1.本发明涉及基于优化随机森林的车载容迟网数据报文转发方法,属于车载容迟网络中路由协议的领域。
背景技术:
2.车载容迟网络(vehicular delay tolerant networks,vdtns)是一种将延迟容忍网络应用到车联网中的一种新型网络结构,通过车辆节点的移动、相遇带来的机会进行数据的“存储-携带-转发”(store-carry-forward)的路由模式来实现通信。在传统的网络中,通常都是依赖于一些基础设施,所以针对这种类型的网络研究都是基于确定的端到端的连接假设。然而在动态环境中是无法保证网络是贯穿始终的端到端的连接。因此,通过利用延迟容忍网络(dtn,delay-tolerant network,或disruption-tolerant network)解决了在极端情况下缺乏端到端的连接下的通信问题。在实际应用,车载容迟网络能有效解决道路拥塞管理、交通事故传播等,这些应用场景通常具有传输延迟大、传输率低、网络拥塞、排队时间长等特点。
3.目前已有的典型算法包括epidemic、spray and wait和prophet等。epidemic是基于泛洪策略的路由算法,每个车辆节点都将报文副本传递给相遇的所有邻居节点,可以最大化的提升成功的投递率,但是在实际环境下,消息泛洪往往会导致网络拥塞。spray and wait路由算法则通过限制消息副本的数目来解决消息泛洪问题,但与此同时,该算法的投递率等性能指标也有所降低。prophet路由算法则利用节点相遇的历史信息估计不同节点与消息目的节点之间的相遇概率,根据相遇概率决定消息转发策略。然而,在vdtn中,车辆的移动通常具有特定的模式,例如公交车遵循固定的路线和时刻表,私家车的移动倾向于有规律的轨迹,出租车的移动行为则体现了人流的热区等。而prophet路由算法并没有很好地考虑车辆的这些移动模式。近几年随着机器学习的兴起,许多机器学习中的算法都被应用到dtn路由算法,比如决策树、强化学习、朴素贝叶斯分类器等。然而,决策树泛化能力差,而且并不够稳定,小部分数据的变化会导致生成结构相差较大的树形结构。强化学习则收敛速度较慢,并导致额外的网络路由开销。虽然朴素贝叶斯分类器简单高效,但是它的条件独立性假设使其无法表达出属性间的依赖关系,从而降低了分类的准确率。而本专利分别从分类性能和多样性两个衡量标准出发,对随机森林进行优化。首先,从分类性能出发,根据每棵树的分类错误率以及在森林中的表现分别给予局部和全局惩罚,从而挑选出在森林中准确率高的的树,使其拥有较高的决策权重。其次,再根据多样性评判指标-不合度量来评判决策树的相似度,继而挑选出相似度较低的决策树,不仅保证了泛化能力同时还提高了准确率,因此路由决策是基于优化的随机森林模型,可以进一步提高容迟网的性能。
技术实现要素:
4.发明目的:本发明目的提供一种基于优化随机森林的车载容迟网数据报文转发方法,该方法着重考虑了泛化能力和准确率,相较于现有算法,能够有效提高网络性能。
5.技术方案:本发明为实现上述发明目的,采用如下技术方案:一种基于优化随机森林的车载容迟网数据报文转发方法,该方法包括如下步骤:
6.步骤1、获取每个车载容迟网络车辆节点的历史数据表,并对车辆属性进行划分;
7.步骤2、根据每个车载容迟网络车辆节点的属性建立训练集,并根据训练集建立初始随机森林模型;
8.步骤3、根据每棵决策树的权重和相似度对随机森林模型进行优化;
9.步骤4、当携带数据报文的车辆节点与其他车辆节点相遇时,若相遇车辆节点为数据报文的目的车辆节点时,此时数据报文直接被投递到相遇车辆节点;如果相遇的车辆节点不是目的车辆节点时,进入步骤5;
10.步骤5、利用优化后的随机森林模型预测当前车辆节点的投递等级x
8,当前
和相遇车辆节点投递等级x
8,相遇
;
11.步骤6、若x
8,当前
>x
8,相遇
,则当前携带数据报文的车辆节点会继续携带报文,转到步骤4;否则,当前携带数据报文的节点将数据报文转发给相遇节点,由相遇节点继续转发报文,本次转发结束。
12.进一步的,步骤1的具体方法如下:
13.每个车载容迟网络车辆节点均维护一张数据报文转发历史数据表,根据实际路线中车辆轨迹特点进行属性的划分,其属性包括:区域码x1、时间戳x2、平均接触时间间隔x3、运动方向x4、速度x5、平均时延x6、距离x7和投递等级x8;其中,区域码是对地理区域的编码,即将整个网络的地理区域以10m
×
10m的大小划分为不同的网格,对每个网格赋予一个唯一的区域码,用于记录数据报文转发时车辆节点所处的位置;时间戳是对时间段的编码,即将一天24小时以10分钟为间隔单位依次离散化编码,用于记录数据报文转发的时间;平均接触时间间隔是在数据报文转发前1小时内该车辆节点与其他车辆节点相遇的平均间隔时间,并以1分钟为单位依次离散化编码;运动方向是车辆节点在数据报文转发时的运动方向,划分为东、西、南、北、东南、东北、西南、西北8个运动方向;速度是车辆节点在数据报文转发时的行驶速度,以历史数据集为依据,并以20km/h为单位依次离散化编码;平均时延表示数据报文从源车辆节点转发到目的车辆节点所经过的平均时间,以2000s为单位依次离散化编码;行驶距离是车辆节点自上次转发数据报文后到本次数据报文转发时行驶的距离,以8km为单位依次离散化编码;投递等级是车辆节点转发数据报文的能力,用该车辆节点已成功转发数据报文数量来表示,并以100为单位依次离散化编码,并且根据每个车载容迟网络车辆节点获得区域码x1、时间戳x2、平均接触时间间隔x3、运动方向x4、速度x5、平均时延x6、距离x7和投递等级x8作为一个数据样本。
14.进一步的,步骤2的具体方法如下:
15.步骤2.1:将所有车载网络车辆节点对应的样本形成数据集合m,按均匀分布随机地将历史数据集m中80%的样本划分为训练数据集f,20%样本划分为测试数据集d;
16.步骤2.2:通过自助重采样技术,从训练数据集f中有放回地重复随机抽取70%的数据,生成以属性x1到x7作为内部节点,投递等级x8为预测目标的分类回归决策树,也即cart树;
17.步骤2.3:重复上述步骤2.2,最后组成t棵决策树的初始随机森林,t>=100。
18.进一步的,步骤3的具体方法如下:
19.设测试数据集的样本数量为|d|,对于第i个样本,i∈[1,|d|],其投递等级标签为ci,ci∈[1,c],c为最大投递等级数;设为初始随机森林中的决策树j对样本i的预测分类,j∈[1,t];表示初始随机森林对样本i预测的分类;
[0020]
步骤3.1、设置每棵决策树的权重;
[0021]
步骤3.2、计算每棵决策树的相似度;
[0022]
步骤3.3、将所有决策树按照权重wj降序排序,选取前n个权重对应的决策树,再将这n棵决策树按相似度simj进行升序排序,选择前s棵决策树以构成最终的优化随机森林模型,所有车载网络车辆节点上都使用该模型预测车辆节点的投递等级。
[0023]
进一步的,步骤3.1的具体方法如下:
[0024]
步骤3.1.1、计算决策树j的局部惩罚因子pj;
[0025][0026]
其中,为决策树j预测投递等级错误的样本数据集pj表示决策树j的预测错误率;|qj|为数据集样本的数量;
[0027]
步骤3.1.2、计算决策树j的全局惩罚因子
[0028][0029]
其中,为决策树j与初始随机森林预测的投递等级不一致的样本数据集,表示决策树j相对于初始随机森林的预测错误率;
[0030]
步骤3.1.3、计算决策树j的权重wj:
[0031][0032]
进一步的,步骤3.2的具体方法如下:
[0033]
步骤3.2.1、计算决策树j的不合度量disj:
[0034][0035]
其中,表示对投递等级决策树j预测为正确而决策树1预测为错误的样本集合,表示对投递等级决策树1预测为正确而决策树j测为错误的样本集合;
[0036]
步骤3.2.2、计算决策树j的相似度simj:
[0037]
simj=1-disj。
[0038]
进一步的,步骤5中,利用随机森林模型预测当前车辆节点的投递等级x
8,当前
和相遇车辆节点投递等级x8,相遇具体方法如下:
[0039]
如果相遇的车辆节点不是目的车辆节点时,此时当前携带数据报文的车辆节点获
取属性区域码x1、时间戳x2、平均接触时间间隔x3、运动方向x4、速度x5、平均时延x6、距离x7的当前值,并生成包括属性x1,x2,
…
,x7的实例样本i
′
,并利用优化的随机森林模型预测样本i
′
的投递等级x8作为当前车辆节点的投递等级:
[0040][0041]
其中,即lk(i
′
)为优化的随机森林模型中将样本i
′
预测为投递等级为k的决策树的集合,表示所有将样本i
′
预测为投递等级为k的决策树的权重之和,x
8,当前
为权重之和最大的投递等级,s为优化的随机森林模型中决策树的个数;按照上述预测当前车辆节点的投递等级x
8,当前
的方法预测计算相遇车辆节点投递等级x
8,相遇
。
[0042]
有益效果:与现有技术相比,本发明的技术方案具有以下有益技术效果:
[0043]
(1)本方法基于随机森林模型,采用集成学习思想克服单一分类器的不足,从而在车载容迟网络数据报文转发路由决策时,能利用更多信息更加精确的选择报文的下一跳节点,进而提升算法的性能。
[0044]
(2)本方法综合考虑了随机森林的多样性和分类性能首先,从分类性能出发,通过每棵树分类错误率以其在森林中的表现分别给予局部和全局惩罚,以此来分配每棵树的权重,从而挑选出权重更高的树。接下来,在权重高的树中,利用多样性评判标准不合度量去选择低相似度的树,最后形成优化的随机森林模型,进一步提高了随机森林模型的准确性和泛化能力,进而提升了报文转发的投递率。
[0045]
(3)通过选择不同的优化参数n和s的值,本方法可适应不同的车载容迟网络环境,具有较好的灵活性。
附图说明
[0046]
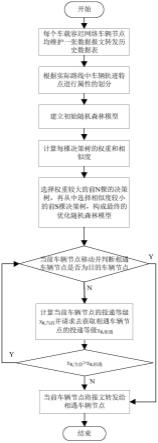
图1是本发明方法对于容迟网络中任意一个报文的转发流程图。
具体实施方式
[0047]
下面结合附图对本发明的技术方案的实施作进一步的详细描述:
[0048]
如图1所示,本发明提出一种基于优化随机森林的车载容迟网数据报文转发方法,该方法包括如下步骤:
[0049]
步骤1、获取每个车载容迟网络车辆节点的历史数据表,并对车辆属性进行划分;
[0050]
步骤2、根据每个车载容迟网络车辆节点的属性建立训练集,并根据训练集建立初始随机森林模型;
[0051]
步骤3、根据每棵决策树的权重和相似度对随机森林模型进行优化;
[0052]
步骤4、当携带数据报文的车辆节点与其他车辆节点相遇时,若相遇车辆节点为数据报文的目的车辆节点时,此时数据报文直接被投递到相遇车辆节点;如果相遇的车辆节点不是目的车辆节点时,进入步骤5;
[0053]
步骤5、利用优化后的随机森林模型预测当前车辆节点的投递等级x
8,当前
和相遇车辆节点投递等级x
8,相遇
;
[0054]
步骤6、若x
8,当前
>x
8,相遇
,则当前携带数据报文的车辆节点会继续携带报文,转到步骤4;否则,当前携带数据报文的节点将数据报文转发给相遇节点,由相遇节点继续转发报文,本次转发结束。
[0055]
步骤1的具体方法如下:
[0056]
每个车载容迟网络车辆节点均维护一张数据报文转发历史数据表,根据实际路线中车辆轨迹特点进行属性的划分,其属性包括:区域码x1、时间戳x2、平均接触时间间隔x3、运动方向x4、速度x5、平均时延x6、距离x7和投递等级x8;其中,区域码是对地理区域的编码,即将整个网络的地理区域以10m
×
10m的大小划分为不同的网格,对每个网格赋予一个唯一的区域码,用于记录数据报文转发时车辆节点所处的位置;时间戳是对时间段的编码,即将一天24小时以10分钟为间隔单位依次离散化编码,用于记录数据报文转发的时间;平均接触时间间隔是在数据报文转发前1小时内该车辆节点与其他车辆节点相遇的平均间隔时间,并以1分钟为单位依次离散化编码;运动方向是车辆节点在数据报文转发时的运动方向,划分为东、西、南、北、东南、东北、西南、西北8个运动方向;速度是车辆节点在数据报文转发时的行驶速度,以历史数据集为依据,并以20km/h为单位依次离散化编码;平均时延表示数据报文从源车辆节点转发到目的车辆节点所经过的平均时间,以2000s为单位依次离散化编码;行驶距离是车辆节点自上次转发数据报文后到本次数据报文转发时行驶的距离,以8km为单位依次离散化编码;投递等级是车辆节点转发数据报文的能力,用该车辆节点已成功转发数据报文数量来表示,并以100为单位依次离散化编码,并且根据每个车载容迟网络车辆节点获得区域码x1、时间戳x2、平均接触时间间隔x3、运动方向x4、速度x5、平均时延x6、距离x7和投递等级x8作为一个数据样本。
[0057]
步骤2的具体方法如下:
[0058]
步骤2.1:将所有车载网络车辆节点对应的样本形成数据集合m,按均匀分布随机地将历史数据集m中80%的样本划分为训练数据集f,20%样本划分为测试数据集d;
[0059]
步骤2.2:通过自助重采样技术,从训练数据集f中有放回地重复随机抽取70%的数据,生成以属性x1到x7作为内部节点,投递等级x8为预测目标的分类回归决策树,也即cart树;
[0060]
步骤2.3:重复上述步骤2.2,最后组成t棵决策树的初始随机森林,t>=1000。
[0061]
步骤3的具体方法如下:
[0062]
设测试数据集的样本数量为|d|,对于第i个样本,i∈[1,|d|],其投递等级标签为c
t
,ci∈[1,c],c为最大投递等级数;设为初始随机森林中的决策树j对样本i的预测分类,j∈[1,t];表示初始随机森林对样本i预测的分类;
[0063]
步骤3.1、设置每棵决策树的权重;
[0064]
步骤3.2、计算每棵决策树的相似度;
[0065]
步骤3.3、将所有决策树按照权重wj降序排序,选取前n个权重对应的决策树,再将这n棵决策树按相似度simj进行升序排序,选择前s棵决策树以构成最终的优化随机森林模型,所有车载网络车辆节点上都使用该模型预测车辆节点的投递等级。
[0066]
步骤3.1的具体方法如下:
[0067]
步骤3.1.1、计算决策树j的局部惩罚因子pj;
[0068][0069]
其中,为决策树j预测投递等级错误的样本数据集pj表示决策树j的预测错误率;|qj|为数据集样本的数量;
[0070]
步骤3.1.2、计算决策树j的全局惩罚因子
[0071][0072]
其中,为决策树j与初始随机森林预测的投递等级不一致的样本数据集,表示决策树j相对于初始随机森林的预测错误率;
[0073]
步骤3.1.3、计算决策树j的权重wj:
[0074][0075]
步骤3.2的具体方法如下:
[0076]
步骤3.2.1、计算决策树j的不合度量disj:
[0077][0078]
其中,表示对投递等级决策树j预测为正确而决策树1预测为错误的样本集合,表示对投递等级决策树1预测为正确而决策树j测为错误的样本集合;
[0079]
步骤3.2.2、计算决策树j的相似度simj:
[0080]
simj=1-disj。
[0081]
步骤5中,利用随机森林模型预测当前车辆节点的投递等级x
8,当前
和相遇车辆节点投递等级x
8,相遇
具体方法如下:
[0082]
如果相遇的车辆节点不是目的车辆节点时,此时当前携带数据报文的车辆节点获取属性区域码x1、时间戳x2、平均接触时间间隔x3、运动方向x4、速度x5、平均时延x6、距离x7的当前值,并生成包括属性x1,x2,
…
,x7的实例样本i
′
,并利用优化的随机森林模型预测样本i
′
的投递等级x8作为当前车辆节点的投递等级:
[0083][0084]
其中,即lk(i
′
)为优化的随机森林模型中将样本i
′
预测为投递等级为k的决策树的集合,表示所有将样本i
′
预测为投递等级为k的决策树的权重之和,x
8,当前
为权重之和最大的投递等级,s为优化的随机森林模型中决策树的个数;按照上述预测当前车辆节点的投递等级x8,
当前的
方法预测计算相遇车辆节点投递等级x
8,相遇
。
[0085]
为了验证本发明的报文转发方法能够有效性,特列举一验证例进行说明。
[0086]
表1部分历史数据集
[0087][0088][0089]
表1是部分历史数据集。首先,根据训练集建立初始的随机森林模型。接下来,根据测试集进一步优化随机森林模型,利用步骤3,我们会获得优化的随机森林模型,假设优化的随机森林模型的决策树的棵数为10。本验证例中,假设携带报文的车辆节点n
当前
与车辆节点n
相遇
相遇,设n
相遇
报文不是目的车辆节点,此时n
当前
的属性实例样本i
′
当前
的取值为《x1=r3,x2=t1,x3=a1,x4=p1,x5=v1,x6=w1,x7=d1>,则优化的随机森林模型中每棵树对实例样本i
′
当前
预测的投递等级结果如表2所示:
[0090]
表2每棵决策树对i
′
当前
投递等级的预测结果
[0091][0092]
则,根据步骤4可得:
[0093]
l1(i
′
当前
)={1,5,6},
[0094]
l2(i
′
当前
)={2,3,8,9,10},
[0095]
l3(i
′
当前
)={4,7},
[0096][0097][0098][0099]
因此,可得车辆节点n
当前
的投递等级为:
[0100][0101]
同理,携带报文的车辆节点n
当前
请求相遇车辆节点n
相遇
用同样的方法计算其投递等
级x
8,相遇
,设x
8,相遇
=1。因为n
当前
的投递等级更大,所以车辆节点n
当前
将继续携带报文,等待下一次相遇转发机会。
[0102]
综上所述,本发明提出了一种基于优化随机森林的车载容迟网数据转发方法,综合考虑了随机森林的多样性和分类性能,提高了随机森林模型的准确性和泛化能力,根据预测投递等级去进行路由决策。该方法能够显著提升报文投递率,并降低网络开销。
[0103]
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。