一种基于pcie总线的mac层数据交换方法及系统
技术领域
1.本发明涉及通信技术领域,具体涉及一种基于pcie总线的mac层数据交换方法及系统。
背景技术:
2.目前mac层的数据交换都是基于以太网实现的,通过二层交换机进行转发,数据延时高,不保证数据的可靠传输,需要进行差错校验。本发明基于pcie的数据处理芯片,支持多路cpu之间通过pcie进行互联,通过建立mac路由表,并建立mac与内存的对应关系,通过查询对应的mac路由表,实现cpu之间的dma数据传输功能,原生支持跨cpu的dma传输,基于pcie的传输,可以保证数据的传输可靠性,不需要进行差错校验。
技术实现要素:
3.为此,本发明提供一种基于pcie总线的mac层数据交换方法及系统,以解决现有mac层的数据交换存在的数据延时高,不保证数据的可靠传输,需要进行差错校验的问题。
4.为了实现上述目的,本发明提供如下技术方案:
5.根据本发明实施例的第一方面,提出了一种基于pcie总线的mac层数据交换方法,多路cpu通过pcie总线连接数据处理芯片,所述方法包括:
6.根据预设规则为每个cpu分配mac地址;
7.读取数据处理芯片配置信息,获取当前运行在pcie总线上的cpu个数,每个cpu根据所述cpu个数进行内存分配,每个cpu上均分配有与其他cpu一一对应的buffer,并建立cpu的mac地址与对应buffer之间的映射关系;
8.当两个cpu之间进行数据交换时,通过查询mac地址表获取目标mac地址,根据所述目标mac地址以及建立的mac地址与buffer之间的映射关系,获取到与目标mac地址对应的buffer,并实现cpu之间的dma数据传输。
9.进一步地,根据预设规则为每个cpu分配mac地址,具体包括:
10.根据pcie插槽位置进行顺序编号,mac地址的前24bit固定,mac地址的后24bit根据pcie插槽位置的顺序编号进行编码。
11.进一步地,每个cpu根据所述cpu个数进行内存分配,每个cpu上均分配有与其他cpu一一对应的buffer,具体包括:
12.每个cpu会取一块内存区域,并根据当前pcie总线上的cpu的数量n,将这块内存区域分成n-1块,并且每块又分为发送区和接收区。
13.进一步地,通过查询mac地址表获取目标mac地址,具体包括:
14.每个cpu和数据处理芯片上都会维护一个mac地址表,根据所述mac地址表确定当前cpu的目标mac地址是否在表中。
15.进一步地,根据所述目标mac地址以及建立的mac地址与buffer之间的映射关系,获取到与目标mac地址对应的buffer,并实现cpu之间的dma数据传输,具体包括:
16.发送方cpu根据所述mac地址表判断目标mac地址是否在线,若在线,则将数据拷贝到本地与目标mac对应的内存块中,当数据处理芯片检测到此内存块中有数据,会中断通知接收方cpu的dma从发送方cpu的内存块中搬数据,完成传输。
17.根据本发明实施例的第二方面,提出了一种基于pcie总线的mac层数据交换系统,多路cpu通过pcie总线连接数据处理芯片,所述系统包括:
18.mac地址分配模块,用于根据预设规则为每个cpu分配mac地址;
19.映射关系构建模块,用于读取数据处理芯片配置信息,获取当前运行在pcie总线上的cpu个数,每个cpu根据所述cpu个数进行内存分配,每个cpu上均分配有与其他cpu一一对应的buffer,并建立cpu的mac地址与对应buffer之间的映射关系;
20.数据交换模块,用于当两个cpu之间进行数据交换时,通过查询mac地址表获取目标mac地址,根据所述目标mac地址以及建立的mac地址与buffer之间的映射关系,获取到与目标mac地址对应的buffer,并实现cpu之间的dma数据传输。
21.本发明具有如下优点:
22.本发明提出的一种基于pcie总线的mac层数据交换方法及系统,在pcie上实现mac层的数据传输,通过加入数据处理芯片系统,配合cpu的mac地址映射表,建立cpu之间的内存映射关系,实现基于mac的通过dma跨cpu传输数据操作,本发明原生支持跨cpu的dma数据传输,可以保证数据的可靠传输,并可以为后续在pcie支持tcp/ip协议栈做前期准备,大大降低组建小型服务器集群的成本。
附图说明
23.为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引伸获得其它的实施附图。
24.图1为本发明实施例1提供的一种基于pcie总线的mac层数据交换方法的流程示意图;
25.图2为本发明实施例1提供的一种基于pcie总线的mac层数据交换方法的原理框架示意图;
26.图3为本发明实施例1提供的一种基于pcie总线的mac层数据交换方法的具体实施流程示意图。
具体实施方式
27.以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
28.实施例1
29.如图1、图2和图3所示,本实施例提出了一种基于pcie总线的mac层数据交换方法,多路cpu通过pcie总线连接数据处理芯片,该方法包括:
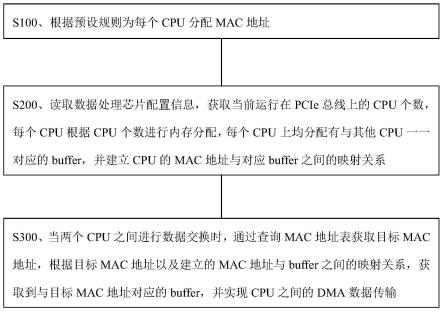
30.s100、根据预设规则为每个cpu分配mac地址。
31.根据pcie插槽位置进行顺序编号,mac地址的前24bit固定,mac地址的后24bit根据pcie插槽位置的顺序编号进行编码。
32.s200、读取数据处理芯片配置信息,获取当前运行在pcie总线上的cpu个数,每个cpu根据cpu个数进行内存分配,每个cpu上均分配有与其他cpu一一对应的buffer,并建立cpu的mac地址与对应buffer之间的映射关系。
33.每个cpu会取一块内存区域,并根据当前pcie总线上的cpu的数量n,将这块内存区域分成n-1块,并且每块又分为发送区和接收区。
34.s300、当两个cpu之间进行数据交换时,通过查询mac地址表获取目标mac地址,根据目标mac地址以及建立的mac地址与buffer之间的映射关系,获取到与目标mac地址对应的buffer,并实现cpu之间的dma数据传输。
35.每个cpu和数据处理芯片上都会维护一个mac地址表,根据mac地址表确定当前cpu的目标mac地址是否在表中,以确定数据是转发还是丢弃。
36.数据处理芯片会把当前pcie总线上的所有cpu上用来收发数据的内存区域统一管理,以方便通过数据处理芯片可以找到每个cpu上的内存地址。
37.当cpu1往cpu2发送数据,首先在cpu1上的mac地址表上判断对应的mac是否在线,如果在线,则把数据拷贝到cpu1上目标mac对应的内存块上,数据处理芯片检测到这块内存区域有数据,会中断通知cpu2的dma从cpu1的内存块中搬数据。反之,从cpu2往cpu1发数据,则数据处理芯片中断通知cpu1,cpu1的dma从cpu2的内存搬数据。都是接收方的dma从发送方搬数据。
38.中断是外部设备向处理器发起的请求事件。接收端的cpu不知道什么时候有数据过来,当有数据过来时,数据处理芯片会产生一个中断,通知接收端的cpu,接收端的cpu收到中断,知道有数据过来,然后用dma去对应的区域去搬数据,具体从哪个cpu的哪块内存搬数据,这些都是通过数据处理芯片来管理。
39.实施例2
40.与上述实施例1相对应的,本实施例提出了一种基于pcie总线的mac层数据交换系统,多路cpu通过pcie总线连接数据处理芯片,该系统包括:
41.mac地址分配模块,用于根据预设规则为每个cpu分配mac地址;
42.映射关系构建模块,用于读取数据处理芯片配置信息,获取当前运行在pcie总线上的cpu个数,每个cpu根据cpu个数进行内存分配,每个cpu上均分配有与其他cpu一一对应的buffer,并建立cpu的mac地址与对应buffer之间的映射关系;
43.数据交换模块,用于当两个cpu之间进行数据交换时,通过查询mac地址表获取目标mac地址,根据目标mac地址以及建立的mac地址与buffer之间的映射关系,获取到与目标mac地址对应的buffer,并实现cpu之间的dma数据传输。
44.本发明实施例提供的一种基于pcie总线的mac层数据交换系统中各部件所执行的功能均已在上述实施例1中做了详细介绍,因此这里不做过多赘述。
45.虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
