1.本公开涉及集成电路(ic),更具体地,涉及分布在ic的多个裸片上的存储器和计算阵列之间的数据传输。
背景技术:
2.神经网络处理器(nnp)是指一种集成电路(ic),其具有一个或多个能够实现神经网络的计算阵列。计算阵列从存储器中输入数据,例如神经网络实现的权重。计算阵列通过多个存储器通道并行地从存储器输入权重。从存储器到计算阵列的数据传输通常会受到偏斜(skew)的影响。因此,数据在不同时间到达计算阵列的不同部分。数据偏斜至少部分地是由于并行操作时存储器通道之间的独立性,并且在具有分布在多个裸片上的计算阵列的多芯片集成电路的情况下,来自每个存储器通道的数据波前与多芯片集成电路中的计算阵列正交。无论是单独看还是累积看,这些问题都会使从存储器到计算阵列的数据传输变得不可预测,并导致存储器中可用带宽的使用低效和/或降级。
技术实现要素:
3.示例实现方案包括集成电路(ic)。集成电路包括多个裸片。ic包括被配置为与存储器通信的多个存储器通道接口,其中所述多个存储器通道接口被设置在所述多个裸片中的第一裸片内。ic可以包括分布在多个裸片上的计算阵列和分布在多个裸片上的多个远程缓冲器。多个远程缓冲器被耦接到多个存储器通道和计算阵列。ic还包括控制器,其被配置为确定多个远程缓冲器中的每一个都已经有数据存储在其中,并且作为响应,将读取使能信号广播到多个远程缓冲器中的每一个,以启动从多个远程缓冲器到在多个裸片的计算阵列的数据传输。
4.另一个示例实现包括控制器。控制器被设置在具有多个裸片的ic内。该控制器包括请求控制器,其被配置为将访问存储器的第一请求转换为兼容片上通信总线的第二请求,其中该请求控制器将第二请求提供给被配置为从存储器的多个通道接收数据的多个请求缓冲器-总线主电路块。控制器还包括远程缓冲器读取地址生成单元,其被耦接到请求控制器并被配置为监控分布在多个裸片上的多个远程缓冲器中的每个远程缓冲器中的填充水平。多个远程缓冲器中的每个远程缓冲器被配置为将从多个请求缓冲器-总线主电路块的相应的一个中获得的数据提供给分布在多个裸片上的计算阵列。响应于确定多个远程缓冲器中的每个远程缓冲器正在基于填充水平存储数据,远程缓冲器读取地址生成单元被配置为发起从多个远程缓冲器中的每个远程缓冲器到在多个裸片到计算阵列的数据传输。
5.另一个示例实现方案包括一种方法。所述方法包括监控分布在多个裸片上的多个远程缓冲器中的填充水平,其中多个远程缓冲器中的每个远程缓冲器被配置为向也分布在多个裸片上的计算阵列提供数据,确定每个多个远程缓冲器中的远程缓冲器基于填充水平存储数据,并且响应于该确定,发起从多个远程缓冲器中的每个远程缓冲器到在多个裸片到计算阵列的数据传输。
6.提供本概述部分仅是为了介绍某些概念,而不是为了确认要求保护的主题的任何关键或基本特征。根据附图和以下详细描述,本发明装置的其他特征将是显而易见的。
附图说明
7.本发明的布置在附图中以示例的方式示出。然而,附图不应被解释为将本发明的布置仅限于所示的特定实施方式。通过阅读以下详细描述并参考附图,各个方面和优点将变得显而易见。
8.图1图示了在集成电路(ic)内实现的电路架构的示例平面图;
9.图2图示了图1的电路架构的示例实现;
10.图3图示了图1的电路架构的另一个示例实现;
11.图4图示了用于实现图1的电路架构的平衡树状结构的示例;。
12.图5图示了如本文公开中描述的请求缓冲总线主机(rbbm)电路块的示例实现;
13.图6图示了主控制器的示例实现;
14.图7图示了请求控制器的示例实现;
15.图8图示了在高带宽存储器和分布式计算阵列之间传输数据的示例方法;
16.图9示出了ic的示例架构。
具体实施方式
17.尽管本公开以定义新颖特征的权利要求书结束,但相信通过结合附图对描述的考虑将更好地理解在本公开中描述的各种特征。出于说明的目的,提供了本文描述的过程、机器、制造及其任何变体。在本公开中描述的具体结构和功能细节不应被解释为限制性的,而仅仅是作为权利要求的基础和作为教导本领域技术人员以不同方式使用在几乎任何适当详细结构中描述的特征的代表性基础。此外,在本公开中使用的术语和短语并非旨在限制,而是提供对所描述的特征的可理解描述。
18.本公开涉及集成电路(ic),更具体地,涉及分布在ic的多个裸片上的存储器和计算阵列之间的数据传输。神经网络处理器(nnp)是指一种具有一个或多个能够实现神经网络的计算阵列的集成电路。在ic是多裸片ic的情况下,ic可以实现分布在多裸片ic的两个或更多个裸片上的单个更大的计算阵列。与不同裸片中的多个较小的独立计算阵列相比,以分布式形式在多个裸片实现单个较大的计算阵列提供了某些好处,包括但不限于改进的延迟、改进的权重存储容量、和改进的计算效率。
19.从高带宽存储器或hbm向计算阵列输入数据,例如神经网络的权重。出于描述的目的,由存储器通道访问的存储器在整个本公开中被称为“高带宽存储器”或“hbm”,以更好地区别于电路架构中的其他类型的存储器,例如缓冲器和/或队列。然而,应当理解,hbm可以使用多种不同技术中的任一种来实现,这些技术支持多个独立和并行的存储器通道,这些通道在通信上链接到通过合适的存储器控制器描述的示例电路架构。hbm的示例可以包括各种ram类型存储器中的任何一种,其包括双倍数据速率ram或其他合适的存储器。
20.尽管计算阵列被分布在ic的多个裸片上,但它被hbm看作为将权重通过可用的存储器通道并行输入到其上的单个计算阵列。例如,计算阵列可以实现为一个阵列,其中每个裸片实现计算阵列的一个或多个行。每个存储器通道可以向计算阵列的一行或多个行提供
数据。
21.在单个计算阵列分布在多个裸片上的情况下,从hbm到计算阵列的数据传输通常会遇到时序问题。例如,每个存储器通道通常都有自己独立的控制引脚、异步时钟、和刷新睡眠模式。这些特性会导致在存储器通道的数据偏斜。结果,计算阵列的不同行通常在不同时间接收数据。由于计算阵列的不同行位于ic的不同裸片上,因此与hbm的距离不同,数据偏斜被进一步地加剧。例如,来自存储器通道的数据波前(例如,数据传播)与ic中的计算阵列正交。这些问题导致从hbm到计算阵列的数据传输整体的不可预测性。
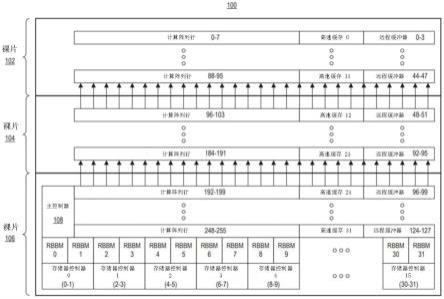
22.根据在本公开中描述的创造性布置,提供了示例电路架构,它能够在存储器通道调度对hbm的读取请求,从而同时改进和/或最大化hbm带宽使用。示例电路架构还能够消除在hbm和计算阵列之间的数据传输偏斜。因此,数据可以以同步方式从hbm提供到在多裸片ic的裸片的计算阵列的不同行,同时减少偏斜。这允许计算阵列保持忙碌,而同时更充分地利用hbm的读取带宽。
23.示例电路架构还能够减少将计算阵列分布在多裸片ic的多个裸片上的开销和复杂度。本文所述的示例电路架构可适用于其中具有不同数量裸片的多裸片ic。随着多裸片ic中裸片数量从一个模型到下一个模型发生变化,和/或每个裸片的面积发生变化,本文描述的示例电路架构可以适应这种变化,以改善在hbm和其上分布着计算阵列的多裸片ic的各种裸片之间的数据传输。
24.在整个本公开中,高级微控制器总线架构(amba)可扩展接口(axi)(以下称为“axi”)协议和通信总线用于描述的目的。axi定义了一个嵌入式微控制器总线接口,用于在兼容的电路块和/或系统之间建立片上连接。axi是作为总线接口的说明性示例提供的,并不旨在限制本公开中描述的示例。应当理解,可以使用其他类似和/或等效协议、通信总线、总线接口和/或互连来代替axi,并且本公开中提供的各种示例电路块和/或信号将基于使用的特定协议、通信总线、总线接口和/或互连。
25.下面参照附图更详细地描述本发明的布置的其他方面。为了说明的简单和清楚起见,图中所示的元件不必按比例绘制。例如,为了清楚起见,一些元件的尺寸可能相对于其他元件被夸大了。此外,在认为适当的情况下,在各个附图之间,标记号被重复以指示对应的、类似的或相同的特征。
26.图1图示了在ic 100中实现的电路架构的示例平面图。ic 100是多裸片ic并且包括计算阵列。计算阵列分布在ic 100的裸片102、104和106上。为了说明的目的,ic 100被示为具有三个裸片。在其他示例中,ic 100可以具有比所示出的更少或更多的裸片。
27.在示例中,计算阵列被细分为256个计算阵列行。计算阵列行0-95在裸片102中实现。计算阵列行96-191在裸片104中实现。计算阵列行192-255在裸片106中实现。计算阵列可以包括将裸片102、104和106连接在一起的数字信号处理(dsp)级联链。
28.数据,例如权重,是从通过多个存储器通道通信地链接到ic 100的hbm(未示出)获得的。一方面,hbm被实现在一个单独的ic中(例如,在ic 100的封装之外)并且在与ic100相同的电路板上。另一方面,hbm被实现在ic100内的另一个裸片中(例如,在与ic 100相同的封装内)。hbm可以沿着ic 100的底侧放置,例如从左到右邻近裸片106的底部。在某些hbm的情况下,存储器通道被称为伪通道(pseudo channels,pc)。为了描述的目的,术语“存储器通道”用来指hbm的存储器通道和/或hbm的伪通道。
29.在图1的示例中,裸片106包括16个存储器控制器0-15。每个存储器控制器能够服务(例如,读取和/或写入)两个存储器通道。图1中的存储器控制器0-15在括号中被标记为显示每个存储器控制器服务的特定存储器通道。例如,存储器控制器0服务于存储器通道0和1,存储器控制器1服务于存储器通道2-3等。
30.每个存储器控制器连接到一个或多个请求缓冲器和一个或多个总线主控电路(例如,axi主控)。在图1所示的一个示例实现方案中,每个存储器通道通过存储器控制器被耦接到一个请求缓冲器-总线主电路块。在图1中,每个请求缓冲器-总线主电路块(例如,其中总线主控可以是axi主控)组合被缩写为“rbbm电路块”并且在图中被图示为“rbbm”。由于每个存储器控制器能够服务于两个存储器通道,因此在每个存储器控制器的正上方有两个rbbm电路块并且它们被耦接到每个存储器控制器。每个rbbm电路块都针对由rbbm电路块服务的特定存储器通道进行标记。因此,图1的示例包括rbbm电路块0-15。在该示例中,存储器控制器和rbbm电路块都位于ic100的一个裸片中,例如在同一个裸片中。
31.裸片102、104和106中的每一个包括多个远程缓冲器。远程缓冲器分布在裸片102、104和106上。在图1的示例中,每个rbbm电路块连接到多个远程缓冲器。在一个示例中,每个rbbm电路块连接到4个不同的远程缓冲器。为了说明的目的,rbbm电路块0连接到远程缓冲器0-3,并向远程缓冲器0-3提供数据。rbbm电路块1连接到远程缓冲器4-7,并向远程缓冲器4-7提供数据,剩余的rbbm电路块中的每一个可以通过裸片104和106的远程缓冲器连接到在裸片102中连续编号的4个远程缓冲器的接连的编号组。
32.裸片102、104和106中的每一个还包括多个高速缓存(cache)。通常,高速缓存的数量(例如32个)对应于存储器通道的数量。每个高速缓存能够向多个计算阵列行提供数据。在图1的示例中,每个高速缓存能够为8个计算阵列行提供数据。裸片102包括高速缓存0-11,其中高速缓存0向计算阵列行0-7提供数据,缓存1向计算阵列行8-15提供数据,高速缓存2向计算阵列行16-23提供数据等。裸片104包括高速缓存12-23,其中高速缓存12向计算阵列行96-103提供数据,高速缓存13向计算阵列行104-111提供数据,高速缓存14向计算阵列行112-119提供数据等。裸片106包括高速缓存24-31,其中高速缓存24向计算阵列行192-199提供数据,高速缓存25向计算阵列行200-207提供数据,高速缓存26向计算阵列行208-215提供数据等。
33.在该示例中,诸如权重之类的数据可以通过在裸片106中实现的32个存储器通道从hbm加载。最终,权重作为乘法操作数被输入到计算阵列行中。权重通过裸片106中的存储器控制器0-15经由并行存储器通道进入ic 100。在裸片106内,每个存储器通道rbbm电路块被放置在每个存储器通道旁边以处理每个存储器通道和相关联的计算阵列行之间的流量控制。rbbm电路块由主控制器108控制以执行hbm的读取和写入请求(例如,“访问”)。
34.在图1的示例中,存储器通道远离远程缓冲器。主控制器108也远离在更靠近裸片106右侧的存储器通道。此外,数据波前以与通过存储器控制器(例如,垂直地)进入ic 100的数据波前正交的方向(例如,水平地)进入计算阵列行。
35.从hbm读取的数据是从rbbm电路块被写入到裸片102、104和106中的远程缓冲器0-127中的各个远程缓冲器中。每个远程缓冲器的读取侧(例如,连接到高速缓存的侧)由主控制器108控制。主控制器108控制每个远程缓冲器0-127的读取侧以执行在裸片102、104和106的读取以消除偏斜的操作,并将数据输入到相应的高速缓存0-31以用于各个计算阵列
行0-255。
36.主控制器108能够协调进出远程缓冲器的数据传输,从而使数据消除偏斜。通过协调来自远程缓冲器的读取,主控制器108确保以同步方式向每个计算阵列行提供数据,例如权重。此外,主控制器108能够改进和/或最大化hbm带宽使用。这允许计算阵列保持忙碌,同时更充分地利用hbm的读取带宽。
37.如所指出的,ic 100可以包括比图1所示的更少或更多的裸片。在这方面,图1示例中的电路架构能够降低分布在多裸片ic的多个裸片上的计算阵列分布数据的开销和复杂度,而不管这种ic包括少于还是多于三个裸片。本文所述的示例架构可适用于具有与所示不同数量的裸片的多裸片ic。此外,如图1所示的裸片102、104和106的尺寸,只是为了更好地说明每个相应裸片中的组件。裸片可以具有相同或不同的尺寸。
38.图2图示了图1的电路架构的示例实现。在图2的例子中,裸片边界已被去除。ic 100可以设置在电路板上,该电路板通过通信总线通信地耦接到主机。例如,ic 100可以通过外围组件快速互连(pcie)连接或其他合适的连接耦接到主计算机。ic 100,例如裸片106,可以包括pcie直接存储器访问(dma)电路202以促进pcie连接。pcie dma电路202经由连接206连接到块随机存取存储器(bram)控制器204。在示例实施方案中,rbbm电路块和/或远程缓冲器的一个或多个请求缓冲器通过使用bram实现。
39.主控制器108连接到bram控制器204。bram控制器204能够作为axi端点从设备进行操作,用于与axi互连和系统主设备集成在一起,以与本地存储装置(例如,bram)通信。在图2的例子中,bram控制器204能够作为pcie和主控制器108之间的桥梁来运行。一方面,主控制器108是由命令队列通过主机-pcie连接进行驱动的集中式控制器(例如,通过pcie dma电路202和bram控制器204进行接收)。
40.主控制器108能够实现多个不同的操作。例如,主控制器108能够实现对hbm的窄写入请求以初始化hbm。在那种情况下,主控制器108能够通过使用全局地址(例如,仅通过使用全局地址)、通过(rbbm电路块31的)axi主控制器31和存储器控制器15访问hbm的所有32个存储器通道。
41.主控制器108还能够实现来自hbm的窄读取请求。在那种情况下,主控制器108能够通过使用全局地址(例如,仅通过使用全局地址)、通过axi主控制器31和存储器控制器15访问hbm的所有32个存储器通道。
42.主控制器108还能够实现来自hbm的宽读取请求。主控制器108能够通过使用本地存储器通道地址、通过用于存储器控制器1-15的总线主电路0-31(例如,rbbm电路块0-31的)并行地(例如,顺序地和随机地)执行来自所有32个存储器通道的读取请求。
43.在图2的示例中,主控制器108能够监控和/或跟踪各种信号。此外,主控制器108能够响应于检测到被监控信号中的某些条件而产生多种不同的信号。例如,主控制器108能够产生信号208。信号208是远程缓冲器读取使能信号。主控制器108能够产生信号208并将信号208(例如,相同的信号)广播到远程缓冲器0-127中的每一个。这样,主控制器108能够以同步方式读取启用每个远程缓冲器,以消除从远程缓冲器读取并提供给计算阵列行的数据的偏斜。
44.信号210是远程缓冲器写入使能信号。rbbm电路块0-31中的每个总线主电路0-31分别能够产生信号210到对应的远程缓冲器。主控制器108能够接收由总线主电路0-31为每
个远程缓冲器生成的每个远程缓冲器写入使能信号。在一个方面,主控制器108能够通过跟踪来自每个远程缓冲器的写入使能信号210和提供给每个远程缓冲器的读取使能信号208来监控每个远程缓冲器的填充水平。
45.信号212与信号208相同。然而,信号212是根据与信号208不同的时钟信号(例如,axi_clk而不是sys_clk)生成的。这样,主控制器108能够向远程缓冲器0-127中的每一个以及向rbbm电路块0-31,例如rbbm电路块0-31中的每一个中的axi主设备,提供远程缓冲器读取使能信号。这样,远程缓冲器填充水平也可以由本地实现在每个rbbm电路块中的远程缓冲器指针管理器来跟踪。远程缓冲器指针管理器将结合图5更详细地进行描述。
46.信号214代表axi-aw/w/b信号,主控制器108能够提供给rbbm电路块31以启动如前所述的窄写入。在本公开中,axi-aw是指axi写入地址信号;axi-w指axi写入数据信号;axi-b指axi写入响应信号;axi-ar指axi读取地址信号;axi-r指axi读取数据信号。axi主控制器108还接收来自每个rbbm电路块0-31的信号216。信号216可以是ar req就绪信号(例如,其中“ar”指的是“地址读取”)。主控制器108还能够向rbbm电路块0-31中的每一个广播信号218,例如ar req广播,以启动hbm的读取。
47.图2的示例电路架构包括多个不同的时钟域。dsp_clk用于为计算阵列行和缓存0-31的输出端口提供时钟。在一个示例中,dsp_clk被设置为710mhz。通过每个缓存0-31之间的8x16b连接和由每个相应缓存输入的8个计算阵列行,实现了0.355tb/s的数据传输速率(8x16x32位*710mhz)。
48.sys_clk用于对连接到远程缓冲器的高速缓存0-31的输入端口(例如,右侧)和连接到高速缓存0-31的远程缓冲器0-127的输出端口(例如,左侧)进行计时。sys_clk还用于对主控制器108的一部分进行计时,例如,以便将信号208广播到每个远程缓冲器。在一个示例中,sys_clk被设置为355mhz。使用所示远程缓冲器0-127和高速缓存0-31之间的8x32b连接,可实现0.355tb/s的数据速率(8x32x32位*355mhz)。例如,sys_clk可以被设置为dsp_clk频率的二分之一或大约二分之一。
49.在图2的示例中,缓存0-31不仅可以缓存数据,还可以遍历时钟域。更具体地说,高速缓存0-31中的每一个都能够以sys_clk速率接收数据并以dsp_clk速率(例如,以输入时钟速率的两倍)将数据输出到计算阵列行。在一个或多个示例实现中,诸如远程缓冲器和rbbm电路块的电路可以以具有比诸如可用于实现计算阵列行的其他硬连线电路块更慢的时钟速度的可编程逻辑来实现。因此,高速缓存0-31能够弥合这种时钟速度的差异。
50.axi_clk用于为远程缓冲器的输入端口(例如,右侧)和rbbm电路块的输出端口(例如,左侧)提供时钟。axi_clk还用于为主控制器108的一部分提供时钟,例如,以便监控接收到的信号210和216以及输出信号212、214和218。在一个示例中,axi_clk被设置为450mhz。通过rbbm电路块0-31和远程缓冲器0-127之间的4x64b连接,实现了0.45tb/s的数据速率(4x64x32位*450mhz)。
51.每个rbbm电路块通过256b连接耦接到对应的存储器控制器,实现0.45tb/s(32x256位*450mhz)的数据速率。存储器控制器0-15的时钟频率也可以为450mhz。每个存储器控制器支持两个64b存储器通道连接(例如,每个存储器通道一个),提供0.45tb/s(2048位/t*1.8gt/s)的数据速率。
52.为了讨论的目的,在本公开中使用术语“存储器通道接口”来指代特定的rbbm电路
块和rbbm电路块所在的存储器控制器的对应部分(例如,单个通道)连接的。例如,rbbm电路块0和连接到rbbm电路块0的存储器控制器0的部分(例如,参考图3的数据缓冲器302-0和请求队列304-0)是存储器通道接口,而rbbm电路块0和连接到rbbm电路块1的存储器控制器0的部分(例如,数据缓冲器302-1和请求队列304-1)被认为是另一个存储器通道接口。
53.主控制器108能够根据经由pcie dma 202和bram控制器204接收的hbm读取和写入命令生成读取和写入请求。主控制器108能够在“加速和等待”模式下操作。例如,主控制器108能够向rbbm电路块0-31的请求缓冲器发送读取请求,直到请求缓冲器和包括远程缓冲器的数据路径已满为止。响应于每个读取命令,主控制器108还能够发起从每个远程缓冲器到对应高速缓存的数据读取操作(例如,数据传输)。此外,主控制器108释放一些请求缓冲器空间并触发主控制器108基于请求缓冲器中可用的空间来生成新的读取请求以从hbm获得更多数据。
54.在一个示例实现方案中,hbm在每个pc内包括16个存储体(bank),以及在每一行内包括32列。通过交错存储体,每台pc最多可以读取16x32x256位(128kb)。bram的大小为4x36kb,一个36kb的bram可用于缓冲两个计算阵列行。这样,图2的示例电路架构能够以512位的突发长度从一台pc读取多达16个交错页,一次为8个计算阵列行提供服务。
55.图3图示了图1的电路架构的另一个示例实施方案。在图3的例子中,裸片边界已被去除。此外,存储器控制器0-31(在图3中缩写为“mc”)中的每一个都被耦接到两个存储器通道。图3呈现了存储器控制器0-15和rbbm电路块0-31的更详细视图。
56.在图3的示例中,每个存储器控制器0-15服务两个存储器通道。因此,每个存储器控制器0-15包括用于每个被服务的存储器通道的数据缓冲器302和用于每个被服务的存储器通道的请求队列304。例如,存储器控制器0包括用于服务存储器通道0的数据缓冲器302-0和请求队列304-0以及用于服务存储器通道1的数据缓冲器302-1和请求队列304-1。类似地,存储器控制器15包括数据缓冲器302-30和为存储器通道30提供服务的请求队列304-30,以及数据缓冲器302-31和为存储器通道31提供服务的请求队列304-31。
57.使用axi协议作为说明性示例,数据缓冲器302可以被实现为axi-r(读取)数据缓冲器。每个数据缓冲器302可以包括64
×
16(1024)个条目,其中每个条目是256位。请求队列304可以被实现为axi-ar(地址读取)请求队列。每个请求队列304可以包括64个条目。每个数据缓冲器302从对应的存储器通道接收数据。每个请求队列304能够将命令、地址和/或控制信号提供给从相应axi主控接收到的相应存储器通道。
58.每个rbbm电路块0-31包括总线主电路和请求缓冲器。例如,rbbm电路块0包括总线主电路0和请求缓冲器0。rbbm电路块1包括总线主电路1和请求缓冲器1。rbbm电路块30包括总线主电路30和请求缓冲器30。rbbm电路块31包括总线主电路31和请求缓冲器31。因此,每个总线主电路具有到对应的数据缓冲器302的数据连接和到对应的请求队列304的控制连接(例如,用于地址、控制信号和/或命令)。
59.由于hbm刷新、时钟域交叉和两个存储器通道在单个存储器控制器中交错,因此在通过不同存储器通道从hbm读取的数据之间引入了偏斜。在存储器通道存在偏斜的情况下,通过不同存储器通道从hbm读取的数据没有对齐。即使所有32个存储器通道的所有读取请求都是由32个axi主控器中的每一个在同一周期发出的,情况也是如此。数据偏斜至少部分地是由于hbm的刷新造成的。
60.考虑一个示例,其中hbm在每3900ns内具有260ns的全局刷新周期。在这种情况下,通过刷新命令将hbm吞吐量限制为0.42tb/s((3900-260)/2900*0.45=0.42)。这也意味着每1755个axi_clk周期(3900*0.45=1755)有一个117个axi_clk周期(260*0.45=117)的刷新窗口期,在此期间,hbm读取或写入请求无法通过存储器通道发送到hbm。由于这些刷新窗口未在所有32个存储器通道上对齐,因此当两个存储器通道之间没有重叠刷新周期时,任何两个存储器通道之间的最大偏斜为117个axi_clk周期。在存储器控制器能够每两个axi_clk周期生成一个新请求的情况下,在两个存储器通道之一已经发出59个读取请求而另一个存储器通道由于刷新性能而被阻塞的周期内,在任何两个存储器通道之间的偏斜可能高达59(117/2=59)个hbm读取请求。
61.在图3的示例中,每个请求队列304可用于在刷新命令周期期间将由主控制器108经由相应的总线主电路发起的多达64个hbm读取请求排队。在这种情况下,在刷新命令周期期间累积的59个hbm读取请求可以被吸收在64条目请求队列304中。主控制器108能够通过监控来自相应的rbbm电路块的信号216(例如,来自用于宽读取请求的hbm的所有存储器通道的ar req就绪信号0-31)来监控每个请求队列304的fifo就绪或满状态。响应于确定每个数据缓冲器302中的空间可用,例如,基于每个请求队列304的状态,主控制器108能够生成新的hbm读取请求(例如,对于每个存储器通道)并向存储器控制器0-15中的每一个广播这样的请求(例如,通过总线主控电路)。也就是说,主控制器108将hbm读取请求发送到请求缓冲器。每个总线主控电路为来自本地请求缓冲器的请求提供服务。在任何一个请求队列304已满的情况下,主控制器108不产生新的hbm读取请求。
62.就在32个存储器通道中的每一个的请求队列304的填充水平而言,hbm宽读取请求可能出现两种情况。第一种情况对应于电路架构为准备好接受新的hbm读取请求的状态。在第一种情况下,每个(例如,所有)请求队列304中都有可用的缓冲器空间来接收来自主控制器108的新hbm读取请求。第二种情况对应于电路架构没有准备好接收新hbm读取请求的状态。在第二种情况下,一个或多个请求队列304已满,并且至少一个其他请求队列304既不满也不空。一些请求队列304已满而其他请求队列为空的情况不会发生,因为任何两个存储器通道之间的最大偏斜(例如,59)小于请求队列304的缓冲器大小(例如,64)。在第二种情况下,由于在所有请求队列304中仍有hbm读取请求未决,hbm吞吐量不会受到为来自主控制器108的新请求服务的影响。
63.参考图2和3,共有32个数据流。每个数据流为256位宽,并从存储器通道延伸到相应的远程缓冲器。如图1所示,一些远程缓冲器位于裸片102或104中,而其他远程缓冲器位于更靠近主控制器108的裸片106中。在一些示例布置中,由于每个存储器通道的数据路径是256位宽,通过保持这些数据路径相对较短,可以最大限度地减少硬件资源。
64.图4图示了用于实现图1的电路架构的平衡树结构的示例。平衡树结构用于将hbm宽读取请求从主控制器108广播到存储器控制器。
65.如图4的示例所示,主控制器108从左到右向各个rbbm电路块广播信号218(ar req广播信号)。为了说明的目的,仅示出了rbbm电路块31、16和0。信号218在每个rbbm电路块的到达时间以相同的axi_clk周期对齐。此外,主控制器108能够向每个远程缓冲器广播信号208(例如,远程缓冲器读取使能)。出于说明的目的,仅显示了远程缓冲器0-3、64-67和124-127。
66.在图4的示例中,每个rbbm电路块包括远程缓冲器指针管理器406(显示为406-31、406-16和406-0)。远程缓冲器指针管理器406可以被包括作为请求缓冲器的一部分,或者与每个相应rbbm电路块内的请求缓冲器分开实现。每个远程缓冲器指针管理器406能够接收信号208,用于跟踪相应远程缓冲器的填充水平。此外,每个远程缓冲器指针管理器406能够将信号210(例如,远程缓冲器写入使能信号210-31、210-16和210-0)输出到对应的远程缓冲器。
67.例如,裸片104中的触发器(ff)402从裸片106中的rbbm电路块31接收256位宽的数据信号。ff 402将数据传递到裸片102中的ff 404。ff 404将数据传递到远程缓冲器0-3。远程缓冲指针管理器406-31能够向裸片104中的ff 408输出控制信号210-31。ff 408向裸片102中的ff 410输出控制信号210-31。ff 410向远程缓冲器0-3输出控制信号210-31。主控制器108生成和广播信号208,例如远程缓冲器就绪信号,并将其广播到裸片106中的远程缓冲器124-127。信号208继续到裸片104中的ff 412。ff 412将信号208输出到远程缓冲器64-67。ff 412向裸片102中的ff 414输出信号208。ff 414向远程缓冲器0-3提供信号208。
68.裸片104中的ff 416从裸片106中的rbbm电路块16接收256位宽的数据信号。ff416将数据传递到远程缓冲器64-67。远程缓冲指针管理器406-16能够将控制信号210-16输出到裸片104中的ff 418。ff 418将控制信号210-16输出到远程缓冲器64-67。
69.rbbm电路块0将256位宽的数据信号直接输出到裸片106中的远程缓冲器124-127。远程缓冲器指针管理器406-0将控制信号210-0直接输出到裸片106中的远程缓冲器124-127。
70.通常,由本公开中描述的创造性布置解决的偏斜具有几个不同的分量。例如,偏斜包括由hbm刷新引起的分量和由数据传播延迟引起的分量,例如跨时钟域的信号、沿同一裸片中不同路径的数据延迟、沿不同裸片的不同路径的数据延迟,等等。hbm刷新是造成偏斜的最大因素。偏斜的这一方面主要由存储器控制器内的读取数据缓冲器处理,例如,去偏斜。即使综合考虑,其他偏斜分量对整体偏斜的贡献也小于hbm偏斜,可以由远程缓冲器处理。因此,无需在32个存储器通道上平衡从存储器控制器到远程缓冲器的hbm读取数据延迟。最小流水线级可用于将数据从存储器控制器发送到裸片102、104和106上的远程缓冲器,因为远程缓冲器具有足够的存储空间来容忍由所描述的延迟不平衡引入的远程缓冲器写入侧的偏斜。
71.图4的示例还说明了远程缓冲器如何能够在用于各个存储器通道的存储器控制器上产生背压。至少部分地,通过在靠近存储器通道的每个rbbm电路块内的每个相应远程缓冲器指针管理器406本地生成每个控制信号210来产生背压。此外,主控制器108使用平衡树结构广播公共信号208。
72.用于远程缓冲器的读取和写入指针在裸片102、104和106上的每个相应远程缓冲器处生成。信号210应该匹配远程缓冲器写入数据的延迟。由于在从各种存储器通道接收数据的远程缓冲器的写入侧之间的偏斜以及在信号210之间的偏斜、写入数据延迟、和远程数据读取使能延迟,远程缓冲器背压可以包括一些缓冲器余量空间以用于吸收那些偏斜。信号210和信号216(图4中未显示)被传播回主控制器108。可以平衡这些信号的延迟以确保主控制器108在同一周期捕获信号以生成新的hbm读取请求和信号208。
73.图5图示了如本公开中描述的rbbm电路块的示例实现方案。在图5的例子中,总线
主控电路502包括两个读取通道。axi主机502包括能够处理读取地址数据的axi-ar主机504和能够处理读取数据的axi-r主机506。其他三个axi写通道:axi-aw(写地址)、axi-w(写数据)和axi-b(写响应)可以在主控制器108内部被操控。出于说明的目的,信号标签“axi_rxxxx”旨在指代相关通信规范中带有前缀“axi_r”的axi信号,而信号标签“axi_arxxxx”旨在指代相关通信规范中带有前缀“axi_ar”的axi信号。
74.请求缓冲器508是先前描述为rbbm电路块的一部分的请求缓冲器并且用于处理在ar req就绪(例如,信号216)和ar req信号之间的hbm读取请求队列背压往返延迟(例如,信号218)。例如,请求缓冲器508的深度应该大于背压往返延迟(例如,小于32)。
75.ar req(地址读取请求)信号218可以指定读取起始地址,该地址是用于来自主电路108在存储器控制器0-15上的宽读取请求的23位本地地址或用于窄读取请求的28位全局地址的读取起始地址。来自主电路108的读取请求仅在存储器控制器15上进行。ar req信号218还可以包括用于窄和宽标识的6比特的读取事务标识符,并指定其他流相关信息。ar req信号218还可以指定4位的读取突发长度,根据所使用的特定axi协议支持高达16字节的突发长度。在一个示例实施例中,三个组合逻辑块存储器(clbm),其中每个clbm是32x14双端口ram,可用于为请求缓冲器508实现32x42 fifo。在这种情况下,请求缓冲器508能够服务于axi-ar主控器504,每个axi_clk周期都有一个新的读取请求。
76.远程缓冲器指针管理器406用来生成用于从hbm接收的读取数据的信号210(远程缓冲器写入使能)。远程缓冲器指针管理器406还能够在本地生成与axi-r主控器506对应的axi-r(读取数据)通道的远程缓冲器背压。由于不同存储器通道之间的偏斜,每个远程缓冲器指针管理器406能够通过跟踪远程缓冲器写入使能和远程缓冲器读取使能来维持相应远程缓冲器的填充级别。一旦hbm读取数据通过断言bram_wvalid信号有效,每个远程缓冲器指针管理器406能够增加远程缓冲器填充水平。每个远程缓冲器指针管理器406还能够在接收到从主控制器108广播的信号208(远程缓冲器读取使能)时递减远程缓冲器填充级别。远程缓冲器指针管理器406还能够基于预定义的远程缓冲器填充级别生成远程缓冲器背压信号(例如,bram_wready)用于每个存储器通道。用于生成背压信号的远程缓冲器填充阈值应考虑跨存储器通道的远程缓冲器写入端延迟之间的偏斜和远程缓冲器的读取和写入端之间的偏斜。
77.如图所示,axi-r主机506能够输出可以提供给对应远程缓冲器的数据。
78.图6图示了主控制器108的示例实施例。如图6所示,主控制器108包括耦接到请求控制器604的远程缓冲器读取地址生成单元(远程缓冲器读取agu)602。在图6的示例中,主控制器108将来自bram控制器204的窄读取请求和宽读取请求都转换成对请求缓冲器0-31的axi-ar请求(仅用于31的窄读取)。主控制器108进一步将窄写入请求转换为仅用于主电路31的axi-w和axi-aw请求。
79.在一方面,同时,对于axi-ar请求,来自axi-r的预期读取突发长度从请求控制器604发送到远程缓冲器读取agu 602。远程缓冲器读取agu 602能够将例如,在其中的队列或存储器中接收到预期的读取突发长度排队。远程缓冲器读取agu 602能够通过跟踪所有信号210(例如,所有远程缓冲器写入使能0-31)和信号208(例如,公共远程缓冲器读取使能)来维持每个远程缓冲器的远程缓冲器填充水平。只要所有远程缓冲器的远程缓冲器填充水平超过存储在队列中的预期突发长度,远程缓冲器读取agu 602就能够触发(例如,继续触
发)远程缓冲器读取操作(例如,断言信号208)。信号208被每个请求缓冲器用于为每个存储器通道创建远程缓冲器背压并且被每个远程缓冲器用于去偏斜。因为预期的突发长度是预先确定的并在远程缓冲器读取agu 602中排队,所以允许输出顺序与输入顺序不同的重新排序功能通过强制axi id为一个相同的值而被禁用。
80.图7图示了图6的请求控制器604的示例实施例。在图7的例子中,请求控制器604包括事务缓冲器702和调度器704。事务缓冲器702使用sys_clk作为写入时钟,使用axi_clk作为读取时钟,以解耦两个异步时钟域。请求控制器604还包括多个控制器,被显示为ar(地址读取)控制器706、axi-aw(地址写入)控制器708、axi-w(写入)控制器710、和能够检测axi b或axi响应通道上的有效响应的axi b检测器712。
81.在图7的示例中,ar控制器706能够检查由信号216(例如,ar req就绪信号0-31)表示的请求缓冲器背压。ar控制器706能够同时,例如共同地,检查ar req就绪信号0-31。一方面,ar控制器706仅在每个请求缓冲器中有可用空间时才生成axi-ar req(hbm读取请求)。
82.对于axi读取相关通道,例如axi-ar和axi-r,axi主机和请求控制器604之间需要请求缓冲器。对于axi写入相关通道,例如axi-aw、axi-w和axi-b、请求控制器604(例如,控制器708、710和712)直接与对应于存储器控制器15的axi主控器31通信。当axi就绪指示和axi有效指示(axi-xx-awready/awvalid或axi-xx-wready/wvalid)在同一周期中被断言时,请求控制器604输出axi请求,并同时从缓冲器读取新请求。
83.调度器704能够基于事务类型将不同的axi事务从事务缓冲器702路由(例如,调度)到控制器706、708、710和/或712中的适当控制器。调度器704还调度axi写入和axi读取之间的axi访问序列;并且,在连续的axi写入操作之间安排axi访问序列。例如,调度器704在接收到来自先前axi写事务的响应之前,不发出新的axi-ar请求或新的axi-aw事务。
84.参照图6和7,远程缓冲器读取agu 602接收对应于每个存储器通道的每个远程缓冲器写入使能和公共远程缓冲器读取使能。通过使用性能计数器对数据传输单元进行计数,可以在远程缓冲器的写入侧或远程缓冲器的读取侧处测量系统的吞吐量。
85.图8示出了在hbm和分布式计算阵列之间传输数据的方法800。方法800可以通过使用如本公开中结合图1至图7所描述的电路架构(参考图8,被称为“系统”)来执行。
86.在方块802中,系统能够监控分布在多个裸片上的多个远程缓冲器中的填充水平。多个远程缓冲器中的每个远程缓冲器可以被配置为向也分布在多个裸片上的计算阵列提供数据。在方块804中,系统能够基于填充水平确定多个远程缓冲器中的每个远程缓冲器正在存储数据。在方块806中,响应于该确定,系统能够发起从多个远程缓冲器中的每个远程缓冲器到多个裸片到计算阵列的数据传输。数据传输可以是同步的(例如,去偏斜的)。例如,每个裸片中发生的数据传输是同步的。最小流水线用于促进从一个芯片到另一个芯片的同步。作为从远程缓冲器输出到计算阵列行的数据,被进一步去偏斜。
87.在一个方面,系统通过向多个远程缓冲器中的每个远程缓冲器广播读取使能信号来启动从每个远程缓冲器的数据传输。读取使能信号是广播到每个远程缓冲器的公共读取使能信号。
88.在另一方面,系统能够通过在一对一的基础上跟踪对应于多个远程缓冲器的多个写入使能,以及跟踪对多个远程缓冲器中的每一个共同的读取使能,而监控填充水平。
89.在特定实施方案中,系统能够通过多个相应的存储器通道从hbm接收被设置在多
个裸片中的第一裸片中的多个rbbm电路块内的数据。多个rbbm电路块向多个远程缓冲器中的各个远程缓冲器提供数据。
90.系统还能够将访问存储器的第一请求转换为符合片上通信总线的第二请求,并且将第二请求提供给对应于多个rbbm电路块中的每一个的通信总线主电路。
91.系统能够将来自多个远程缓冲器中的每一个的数据提供给分布在多个裸片上的多个高速缓存电路块,其中每个高速缓存电路块连接到多个远程缓冲器中的至少一个远程缓冲器和计算阵列。每个高速缓存电路块可以被配置为以第一时钟速率从选定的远程缓冲器接收数据,并且以超过第一时钟速率的第二时钟速率将数据输出到计算阵列。
92.图9图示了可编程器件900的示例架构。可编程器件900是可编程ic和自适应系统的示例。在一方面,可编程器件900也是片上系统(soc)的示例。可编程器件900可以使用多个互连的裸片来实现,其中图9中所示的各种可编程电路资源是在不同的互连裸片上实现的。在一个示例中,可编程器件900可用于实现本文结合图1-8描述的示例电路架构。
93.在示例中,可编程器件900包括数据处理引擎(dpe)阵列902、可编程逻辑(pl)904、处理器系统(ps)906、片上网络(noc)908、平台管理控制器(pmc)910,以及一个或多个硬接线电路块912。还包括配置帧接口(cfi)914。
94.dpe阵列902被实现为多个互连的可编程数据处理引擎(dpe)916。dpe 916可以被布置在阵列中并且是硬连线的。每个dpe 916可以包括一个或多个核918和存储器模块(图9中缩写为“mm”)920。一方面,每个核918能够执行存储在包含在每个相应核中的特定于核的程序存储器中的程序代码(未显示)。每个核918能够直接访问同一dpe 916内的存储器模块920和在上、下、左和右方向上与dpe 916的核918相邻的任何其他dpe 916的存储器模块920。例如,核918-5能够直接读取存储器模块920-5、920-8、920-6和920-2。核918-5将每个存储器模块920-5、920-8、920-6和920-2视为统一的存储器区域(例如,作为核918-5可访问的本地存储器的一部分)。这有助于在dpe阵列902中的不同dpe 916之间共享数据。在其他示例中,核918-5可以直接连接到其他dpe中的存储器模块920。
95.dpe 916通过可编程互连电路互连。可编程互连电路可以包括一个或多个不同且独立的网络。例如,可编程互连电路可以包括由流连接(阴影箭头)形成的流网络、由存储器映射连接(交叉阴影箭头)形成的存储器映射网络。
96.通过存储器映射连接将配置数据加载到dpe 916的控制寄存器中允许独立地控制每个dpe 916和其中的组件。dpe 916可以按每个dpe为基础被启用/禁用。例如,每个核918可以被配置为访问所描述的存储器模块920或仅访问其子集,以实现核918或作为集群操作的多个核918的隔离。每个流连接可以被配置为在仅选定的dpe 916之间建立逻辑连接,以实现dpe 916或作为集群操作的多个dpe 916的隔离。因为每个核918可以加载有特定于该核918的程序代码,所以每个dpe 916能够在其中实现一个或多个不同的核。
97.在其他方面,dpe阵列902内的可编程互连电路可以包括其他的独立网络,例如独立于(例如,不同和分离的)流连接和存储器映射连接和/或事件的调试网络广播网络。在一些方面,调试网络由存储器映射连接形成和/或是存储器映射网络的一部分。
98.核918可以通过核到核级联连接直接与相邻核918连接。在一方面,核到核级联连接是核918之间的单向和直接连接,如图所示。在另一方面,核到核级联连接是核918之间的双向和直接连接。核到核级联接口的激活也可以通过将配置数据加载到各个dpe 916的控
制寄存器中而被控制。
99.在示例实现方案中,dpe 916不包括高速缓存存储器。通过省略高速缓存存储器,dpe阵列902能够实现可预测的例如确定性的性能。此外,由于不需要保持位于不同dpe 916中的高速缓存存储器之间的一致性,因此避免了显著的处理开销。在另一个示例中,核918不具有输入中断。因此,核918能够不间断地操作。省略对核918的输入中断还允许dpe阵列902实现可预测的例如确定性的性能。
100.soc接口块922作为将dpe 916连接到可编程器件900的其他资源的接口进行操作。在图9的示例中,soc接口块922包括排列成一行的多个互连的片(tile)924。在特定实施例中,不同的架构可以用于在soc接口块922内实现片924,其中每个不同的片架构支持与可编程器件900的不同资源的通信。片924被连接,使得数据可以从一个片到另一个片进行双向传播。每个片924能够作为直接在上方的dpe 916列的接口运行。
101.片924通过使用所示的流连接和存储器映射连接而被连接到相邻的片、直接在上面的dpe 916、和在下面的电路。片924还可以包括连接到在dpe阵列902中实现的调试网络的调试网络。每个片924能够从诸如ps 906、pl 904和/或另一个硬连线电路块912的另一个源接收数据。例如,片924-1能够将寻址到上列中的dpe 916的数据的那些部分(无论是应用程序还是配置)提供给这样的dpe 916,同时将寻址到其他列中的dpe 916的数据发送到其他片924例如,924-2或924-3,以便这样的片924可以在它们各自的列中相应地路由被寻址到dpe 916的数据。
102.在一个方面,soc接口块922包括两种不同类型的片924。第一种类型的片924具有被配置为仅用作dpe 916和pl 904之间的接口的架构。第二种类型的片924具有被配置为用作dpe 916和noc 908之间以及dpe 916和pl 904之间的接口的架构。soc接口块922可以包括第一和第二类型的片的组合或仅第二类型的片。
103.在一方面,dpe阵列902可用于实现本文所述的计算阵列。在这方面,dpe阵列902可以分布在多个不同的裸片上。
104.pl 904是可以被编程以执行指定功能的电路。作为示例,pl 904可以被实现为现场可编程门阵列类型的电路。pl 904可以包括一组可编程电路块。如本文所定义,术语“可编程逻辑”是指用于构建可重新配置数字电路的电路。可编程逻辑由许多提供基本功能的可编程电路块(有时称为“片”)组成。与硬接线电路不同,pl 904的拓扑结构具有高度可配置性。pl 904的每个可编程电路块通常包括可编程元件926(例如,功能元件)和可编程互连942。可编程互连942提供pl 904的高度可配置拓扑。可编程互连942可以按每条线被配置来在提供pl 904的可编程电路块的可编程元件926之间的连接性,并且是按每比特可配置的(例如,其中每条线传送单个信息比特),与在dpe 916之间的连接性不同。
105.pl 904的可编程电路块的示例包括具有查找表和寄存器的可配置逻辑块。与下面描述的硬连线电路(有时称为硬块)不同,这些可编程电路块在制造时具有未定义的功能。pl904可以包括其他类型的可编程电路块,它们也提供基本的和定义的功能,但可编程性更有限。这些电路块的示例可以包括数字信号处理块(dsp)、锁相环(pll)和块随机存取存储器(bram)。与pl 904中的其他可编程电路块一样,这些类型的可编程电路块数量众多,并且与pl 904的其他可编程电路块混合在一起。这些电路块还可以具有通常包括可编程互连942和可编程元件926的架构,并且,这样的话,是pl 904的高度可配置拓扑的一部分。
106.在使用之前,pl 904,例如可编程互连和可编程元件,必须通过将被称为配置比特流的数据加载到其中的内部配置存储器单元中来编程或“配置”。配置存储单元一旦加载了配置比特流,就限定了pl 904的配置方式,例如拓扑结构和操作方式(例如,执行的特定功能)。在本公开中,“配置比特流”不等同于可由处理器或计算机执行的程序代码。
107.在一个方面,pl 904可用于实现图1-7中所示的组件中的一个或多个。例如,各种缓冲器、队列和/或控制器可以通过使用pl 904来实现。在这点上,pl 904可以分布在多个裸片上。
108.ps 906被实现为作为可编程器件900的一部分制造的硬连线电路。ps 906可以被实现为或包括各种不同处理器类型中的任一种,每个处理器类型都能够执行程序代码。例如,ps 906可以被实现为单独的处理器,例如,能够执行程序代码的单核。在另一示例中,ps906可以实现为多核处理器。在又一示例中,ps 906可以包括一个或多个核、模块、协处理器、i/o接口和/或其他资源。ps 906可以使用多种不同类型的架构中的任何一种来实现。可用于实现ps 906的示例架构可包括但不限于arm处理器架构、x86处理器架构、图形处理单元(gpu)架构、移动处理器架构、dsp架构、前述架构的组合、或能够执行计算机可读指令或程序代码的其他合适架构。
109.noc 908是用于在可编程器件900中的端点电路之间共享数据的可编程互连网络。端点电路可以被布置在dpe阵列902、pl 904、ps 906和/或选定的硬连线电路块912中。noc 908可以包括带有专用交换的高速数据路径。在一个示例中,noc 908包括一个或多个水平路径、一个或多个垂直路径、或水平和垂直路径两者。如图9所示的区域的排列和数量仅仅是一个例子。noc 908是可编程器件900内可用于连接选定组件和/或子系统的通用基础设施的示例。
110.在noc 908内,要通过noc 908路由的网络在创建用于在可编程器件900内实现的用户电路设计之前是未知的。noc 908可以通过将配置数据加载到内部配置寄存器中来编程,该内部配置寄存器定义元件如何在noc 908内,例如交换机和接口被配置和操作以在交换机之间以及在noc接口之间传递数据以连接端点电路。noc 908被制造为可编程器件900的一部分(例如,是硬连线的),并且虽然不可物理修改,但可以被编程以建立用户电路设计的不同主电路和不同从电路之间的连接性。noc 908在通电后不会在其中实现任何数据路径或路由。然而,一旦由pmc 910进行配置后,noc 908就实现端点电路之间的数据路径或路由。
111.pmc 910负责管理可编程器件900。pmc 910是可编程器件900内的一个子系统,它能够管理整个可编程器件900上的其他可编程电路资源。pmc 910能够维护一个安全可靠的环境、引导可编程器件900以及在正常操作期间管理可编程器件900。例如,pmc 910能够为可编程设备900(例如,dpe阵列902、pl 904、ps 906和noc 908)的不同可编程电路资源提供对通电、启动/配置、安全、电源管理、安全监控、调试和/或错误处理的统一的和可编程的控制。pmc 910作为将ps 906和pl 904解耦的专用平台管理器操作。因此,ps 906和pl 904可以彼此独立地被管理、配置和/或通电和/或断电。
112.在一个方面,pmc 910能够作为整个可编程器件900的信任根操作。作为示例,pmc 910负责认证和/或验证包含可加载到可编程器件900中的可编程器件900的任何可编程资源的配置数据的器件图像。pmc 910还能够保护可编程器件900在操作期间免受篡改。通过
作为可编程器件900的信任根操作,pmc 910能够监控pl 904、ps 906和/或任何其他可包括在可编程器件900中的可编程电路资源的操作。由pmc 910执行的信任根能力是与ps 906和pl 904和/或由ps 906和/或pl 904执行的任何操作不同且分开的。
113.在一方面,pmc 910在专用电源上运行。因此,pmc 910由分开和独立于ps 906的电源和pl 904电源的电源供电。这种电源独立性允许pmc 910、ps 906和pl 904在电噪声和毛刺方面相互保护。此外,当pmc 910继续操作时,ps 906和pl 904之一或两者可被断电(例如,暂停或置于休眠模式)。这种能力允许已经被断电的可编程器件900的任何部分,例如,pl 904、ps 906、noc 908等,能够更快地唤醒并恢复到操作状态,而不需要整个可编程器件900进行完整的上电和开机过程。
114.pmc 910可以被实现为具有专用资源的处理器。pmc 910可以包括多个冗余处理器。pmc 910的处理器能够执行固件。固件的使用支持可编程器件900的全局特征的可配置性和分段,诸如复位、时钟和保护,以在创建单独的处理域(其不同于可能是特定于子系统的“电源域”)中提供灵活性。处理域可以涉及可编程器件900的一个或多个不同可编程电路资源的混合或组合(例如,其中处理域可以包括与dpe阵列902、ps 906、pl 904、noc 908和/或其他硬连线电路块912不同的组合与器件)。
115.硬连线电路块912包括被制造为可编程器件900的一部分的专用电路块。虽然是硬连线的,但硬连线电路块912可以通过将配置数据加载到控制寄存器中来配置以实现一种或多种不同的操作模式。硬连线电路块912的示例可以包括输入/输出(i/o)块、用于向可编程器件900外部的电路和/或系统、存储器控制器等发送和接收信号的收发器。不同i/o块的示例可以包括单端的和伪差分的i/o。收发器的示例可以包括高速差分时钟收发器。硬连线电路块912的其他示例包括但不限于密码引擎、数模转换器(dac)、模数转换器(adc)等。通常,硬连线电路块912是专用电路块。
116.在一个方面,硬连线电路块912可以用于实现图1-7中所示的组件中的一个或多个组件。例如,各种存储器控制器和/或其他控制器均可以被实现为硬连线电路块912。在这点上,一个或多个硬连线电路块912可以分布在多个裸片上。
117.cfi 914是一个接口,通过该接口可以向pl 904提供配置数据,例如配置比特流,以在其中实现不同的用户指定电路和/或电路。cfi 914耦接到pmc 910并且可由pmc 910访问以向pl 904提供配置数据。在一些情况下,pmc 910能够首先配置ps 906,使得ps 906一旦被pmc 910配置,就可以通过以下方式向pl 904提供配置数据cfi 914。一方面,cfi 914具有并入其中的内置循环冗余校验(crc)电路(例如,crc 32位电路)。因此,任何被加载到cfi 914和/或经由cfi 914被读回的数据可以通过检查被附加到数据的代码的值来检查完整性。
118.图9上显示的各种可编程电路资源可以作为可编程器件900的引导过程的一部分进行初始编程。在运行时间期间,可编程电路资源可以被重新配置。在一方面,pmc 910能够初始配置dpe阵列902、pl 904、ps 906和noc 908。在运行期间的任何时间点,pmc 910可以重新配置可编程器件900的全部或一部分。在一些情况下,ps 906一旦被pmc 910初始配置,它就可以配置和/或重新配置pl 904和/或noc 908。
119.结合图9描述的示例可编程器件仅用于说明目的。在其他示例实现方案中,本文描述的示例电路架构可以在定制多裸片ic(例如,具有多个裸片的专用ic)中和/或在可编程
ic(诸如具有多个裸片的现场可编程门阵列(fpga))中实现。此外,用于通信地链接ic封装内的裸片的特定技术,例如,具有耦接裸片的布线的普通硅中介层、多芯片模块、三个或更多堆叠裸片等,并非旨在限制这里描述的创造性安排。
120.出于解释的目的,阐述了特定的命名法以提供对本文公开的各种发明概念的透彻理解。然而,本文使用的术语仅出于描述本发明布置的特定方面的目的,并非旨在进行限制。
121.如本文所限定的,单数形式“一”、“一个”和“该”旨在也包括复数形式,除非上下文另有明确指示。
122.如本文所限定的,术语“大约”是指几乎正确或精确、在值或数量上接近但不精确。例如,术语“大约”可以表示所列举的特征、参数或值在准确特征、参数或值的预定量内。
123.如本文所限定的,除非另有明确说明,否则术语“至少一个”、“一个或多个”和“和/或”是开放式表达,它们在操作中既是结合的又是分离的。例如,“a、b和c中的至少一个”、“a、b或c中的至少一个”、“a、b和c中的一个或多个”、“一个或多个a、b或c的组合”和“a、b和/或c”是指单独的a、单独的b、单独的c、a和b一起、a和c一起、b和c一起,或a、b和c一起。
124.如本文所限定,术语“自动”是指无需人工干预。如本文所定义,术语“用户”是指人。
125.如本文所限定,根据上下文,术语“如果”表示“当
…
时”或“在
…
时”或“响应于”,取决于上下文。因此,短语“如果确定”或“如果检测到[所述条件或事件]”可以解释为表示“在确定时”或“响应于确定”或“在检测到[所述条件或事件]时”或“响应于检测到[所述条件或事件]”或“响应于检测到[所述条件或事件]”,具体取决于上下文。
[0126]
如本文所限定,术语“响应于”和如上所述的类似语言,例如“如果”、“当
…
时”或“在
…
时”,是指对动作或事件容易地响应或做出反应。响应或反应是自动执行的。因此,如果“响应于”第一动作而执行第二动作,则在第一动作的发生与第二动作的发生之间存在因果关系。术语“响应”表示因果关系。
[0127]
如本文所限定,术语“处理器”意指至少一个硬件电路。硬件电路可以被配置为执行被包含在程序代码中的指令。硬件电路可以是集成电路或嵌入在集成电路中。
[0128]
如本文所限定,术语“基本上”是指不需要精确实现所列举的特性、参数或值,而是可能出现偏斜或变化(包括例如容差、测量误差、测量精度限制和本领域技术人员已知的其他因素),其大小不排除该特性打算提供的效果。
[0129]
术语第一、第二等可以在本文中用于描述各种单元。这些单元不应受这些术语的限制,因为这些术语仅用于将一个单元与另一个单元区分开来,除非另有说明或上下文另有明确指示。
[0130]
图中的流程图和框图说明了根据本发明布置的各个方面的系统、方法和计算机程序产品的可能实现的体系结构、功能和操作。在这点上,流程图或框图中的每一块可以表示一个模块、段、或指令的一部分,其包括用于实现指定操作的一个或多个可执行指令。
[0131]
在一些替代实施方式中,方块中标注的操作可能不按图中标注的顺序发生。例如,连续显示的两个块可以基本上同时执行,或者这些块有时可以以相反的顺序执行,这取决于所涉及的功能。在其他示例中,方块通常可以按递增的数字顺序执行,而在其他示例中,可以以不同的顺序执行一个或多个方块,其中结果被存储并在不紧随其后的后续方块或其
他方块中使用。还将注意,框图和/或流程图说明的每个块,以及框图和/或流程图说明中的块的组合,可以由执行指定功能或动作,或实现专用硬件和计算机指令的组合的专用的基于硬件的系统实现。
[0132]
可以在以下权利要求中找到的所有装置或步骤加上功能元件的相应结构、材料、动作和等同物旨在包括用于与其他要求保护的元件组合执行功能的任何结构、材料或动作,正如特别声称的那样。
[0133]
ic可以包括多个裸片。ic可以包括被配置为与存储器通信的多个存储器通道接口,其中所述多个存储器通道接口设置在所述多个裸片中的第一裸片内。ic可以包括分布在多个裸片上的计算阵列和分布在多个裸片上的多个远程缓冲器。多个远程缓冲器可以耦接到多个存储器通道和计算阵列。ic还可以包括控制器,该控制器被配置为确定多个远程缓冲器中的每一个都在其中存储了数据,并且作为响应,向多个远程缓冲器中的每一个广播读取使能信号,从而发起从多个远程缓冲器跨多个裸片到计算阵列的数据传输。
[0134]
可以同步数据传输以消除由各个传输所传送的数据引起的偏斜。
[0135]
前述和其他实施方式可以各自可选地包括单独或组合的以下特征中的一个或多个。一种或多种实施方式可以包括所有以下特征的组合。
[0136]
在一个方面,ic可以包括被设置在第一裸片中的多个请求缓冲器-总线主电路块,其中每个请求缓冲器-总线主电路块连接到多个存储器通道接口中的一个存储器通道接口以及所述多个远程缓冲器中的至少一个远程缓冲器。
[0137]
在另一方面,ic可以包括被分布在多个裸片上的多个高速缓存电路块,其中每个高速缓存电路块连接到多个远程缓冲器中的至少一个远程缓冲器并且连接到计算阵列。
[0138]
在另一方面,每个高速缓存电路块可以被配置为以第一时钟速率从选定的远程缓冲器接收数据并且以超过第一时钟速率的第二时钟速率将数据输出到计算阵列。
[0139]
在另一方面,计算阵列包括多行,其中,所述多个裸片中的每个裸片包括多行中的两行或多行。
[0140]
在另一方面,每个存储器通道接口可以将来自存储器的数据提供给计算阵列的两行或多行。
[0141]
在另一方面,存储器是高带宽存储器。在另一方面,存储器是双倍数据速率随机存取存储器。
[0142]
在另一方面,计算阵列实现神经网络处理器,并且数据指定由神经网络处理器施加的权重。
[0143]
在另一方面,每个存储器通道接口将来自存储器的数据提供给计算阵列的两行或多行。
[0144]
在一个方面,控制器被设置在具有多个裸片的ic内。该控制器包括请求控制器,该请求控制器被配置为将访问存储器的第一请求转换为符合片上通信总线的第二请求,其中该请求控制器将第二请求提供给多个请求缓冲器-总线主电路块,该多个请求缓冲器-总线主电路块被配置为接收来自存储器的多个通道的数据。控制器还包括远程缓冲器读取地址生成单元,其耦接到请求控制器并被配置为监控分布在多个裸片上的多个远程缓冲器中的每一个中的填充水平。多个远程缓冲器中的每个远程缓冲器被配置为将从多个请求缓冲器-总线主电路块中的相应一些获得的数据提供给也分布在多个裸片上的计算阵列。响应
于基于填充级别确定多个远程缓冲器中的每个远程缓冲器正在存储数据,远程缓冲器读取地址生成单元被配置为发起从多个远程缓冲器中的每个远程缓冲器跨越多个裸片到计算阵列的数据传输。
[0145]
可以同步数据传输以消除由各个传输传送的数据引起的偏斜。
[0146]
前述和其他实施方式可以各自可选地包括单独或组合的以下特征中的一个或多个。一种或多种实施方式可以包括所有以下特征的组合。
[0147]
在一个方面,请求控制器可以以第一时钟速率接收第一请求并且以第二时钟速率提供第二请求。
[0148]
在另一方面中,远程缓冲器读地址生成单元可以通过跟踪与多个远程缓冲器对应的多个写入使能并跟踪对多个远程缓冲器中的每一个共同的读使能来监控多个远程缓冲器中的每一个中的填充水平。
[0149]
一种方法可以包括监控分布在多个裸片上的多个远程缓冲器中的填充水平,其中多个远程缓冲器中的每个远程缓冲器被配置为向也分布在多个裸片上的计算阵列提供数据.该方法还可以包括基于填充水平确定多个远程缓冲器中的每个远程缓冲器正在存储数据,并且响应于该确定,启动从多个远程缓冲器中的每个远程缓冲器跨越多个裸片到计算阵列的数据传输。
[0150]
可以同步数据传输以消除由各个传输传送的数据引起的偏斜。
[0151]
前述和其他实施方式可以各自可选地包括,单独地或组合地,以下特征中的一个或多个。一种或多种实施方式可以包括所有以下特征的组合。
[0152]
在一个方面,从每个远程缓冲器发起数据传输包括向多个远程缓冲器中的每个远程缓冲器广播读取使能信号。
[0153]
在另一方面,监控填充水平可以包括跟踪对应于多个远程缓冲器的多个写入使能和跟踪对于多个远程缓冲器中的每一个来说共同的读取使能。
[0154]
在另一方面,该方法可以包括在布置在多个裸片中的第一裸片中的多个请求缓冲器总线主电路块内,通过多个相应的存储器通道从存储器接收数据,其中多个请求缓冲器总线主电路块向多个远程缓冲器中的各个远程缓冲器提供数据。
[0155]
在另一方面,该方法可以包括将访问存储器的第一请求转换成符合片上通信总线的第二请求,并且将第二请求提供给与多个请求缓冲器中的每一个对应的通信总线主控电路。
[0156]
在另一方面,该方法可以包括将来自多个远程缓冲器中的每一个的数据提供给分布在多个裸片上的多个高速缓存电路块,其中每个高速缓存电路块连接到该多个远程缓冲器的至少一个远程缓冲器以及计算阵列。
[0157]
在另一方面,每个高速缓存电路块可以被配置为以第一时钟速率从选定的远程缓冲器接收数据,并以超过第一时钟速率的第二时钟速率将数据输出到计算阵列。
[0158]
在此提供的对本发明的布置的描述是为了说明的目的,并不旨在穷举或限制于所公开的形式和示例。此处使用的术语被选择来解释本发明布置的原理、实际应用、或对市场中发现的技术改进,和/或使本领域的其他普通技术人员能够理解此处公开的发明布置。在不背离所描述的发明布置的范围和精神的情况下,修改和变化对于本领域普通技术人员来说是显而易见的。因此,应参考以下权利要求,而不是参考前述公开内容,以指示此类特征
和实施方式的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。