052]
步骤s3:寻找粒子的个体最优p
besti
和种群最优g
besti
,记录个体最优和种群最优的粒子位置;
[0053]
步骤s4:采用改进粒子群算法进行粒子位置更新,引入惯性系数wd,更新学习因子,更新粒子位置,计算迭代后的粒子适应度值并排序,更新粒子的个体最优和群体最优,其中,学习因子采用以迭代次数k为自变量的三角函数,粒子群算法的权重采用动态权重;
[0054]
步骤s5:判定条件,迭代次数k是否到达最大迭代次数t
max
,
[0055]
若k小于t
max
,则k 1,并重新进行步骤s4;
[0056]
若k等于t
max
,则输出并保存种群最优的n个粒子位置,作为n个相似案例,记录适应度函数值f
best
(xi)。
[0057]
步骤s6:参数拟合,采用knn算法对n个相似案例进行拟合,记录knn算法的权重
[0058]
步骤s7:效果评估,设置评估门限,效果评估结果满足要求设定评估门限,则结束,不满足要求,反馈至步骤s4,其中步骤s4中改进粒子群算法的惯性系数wd采用步骤s6中knn算法的权重
[0059]
优选地,所述步骤s4中改进粒子群算法的学习因子设置为:
[0060][0061][0062]
其中,c
max
=2,c
min
=1,k为迭代次数,t
max
为最大迭代次数, c1和c2在[1,2]之间变化。
[0063]
优选地,步骤s6中knn算法的权重计算采用公式:
[0064][0065]
其中,di目标案例与第i个案例的距离,n是步骤5检索的相似案例,i={1,2,...,n}。
[0066]di
目标案例与第i个案例的距离,采用空间自由衰减算法,如下公式:
[0067][0068]
式中,n相似案例的数量;
[0069]di
(x
t
,xi)目标案例与第i个案例距离;
[0070]fsi
第i个案例的中心频率;
[0071]ft
目标案例的中心频率;
[0072]
l
si
第i个案例的电平的差值;
[0073]
l
t
目标案例的电平的差值;
[0074]dsi
第i个案例的距离的比值;
[0075]dt
目标案例的距离的比值;
[0076]w1d w
2d w
3d
特征权重。
[0077]
优选地,所述步骤s2、步骤s4的适应度计算方法设置为决定系数或均方误差、平均绝对百分比误差或平均误差至少之一。
[0078]
优选地,所述步骤s3、步骤s4寻找粒子的个体最优和种群最优的过程为:
[0079]
个体最优,将每个粒子的适应度函数值f(xi)与之前计算出的最好位置的适应度值进行比较,如果当前的适应度函数值f(xi)小于最好位置的适应度值,则更新粒子的位置和适应度值f(xi),更新当前位置值和适应度函数值f(xi);
[0080]
群体最优,比较单个粒子的适应度函数值f(xi)与所有粒子经过的最好位置的适应度值,如果当前适应度函数值f(xi)更小,则用现在粒子的位置和适应度值更新为当前的位置值和适应度值f(xi),记录此位置下的数据集坐标值。
[0081]
实施例
[0082]
以自适应知识引擎技术的实现过程进行仿真,目标案例是通过对接收机采集的数据进行处理,对来自接收机的输入信息进行分析提炼作为目标案例,通过改进的粒子群算法在已有的案例库中进行相似案例的检索,输出检索的相似案例,通过结果评估获得实际效果。
[0083]
优选地,在每次检索案例的时候,所用到的权重都是上一次检索案例的最佳权重,合适权重有利于提高算法的全局搜索能力,所采用的权重值可以随着案例库的动态增加而发生改变,所检索出的相似案例的质量也不断提高。
[0084]
需要随机选取部分案例作为数据集,不能选取全部数据作为数据集,因为使用全部案例会造成推理效率降低。这样有利于提高的检索效率,选取部分数据集可以减少用时。在随机选取案例时,尽可能选取多种类型的案例,这样则不会因案例过于单一而影响干扰效果。在第一次使用权重的时候,先随机生成一组权重进行计算,随着粒子群算法迭代次数的不断增多,最终生成最佳权重值。
[0085]
优选地,在所述步骤s6的设定参数为功率参数、电平、距离,其中,以干扰功率作为主要参数,进行拟合包括以下步骤:
[0086]
将n个相似案例,即步骤s5获得的相似案例n的干扰功率进行加权平均后作为干扰目标案例的干扰功率,公式如下:
[0087][0088][0089]
式中,对目标案例的干扰功率;
[0090]
pi第i个相似案例的干扰功率;
[0091]
knn算法的权重,作为最优权重作为惯性系数参于下一次粒子群算法的迭代;
[0092]di
目标案例与第i个案例的距离,目标案例则是需要对比检索与之相似的案例称为目标案例。
[0093]di
目标案例与第i个案例的距离,采用空间自由衰减算法,如下公式:
[0094][0095]
式中,n相似案例的数量;
[0096]di
(x
t
,xi)目标案例与第i个案例距离;
[0097]fsi
第i个案例的中心频率;
[0098]ft
目标案例的中心频率;
[0099]
l
si
第i个案例的电平的差值;
[0100]
l
t
目标案例的电平的差值;
[0101]dsi
第i个案例的距离的比值;
[0102]dt
目标案例的距离的比值;
[0103]w1dw2dw3d
特征权重,依据本次迭代使用的惯性权重,及三个参数频率、电平、距离在设计中的重要程度,合理分配。
[0104]
采用所述改进粒子群算法采用自适应度函数mape、mse、 mae、r2至少之一,改进粒子群算法与常规粒子群算法相比的优势如图2、图3,统计如表1。
[0105]
表1传统的pso算法与改进的pso算法
[0106]
评价方法传统pso算法改进的pso算法mape3.836243.83618mse146.249146.151mae7.42637.4181r20.9864270.986987
[0107]
评价指标结果分析见表1,相比于传统的pso算法,改进后的 pso算法的mape、mse和mae数值越小,pso算法的预测效果越好。r2的取值范围是[0,1],当r2的数值越大,说明预测效果好; r2的数值越小,说明预测效果差。即r2数值越大干扰功率预测效果越好。
[0108]
mape指标降低了0.00006,降低的幅度达到了0.006%;mse 指标降低了0.098,降低的幅度达到了9.8%;mae指标降低了 0.0082,降低的幅度达到了0.82%;、r2指标提高了0.00056,结果高达到了0.056%。可以明显看出,改进的pso算法预测效果更好。
[0109]
仿真效果:改进的pso案例检索算法中,当t
max
为50;输出的最优的惯性权重系数wd为[0.464160,0.050000,0.535840]; f
best
(xi)适应度函数值为146.151,仿真结果见图2,图3。
[0110]
步骤s7中的效果评估,对于所例举的自适应知识引擎技术,干扰成功则意味着通讯接收模块不能接收完整电磁信号,通过根据评估结果,调整惯性权重系数,可以提高干扰率及时间效率。
[0111]
表2仿真结果
[0112]
仿真场景干扰率决策时间(s)无决策80.86%8.23
本文决策引擎93.67%1.97
[0113]
从表2中可以看出本文决策引擎的干扰率为93.67%、决策时间为 1.97s,性能
[0114]
优于无决策的系统,这是因为自适应引擎系统可以根据电磁信号通过算法选择合适的参数进行决策,使得干扰率提升,决策时间降低。
[0115]
以上所述,仅是本发明的较佳实施例,并非对本发明作任何限制。凡是根据发明技术实质对以上实施例所作的任何简单修改、变更以及等效变化,均仍属于本发明技术方案的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。