1.本发明涉及基于深度自编码器的航空发动机气路性能异常检测系统,属于航空发动机性能检测技术领域。
背景技术:
2.航空发动机作为飞机的核心部件,确保其安全运行是保障飞机安全运行的关键。由于航空发动机系统的复杂性及恶劣工作环境影响,会造成发动机异常,而发动机异常状况若不能被及时发现,将影响飞机的正常运行。
3.在所有发动机异常形式中,气路异常在总异常中占很大比例。目前针对气路异常的检测和维修方式均需耗费大量的人力和财力,并且准确性差,造成安全隐患。因此采用一种高效的方法实现航空发动机的气路异常检测对保障人类生命安全和减少经济损失有着重要的意义。
技术实现要素:
4.针对现有航空发动机气路异常的检测手段落后,检测结果准确性差的问题,本发明提供一种基于深度自编码器的航空发动机气路性能异常检测系统。
5.本发明的一种基于深度自编码器的航空发动机气路性能异常检测系统,包括,
6.深度自编码器模块,包括气路异常分数计算模块和基于迁移学习的深度特征提取模块ae3;其中气路异常分数计算模块包括编码器一、解码器一和解码器二;其中编码器一与解码器一组成深度自编码器ae1,编码器一与解码器二组成深度自编码器ae2;深度特征提取模块ae3包括编码器二和解码器三;
7.深度自编码器模块的训练过程包括:
8.深度自编码器ae1和深度自编码器ae2同时对输入的正常样本数据x进行重构,获得重构数据ae1(x)和ae2(x),并使重构数据ae1(x)和ae2(x)与正常样本数据x的差异最小;然后将重构数据ae1(x)输入深度自编码器ae2进行重构,获得重构数据ae2(ae1(x));对深度自编码器ae2的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最大;对深度自编码器ae1的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最小;深度自编码器ae1和深度自编码器ae2依次进行训练,构成对抗训练过程;
9.将正常样本数据x设置为源域,深度特征提取模块ae3对源域x进行重构,获得重构数据ae3(x),并使重构数据ae3(x)和正常样本数据x的差异最小,完成深度特征提取模块ae3的预训练;
10.再选择预设数量的正常数据和相同数量的异常数据共同设置为目标域y,针对目标域y基于迁移学习技术对预训练后深度特征提取模块ae3继续进行训练,获得重构数据ae3(y),并使重构数据ae3(y)与目标域y的差异最小,完成预训练后深度特征提取模块迁移学习的再训练;
11.从而完成深度自编码器模块的训练;
12.训练后深度自编码器模块中气路异常分数计算模块用于对输入检测数据w进行处理,获得重构数据ae1(w)和重构数据ae2(ae1(w));深度特征提取模块ae3中的编码器二用于对输入检测数据w进行处理,获得编码后深度特征e3(w);
13.随机森林分类器,根据输入的异常分数和编码后深度特征e3(w)进行异常判断,获得异常检测结果;所述异常分数由重构数据ae1(w)和重构数据ae2(ae1(w))相加获得。
14.根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,随机森林分类器的训练过程包括:
15.由重构数据ae1(x)和重构数据ae2(ae1(x))相加获得异常分数;由编码器二的输出获得编码后深度特征e3(x);
16.将所述异常分数和编码后深度特征e3(x)输入随机森林分类器,对随机森林分类器进行有监督训练,获得训练后随机森林分类器。
17.根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,所述正常样本数据x的获得方法包括:
18.获取多维度多变量时间序列原始数据γ:
[0019][0020]
式中t表示时间序列点的总个数,m表示每个时间序列点观测特征的总个数;x
ij
表示第i个时间序列点第j个观测特征的值;i=1,2,3,
……
,t;j=1,2,3,
……
,m;
[0021]
对原始数据γ采用步长为n的滑动窗口提取样本,获得正常样本数据x:
[0022][0023]
其中k表示正常样本数据x中的正常样本总个数,xk表示正常样本k;
[0024]
其中:
[0025][0026]
根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,按照获得正常样本数据x的方法获得检测数据w:
[0027]
[0028]
其中h表示检测数据w中检测样本总个数,wh表示检测样本h。
[0029]
根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,深度自编码器模块的训练过程中,使重构数据ae1(x)和ae2(x)与正常样本数据x的差异最小的计算方法包括:
[0030][0031][0032]
式中l
ae1
表示深度自编码器ae1的重构数据与正常样本数据x的差异值,l
ae2
表示深度自编码器ae2的重构数据与正常样本数据x的差异值;
[0033]
对深度自编码器ae1的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最小的计算方法包括:
[0034][0035]
对深度自编码器ae2的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最大的计算方法包括:
[0036][0037]
根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,根据深度自编码器ae1训练过程中获得的差异值获得深度自编码器ae1的损失函数:
[0038]
loss
ae1
=l
ae1
(x,ae1(x)) l
ae1
(x,ae2(ae1(x)))
ꢀꢀ
(8)
[0039]
根据深度自编码器ae2训练过程中获得的差异值获得深度自编码器ae2的损失函数:
[0040]
loss
ae2
=l
ae2
(x,ae2(x))-l
ae2
(x,ae2(ae1(x)))
ꢀꢀ
(9)
[0041]
进而得到:
[0042][0043][0044]
式中loss
ae1
表示深度自编码器ae1的损失函数,loss
ae2
表示深度自编码器ae2的损失函数;
[0045]
再继续对公式(10)和(11)进行演化,获得:
[0046][0047][0048]
式中n表示训练轮数。
[0049]
根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,深度特征提取模块ae3预训练过程中,使重构数据ae3(x)和正常样本数据x的差异最小的计算方法包括:
[0050][0051]
式中l
ae3
表示深度特征提取模块ae3的重构数据与正常样本数据x的差异值。
[0052]
根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,预训练后深度特征提取模块ae3迁移学习的再训练过程的计算方法包括:
[0053][0054]
l
ae3
表示深度特征提取模块ae3的再训练过程重构数据与目标域的差异值。
[0055]
根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,滑动窗口的步长为10。
[0056]
根据本发明的基于深度自编码器的航空发动机气路性能异常检测系统,预设数量的正常数据的获得方法包括:
[0057]
由正常样本数据x中选择预设数量的正常数据,或在正常样本数据x以外选择预设数量的正常数据。
[0058]
本发明的有益效果:本发明的气路异常分数计算模块利用对抗性的训练方法来计算异常分数,使其可以在快速训练的情况下有效隔离异常;然后,在异常分数的基础上采用深度特征提取模块提供深度特征进一步提高异常检测模型的性能;而对于小样本的异常数据引入迁移学习技术以学习其深度特征的有效表示。最终,将异常分数与深度特征共同输入随机森林进行异常检测。
[0059]
经验证,本发明系统的检测结果与现有方式的结果相比精度更高,具有明显的优势。
附图说明
[0060]
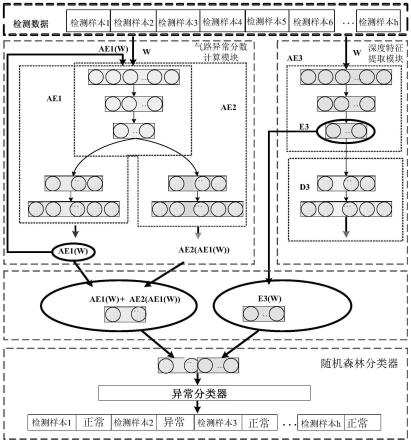
图1是本发明所述基于深度自编码器的航空发动机气路性能异常检测系统的原理框图;图中e3表示编码器二,d3表示解码器三;
[0061]
图2是深度自编码器模块的训练过程原理图;
[0062]
图3是通用自编码器的结构示意图;图中encoding1表示编码器第一个编码层的编码操作,encoding2表示编码器第二个编码层的编码操作,decoding1表示解码器第一个解码层的解码操作,decoding2表示解码器第二个解码层的解码操作;
[0063]
图4是具体实施方式中针对多台发动机获得的正常样本与异常样本的气路异常分数曲线图;
[0064]
图5是具体实施方式中针对单台发动机获得的气路异常分数曲线图;
[0065]
图6是具体实施方式中采用不同分类器获得的f1值示意图;其中dfen表示只使用基于迁移学习的深度特征提取模块 随机森林分类器的异常检测;ascn代表只使用气路异常分数计算模块 随机森林分类器的异常检测;aadmm代表使用气路异常分数计算模块 基于迁移学习的深度特征提取模块 随机森林的异常检测;aadmm即为本发明系统的检测方法;
[0066]
图7是采用本发明系统与其它六种方法进行异常检测的性能对比图。
具体实施方式
[0067]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0068]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0069]
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
[0070]
具体实施方式一、结合图1和图2所示,本发明提供了一种基于深度自编码器的航空发动机气路性能异常检测系统,包括,
[0071]
深度自编码器模块,包括气路异常分数计算模块和基于迁移学习的深度特征提取模块ae3;其中气路异常分数计算模块包括编码器一、解码器一和解码器二;其中编码器一与解码器一组成深度自编码器ae1,编码器一与解码器二组成深度自编码器ae2;深度特征提取模块ae3包括编码器二和解码器三;
[0072]
深度自编码器模块的训练过程包括:
[0073]
深度自编码器ae1和深度自编码器ae2同时对输入的正常样本数据x进行重构,获得重构数据ae1(x)和ae2(x),并使重构数据ae1(x)和ae2(x)与正常样本数据x的差异最小;然后将重构数据ae1(x)输入深度自编码器ae2进行重构,获得重构数据ae2(ae1(x));对深度自编码器ae2的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最大;对深度自编码器ae1的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最小;深度自编码器ae1和深度自编码器ae2依次进行训练,构成对抗训练过程;
[0074]
将正常样本数据x设置为源域,深度特征提取模块ae3对源域x进行重构,获得重构数据ae3(x),并使重构数据ae3(x)和正常样本数据x的差异最小,完成深度特征提取模块ae3的预训练;
[0075]
再选择预设数量的正常数据和相同数量的异常数据共同设置为目标域y,针对目标域y基于迁移学习技术对预训练后深度特征提取模块ae3继续进行训练,获得重构数据ae3(y),并使重构数据ae3(y)与目标域y的差异最小,完成预训练后深度特征提取模块迁移学习的再训练;
[0076]
从而完成深度自编码器模块的训练;
[0077]
训练后深度自编码器模块中气路异常分数计算模块用于对输入检测数据w进行处理,获得重构数据ae1(w)和重构数据ae2(ae1(w));深度特征提取模块ae3中的编码器二用于对输入检测数据w进行处理,获得编码后深度特征e3(w);
[0078]
随机森林分类器,根据输入的异常分数和编码后深度特征e3(w)进行异常判断,获得异常检测结果;所述异常分数由重构数据ae1(w)和重构数据ae2(ae1(w))相加获得。
[0079]
进一步,随机森林分类器的训练过程包括:
[0080]
由重构数据ae1(x)和重构数据ae2(ae1(x))相加获得异常分数;由编码器二的输出获得编码后深度特征e3(x);
[0081]
将所述异常分数和编码后深度特征e3(x)输入随机森林分类器,对随机森林分类器进行有监督训练,获得训练后随机森林分类器。
[0082]
再进一步,可以按照以下步骤完成检测系统的训练:
[0083]
首先进行数据预处理:航空发动机数据多为多变量时间序列,多变量时间序列数据是一个由多维度数据点组成的序列;
[0084]
所述正常样本数据x的获得方法包括:
[0085]
获取多维度多变量时间序列原始数据γ:
[0086][0087]
式中t表示时间序列点的总个数,m表示每个时间序列点观测特征的总个数;x
ij
表示第i个时间序列点第j个观测特征的值;i=1,2,3,
……
,t;j=1,2,3,
……
,m;
[0088]
原始数据γ中每一行数据都是特定时间点下对于不同数据特征测量的观测值。数据的每一行包含m个特征,单变量时间序列即是当m=1时的情况。本发明主要关注多变量时间序列问题的处理,因为单变量时间序列是多变量时间序列的一种特殊情况,因此本发明同样适用于单变量时间序列问题。
[0089]
航空发动机的运行数据与时间高度相关,为了更好的捕捉数据的时间序列特性,需要对γ采用滑动窗口的方法来提取样本。对原始数据γ采用步长为n的滑动窗口提取样本,获得正常样本数据x:
[0090][0091]
其中x作为训练模型的输入,x1,x2,x3,...,xk代表不同的样本,k表示正常样本数据x中的正常样本总个数,xk表示正常样本k;假设k个正常样本中不存在异常点;
[0092]
其中:
[0093][0094]
与训练过程相同,异常检测过程中,同样是以滑动窗口处理数据来提取样本,获得的检测数据为w。
[0095]
按照获得正常样本数据x的方法获得检测数据w:
[0096][0097]
其中h表示检测数据w中检测样本总个数,wh表示检测样本h。
[0098]
以某航空公司的实际航空发动机运维数据为例,使用滑动窗口方法对于航空发动机数据进行预处理。当滑动窗口的步长n选择为10时,最终获得的发动机数据样本如表1所示。
[0099]
表1
[0100][0101]
表1中degt为排气温度变化量,dn2为核心机转速变化量,dff为燃油流量变化量,zpcn12为风扇转速;
[0102]
气路分数计算模型训练:
[0103]
传统深度自编码器是一种包含输入层、隐含层和输出层的无监督人工学习网络,结构如图3所示。
[0104]
设输入数据样本为x,经过多次解码过程即可获得输入数据的重构表达,整个解码过程可以简写为d(h),h表示中间层的深度特征,对深度特征解码即还原出x;其中重构数据整个深度自编码器处理输入数据x的过程可以简写为ae(x),其中自编码器的训练目标是重构误差最小化,重构误差l
ae
的计算定义为:
[0105][0106]
通常使用自编码器进行异常检测是使用重构误差作为异常分数,由于自编码器训练的过程是尽可能的重建输入数据,当训练过程输入均为正常数据时,自编码器对于正常数据的重构会变得容易,而自编码器对于未遇到的异常样本将会重构困难,具体表现为异常数据的重构误差大,此处一般定义一个临界值,超过临界值的即为异常情况。但是仅使用重构误差作为异常分数进行检测可能不是最好的选择,因为如果异常很小,与正常样本比较相近,则重构误差也相应的比较小,会导致无法检测这部分异常。针对这个问题,考虑到生成对抗网络可以基于生成器和辨别器两个网络之间的博弈来提高判别器区分正常样本和伪造样本的能力,这种对抗性的训练方法可以借鉴来解决小异常样本难以区分的问题。但是由于生成对抗网络的生成器接受的数据来自于随机噪声分布,会导致生成对抗网络训
练不稳定的问题。本发明考虑将生成对抗网络的思想应用于自编码器架构,分为两阶段进行训练,第一阶段两个自编码器各自重构输入样本,与普通自编码器的训练过程相同;而第二阶段,两个自编码器功能分别对应于生成对抗网络的生成器和辨别器,与其不同之处在于,生成器接受的数据来自于另一个自编码器重构出的数据,生成器训练生成可以欺骗辨别器的伪造样本,辨别器训练区分伪造样本与真实样本,因为输入数据并不是随机噪音分布,训练更容易收敛,自编码器的结构使得对抗训练获得了稳定性,而对抗训练使得模型增强了对于异常样本的区分能力两者相辅相成,克服了各自的缺点。
[0107]
将这种基于对抗训练方法的自编码器架构称为ascn,ascn基于两阶段的训练任务进行训练,并最终输出一个代表样本异常情况的异常分数,ascn综合考虑两阶段的训练任务,结合对抗性训练的特点,重定义了一个新的气路异常分数,气路异常分数可以代表样本异常情况的表达。ascn的训练过程如图2所示,其包含一个编码器网络和两个解码器网络,两个解码器网络共同使用来自于同一个编码器的输出,组成了两个深度自编码器ae1和ae2,两个深度自编码器对输入数据x进行处理表示为ae1(x)和ae2(x)。训练过程中,首先两个深度自编码器ae1和ae2均重构输入数据x,然后,将ae1重构出来的伪造数据输入ae2,企图欺骗ae2,而ae2的目标是让其可以区分是原始输入x还是ae1重构出来的数据ae1(x),整个ascn的训练过程表述如下:
[0108]
1)第一阶段的训练:目标是训练ae1和ae2来重构输入x,ae1和ae2同时进行训练,将输入数据x通过编码解码的操作重构为ae1(x)和ae2(x),并使得重构误差尽可能的小。
[0109]
深度自编码器模块的训练过程中,使重构数据ae1(x)和ae2(x)与正常样本数据x的差异最小的计算方法包括:
[0110][0111][0112]
式中l
ae1
表示深度自编码器ae1的重构数据与正常样本数据x的差异值,l
ae2
表示深度自编码器ae2的重构数据与正常样本数据x的差异值;
[0113]
2)第二阶段的训练:目标是训练ae2区分真实的数据与来自ae1的数据,在此阶段,将ae1的重构输出ae1(x)输入ae2,基于对抗训练策略,ae1的训练目标是最小化原始输入与ae2再重构的输出ae2(ae1(x))之间的差距,而ae2的训练目标是放大他们之间的差异,两者形成了对抗训练的架构。
[0114]
对深度自编码器ae1的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最小的计算方法包括:
[0115][0116]
对深度自编码器ae2的训练使正常样本数据x与重构数据ae2(ae1(x))的差异最大的计算方法包括:
[0117][0118]
将以上两阶段的训练目标组合到一起,那么ae1是使第一阶段训练的x和ae1(x)重构误差最小,使第二阶段训练的x和ae2(ae1(x))的差异最小;ae2是使第一阶段训练的x和
ae2(x)最小,使第二阶段训练的x和ae2(ae1(x))的差异最大(此处取负号),这样的双重训练目标可以组合为loss函数:
[0119]
根据深度自编码器ae1训练过程中获得的差异值获得深度自编码器ae1的损失函数:
[0120]
loss
ae1
=l
ae1
(x,ae1(x)) l
ae1
(x,ae2(ae1(x)))
ꢀꢀ
(8)
[0121]
根据深度自编码器ae2训练过程中获得的差异值获得深度自编码器ae2的损失函数:
[0122]
loss
ae2
=l
ae2
(x,ae2(x))-l
ae2
(x,ae2(ae1(x)))
ꢀꢀ
(9)
[0123]
进而得到:
[0124][0125][0126]
式中loss
ae1
表示深度自编码器ae1的损失函数,loss
ae2
表示深度自编码器ae2的损失函数;
[0127]
对于loss
ae2
函数的可行性分析:真实的样本是x,此处为了分析将其标注为pos(x),ae1伪造的样本是假样本,此处标注为neg(x),则ae1(pos(x))=neg(x),将ae1和ae2的重构误差以error表示,忽略开平方后的二次项,进而上式可以表示为:
[0128][0129]
对抗性训练体现在loss
ae2
的训练中,模型训练时通过反向传播减小loss
ae2
,即减小error
ae2
(pos(x)),这个过程增加了ae2对于真实数据pos(x)的重构能力,而相应的,由上式可知,error
ae1
(pos(x))和error
ae2
(neg(x))均会增大,训练error
ae1
(pos(x))增大代表使得ae1伪造样本的能力下降,而error
ae2
(neg(x))增大代表使得ae2对于伪造样本的重构能力下降,以上总体可以实现对抗性训练的目标,即可使得ae2对于区分伪造样本与真实样本的能力得到增强,可以确定loss函数的有效性,因此:
[0130]
再继续对公式(10)和(11)进行演化,获得:
[0131][0132][0133]
式中n表示训练轮数。
[0134]
训练完成后,在异常检测阶段,将航空发动机数据预处理后输入ascn,可以获得气路异常分数s,作为后续异常检测的重要信息,此时气路异常分数需包含两部分训练信息,定义为:
[0135]
s=l
ae1
(w,ae1(w)) l
ae2
(w,ae2(ae1(w)))
[0136]
根据使用重构误差进行异常检测的经验,此时可以设置一个临界值,气路异常分数超过临界值的即可被判定为异常,但是设置临界值的方式并不方便,如何选择合适的临界值是一个问题,并且,只是使用一个临界值来判断数据样本的异常情况并没有充分利用异常分数的全部信息;气路异常分数代表了数据的特征情况,应该被更有效的使用,此时,考虑可以使用气路异常分数与随机森林结合的方式,将数据对应的气路异常分数输入随机森林进行分类,判断数据的异常情况,后续实验也证明了这种方式的有效性。但是由于航空发动机异常检测的性能提升对于航空公司来说,可以创造巨大的经济价值以及减小人力物力的浪费,并且气路异常分数更注重的是数据的异常情况,可能对于数据的特征概括并不全面,考虑加入数据的深度特征与其一起输入随机森林可以进一步提高对于数据的使用,提高模型的性能。
[0137]
深度特征提取模块ae3的训练:
[0138]
dfen是一个引入迁移学习的自编码器架构,它的训练过程如图2所示。dfen的训练目标是获得原始输入数据的深度特征。航空发动机实际运行过程中异常样本量很少,若直接输入自编码器之中进行深度特征学习,可能无法学习到异常样本的有效特征表示。相比较之下,收集大量的正常样本往往容易,并且针对发动机的实际运行状况,虽然正常样本与异常样本的特征分布不同,但是他们的性能参数均是来自同一型号的发动机,样本之间具有一定的相似性,迁移学习可以将源域的深度特征知识迁移到目标域之中,提高模型提取目标域深度特征的能力,因此迁移学习非常适合引入该模型之中来提高提取小数据量异常样本深度特征的能力。dfen的训练首先使用大量的正常样本x来进行模型预训练,即是针对源域的模型训练。再使用迁移学习技术输入少量异常样本与少量正常样本y,对预训练好的模型进行微调,使得模型进一步适应异常样本的数据特点,引入迁移学习的自编码器可以更好的提取异常样本的深度特征。整个dfen的训练过程可以表述如下:
[0139]
(1)预训练阶段:深度特征提取模块ae3预训练过程中,将大量正常样本设置为源域,针对源域x训练深度自编码器ae3,使重构数据ae3(x)和正常样本数据x的差异最小的计算方法包括:
[0140][0141]
式中l
ae3
表示深度特征提取模块ae3的重构数据与正常样本数据x的差异值。
[0142]
(2)迁移学习阶段:在此阶段,将相同数量的异常样本与正常样本设置为目标域,基于迁移学习的技术对自编码器ae3继续训练,将源域学习到的特征迁移到目标域之中,预训练后深度特征提取模块ae3迁移学习的再训练过程的计算方法包括:
[0143][0144]
l
ae3
表示深度特征提取模块ae3的再训练过程重构数据与目标域的差异值;由此实现深度特征提取模块ae3的微调。
[0145]
训练完成后,在异常检测阶段,将航空发动机正常和异常样本输入dfen,可以提取出它们对应的深度特征。
[0146]
采用训练后的深度自编码器模块进行异常检测:
[0147]
深度自编码器模块aadmm的异常检测阶段如图1所示,将需要进行异常检测的航空
发动机数据预处理后输入aadmm,ascn部分输出气路异常分数s,dfen部分输出对应深度特征e3(w),将气路异常分数s与e3(w)共同作为航空发动机异常检测的重要特征输入随机森林分类器,判断待检测数据w是否异常。本发明的意义在于将基于对抗训练的气路异常分数计算模型与基于迁移学习的深度特征提取模型结合起来共同进行异常检测,最终的分类器可根据实际需要进行选择。aadmm最终的异常分类器采用随机森林进行异常检测,最终对每个检测样本作出正常或异常的判断。
[0148]
随机森林是随机树分类器的组合,随机森林的核心是对于训练集进行重采样,组成多个训练子集,每个子集生成一个决策树,所有随机树通过投票的方式进行决策,共同组成随机森林。随机森林具有训练速度快,精度高、不容易过拟合、实现简单等优点,但是对于某些噪音较大的数据,随机森林的分类会造成过拟合,影响最终的训练结果。对于航空发动机而言,其实际运维数据往往包含大量的噪声,并且正负样本严重不均衡,因此直接使用随机森林效果是不佳的,但是经过ascn和dfen对航空发动机数据的处理,并且与随机森林算法相结合,可以弥补随机森林算法固有的缺点,并且经过深度特征提取的数据噪声被大量过滤,更适合于随机森林算法。本发明中,获得输入样本的气路异常分数和深度特征以后,将他们共同输入随机森林获得最终的异常检测结果。
[0149]
作为示例,滑动窗口的步长为10。
[0150]
进一步,预设数量的正常数据的获得方法包括:
[0151]
由正常样本数据x中选择预设数量的正常数据,或在正常样本数据x以外选择预设数量的正常数据。
[0152]
定义评价指标:
[0153]
在机器学习分类模型中最常见的性能指标是精度,它的定义如下:
[0154][0155]
式中acc为精度值,∏(
·
)为指示函数,若
·
为真,则取值为1,否则取值为0;
[0156]hθ
(xi)为学习得到的模型,输出当前正常样本经计算获得的类别,yi为当前正常样本的实际类别,即为正常还是异常。通过计算获得的类别和实际类别进行比较获得精度值。
[0157]
由于大多数异常检测方法面对的数据都是不均衡样本,航空发动机的全生命周期运行中,大部分时间也都是正常状态下运行,这造成收集到的发动机气路状态监测数据正常样本往往远远多于异常样本,即气路监测数据是类别不均衡的样本。为了更好的适应异常检测的数据类型,可采用精确率p和召回率r作为主要性能参考指标。针对航空发动机样本,精确率p是指“经过异常检测确定的发动机异常样本中有多少是真正发生了异常”,召回率r是指“发动机发生气路异常的样本有多少比例被检测出来”。p和r的表达式分别如下:
[0158][0159][0160]
式中tp为异常样本并且被算法判断为异常的样本数量,fp为正常样本并且被算法判断为异常的样本数量,fn为异常样本并且被算法判断为正常的样本数量。
[0161]
可以发现,精确率p与召回率r是相异的一对评价指标,当精确率p提高时,相应的
召回率会下降,反之亦然。对于航空发动机异常检测而言,召回率r非常重要,因为当召回率r降低,代表着有一些发动机的异常没有被发现,在这种情况下使用发动机将会存在潜在的危险,甚至威胁乘客的人身安全。但是精确率也是很重要的,因为当精确率降低的时候,将部分正常的发动机判断为异常的比例将提高,浪费人力物力,对于航空公司来说,暂停航空发动机的使用来进行故障排查意味着大量的经济损失。为了兼顾精确率和召回率,一个常用的指标是f1值,f1值是精确率p和召回率r的调和均值,兼顾了两者,f1函数的公式如下:
[0162][0163]
异常分数模块可行性分析:
[0164]
aadmm中的重要组成部分是对数据样本进行气路异常分数的计算,发动机样本的气路异常分数对于发动机异常检测是非常重要的,可以作为最终异常检测的重要特征。
[0165]
本文进行了两部分的实验来证明气路异常分数对于异常检测的有效性:
[0166]
第一部分:由于发动机的异常样本较少,一般将发动机拆卸前的一部分飞行循环视为异常,因此每一台发动机可以提取的异常样本很少,所以可将多台航空发动机的异常样本整合到一起,共同组成可以代表整体航空公司发生发动机异常情况的数据样本,并随机选取每台发动机与异常样本相同数量的正常样本,代表航空公司发动机正常运行时的数据样本。将这两部分数据输入aadmm的ascn部分,计算正常样本与异常样本的气路异常分数,如图4所示,图4中,处于上方的曲线代表异常数据样本的气路异常分数,下方曲线代表正常数据样本的气路异常分数,可以发现异常数据样本的气路异常分数普遍高于正常数据样本,并且具有良好的可分性,除了小部分数据有重叠,可以明显区分正常和异常。
[0167]
第二部分:与第一部分的实验相似,但是此处只选择一台发生异常的航空发动机,针对其拆卸前一段时间的运行数据进行实验,直接将这台发动机最后一段时间飞行循环的数据样本输入aadmm的ascn部分,计算气路异常分数并绘图,结果如图5所示,可以发现,越靠近拆卸的飞行循环,气路异常分数越大,并且有非常明显的突变,从整体来看,这一台发动机拆卸前一段时间的飞行循环的气路异常分数,相对正常样本比较大,已经出现了一些异常的问题。
[0168]
由以上实验可以确定,针对航空公司发动机的实况数据,可以使用气路异常分数来反映发动机正常样本与异常样本之间的差异性,并且效果很好,气路异常分数对于两者有着良好的区分性,后续实验也可以发现增加了气路异常分数部分的异常检测性能有明显的提升。因此,将发动机气路异常分数作为最终异常分类的重要特征之一是合理的。
[0169]
实验结果及分析:
[0170]
为了验证aadmm具有优秀的异常检测性能,并且每一部分模型结构对于aadmm都拥有重要的影响,此处进行了三组对比实验,三组实验的结果如表2所示,其中针对航空发动机的实际情况,精确率p和召回率r都十分重要,f1分数同时考虑了两者,因此将作为主要判断性能的结果:
[0171]
第一组实验,理论上气路异常分数可以代表数据的异常情况,可以作为异常分类的重要特征,只使用气路异常分数输入后续异常分类器,是否会取得不错的异常检测新效果,本组实验的目的就是为了证明这个结构,输入样本后,将ascn计算得到的异常分数直接输入六种分类器计算精确率p、召回率r和f1分数。
[0172]
第二组实验训练自编码器并提取数据的深度特征,不计算气路异常分数,对应于aad mm的dfen部分,获得预训练模型后再使用部分异常样本对于自编码器进行迁移学习,微调模型后进行正常样本和异常样本的深度特征提取,最终输入svm,随机树,梯度提升决策树,k近邻,朴素贝叶斯,随机森林六种分类器计算精确率p、召回率r和f1分数。
[0173]
第三组实验在第二组实验的基础上,再加入异常检测分数,输入数据样本经过由迁移学习微调的模型进行深度特征提取后,与气路异常分数共同作为输入,输入六种分类器,计算精确率、召回率和f1分数。
[0174]
表2
[0175][0176]
其中第一组只使用了异常分数计算模块的功能与分类器结合,也就是ascn 分类器:
[0177]
其中score表示异常分数,svm表示支持向量机分类器,tree表示随机树分类器,gbdt表示梯度提升决策树分类器,knn表示k近邻分类器,nb表示朴素贝叶斯分类器,forest表示随机森林分类器;
[0178]
第二组只使用了深度特征提取模块的功能与分类器结合,其中dae tl表示深度特
征提取模块;
[0179]
第三组使用了异常分数计算模块、深度特征提取模块与分类器结合;其中dae tl score forest即为采用本发明系统进行的检测。
[0180]
结合图6所示,第一组实验只使用aadmm的ascn部分来做航空发动机数据的异常检测,也就是只对航空发动机的输入样本计算气路异常分数,然后使用获得的气路异常分数与六种异常分类器结合做异常检测,主要目的是验证气路异常分数对于最终异常检测的有效性。由表2中结果可以发现,就算只使用气路异常分数直接作为异常分类的特征,也可以达到不错的效果,其中除了svm和nb两种分类器对于气路异常分数的分类效果不佳,f1分数均小于0.5以外,其余分类器的效果基本都在0.8左右,对于航空发动机异常检测来说,虽然性能效果不是特别好,但是也可以说明气路异常分数是可以作为异常检测的重要特征的,对于最终异常检测效果具有很大的影响。
[0181]
在第二组实验中主要目的是只使用aadmm的dfen部分来做航空发动机数据的异常检测,此处使用大量航空发动机数据对深度自编码器模型进行预训练后,使用小部分异常样本对模型进行迁移学习,获得深度特征提取模型。使用训练好的dfen提取测试样本的深度特征后,使用六种机器学习方法进行异常检测分类。由表2实验结果可以发现,使用深度自编码器 迁移学习 分类器也可以达到一个相对比较高的异常检测精度,使用gbdt和forest分类器的性能相对最好,三者的f1分数均可以达到0.9以上,gbdt的f1分数是最佳的,forest略逊色于gbdt。结合svm和nb分类器的异常检测方法效果最差,可能是由于提取了深度特征以后,容易对这两种方法造成过拟合,造成测试效果不佳。通过第二组实验可以发现,只使用dfen对航空发动机数据进行异常检测,也可以达到不错的效果,但是最终结合不同分类器的效果差异较大,应结合实际进行选择。
[0182]
第三组实验是对于aadmm最终的分类器进行调整,对第一组与第二组实验的模型功能进行结合,既使用经过迁移学习微调的深度自编码器进行特征提取,也计算经过对抗训练自编码器获得的气路异常分数,将获得的深度特征与气路异常分数工作输入最终的六种分类器做异常检测,分析对于两者结合的模型不同的分类器会有什么影响,并且两者结合的效果如何。由表2中结果可知,将深度特征与气路异常分数结合的模型效果明显优于只使用其中深度特征或者气路异常分数的效果,并且性能有明显提升。其中,使用dae tl score forest的异常检测模型效果是最佳的,也就是本发明提出的aadmm模型,针对本发明中的航空发动机数据,选择forest作为最终异常检测分类器,aadmm的精确率、召回率和f1分数分别达到了0.9691,0.9126,0.9400;值得一提的是,与gbdt结合的分类效果也是很不错的,实际使用中,可根据实际情况选择不同的异常分类器。
[0183]
为了验证aadmm与其他方法直接对比的性能情况,下面直接使用svm,随机树,梯度提升决策树,k近邻,朴素贝叶斯,随机森林等共六种分类器对于选择好的样本进行分类,为了照顾部分分类器无法处理不均衡样本的特性,筛选了与异常样本相同数量的正常样本,保证二分类样本的均衡性,计算分类结果的精确度、召回率和f1分数,其结果如表3所示。
[0184]
表3
[0185][0186]
表3对比了六种异常检测方法的性能,可以发现nb的性能效果最差,f1分数只有0.5399,而gbdt和forest的效果也都达到了0.9以上,本发明的aadmm的f1分数是0.94,效果是对比方法中的最佳。因为分类的正负样本的数量是对等的,因此还对比了七种方法的精度,aadmm的精度达到了0.9412,也是对比方法中的最佳。因此可知,本发明的aadmm针对航空发动机数据样本具有良好的异常检测性能,在各项性能指标中均表现优异
[0187]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其它所述实施例中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
