1.本发明涉及网络异常检测领域,尤其涉及的是一种物联网异常实时检测 方法和装置、可读存储介质。
背景技术:
2.随着科技的进步,智慧城市的理念逐渐深入人心,随着智慧城市的发展, 物联网的总连接量正在急剧增加。然而,大多数物联网设备都受到其硬件性 能的限制,这使得物联网设备容易受到黑客的攻击。更糟糕的是,在智慧城 市场景中,大多数物联网设备(如摄像头、灯光等)都暴露在室外,使黑客 更容易通过物理访问访问物联网局域网进行攻击。另外,由于城市监控摄像 头设备数量众多,难以实现对海量物联网流量的低成本实时检测。
3.因此,现有技术还有待改进。
技术实现要素:
4.本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种物 联网异常实时检测方法和装置、可读存储介质,以解决在现有物联网设备流 量日益增长的情况下,导致现有检测系统难以实现高精度的实时检测的问题。
5.本发明解决技术问题所采用的技术方案如下:
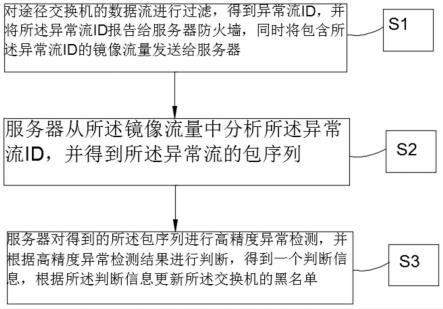
6.一种物联网异常实时检测方法,所述物联网异常实时检测方法包括:
7.对途径交换机的数据流进行过滤,得到异常流id,并将所述异常流id报 告给服务器防火墙,同时将包含所述异常流id的镜像流量发送给服务器;
8.所述服务器从所述镜像流量中分析所述异常流id,并得到所述异常流的 包序列;
9.所述服务器对得到的所述包序列进行高精度异常检测,并根据高精度异 常检测结果进行判断,得到一个判断信息,根据所述判断信息更新所述交换 机的黑名单。
10.作为进一步的改进技术方案,所述对途径交换机的数据流进行过滤包括:
11.提前将孤立森林转换成规则并部署在所述交换机上;
12.对途径所述交换机的数据流进行特征提取,得到流特征;
13.采用所述孤立森林转换的规则对所述流特征进行识别判断,得到一个识 别判断信息,根据识别判断信息确定异常流。
14.作为进一步的改进技术方案,所述将孤立森林转换成规则包括:
15.记录每个孤立树的分支值;
16.通过所述分支值将所述孤立森林的特征子空间域划分为多个细粒度的 域,并枚举所述细粒度的域的值。
17.作为进一步的改进技术方案,所述特征提取包括:
18.在所述交换机入口的第一个管道中采用双哈希算法计算五元组的索引, 并根据双哈希表算法计算数据存储的位置;
19.根据所述数据存储的位置读写流特征,得到流特征的数据包;
20.对所述流特征的数据包进行压缩,得到压缩包;
21.通过使用所述交换机的重新提交功能,将所述压缩包发送到所述交换机 入口的第二个管道内。
22.作为进一步的改进技术方案,所述将所述压缩包发送到所述交换机入口 的第二个管道内后,通过所述孤立森林转换成规则对异常进行识别,识别到 异常流后得到异常流的特征,此时所述交换机封装一个原始包头,并将异常 流特征添加到所述原始包头中,再将含有所述原始包头的数据包发送到所述 服务器。
23.作为进一步的改进技术方案,所述服务器从所述镜像流量中分析所述异 常流id,并得到所述异常流的包序列包括:
24.所述服务器根据所述镜像流量和所述异常流id匹配历史报文,得到匹配 结果;
25.根据所述匹配结果对所述异常流进行特征提取,得到所述异常流的包序 列。
26.作为进一步的改进技术方案,所述高精度异常检测通过构建一个深度检 测模型进行,所述深度检测模型包括自动编码器,所述自动编码器为非对称 的自动编码器模型。
27.作为进一步的改进技术方案,所述非对称的自动编码器模型采用可分离 卷积代替普通卷积层、采用扩张卷积代替原来的卷积操作及采用模型量化对 模型进行压缩。
28.作为进一步的改进技术方案,所述模型量化包括:
29.模型数据从浮点表示转换为较低精度的表示;
30.采用尺度量化的不对称变体来转换模型数据。
31.作为进一步的改进技术方案,所述深度检测模型和孤立森林的模型需要 在服务器上进行更新训练,所述更新训练包括:
32.重新训练所述孤立森林模型并部署到所述交换机上;
33.重新训练所述深度检测模型并部署到所述服务器上。
34.一种物联网异常实时检测装置,所述装置包括:
35.异常初筛模块,用于对途径交换机的数据流进行过滤,得到异常流id, 并将所述异常流id报告给服务器防火墙,同时将包含所述异常流id的镜像 流量发送给服务器;
36.分析模块,用于从所述镜像流量中分析所述异常流id,并得到所述异常 流的包序列;
37.高精度检测模块,用于对得到的所述包序列进行高精度异常检测,并根 据高精度异常检测结果进行判断,得到一个判断信息,根据所述判断信息更 新所述交换机的黑名单。
38.一种终端,所述终端包括:存储器及处理器,所述存储器存储有物联网 异常实时检测程序,所述物联网异常实时检测程序被处理器执行时用于实现 以下步骤:对途径交换机的数据流进行过滤,得到异常流id,并将所述异常 流id报告给服务器防火墙,同时将包含所述异常流id的镜像流量发送给服 务器;所述服务器从所述镜像流量中分析所述异常流id,并得到所述异常流 的包序列;所述服务器对得到的所述包序列进行高精度异常检测,并根据高 精度异常检测结果进行判断,得到一个判断信息,根据所述判断信息更新所 述交换机的黑名单。
39.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被 处理器执行时实现以下步骤:
40.对途径交换机的数据流进行过滤,得到异常流id,并将所述异常流id报 告给服务器防火墙,同时将包含所述异常流id的镜像流量发送给服务器;所 述服务器从所述镜像流量中分析所述异常流id,并得到所述异常流的包序列; 所述服务器对得到的所述包序列进行高精度异常检测,并根据高精度异常检 测结果进行判断,得到一个判断信息,根据所述判断信息更新所述交换机的 黑名单。
41.本发明采用上述技术方案具有以下效果:
42.本发明通过提前将孤立森林转换成规则并部署在所述交换机上,实现了 在交换机上通过无监督学习算法来对互联网进行恶意流量的检测,降低了成 本的同时提高了检测速率和精准度,通过在交换机上设计使用了双哈希算法 特征提取方案,降低了延迟和资源占用,提高了异常召回率,通过设置非对 称的自动编码器模型,可以在交换机初步检测流量后进一步检测,提高了检测 高精度,通过采用可分离卷积和扩张卷积及模型量化操作,使得模型能够每 秒处理百万个包。
附图说明
43.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实 施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面 描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲, 在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的 附图。
44.图1是本发明的一种物联网异常实时检测方法的流程图。
45.图2是本发明的一种物联网异常实时检测方法的框架图。
46.图3是本发明的一种物联网异常实时检测方法的交换机实现流程图。
47.本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步 说明。
具体实施方式
48.为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并 举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅 仅用以解释本发明,并不用于限定本发明。
49.发明人经过研究发现,若想在网络上实现对海量流量的低成本实时检测, 需要克服以下三点技术问题:
50.1.通常维护人员会使用基于规则的检测系统(例如基于端口的防火墙)辅 以离线采样分析来保护网络,而基于规则的检测无法检测到零日攻击,并且 很容易被绕过,与基于规则检测不同的是,应用无监督学习算法来检测恶意 流量是检测零日漏洞的有效方法,然而,这些方法将所有流量检测都放在服 务器的控制面上,不能以低成本提供令人满意的处理延迟和吞吐,为了达到 低成本的处理需要在交换机上部署无监督学习算法,然而在交换机上部署无 监督方法很困难,因为交换机的数据面仅支持简单指令来保证高速处理且资 源有限(如,状态表只有10-20个),这种限制阻碍了复杂模型的部署,导致 只能部署单棵决策树(dt)或基于阈值的模型,另外,如果在可编程交换机的 数据面上部署森林虽然可以实现在交换机上部署无监督学习算法,然而该方 法是采用编码表的方式将每棵树编码成一个状态表来实现森林,但可编程交 换机只有10-20状态表,因此,只能在交换机中部署
不超过10棵树。但森林 在树数量很少的情况下,并不能在大数据集中学习到很好地性能。
51.2.交换机上的流特征提取和维护也非常困难(例如,sram只有数百mb)。 这些特征必须使交换机的数据平面能够从服务器的控制面中卸载更多流量, 同时召回尽可能多的异常并消耗更少的资源,且现有一个连续发送的报文 (burst)报长序列可以推测出iot设备的事件类别和活动。其中burst指的是一 条流连续收发的报文时间间隔不超过一定阈值limitt。在之前,现有技术没有 考虑突发长度引起的资源占用问题,而在交换机中无法维持长序列突发。因 为可能存在长流keepalive,长流会导致长时间占用交换机的存储资源,这在 大流量环境下是不可行的。
52.3.现有的深度模型处理数据包的速率较低,不能适应大流量数据的处理。
53.为了解决上述问题,在本技术实施例中,通过提前将孤立森林转换成规 则并部署在所述交换机上,实现了在交换机上通过无监督学习算法来对互联 网进行恶意流量的检测,降低了成本的同时提高了检测速率和精准度,通过 在交换机上设计使用了双哈希算法特征提取方案,降低了延迟和资源占用, 提高了异常召回率,通过设置非对称的自动编码器模型,可以在交换机初步检 测流量后进一步检测,提高了检测高精度,通过采用可分离卷积和扩张卷积 及模型量化操作,使得模型能够每秒处理百万个包。
54.下面结合附图,详细说明本技术的各种非限制性实施方式。
55.如图1-2所示,一种物联网异常实时检测方法,所述物联网异常实时检测 方法包括:
56.s1、对途径交换机的数据流进行过滤,得到异常流id,并将所述异常流 id报告给服务器防火墙,同时将包含所述异常流id的镜像流量发送给服务 器;
57.所述对途径交换机的数据流进行过滤包括:
58.提前将孤立森林转换成规则并部署在所述交换机上;
59.对途径所述交换机的数据流进行特征提取,得到流特征;
60.采用所述孤立森林转换的规则对所述流特征进行识别判断,得到一个识 别判断信息,根据识别判断信息确定异常流。
61.具体的,采用孤立森林(iforest)是因为孤立森林模型训练具有近常数级的 计算复杂度,并且满足低常数和低内存要求,孤立森林模型主要是基于异常 的两点特性来实现:1.异常实例要少于正常实例,2.异常实例的特征值会显著区 别于正常值。
62.并通过孤立森林可通过一种隔离树(itree)结构来隔离每个实例,且由 于异常样例对隔离的敏感性,异常往往被隔离在更靠近树根的地方,而正常 的样例在树的较深端被隔离。
63.孤立森林在设计之初是用于隔离异常,而不是描绘正常的实例,因此往 往用于全局的离线检测中,因为隔离树随机从最大最小值范围中选择特征切 分点,并且其假设只要能隔离出异常的规则范围就行。因此当数据中出现个 别离群值,且容易区分时,其生成的正常行为规范范围就会很大。所以训练 集是具有多个行为事件的干净正常数据集时候,其正常行为的范围就比一般 范围要大,所以需要将异常分数的阈值设置的比孤立森林算法默认采用的要 低,因此需要将最后得到的决策分数减上一个偏置量,在这里通过调大sklearn 库中实现的孤立森林算法内的污染值(contamination)来间接实现需求。通过 控制污染值,从而间接的实现对正常行为范围大小的限制。
64.所述将孤立森林转换成规则包括:
65.记录每个孤立树的分支值;
66.通过所述分支值将所述孤立森林的特征子空间域划分为多个细粒度的 域,并枚举所述细粒度的域的值。
67.具体的,根据iforest和itree算法的理解,iforest是通过一系列的二叉 树切分点来实现对特征域的划分,其中切分后的特征域在一维上是多个线段, 而在二维下是多个正方形,在三维上则是多个正方体,在超维上是个超正方 体,并且这种在同一个划分后的细粒度特征域中其具有的异常得分是一致的, 同样的,孤立森林是多棵孤立树的集合,只是划分的特征域更细。
68.具体的iforest伪代码算法如下:
[0069][0070]
具体的itree伪代码算法如下:
[0071][0072]
因此通过记录每个孤立树的分支(branch)值,将特征空间域划分为多个 细粒度的特征域,并且枚举这些域的值,来实现iforest转换至规则。与现有 枚举方法相比,通过利用iforest算法中二叉树中同个域内的标签一致的特性, 将原有的无穷特征域空间减少至常数级可执行程度。
[0073]
具体iforest转换至规则的算法如下:
[0074][0075]
在获得细粒度的特征域后,如何高效的获得代表一个特征域内的样本至 关重要,通过分析iforest源码实现逻辑,发现左分支是小于等于,右分支是 大于等于,且在可编程交换机上,由于不支持浮点数运算,因此绝大部分特 征都是整数(如报头特征或者流总长),所以两个不相同且邻近的决策面中间一 定是存在一个整数,因此采用每个决策分支向下取整后的值作为该特征域的 样本。
[0076]
公式证明如下:
[0077]
设branch1,branch2,
…
,branchn为整数特征f的n个分支,则样例集合可 以表示为:
[0078]
feature_domain
←
set(floor(branch))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0079]
其中set为求集合,floor是向下取整。
[0080]
证明:假设分支branch为实数,由于特征是整数特征,并且分支判断条件是左 分支为小于等于,new_branch
←
set(floor(branch))因此可以将所有分支进 行求底,再求集合操作。这样使得新生成的各个分支都为整数且互不相同。
[0081]
于是特征域中的值x满足:
[0082]
new_branchi-1≤branchi-1《xi≤new_branchi≤branchi,即取底后的 new_branch一定在特征域空间中,且feature_domain==new_branch得证。
[0083]
这样选取样本可以涵盖所有特征域,且无遗漏。
[0084]
获取特征分支及其标签后,需要生成范围规则。通过将分支从小到大排 序,并将两个相邻分支之间的空间视为特征域空间,然后合并相同标签的特 征域空间,最后生成范围规则。
[0085]
另外,通过添加最大值inf作为每个特征f的边界分支,以解决多维特征 排序导致后一个分支的值小于前一个值的问题。
[0086]
所述特征提取包括:
[0087]
在所述交换机入口的第一个管道中采用双哈希算法计算五元组的索引, 并根据双哈希表算法计算数据存储的位置;
[0088]
根据所述数据存储的位置读写流特征,得到流特征的数据包;
[0089]
对所述流特征的数据包进行压缩,得到压缩包;
[0090]
通过使用所述交换机的重新提交功能,将所述压缩包发送到所述交换机 入口的第二个管道内。
[0091]
所述将所述压缩包发送到所述交换机入口的第二个管道内后,通过所述 孤立森林转换成规则对异常进行识别,识别到异常流后得到异常流的特征, 此时所述交换机封装一个原始包头,并将异常流特征添加到所述原始包头中, 再将含有所述原始包头的数据包发送到所述服务器。
[0092]
具体的,burst长度截断:使用双向流的burst包数和长度之和作为特征。 此外,通过设置包数截止阈值,以实现低资源占用和高实时异常检测。
[0093]
另外,为了减少交换机匹配双向五元组流的高复杂度操作,通过设计了一 种双哈希算法来实现双向流的突发包和的线性统计。具体的,将原始哈希函 数hash(dst_ip,src_ip,dst_port,src_port,protocol)分成两部分来计 算hash(dst_ip,dst_port,protocol) has(src_ip,src_port,protocol)。 这样通过提出的两个哈希和一个二元求和运算,可以将原来双向流五元组匹 配的复杂运算部署到交换机上。
[0094]
此外,为了防止大流量引起的哈希冲突,进一步设计了双哈希表算法。具 体的,通过将一个哈希表分为两个哈希表。当第一个哈希表中的值冲突时, 则对第一个哈希值执行哈希函数并将其分配给第二个哈希表。与仅使用一个 相同位宽的哈希表相比,双哈希表将减少一个数量级的冲突率。
[0095]
如图3所示,具体实施时,通过p4编程语言在可编程交换机上完成部署。 交换机主要有入口阶段和出口阶段。在入口(ingress)阶段,需要实现流识别、 流特征提取和存储以及异常检测,在出口(egress)阶段,主要进行包镜像和 异常流识别。
[0096]
在ingress的第一个管道中,首先是流识别。通过使用双哈希算法计算五 元组的索引,并根据双哈希表算法计算数据存储的位置。然后根据数据存储 的位置读写流特征。但是,由于tofino芯片的限制,流水线中的一个寄存 器只能读写一次。因此,读取和更新操作需要分布在不同的管道上。然后, 需要使用重新提交(resubmit)功能,并将数据包发送到第二个管道进行更新。 但是resubmit函数的数据长度限制在64位,而流特征(五元组、时间戳、突 发长度、包数)的占用率远远超过64位。因此,需要在第一个管道的末端压 缩特征从而形成压缩标志。具体来说,通过使用一些标志来通知下一个阶段 需要执行的操作,而不是发送所有的流特征。例如,判断桶1或桶2中存 在流特征,是否需要截断流,流是否超过突发的间隔阈值。
[0097]
在ingress的第二个管道中,交换机根据压缩标志(例如,突发间隔超时、 包数超过切割阈值)决定是否需要进行异常流识别。如果需要检测,则使用 孤立森林转换成的规则来识别异常。需要注意的是,通过将标志判断和异常 检测压缩到同一个规则匹配表中进行并行处理,如果需要进行异常流量判断, 则表示之前的突发流量统计已经结束,需要替换相应寄存器中的内容。否则, 更新流特征内容。
[0098]
在出口阶段,通过根据是否是异常流进行不同的操作。对于检测到的异常 流,通过封装最后一个原始包头,将异常流特征(突发长度、包数)添加到 新的包头中,并将包发送到服务器的相应端口。然后服务器根据交换机上报 的异常流五元组匹配历史报文,进行进一步检测。
[0099]
s2、所述服务器从所述镜像流量中分析所述异常流id,并得到所述异常 流的包序列;
[0100]
所述服务器从所述镜像流量中分析所述异常流id,并得到所述异常流的 包序列
包括:
[0101]
所述服务器根据所述镜像流量和所述异常流id匹配历史报文,得到匹配 结果;
[0102]
根据所述匹配结果对所述异常流进行特征提取,得到所述异常流的包序 列。
[0103]
s3、所述服务器对得到的所述包序列进行高精度异常检测,并根据高精 度异常检测结果进行判断,得到一个判断信息,根据所述判断信息更新所述 交换机的黑名单。
[0104]
所述高精度异常检测通过构建一个深度检测模型进行,所述深度检测模 型包括自动编码器,所述自动编码器为非对称的自动编码器模型。
[0105]
所述非对称的自动编码器模型采用可分离卷积代替普通卷积层、采用扩 张卷积代替原来的卷积操作及采用模型量化对模型进行压缩。
[0106]
具体的通过设计了一个非对称自动编码器的结构,而不是传统的对称自动 编码器。这是因为编码器需要更深的层才能更好地提取表示,而解码器可以 在没有过于复杂的操作的情况下重建特征。与对称自动编码器相比,这种非 对称结构保持了相似的性能,同时显着减少了参数数量,提高了训练速度和 吞吐量。
[0107]
可分离卷积:现有的mobilenets中,一个完整的2d卷积操作可以分解为 两个步骤,即深度卷积(depthwise convolution)和点卷积(pointwiseconvolution)。
[0108]
对于原始卷积层操作,输出通道上的每个特征图由所有输入通道上的卷积 核计算,因此一个输出通道需要input_channel
·
kernel_size参数量的卷积。 所以,一次卷积层的参数量与输出信道的数量和卷积kernel的大小成正比, 即,input_channel
·
kernel_size
·
output_channel。然而采用可分离卷积后, 深度卷积在输入层的每个通道上独立地执行卷积操作。换言之,采用组数等 于输入通道数的组卷积。也就是说,深度卷积的参数总数是 input_channel
·
kernel_size。此外,逐点卷积对来自深度卷积的所有输出通 道的信息进行加权组合,有效地利用了同一空间位置不同通道的特征信息。 因此,逐点卷积中的卷积核数为input_channel
·
output_channel。
[0109]
总的可分离卷积参数的总数是:
[0110]
input_channel
·
kernel_size input_channel
·
output_channel。
[0111]
扩张卷积:通过利用扩张卷积在magnifier中构建了一个大的感受野,这 些卷积以一定的扩张率跳过输入。直观地说,扩张卷积不是对小输入区域进 行细粒度视图,而是允许网络对网络进行粗略、广泛的视图。这使模型能够 实现与具有较少层的深度模型一样大的感受野,从而使模型能够在特征之间 获得更多信息。由于扩张卷积中使用的实际滤波器仍然与常规卷积中的相同, 因此参数数量和训练成本不会增加。
[0112]
所述模型量化包括:
[0113]
模型数据从浮点表示转换为较低精度的表示;
[0114]
采用尺度量化的不对称变体来转换模型数据。
[0115]
具体的,通过模型量化可优化深度检测模型,通过将模型数据从浮点表 示转换为较低精度的表示,通常使用8位整数,以使模型能够实现更高的吞 吐量、更低的延迟和内存消耗。深度检测模型采用尺度量化的不对称变体来 转换模型数据。详细地说,等式2定义了比例因子s,前提是选择的可表示 范围是[-α,α]并最终产生一个b位整数值。
[0116]
等式2:
[0117][0118]
然后,等式2定义了实值χ的比例量化,使用比例因子s产生χq。
[0119]
等式3:
[0120]
χq=quantize(χ,b,s)=clip(round(s
·
χ),-2
b-1
1,2
b-1-1)
[0121]
为了实现低精度损失的量化,需要为模型参数(如权重值和激活值)选 择一个合适的α来实现模型校准。对于权重值,使用校准期间看到的最大绝 对值的最大校准足以维持int8权重的准确性,因为它们的值不依赖于网络输 入。对于激活值,通过选择熵校准,它使用kl散度作为度量,以最小化原 始浮点值和可以由量化格式表示的值之间的信息损失。以上模型量化,通过 将pytorch转换至onnx再到tensorrt实现。
[0122]
所述深度检测模型和孤立森林的模型需要在服务器上进行更新训练,所 述更新训练包括:
[0123]
重新训练所述孤立森林模型并部署到所述交换机上;
[0124]
重新训练所述深度检测模型并部署到所述服务器上。
[0125]
关于模型计算的复杂度:
[0126]
分别在检测截断、训练阶段、规则转换阶段计算模型复杂度。
[0127]
检测阶段:在检测阶段,将iforest模型转换为规则并部署在交换机上。 由于可编程交换机硬件实现了流水线的m/a功能,模型检测可以在不增加额 外开销的情况下,在高吞吐量下实现零延迟处理速度。
[0128]
特征提取阶段:在特征提取阶段,只用到了hash算法加一次加法运算, 所以计算复杂度也是o(1)。
[0129]
训练阶段:在训练阶段,前人已证明计算复杂度是o(tψlogψ),而t一般 在400左右,ψ在3000以内。因此,实际计算开销也很小,几乎是恒定级别 的操作。
[0130]
在规则转换阶段时:由于需要遍历特征域中的值,因此计算复杂度与各 特征的分支数量有关。在itree伪代码算法得知单棵树的最高高度是 l=ceiling(log2ψ),因此在最差情况下单棵树的最大分支数为该树为二叉完全 树时即2
l 1-2,因此iforest总分支数在最差情况下为2t*(ψ-1)。在只有单 特征时候,转换规则的最差复杂度为o(tψ)。且在实际使用时候,由与itree 隔离异常的能力,单棵树的分支是远少于完全树的分支数,并且ψ和t不随数 据集大小变化,因此实际计算复杂度也是常数级的。
[0131]
综上,整个模型从训练到转换规则的复杂度不超过o(tψlogψ),是都可 以放在计算能力弱的设备上,并且可以实现实时的更新,以及实时的检测。
[0132]
一种物联网异常实时检测装置,所述装置包括:
[0133]
异常初筛模块,用于对途径交换机的数据流进行过滤,得到异常流id, 并将所述异常流id报告给服务器防火墙,同时将包含所述异常流id的镜像 流量发送给服务器;
[0134]
分析模块,用于从所述镜像流量中分析所述异常流id,并得到所述异常 流的包序列;
[0135]
高精度检测模块,用于对得到的所述包序列进行高精度异常检测,并根 据高精度异常检测结果进行判断,得到一个判断信息,根据所述判断信息更 新所述交换机的黑名单。
[0136]
一种终端,所述终端包括:存储器及处理器,所述存储器存储有物联网 异常实时检测程序,所述物联网异常实时检测程序被处理器执行时用于实现 以下步骤:
[0137]
对途径交换机的数据流进行过滤,得到异常流id,并将所述异常流id报 告给服务器防火墙,同时将包含所述异常流id的镜像流量发送给服务器;所 述服务器从所述镜像流量中分析所述异常流id,并得到所述异常流的包序列; 所述服务器对得到的所述包序列进行高精度异常检测,并根据高精度异常检 测结果进行判断,得到一个判断信息,根据所述判断信息更新所述交换机的 黑名单。
[0138]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被 处理器执行时实现以下步骤:
[0139]
对途径交换机的数据流进行过滤,得到异常流id,并将所述异常流id报 告给服务器防火墙,同时将包含所述异常流id的镜像流量发送给服务器;所 述服务器从所述镜像流量中分析所述异常流id,并得到所述异常流的包序列; 所述服务器对得到的所述包序列进行高精度异常检测,并根据高精度异常检 测结果进行判断,得到一个判断信息,根据所述判断信息更新所述交换机的 黑名单。
[0140]
本发明通过提前将孤立森林转换成规则并部署在所述交换机上,实现了 在交换机上通过无监督学习算法来对互联网进行恶意流量的检测,降低了成 本的同时提高了检测速率和精准度,通过在交换机上设计使用了双哈希算法 特征提取方案,降低了延迟和资源占用,提高了异常召回率,通过设置非对 称的自动编码器模型,可以在交换机初步检测流量后进一步检测,提高了检测 高精度,通过采用可分离卷积和扩张卷积及模型量化操作,使得模型能够每 秒处理百万个包。
[0141]
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人 员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于 本发明所附权利要求的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。