1.本技术涉及故障诊断技术领域,尤其涉及一种故障预测方法及相关装置。
背景技术:
2.随着科学技术的发展,基于样本数据训练机器学习模型,已广泛应用在各个领域中。在对机器学习模型进行训练时,可以采集大量的样本数据,并依据针对样本数据提取的特征,对机器学习模型进行训练,以使机器学习模型对输入数据的预测结果与提取的特征逐渐接近。样本数据可以包括正样本数据和负样本数据,正样本数据为需要机器学习模型学习的某一类别的数据,负样本数据为不属于该类别的数据。
3.在某种应用场景下,正样本数据的样本数量可能非常少。例如在硬盘故障预测领域中,对于固态驱动器(solid state disk或solid state drive,简称ssd)来说,俗称固态硬盘,ssd硬盘的故障率很低,故障硬盘数据很少。这就导致训练得到的预测模型的预测准确度较低。
技术实现要素:
4.本技术实施例公开了一种故障预测方法及相关装置,能够提高模型预测的准确性。
5.本技术实施例第一方面公开了一种故障预测方法,包括:从多个样本数据中划分得到正样本数据和负样本数据,其中,正样本数据包括多个样本数据中的故障数据和第一部分亚健康数据,第一部分亚健康数据的特征与故障数据的特征的相似度大于第一阈值,负样本数据包括多个样本数据中的健康数据和第二部分亚健康数据,第二部分亚健康数据的特征与故障数据的特征的相似度小于第二阈值;根据正样本数据和负样本数据训练得到故障预测模型,其中,故障预测模型用于分析目标数据。
6.在本技术实施例中,对样本数据重新进行划分得到正样本数据和负样本数据,其中,正样本数据中包括样本数据总的故障数据和一部分亚健康数据,此部分亚健康数据是与故障数据相似度比较高的数据;负样本数据包括样本数据中的健康数据和一部分亚健康数据,此部分亚健数据是与故障数据相似度比较低的数据。相对于现有的将故障数据作为负样本数据以及将非故障数据作为正样本数据的划分方式而言,通过这种方法,可以对样本数据重新进行划分来有效解决正负样本不均衡问题,基于上述正样本数据和负样本数据可以更好的对模型进行训练,提高模型预测的准确性。
7.在第一方面的一种可能的实施方式中,从多个样本数据中划分得到正样本数据和负样本数据之前,还包括:按照预设滑窗获取多个预设滑窗内的每个样本数据的差分值;对多个预设滑窗内的每个样本数据的差分值分别进行求和,得到多个样本特征。
8.可以看出,通过预设滑窗所提取的样本特征可以反应到一定时间窗口内的信息,便于对样本数据进行更好的划分。
9.在第一方面的一种可能的实施方式中,从多个样本数据中划分得到正样本数据和
负样本数据,包括:从多个样本数据中确定目标亚健康数据,其中,目标亚健康数据的特征与健康数据的特征的相似度小于第三阈值;将目标亚健康数据中与故障数据的特征相似度大于第一阈值的目标亚健康数据标记为第一部分亚健康数据;将目标亚健康数据中与故障数据的特征相似度小于第二阈值的目标亚健康数据标记为第二部分亚健康数据;将故障数据和第一部分亚健康数据标记为正样本数据;将健康数据和第二部分亚健康数据标记为负样本数据。
10.可以看出,首先从样本数据中确定目标亚健康数据,然后将目标亚健康数据中与故障数据具有相似度的数据标记为第一部分亚健康数据,将第一部分亚健康数据归类为正样本数据,对原本只包含故障数据的正样本数据进行了扩充;将目标亚健康数据中与故障数据不太具有相似度的数据标记为第二部分亚健康数据,将第二部分亚健康数据和健康数据归类为负样本数据。通过本方法可以对样本数据进行更好的划分,使得划分得到的正负样本数据达到均衡的状态。
11.在第一方面的一种可能的实施方式中,从多个样本数据中确定多个目标亚健康数据,包括:将多个样本数据中特征值为0或者特征值趋向为0的数据标记为健康数据;对健康数据和多个样本数据进行特征相似度分析,将多个样本数据中与健康数据的特征相似度小于第三阈值的数据标记为亚健康数据。
12.可以看出,首先从样本数据中确定健康数据,然后将样本数据中与健康数据不太具有相似度的数据标记为目标亚健康数据。至此,样本数据被划分为故障数据、目标亚健康数据和故障数据。而目标亚健康数据可以认为是划分故障数据和健康数据的边界。
13.在第一方面的一种可能的实施方式中,根据正样本数据和负样本数据训练得到故障预测模型之后,还包括:基于故障预测模型分析目标数据得到预测结果;根据预测结果确定预测结果的多个原因;输出预测结果、多个原因、以及预测结果的各个原因的重要性占比。
14.可以看出,基于故障预测模型不仅可以输出预测结果,还可以输出预测结果的多个原因,以及各个原因的重要性占比。因此,根据预测结果的多个原因可以对运维操作提供指导,便于进行有针对性的维护。
15.在第一方面的一种可能的实施方式中,根据预测结果确定导致预测结果的原因,包括:根据预测结果从故障预测模型中选择预测结果对应的决策树;获取决策树对应的决策路径上的分裂特征,分裂特征为导致预测结果的原因。
16.可以看出,基于故障预测模型来确定分裂特征,将分裂特征作为预测结果的原因,不需要人为去寻找原因,更加便捷且具有可信度。
17.在第一方面的一种可能的实施方式中,正样本数据和负样本数据为根据增长趋势分析、距离计算和聚类方法中的一种或多种从多个样本数据中划分得到的。
18.可以看出,可以通过不同的分类方法对样本数据进行分类,分类方法更加丰富,可选择性更高。
19.在第一方面的一种可能的实施方式中,故障预测模型为随机森林模型。
20.本技术实施例第二方面公开了一种故障预测装置,包括:
21.样本划分单元,用于从多个样本数据中划分得到正样本数据和负样本数据,其中,正样本数据包括多个样本数据中的故障数据和第一部分亚健康数据,第一部分亚健康数据
的特征与故障数据的特征的相似度大于第一阈值,负样本数据包括多个样本数据中的健康数据和第二部分亚健康数据,第二部分亚健康数据的特征与故障数据的特征的相似度小于第二阈值;
22.训练单元,用于根据正样本数据和负样本数据训练得到故障预测模型,其中,故障预测模型用于分析目标数据。
23.在本技术实施例中,对样本数据重新进行划分得到正样本数据和负样本数据,其中,正样本数据中包括样本数据总的故障数据和一部分亚健康数据,此部分亚健康数据是与故障数据具有相似度的数据;负样本数据包括样本数据中的健康数据和一部分亚健康数据,此部分亚健数据是与故障数据相似度比较低的数据。相对于现有的将故障数据作为负样本数据以及将非故障数据作为正样本数据的划分方式而言,通过这种方法,可以对样本数据重新进行划分来有效解决正负样本不均衡问题,基于上述正样本数据和负样本数据可以更好的对模型进行训练,提高模型预测的准确性。
24.在第二方面的一种可能的实施方式中,还包括特征单元,用于:按照预设滑窗获取多个预设滑窗内的每个样本数据的差分值;对多个预设滑窗内的每个样本数据的差分值分别进行求和,得到多个样本特征。
25.可以看出,通过预设滑窗所提取的样本特征可以反应到一定时间窗口内的信息,便于对样本数据进行更好的划分。
26.在第二方面的一种可能的实施方式中,样本划分单元,具体用于:从多个样本数据中确定目标亚健康数据,其中,目标亚健康数据的特征与健康数据的特征的相似度小于第三阈值;将目标亚健康数据中与故障数据的特征相似度大于第一阈值的目标亚健康数据标记为第一部分亚健康数据;将目标亚健康数据中与故障数据的特征相似度小于第二阈值的目标亚健康数据标记为第二部分亚健康数据;将故障数据和第一部分亚健康数据标记为正样本数据;将健康数据和第二部分亚健康数据标记为负样本数据。
27.可以看出,首先从样本数据中确定目标亚健康数据,然后将目标亚健康数据中与故障数据具有相似度的数据标记为第一部分亚健康数据,将第一部分亚健康数据归类为正样本数据,对原本只包含故障数据的正样本数据进行了扩充;将目标亚健康数据中与故障数据不太具有相似度的数据标记为第二部分亚健康数据,将第二部分亚健康数据和健康数据归类为负样本数据。通过本方法可以对样本数据进行更好的划分,使得划分得到的正负样本数据达到均衡的状态。
28.在第二方面的一种可能的实施方式中,样本划分单元,具体用于:将多个样本数据中特征值为0或者特征值趋向为0的数据标记为健康数据;对健康数据和多个样本数据进行特征相似度分析,将多个样本数据中与健康数据的特征相似度小于第三阈值的数据标记为亚健康数据。
29.可以看出,首先从样本数据中确定健康数据,然后将样本数据中与健康数据不太具有相似度的数据标记为目标亚健康数据。至此,样本数据被划分为故障数据、目标亚健康数据和故障数据。而目标亚健康数据可以认为是划分故障数据和健康数据的边界。
30.在第二方面的一种可能的实施方式中,还包括预测分析单元,用于基于故障预测模型分析目标数据的预测结果;根据预测结果确定预测结果的多个原因;输出预测结果、多个原因、以及预测结果的各个原因的重要性占比。
31.可以看出,基于故障预测模型不仅可以输出预测结果,还可以输出预测结果的多个原因,以及各个原因的重要性占比。因此,根据预测结果的多个原因可以对运维操作提供指导,便于进行有针对性的维护。
32.在第二方面的一种可能的实施方式中,预测分析单元,具体用于:根据预测结果从故障预测模型中选择预测结果对应的决策树;获取决策树对应的决策路径上的分裂特征,分裂特征为导致预测结果的原因。
33.可以看出,基于故障预测模型来确定分裂特征,将分裂特征作为预测结果的原因,具有可信度。
34.在第二方面的一种可能的实施方式中,正样本数据和负样本数据为根据增长趋势分析、距离计算和聚类方法中的一种或多种从多个样本数据中划分得到的。
35.可以看出,可以通过不同的分类方法对样本数据进行分类,分类方法更加丰富,可选择性更高。
36.在第二方面的一种可能的实施方式中,故障预测模型为随机森林模型。
37.本技术实施例第三方面公开了一种故障预测设备,包括至少一个处理器、至少一个存储器和通信接口,通信接口用于发送和/或接收数据,至少一个处理器用于调用至少一个存储器中存储的计算机程序,以使得装置实现第一方面或者第一方面任意一种可能的实施方式所描述的方法。
38.本技术实施例第四方面公开了一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,当计算机程序在一个或多个处理器上运行时,执行第一方面或第一方面的任意一种可能的实施方式所描述的方法。
39.本技术实施例第五方面公开了一种芯片系统,芯片系统包括至少一个处理器,存储器和接口电路,该接口电路用于为上述至少一个处理器提供信息输入/输出,该存储器中存储有计算机程序,当计算机程序在一个或多个处理器上运行时,执行第一方面或第一方面的任意一种可能的实施方式所描述的方法。
附图说明
40.以下对本技术实施例用到的附图进行介绍。
41.图1是本技术实施例提供的一种故障预测系统的结构示意图;
42.图2是本技术实施例提供的一种故障预测的场景示意图;
43.图3是本技术实施例提供的一种故障预测方法的流程示意图;
44.图4是本技术实施例提供的一种故障预测装置的结构示意图;
45.图5是本技术实施例提供的一种故障预测设备的结构示意图。
具体实施方式
46.下面结合本技术实施例中的附图对本技术实施例进行描述。
47.在硬盘故障预测领域中,近年来,越来越多的企业在数据存储中采用固态硬盘(solid state drive,ssd),但是随着ssd即将进入生命周期的中后期,本技术的发明人发现一些大型数据中心的ssd的故障率逐年上升。硬盘故障问题可能直接影响客户业务的连续性。相比于被动容错技术,硬盘故障的主动预测可以根据预测结果,有计划地执行运维策
略,避免ssd的突然故障导致客户业务的可用性和客户体验受到影响。
48.目前来说,在硬盘故障预测领域中,本技术的发明人发现故障预测存在以下问题:
49.问题1,硬盘故障预测研究多针对机械硬盘(hard disk drive,hdd),因为ssd故障率更低,所利用的故障硬盘数据更少,从而可能导致在模型训练时存在正负样本不平衡的问题。部分故障硬盘在s.m.a.r.t和i/o数据等信息上没有明显的特征,而健康硬盘却存在大量特征,所以健康硬盘的特征会混淆对故障硬盘的判断,从而可以导致健康硬盘和故障硬盘在特征上难以区分。
50.目前的故障预测方法是在健康硬盘和故障硬盘中按照一定比例随机抽取数据作为样本训练集,剩余数据集作为测试集/验证集,比如说使用采样方法。
51.其中,采样方法包括上采样和下采样。下采样指对占比比较大的样本随机抽样,或通过k-means等聚类方法对占比比较大的样本进行抽取;上采样是指对样本数据量较少的样本进行重复采样(比如朴素随机上采样),或者通过合成少数类过采样技术(synthetic minority oversampling technique,smote)等方法生成样本数据。
52.本技术的发明人发现由于采样方法没有根据硬盘数据的特征对硬盘数据进行划分,无法很好的对正负样本进行划分。
53.再比如说,使用无监督和异常检测方法来解决正负样本不均衡问题。
54.其中,无监督和异常检测类方法只使用占比较大的样本类训练模型。常用的方法包括基于统计的异常检测算法(比如说boxplot,3-sigma,移动平均等),基于密度的异常检测算法(比如说离群因子(local outlier factor,lof)),基于聚类的异常检测算法(k-means,dbscan,one-class svm,iforest),基于主成分分析的算法(principal components analysis,pca),基于样本重建误差的算法(autoencoder)等。
55.本技术的发明人发现由于无监督和异常检测类方法缺少对样本标注信息的利用,也无法很好的对正负样本进行划分。
56.问题2,目前的故障预测领域的研究主要以提高模型召回率,降低模型误报率为目标。比如说,使用支持向量机(support vector machine,svm)、随机森林、长短时记忆网络(long short-term memory,lstm)等模型方法,以提高模型召回率,降低模型误报率。但是,本技术的发明人发现现有sklearn提供的随机森林只针对训练集数据来提供特征重要性。本技术的发明人发现treeinterpreter方法只可以给出随机森林模型预测结果的特征值的贡献度。
57.本技术的发明人发现目前的故障预测技术缺模型可解释性分析,无法针对模型给出的预测结果,给出导致预测结果的原因。所以可能导致无法根据预测结果采取针对性的运维处理。
58.treeinterpreter方法缺少特征值占比和可视化呈现,不利于用户读取和理解信息。
59.问题3,在训练故障预测模型中,本技术的发明人发现目前的特征构造方法仅仅是计算相邻样本数据的一阶/二阶差分值。
60.一阶差分值计算:
61.△
y(x)=y(x 1)-y(x)
ꢀꢀꢀ
公式1
62.二阶差分值计算:
63.△
(
△
y(x))=
△
(y(x 1)-y(x))=
△
y(x 1)
‑△
y(x)
ꢀꢀꢀ
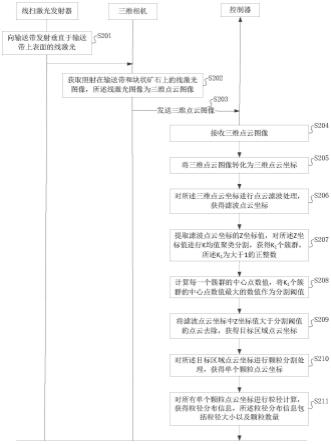
公式2
64.本技术的发明人发现相邻样本数据的一阶/二阶差分值无法表征历史时间窗口内样本数据的增强趋势。因为故障盘的故障时间可能发生在特征值非增长的时间段(一阶/二阶差分值为0的时间段),所以仅采用目前的特征构造方法无法有些预测此类故障,可能会影响模型分类效果。
65.针对上述问题,本技术实施例提供了一种故障预测方法及相关装置,通过该方法可以对将预设滑窗内的每个样本数据的一阶差分值的累加和作为样本特征,从而可以得到多个样本特征。然后从多个样本特征中划分得到正样本特征和负样本特征,其中,正样本特征包括多个样本数据中的故障数据的特征和第一部分亚健康数据的特征,第一部分亚健康数据的特征与故障数据的特征的相似度大于第一阈值,负样本特征包括多个样本数据中的健康数据和第二部分亚健康数据,第二部分亚健康数据的特征与故障数据的特征的相似度小于第二阈值。再然后,根据正样本特征和负样本特征训练得到故障预测模型。基于故障预测模型预测得到目标数据的预测结果;根据预测结果确定导致预测结果的原因,并且输出预测结果,导致预测结果的原因,以及导致预测结果的各个原因的重要性占比。
66.请参见图1,图1是本技术实施例提供的一种故障预测系统的结构示意图,该故障预测系统100包括数据采集模块101、预处理模块102、特征提取模块103、模型训练模块104和故障预测模块105,其中:
67.数据采集模块101用于采集和统计来自电子设备的数据,该数据为用于模型训练的样本数据,其中,样本数据可能存在正样本和负样本分布不均衡的情况。比如,若样本数据为ssd硬盘的数据,可能存在故障硬盘数据很少,而非故障硬盘数据很多,也即正样本数据很少,负样本数据很多。其中,电子设备可以是具有数据存储能力的设备,可以是实体存储设备,例如内存(包括随机存储记忆体(random access memory,ram)、只读存储器(read-only memory,rom)、可擦除可编程只读存储器(erasable programmable read only memory,eprom)等),再如磁盘(包括便携式随机存储器(compact disc random access memory,cd-ram)、固态硬盘(solid state drive,ssd)等),也可以是其他具有数据存储能力的电子设备,例如网络附属存储(network attached storage,nas)服务器等,还可以是虚拟存储设备,例如虚拟机、容器等等。
68.预处理模块102用于对数据采集模块101采集的样本数据进行预处理。进一步的,预处理可以包括:整理样本数据的数据格式,筛选出故障数据的列表,对多个样本数据中的故障数据进行标注,以及根据故障时间对故障数据进行标注等处理方式。
69.特征提取模块103用于构造滑窗累积差分特征,具体的,按照预设滑窗获取多个所述预设滑窗内的每个样本数据的差分值;对多个预设滑窗内的每个样本数据的差分值分别进行求和,从而可以得到多个样本特征。需要说明的是,差分值可以是一阶差分值,也可以是二阶差分值,本技术实施例不做任何限制。
70.模型训练模块104是具有数据处理能力和数据收发能力的电子设备,可以是体设备如主机、机架式服务器、刀片式服务器等,也可以是虚拟设备如虚拟机、容器等,从多个样本数据中划分得到正样本数据和负样本数据,其中,正样本数据包括多个样本数据中的故障数据和第一部分亚健康数据,第一部分亚健康数据的特征与故障数据的特征的相似度大于第一阈值,负样本数据包括多个样本数据中的健康数据和第二部分亚健康数据,第二部
分亚健康数据的特征与故障数据的特征的相似度小于第二阈值。然后,模型训练模块104还可以根据划分得到的正样本数据和负样本数据训练得到故障预测模型。
71.故障预测模块105是具有数据处理能力和数据收发能力的电子设备,可以是实体设备如主机、机架式服务器、刀片式服务器等,也可以是虚拟设备如虚拟机、容器等,用于基于训练的故障预测模型预测得到目标数据的预测结果,然后再根据预测结果确定预测结果的多个原因,并且输出预测结果,多个原因,以及预测结果的各个原因的重要性占比。
72.可选的,故障预测模块105可以和数据采集模块101、预处理模块102、特征提取模块103、模型训练模块104可以是一个设备,也可以是某设备中的一个模块,还可以是多个设备组成的设备集群。例如,故障预测模块105可以部署在需要进行故障预测的一个或多个设备中,但是,需要进行故障预测的设备可以是数据采集模块101、预处理模块102、特征提取模块103、模型训练模块104所部署的设备,也可以不是数据采集模块101、预处理模块102、特征提取模块103、模型训练模块104所部署的设备。
73.请参见图2,图2是本技术实施例提供的一种故障预测的场景示意图。从图2可以看出,场景20包括特征提取20a、模型训练20b和故障分析20c。其中,特征提取20a中包括数据收集模块200、故障标注模块201、特征提取模块202和特征选择模块203;模型训练20b包括样本数据划分模块204和模型训练模块205;故障分析20c包括故障预测模块206和分析模块207。
74.数据收集模块200,用于收集用于模型训练的样本数据,其中,样本数据可以包括一个或多个电子设备每一天的运行数据。其中,电子设备可以是具有数据存储能力的设备,可以是实体存储设备,例如内存(包括随机存储记忆体(random access memory,ram)、只读存储器(read-only memory,rom)、可擦除可编程只读存储器(erasable programmable read only memory,eprom)等),再如磁盘(包括便携式随机存储器(compact disc random access memory,cd-ram)、固态硬盘(solid state drive,ssd)等),也可以是其他具有数据存储能力的电子设备,例如网络附属存储(network attached storage,nas)服务器等,还可以是虚拟存储设备,例如虚拟机、容器等等。
75.故障标注模块201,用于对样本数据中的故障数据进行标注。进一步的,可以根据故障时间对样本数据中的故障数据进行标注。可以理解的是,故障数据来自发生故障的电子设备。
76.特征提取模块202,用于构造样本特征。进一步的,按照预设滑窗获取多个所述预设滑窗内的每个样本数据的差分值;对多个预设滑窗内的每个样本数据的差分值分别进行求和,从而可以得到多个样本特征。需要说明的是,差分值可以是一阶差分值,也可以是二阶差分值,本技术实施例不做任何限制。
77.特征选择模块203,基于特征相关性和特征重要性从多个样本特征中筛选用于模型训练的样本特征。
78.样本数据划分模块204,用于从多个样本数据中划分得到正样本数据和负样本数据,其中,正样本数据包括多个样本数据中的故障数据和第一部分亚健康数据,第一部分亚健康数据的特征与故障数据的特征的相似度大于第一阈值,负样本数据包括多个样本数据中的健康数据和第二部分亚健康数据,第二部分亚健康数据的特征与故障数据的特征的相似度小于第二阈值。
79.模型训练模块205,用于根据划分得到的正样本数据和负样本数据,以及多个样本特征来训练故障预测模型。进一步的,基于随机森林算法训练故障预测模型。
80.故障预测模块206,用于基于训练的故障预测模型预测得到目标数据的预测结果。其中,目标数据为每天收集的目标设备的数据。
81.分析模块207,用于再根据预测结果确定预测结果的多个原因,并且输出预测结果,多个原因,以及预测结果的各个原因的重要性占比。
82.可选的,数据收集模块200、故障标注模块201、提取模块202和特征选择模块203可以是一个设备,也可以是某设备中的一个模块,还可以是多个设备组成的设备集群。样本数据划分模块204和模型训练模块205可以是一个设备,也可以是某设备中的一个模块,还可以是多个设备组成的设备集群。故障预测模块206和分析模块207可以是一个设备,也可以是某设备中的一个模块,还可以是多个设备组成的设备集群。
83.请参见图3,图3是本技术实施例提供的一种故障预测方法的流程示意图,进一步的,该方法可基于图1所示的框架来实现,该方法包括但不限于如下步骤:
84.步骤s301:提取样本特征。
85.具体地,在提取样本数据的样本特征之前,需要对样本数据进行预处理,比如说数据清理、数据集成、数据变换和数据归约中的一种或多种。并且还需要对样本数据中的故障数据进行标注,可以理解的是,故障设备的数据被标记为故障数据,非故障设备的数据被标记为非故障数据。比如说,当某一电子设备或电子设备中的某一功能模块发生故障导致不能正常工作时,发生故障的设备会被记录在故障列表中,故障列表包括故障时间、故障设备等信息。通过故障列表可以查找出样本数据中的故障数据,并根据故障时间对样本数据中的故障数据进行标注。需要说明的,故障数据不仅仅包括发生故障当天的数据,还包括发生故障之前的数据。
86.然后,由特征提取模块来提取样本数据的多个样本特征。进一步的,特征提取模块按照预设滑窗(滑动窗口)获取多个预设滑窗内的每个样本数据的差分值,然后对多个预设滑窗内的每个样本数据的差分值分别进行求和,从而可以得到多个样本特征。进一步的,还可以对多个样本特征按照大小进行排序,从排序后的样本特征中可以获取预设窗口内的变化趋势,故障数据的变化趋势可以是增长趋势。需要说明的是,预设滑窗可以按照实际需求来选择合适的值,本技术实施例不做任何限制。
87.举例来说,若采集的样本数据为ssd硬盘的s.m.a.r.t数据和i/o数据,可以将每一天的ssd硬盘的s.m.a.r.t数据和i/o数据作为一个子集,假如采集的数据为m天内的数据,则样本数据可以包括m个子集。首先,需要分别计算m个子集的差分值。若预设滑窗为n天,n为小于m的正整数,则以n天为滑动窗口对m个子集进行划分得到p个集合,分别获取p个集合中的每个子集的差分值,将集合中的每个子集的差分值进行求和,则差分值的累加和可以作为样本特征,因为有p个集合,从而可以得到p个样本特征。
88.可以理解的是,s.m.a.r.t数据属于硬盘有异常发生的时候可能发出的警告信息,随着时间的推移,当硬盘发生异常的频率越多,警告信息也会越多,从而可能导致硬盘的故障。因此,故障数据的变化趋势可以是增长趋势。
89.在一种可能的实现方式中,当从多个样本数据中提取出多个样本特征后,需要根据特征相关性和特征重要性来选择模型训练所需要的样本特征。也即,通过自动或手动选
择可能对模型的质量提供贡献的特征。特征选择是剔除那些不相关的、可能会降低模型精度和质量的特征的过程。特征相关性,是一种理解数据集中多个变量和属性之间关系的方法,使用相关性,可以得到一个或多个属性依赖于另一个属性或是另一个属性的原因,以及一个或多个属性与其他属性相关联。特征重要性,可以提供数据中每个特征的得分,得分越高,该特征对输出变量的重要性或相关性就越高。
90.需要说明的是,差分值可以为一阶差分值,也可以为二阶差分值,本技术实施例不做任何限制。
91.步骤s302:从多个样本数据中划分得到正样本数据和负样本数据。
92.具体地,因为采集到的样本数据存在正负样本不均衡的问题,所以模型训练模块需要对样本数据重新进行划分,得到用于训练模型的正样本数据和负样本数据。划分得到的正样本数据包括多个样本数据中的故障数据和第一部分亚健康数据,第一部分亚健康数据的特征和故障数据的特征的相似度大于第一阈值;负样本数据包括多个样本数据中的健康数据和第二部分亚健康数据,第二部分亚健康数据的特征与所述故障数据的特征的相似度小于第二阈值。需要说明的是,第一阈值和第二阈值可能相等,也可能不相等。第一阈值和第二阈值可以是根据经验人为设定的一个用于参考对比的值,或者为根据多个历史值进行训练(或学习)得到的一个用于参考对比的值。因此,不同的场景所对应的第一阈值或第二阈值也不相同。
93.在一种可能的实现方式中,特征值为0或者特征值趋向为0可以表明预设滑窗内的差分值的累加和没有异常变化,也即每一天采集的数据波动不大,处于平稳的状态。比如,趋向为0具体是指与0的差值的绝对值小于第五阈值,该第五阈值可以是人为设置的一个较小的值,比如0.1,再如,0.05,本技术实施例对第五阈值的取值不做任何限制。
94.举例来说,若采集的样本数据为一段时间内每一天的ssd硬盘的s.m.a.r.t数据,s.m.a.r.t数据记录了硬盘出现异常时的数据,比如说硬盘不可纠正错误计数、新增坏块数、块编程错误计数等信息。可以看出,当采集的样本数据在预设滑窗内没有异常数据或者异常数据处于不增长状态(差分值为0或者趋向为0)时,提取的特征值可以为0或者特征值趋向可以为0,可以将此部分数据标记为健康数据。然后,模型训练模块可以对健康数据和多个样本数据(可以是采集到的样本数据中不包含故障数据和/或健康数据的数据)进行特征相似度分析,将上述多个样本数据中与健康数据的特征相似度小于第三阈值的数据标记为亚健康数据。模型训练单元可以通过距离计算、聚类方法中一种或多种来进行特征相似度分析。举例来说,可以采用明可夫斯基距离(minkowski dinstance),也被称为明氏距离,或者闵氏距离。两个i维变量u=(u1,u2,u3,
…
,ui)和v=(v1,v2,v3,
…
,vi)间的明氏距离定义为:
95.(∑(|wi(u
i-vi)|
p
))
1/p
ꢀꢀꢀ
公式3
96.其中,p是一个变参数。当p=1时,即为曼哈顿距离;当p=2时,即为欧式距离,当p取无穷时,即为切比雪夫距离。v表示健康数据,u表示多个样本数据,u具体可以是多个样本数据中不包含健康数据和/故障数据的数据。通过公式3可以对健康数据和上述多个样本数据进行特征相似度分析,也即可以计算得到健康数据和多个样本数据之间的距离(特征相似度),对计算得到的距离进行排序,然后从排序后的距离中选择小于或者小于等于第三阈值的数据标记为亚健康数据。需要说明的是,第三阈值为根据经验人为设定的一个用于参
考对比的值,或者为根据多个历史值进行训练(或学习)得到的一个用于参考对比的值,本技术实施例对第三阈值不做任何限制。
97.在一种可能的实现方式中,模型训练模块可以通过pca方法从多个样本数据中划分得到健康数据和亚健康数据。具体的,模型训练模块通过pca方法将多个样本数据(可以是不包含故障数据的数据)映射到低维特征空间,记上述样本数据x=(x1,x2,x3,
…
,xi),计算协方差矩阵c=x
t
x,x
t
代表转置向量,然后求解协方差矩阵c的特征值λ1,λ2,
……
,λj,以及特征向量e1,e2,
……
,ej。计算每个数据xi在主成分ej上的偏离程度通过计算得到样本数据的分值,然后将样本数据的分值按照大小排序构成分值集合。将分值集合中分值为0或者分值趋向为0对应的样本数据标记为健康数据,将分值集合中小于第三阈值的分值对应的样本数据标记为亚健康数据。需要说明的是,第三阈值为根据经验人为设定的一个用于参考对比的值,或者为根据多个历史值进行训练(或学习)得到的一个用于参考对比的值,本技术实施例对第三阈值不做任何限制。
98.在确定出目标亚健康数据之后,模型训练单元将目标亚健康数据与故障数据进行特征相似度比较,将目标亚健康数据中与故障数据的特征相似度大于第一阈值的数据标记为第一部分亚健康数据,将目标亚健康数据中与故障数据之间的特征相似度小于第二阈值的数据标记为第一部分亚健康数据。举例来说,可以通过mann-kendall增长趋势算法,使用统计学中的假设检验方法。在mann-kendall检验中,原假设y0为目标亚健康数据y=(y1,y2,y3,
…
,yi),是n个独立的,随机变量同分布的样本;备择假设y1是双边检验。定义检验统计量s:
[0099][0100]
其中,yj和yk为不同时刻点的数据,sgn(y
j-yk)为指示函数,根据y
j-yk的正负号取值为1,0,-1。
[0101]
mann-kendall统计量公式s大于、等于、小于零时分别为:
[0102][0103]
在双边检验中,衡量趋势大小的指标为1《k《j《i,正的β表示“上升趋势”,负的β表示“下降趋势”。对于给定的置信水平α,原假设y0:β=0,当|z
mk
|》z
1-α
时,拒绝原假设,即在置信水平α上,数据存在上升或下降趋势。因为故障数据的变化趋势可以是增长趋势,所以模型训练单元将目标亚健康数据中存在明显上升趋势的数据与故障数据进行比较,将存在上升趋势的数据中与故障数据的特征相似度大于所述第一阈值的目标亚健康数据标记为第一部分亚健康数据,将存在上升趋势的数据中与故障数据的特征相似度小于第二阈值的目标亚健康数据标记为第二部分亚健康数据。
[0104]
最后,模型训练单元可以将故障数据和第一部分亚健康数据标记为正样本数据,将健康数据和第二部分亚健康数据标记为负样本数据。
[0105]
步骤s303:根据正样本数据和负样本数据训练得到故障预测模型。
[0106]
具体地,当对采集到的样本数据进行重新划分得到正样本数据和负样本数据之后,模型训练模块可以基于构造的样本特征、正样本数据和负样本数据训练得到故障预测模型。进一步的,基于下采样方法分别从正样本数据和负样本数据中选择训练数据,然后将剩余样本数据作为验证/测试数据。进一步的,故障预测模型可以为随机森林模型。
[0107]
步骤s304:基于故障预测模型对目标数据进行分析。
[0108]
具体地,当某一设备或某一设备的模块需要进行故障分析时,故障预测模块可以基于故障预测模型对目标数据进行分析,目标数据可以是上述设备或上述设备的模块的数据。基于预测模型对目标数据进行分析可以得到上述设备或者上述设备的模块是否故障,以及在哪一天可能出现故障。当预测结果为设备可能在某一天(比如说14天后)出现故障时,基于故障预测模型分析目标数据的预测结果,根据预测结果确定预测结果的多个原因,然后故障预测模块可以输出预测结果、多个原因、以及预测结果的各个原因的重要性占比。进一步的,故障预测模块可以可视化呈现出预测结果、多个原因、以及预测结果的各个原因的重要性占比。因此,可以对设备提前(比如说提前14天)预警,根据预测结果的多个原因有计划地执行运维策略,避免因上设备或上述设备的模块突然出现故障导致客户业务的可用性和客户体验受影响。
[0109]
在一种可能的实现方式中,故障预测模型为随机森林模型,当故障预测模块基于故障预测模型分析目标数据得到故障结果时,故障预测模块可以根据预测结果从故障预测模型中选择预测结果对应的决策树。在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出是由个别树输出的类别的众数而定。在决策树模型中,在每个决策节点上,选择最佳的特征进行分割,以便进一步区分到达该决策节点的样本。在每一次分割中,都可以更接近最终的决定(即叶节点)。因此,在每个决策节点上,所选择的分割特征决定了最终的预测结果。所以,故障预测模块可以获取决策树对应的决策路径上的分裂特征,并将分裂特征作为导致预测结果的原因。可以理解的是,可以是多个分裂特征的共同作用而产生的预测结果。进一步的,多个分裂特征所形成的组合可以表示为产生预测结果的故障模式。然后,故障预测模块可以对多个分裂特征进行计数、排序、归一化计算得到多个特征重要性和对应的重要性占比,重要性占比可以是该分裂特征在多个分裂特征中所占得比例。进一步的,可以选择多个特征重要性中的前m个作为预测结果的原因。
[0110]
需要说明的是,本技术实施例所提及的特征值,可以理解为特征向量。
[0111]
图3所描述的方法中,样本数据重新进行划分得到正样本数据和负样本数据,其中,正样本数据中包括样本数据总的故障数据和一部分亚健康数据,此部分亚健康数据是与故障数据具有相似度的数据;负样本数据包括样本数据中的健康数据和一部分亚健康数据,此部分亚健数据是与故障数据相似度比较低的数据。相对于现有的将故障数据作为负样本数据以及将非故障数据作为正样本数据的划分方式而言,通过这种方法,可以对样本数据重新进行划分来有效解决正负样本不均衡问题,基于上述正样本数据和负样本数据可以更好的对模型进行训练,提高模型预测的准确性。
[0112]
上述详细阐述了本技术实施例的方法,下面提供了本技术实施例的装置。
[0113]
请参见图4,图4是本技术实施例提供的一种故障预测装置400的结构示意图,该故障预测装置400可以是设备节点,也可是设备节点中的一个模块,例如芯片或者集成电路等、该故障预测装置400用于实现前述的故障预测方法,如图3所示的实施例描述的故障预
测方法。
[0114]
进一步的,该故障预测装置400可以包括样本划分单元401,训练单元402,特征单元403和预测分析单元404,其中,各个单元的详细描述如下:
[0115]
样本划分单元401,用于从多个样本数据中划分得到正样本数据和负样本数据,其中,正样本数据包括多个样本数据中的故障数据和第一部分亚健康数据,第一部分亚健康数据的特征与故障数据的特征的相似度大于第一阈值,负样本数据包括多个样本数据中的健康数据和第二部分亚健康数据,第二部分亚健康数据的特征与故障数据的特征的相似度小于第二阈值;
[0116]
训练单元402,用于根据正样本数据和负样本数据训练得到故障预测模型,其中,故障预测模型用于分析目标数据。
[0117]
在本技术实施例中,对样本数据重新进行划分得到正样本数据和负样本数据,其中,正样本数据中包括样本数据总的故障数据和一部分亚健康数据,此部分亚健康数据是与故障数据具有相似度的数据;负样本数据包括样本数据中的健康数据和一部分亚健康数据,此部分亚健数据是与故障数据相似度比较低的数据。相对于现有的将故障数据作为负样本数据以及将非故障数据作为正样本数据的划分方式而言,通过这种方法,可以对样本数据重新进行划分来有效解决正负样本不均衡问题,基于上述正样本数据和负样本数据可以更好的对模型进行训练,提高模型预测的准确性。在一种可能的实施方式中,特征单元403,用于按照预设滑窗获取多个预设滑窗内的每个样本数据的差分值;对多个预设滑窗内的每个样本数据的差分值分别进行求和,得到多个样本特征。
[0118]
可以看出,通过预设滑窗所提取的样本特征可以反应到一定时间窗口内的信息,便于对样本数据进行更好的划分。
[0119]
在一种可能的实施方式中,样本划分单元401,具体用于:从多个样本数据中确定目标亚健康数据,其中,目标亚健康数据的特征与健康数据的特征的相似度小于第三阈值;将目标亚健康数据中与故障数据的特征相似度大于第一阈值的目标亚健康数据标记为第一部分亚健康数据;将目标亚健康数据中与故障数据的特征相似度小于第二阈值的目标亚健康数据标记为第二部分亚健康数据;将故障数据和第一部分亚健康数据标记为正样本数据;将健康数据和第二部分亚健康数据标记为负样本数据。
[0120]
可以看出,首先从样本数据中确定目标亚健康数据,然后将目标亚健康数据中与故障数据具有相似度的数据标记为第一部分亚健康数据,将第一部分亚健康数据归类为正样本数据,对原本只包含故障数据的正样本数据进行了扩充;将目标亚健康数据中与故障数据不太具有相似度的数据标记为第二部分亚健康数据,将第二部分亚健康数据和健康数据归类为负样本数据。通过本方法可以对样本数据进行更好的划分,使得划分得到的正负样本数据达到均衡的状态。
[0121]
在一种可能的实施方式中,样本划分单元401,具体用于:将多个样本数据中特征值为0或者特征值趋向为0的数据标记为健康数据;对健康数据和多个样本数据进行特征相似度分析,将多个样本数据中与健康数据的特征相似度小于第三阈值的数据标记为亚健康数据。
[0122]
可以看出,首先从样本数据中确定健康数据,然后将样本数据中与健康数据不太具有相似度的数据标记为目标亚健康数据。至此,样本数据被划分为故障数据、目标亚健康
数据和故障数据。而目标亚健康数据可以认为是划分故障数据和健康数据的边界。
[0123]
在一种可能的实施方式中,预测分析单元404,用于基于故障预测模型分析目标数据的预测结果;根据预测结果确定预测结果的多个原因;输出预测结果、多个原因、以及预测结果的各个原因的重要性占比。
[0124]
可以看出,基于故障预测模型不仅可以输出预测结果,还可以输出预测结果的多个原因,以及各个原因的重要性占比。因此,根据预测结果的多个原因可以对运维操作提供指导,便于进行有针对性的维护。
[0125]
在一种可能的实施方式中,预测分析单元404,用于根据预测结果从故障预测模型中选择预测结果对应的决策树;获取决策树对应的决策路径上的分裂特征,分裂特征为导致预测结果的原因。
[0126]
可以看出,基于故障预测模型来确定分裂特征,将分裂特征作为预测结果的原因,具有可信度。
[0127]
在一种可能的实施方式中,正样本数据和负样本数据为根据增长趋势分析、距离计算和聚类方法中的一种或多种从多个样本数据中划分得到的。
[0128]
可以看出,可以通过不同的分类方法对样本数据进行分类,分类方法更加丰富,可选择性更高。
[0129]
在一种可能的实施方式中,故障预测模型为随机森林模型。
[0130]
需要说明的是,各个单元的实现还可以对应参照图3所示的方法实施例的相应描述。
[0131]
请参见图5,图5是本技术实施例提供的一种故障预测设备的结构示意图,该故障预测设备500包括至少一个处理器501、至少一个存储器502和通信接口503。可选的,还可以包含总线504,其中,处理器501、存储器502和通信接口503通过总线504相互连接。
[0132]
其中,存储器502用于提供存储空间,存储空间中可以存储操作系统和计算机程序等数据。存储器502包括但不限于是随机存储记忆体(random access memory,ram)、只读存储器(read-only memory,rom)、可擦除可编程只读存储器(erasable programmable read only memory,eprom)、或便携式只读存储器(compact disc read-only memory,cd-rom)等等。
[0133]
处理器501是进行算术运算和/或逻辑运算的模块,具体可以是中央处理器(central processing unit,cpu)、图片处理器(graphics processing unit,gpu)、微处理器(microprocessor unit,mpu)、专用集成电路(application specific integrated circuit,asic)、现场可编程逻辑门阵列(field programmable gate array,fpga)、复杂可编程逻辑器件(complex programmable logic device,cpld)等处理模块中的一种或者多种的组合。
[0134]
通信接口503用于接收外部发送的数据和/或向外部发送数据,可以为包括诸如以太网电缆等的有线链路接口,也可以是无线链路(wi-fi、蓝牙、通用无线传输、车载短距通信技术等)接口。可选的,通信接口503还可以包括与接口耦合的发射器(如射频发射器、天线等),或者接收器等。
[0135]
该故障预测设备500中的处理器501用于读取存储器502中存储的计算机程序代码,执行以下操作:
[0136]
从多个样本数据中划分得到正样本数据和负样本数据,其中,正样本数据包括多个样本数据中的故障数据和第一部分亚健康数据,第一部分亚健康数据的特征与故障数据的特征的相似度大于第一阈值,负样本数据包括多个样本数据中的健康数据和第二部分亚健康数据,第二部分亚健康数据的特征与故障数据的特征的相似度小于第二阈值;根据正样本数据和负样本数据训练得到故障预测模型,其中,故障预测模型用于分析目标数据。
[0137]
在本技术实施例中,对样本数据重新进行划分得到正样本数据和负样本数据,其中,正样本数据中包括样本数据总的故障数据和一部分亚健康数据,此部分亚健康数据是与故障数据具有相似度的数据;负样本数据包括样本数据中的健康数据和一部分亚健康数据,此部分亚健数据是与故障数据相似度比较低的数据。相对于现有的将故障数据作为负样本数据以及将非故障数据作为正样本数据的划分方式而言,通过这种方法,可以对样本数据重新进行划分来有效解决正负样本不均衡问题,基于上述正样本数据和负样本数据可以更好的对模型进行训练,提高模型预测的准确性。
[0138]
在一种可能的实施方式中,处理器501,还用于:按照预设滑窗获取多个预设滑窗内的每个样本数据的差分值;对多个预设滑窗内的每个样本数据的差分值分别进行求和,得到多个样本特征。
[0139]
可以看出,通过预设滑窗所提取的样本特征可以反应到一定时间窗口内的信息,便于对样本数据进行更好的划分。
[0140]
在一种可能的实施方式中,处理器501,具体用于:从多个样本数据中确定目标亚健康数据,其中,目标亚健康数据的特征与健康数据的特征的相似度小于第三阈值;将目标亚健康数据中与故障数据的特征相似度大于第一阈值的目标亚健康数据标记为第一部分亚健康数据;将目标亚健康数据中与故障数据的特征相似度小于第二阈值的目标亚健康数据标记为第二部分亚健康数据;将故障数据和第一部分亚健康数据标记为正样本数据;将健康数据和第二部分亚健康数据标记为负样本数据。
[0141]
可以看出,首先从样本数据中确定目标亚健康数据,然后将目标亚健康数据中与故障数据具有相似度的数据标记为第一部分亚健康数据,将第一部分亚健康数据归类为正样本数据,对原本只包含故障数据的正样本数据进行了扩充;将目标亚健康数据中与故障数据不太具有相似度的数据标记为第二部分亚健康数据,将第二部分亚健康数据和健康数据归类为负样本数据。通过本方法可以对样本数据进行更好的划分,使得划分得到的正负样本数据达到均衡的状态。
[0142]
在一种可能的实施方式中,处理器501,具体用于:将多个样本数据中特征值为0或者特征值趋向为0的数据标记为健康数据;对健康数据和多个样本数据进行特征相似度分析,将多个样本数据中与健康数据的特征相似度小于第三阈值的数据标记为亚健康数据。
[0143]
可以看出,首先从样本数据中确定健康数据,然后将样本数据中与健康数据不太具有相似度的数据标记为目标亚健康数据。至此,样本数据被划分为故障数据、目标亚健康数据和故障数据。而目标亚健康数据可以认为是划分故障数据和健康数据的边界。
[0144]
在一种可能的实施方式中,处理器501,还用于:基于故障预测模型分析目标数据的预测结果;根据预测结果确定预测结果的多个原因;输出预测结果、多个原因、以及预测结果的各个原因的重要性占比。
[0145]
可以看出,基于故障预测模型不仅可以输出预测结果,还可以输出预测结果的多
个原因,以及各个原因的重要性占比。因此,根据预测结果的多个原因可以对运维操作提供指导,便于进行有针对性的维护。
[0146]
在一种可能的实施方式中,处理器501,还用于:根据预测结果从故障预测模型中选择预测结果对应的决策树;获取决策树对应的决策路径上的分裂特征,分裂特征为导致预测结果的原因。
[0147]
可以看出,基于故障预测模型来确定分裂特征,将分裂特征作为预测结果的原因,不需要人为去寻找原因,更加便捷具有可信度。
[0148]
在一种可能的实施方式中,处理器501,还用于:正样本数据和负样本数据为根据增长趋势分析、距离计算和聚类方法中的一种或多种从多个样本数据中划分得到的。
[0149]
可以看出,可以通过不同的分类方法对样本数据进行分类,分类方法更加丰富,可选择性更高。
[0150]
在一种可能的实施方式中,故障预测模型为随机森林模型。
[0151]
需要说明的是,各个操作的实现还可以对应参照图3所示的方法实施例的相应描述。
[0152]
本技术实施例还提供一种芯片系统,所述芯片系统包括至少一个处理器,存储器和接口电路,所述存储器、所述收发器和所述至少一个处理器通过线路互联,所述至少一个存储器中存储有计算机程序;所述计算机程序被所述处理器执行时,图3所示的方法流程得以实现。
[0153]
本技术实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当计算机程序在一个或多个处理器上运行时,图3所示的方法流程得以实现。
[0154]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。该计算机程序产品包括一个或多个计算机程序。在计算机上加载和执行该计算机程序指令时,可以全部或部分地实现本技术实施例所描述的流程或功能。该计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。该计算机程序可以存储在计算机可读存储介质中,或者通过计算机可读存储介质进行传输。该计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如,固态硬盘(solid state disk,ssd))等。
[0155]
本技术方法实施例中的步骤可以根据实际需要进行顺序调整、合并和删减。
[0156]
本技术装置实施例中的模块可以根据实际需要进行合并、划分和删减。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。