1.本发明涉及数字病理学领域,更特别地涉及图像分析领域。
背景技术:
2.已知有几种图像分类方法可用于将数字病理图像分类为不同的类别,诸如“健康组织”或“癌组织”等。例如,sertan kaymaka等人在“breast cancer image classification using artificial neural networks”,《procedia computer science》,第120卷,2017年,第126-131页中,描述了一种使用反向传播神经网络(bppn)对乳腺癌诊断图像进行自动分类的方法。
3.然而,申请人已观察到,就乳房x光检查图像中癌症相关的节结的早期检测而言提供良好结果的各种机器学习技术未能对其他类型的组织切片的图像,特别是全视野载玻片图像进行分类。
4.与使用现有机器学习方法进行图像分类相关联的另一个问题是,经训练的机器学习程序通常就像是黑箱。在决定给某个患者施用潜在有效但副作用强烈的药物是否可行时,不得不完全或部分依赖这个“黑箱”,而不能以语言表述潜在的“决策逻辑”,这对于医生和患者来说都是不尽如人意的。
5.maximilian ilse等人的:“attention-based deep multiple instance learning”,arxiv.org,cornell university library,201olin library cornell university ithaca,ny 14853,2018年2月13日,xp081235680,描述了基于注意力的多实例学习器(mil)在组织病理学数据集上的应用。
6.匿名出版物“deep multiple instance learning with gaussian weighting”,iclr 2020conference blind submission,2019年9月25日(2019-09-25),第1-10页,xp055698116,从url:https://openreview.netiattachment?id=bklrea4kws&name=original.pdf在2020-05-25检索自互联网,描述了一种深度多实例学习(mil)方法,其经过端到端训练以根据弱监督执行分类。mil方法被实现为双流神经网络,专门用于实例分类和加权任务,利用高斯径向基函数通过在包内局部地对实例进行比较以及跨包全局地对实例进行比较来归一化实例权重。
技术实现要素:
7.本发明目的是提供一种经改进的对组织图像进行分类的方法以及一种如独立权利要求中指出的对应图像分析系统。在从属权利要求中给出了本发明的实施例。如果本发明的实施例不是互相排斥的,则可以彼此自由地组合。
8.在一个方面,本发明涉及一种用于对组织图像进行分类的方法。该方法包括:
[0009]-通过图像分析系统接收多个数字图像;每个数字图像描绘了患者的组织样品;
[0010]-通过图像分析系统将每个所接收的图像拆分成一组图像块;
[0011]-针对块中的每个块,通过图像分析系统,计算特征向量,该特征向量包括从块中
选择性地提取的图像特征;
[0012]-提供多实例学习(mil)程序,该多实例学习程序被配置成使用模型来基于从任何输入图像的所有块中提取的特征向量将所述任何输入图像分类为至少两个不同类别中的一个类别的成员;
[0013]-针对块中的每个块,计算确定性值(根据本发明的实施例在本文中称为“c”),该确定性值指示模型关于块的特征向量对从中导出块的图像的分类的贡献的确定性;
[0014]-针对图像中的每个图像:
[0015]
●
通过mil程序使用基于确定性值的池化函数用于将从图像中提取的特征向量聚合成全局特征向量作为图像的块的确定性值的函数,并且从全局特征向量计算聚合的预测值(根据本发明的实施例在本文中称为“ah”);或
[0016]
●
通过mil程序从图像的特征向量中的每个特征向量计算预测值,并且通过mil程序使用基于确定性值的池化函数用于将图像的预测值聚合成聚合的预测值(根据本发明的实施例在本文中称为“ah”)作为图像的块的确性值的函数;以及
[0017]-通过mil程序将图像中的每个图像基于聚合的预测值分类为至少两个不同类别中的一个类别的成员。
[0018]
由于以下多种原因,这些特征可能是有益的:
[0019]
多实例学习(mil)程序是弱监督学习程序的一种形式,其被配置成从训练集学习,其中训练实例被布置在称为包的集合中,并且其中针对整个包提供标签,而包中的单独实例的标签是未知的。因此,mil程序只需要弱注释的训练数据。该类型的数据在医学成像中尤其常见,因为对单独图像区域进行注释以提供充分注释的训练数据非常耗时且因此成本高昂。此外,暗示(具有高预测值使)数字图像属于特定类别的成员(例如,描绘健康组织的图像/描绘原发性肿瘤的图像/描绘转移的图像)的组织结构有时是病理学家所未知的或者无法察觉的。因此,使用mil程序对数字组织图像进行分类可能具有以下优势:弱注释的训练数据足以训练能够准确地对数字组织图像进行分类的mil程序。此外,经训练的mil程序将能够准确地对数字组织图像进行分类,即使是在人类注释者(例如病理学家)不了解对组织的类别隶属关系具有高度预测性的组织结构并且因此无法选择具有组织区域(具有和不具有该组织结构)的无偏比的训练图像的情况下。
[0020]
此外,使用具有基于确定性值的池化函数的mil程序将模型不确定性合并到分类中。申请人已观察到,这大大提高了分类准确度,特别是在组织载玻片图像分析领域,特别是当组织载玻片图像是全视野载玻片图像时。
[0021]
当mil程序被用于解决计算病理学的问题时,要用作训练图像的全视野载玻片图像(wsi)被赋予全局标签(例如,指示活体组织检查中是否存在肿瘤细胞)。然后通过从训练wsi中对图像块进行采样来从训练wsi中提取多个实例,并将其分组到包中,其中每个包都含有从特定训练wsi中提取的块并具有该载玻片图像的全局标签。
[0022]
在许多情况下,只有一小部分实例(块)将含有针对wsi标签的证据,例如当肿瘤位于活体组织检查的一小部分中时。此外,包的大小(每个训练wsi的块的数量)可能非常大,因为全分辨率的wsi中的组织的尺寸很大(在数千个实例或以上的量级)。这些因素形成具有挑战性的mil环境。随着包变得更大,包中的负实例群体越大,包被错误分类的可能性就越大,因为有更多机会找到正类别的证据。深度学习模型的不稳定性质增加了这种可能性,
其中输入图像的微小变化可能会触发非常不同的输出。正因为如此,含有许多看起来相似的实例的大包可能会导致非常不同的特征向量和相应的预测以及针对这些预测中的每个预测的预测值。申请人已观察到,不仅考虑块的特征值(或从特征向量导出的预测值)而且考虑确定性值大大地改善这个问题,因为考虑到模型关于特定块中所描绘的组织纹理和图像特征的不确定性。
[0023]
根据实施例,基于确定性值的池化函数是基于确定性值的最大池化函数、均值池化函数或注意力池化函数。
[0024]
池化函数是mil中的的关键元素。池化函数指定mil模型的实例(即图像的块的预测)如何组合以形成包输出,即图像的分类结果。存在几个池化函数,例如最大池化函数、均值池化函数和注意力池化。然而,申请人已观察到,在低证据率包(例如,与实例总数相比,正实例的数量较少)的情况下,如果使用最大池化,则单个假正实例预测将破坏所得的包预测,并产生假正结果。另一方面,如果使用均值池化,则包中的大量负实例将掩盖正实例并产生假负包预测。
[0025]
在经学习的注意力mil的情况下,注意力学习在低证据率的情况下受到显著的负面影响。大包带来的另一个挑战是通过选择关键实例来实现模型的可解释性。更大的包呈现出更高的可能导致关键实例选择出现错误的不稳定性概率。因此,使用基于确定性值的池化函数在数字组织图像,特别是全视野载玻片图像的上下文中是特别有利的。
[0026]
使用基于确定性值的池化函数解决了当前池化函数的缺点,并解决了mil在证据率低的情况(如(全视野载玻片)组织图像经常出现的情况)下表现不佳的问题。例如,通过针对该实例计算出的确定性值对特征向量(或从其导出的预测值)进行加权,针对每个实例的模型的不确定性都被考虑在内。
[0027]
对数字组织图像进行分类可用于评估利用特定药物成功治疗患有疾病的患者的机会。例如,只有在距癌细胞一定距离处存在某些免疫细胞的情况下,在癌症患者免疫疗法过程中使用的一些药物才起作用。在这种情况下,尝试自动识别组织图像中的这些对象,即某些细胞类型或某些亚细胞和超细胞结构,以便能够做出关于疾病的存在情况和/或推荐的治疗的说明。本发明的实施例可以具有以下优点:实施例利用了mil程序,因此不需要明确知道某些组织结构和某些疾病或它们的治疗选项之间的关系。通过训练和使用经训练的mil程序,可以隐式检测与某种疾病和/或其治疗相关的未知预测特征。因此,本发明的实施例不限于在特定时间可用的医学知识。
[0028]
在另外的有益方面,使用将图像块视为实例的mil程序特别适合在全视野载玻片组织样品图像的上下文中预测与患者相关的特征。这是因为全视野载玻片组织样品通常覆盖许多不同的组织区域,只有一些组织区域可具有任何预测值。例如,微转移的直径可能只有几毫米,但载玻片和相应的全视野载玻片图像的长度可达许多厘米。尽管整个图像是用标签标记的-根据对样品来源患者的经验观察-使用特定标签,例如“对药物d有应答=真”,包括许多免疫细胞且预测正应答的微转移周围的组织区域也可能仅覆盖几毫米。因此,大多数块不包括相对于图像方式和通常的患者方式标签可预测的任何组织区域。mil程序特别适用于基于数据实例包识别预测特征,其中假定大部分实例没有任何预测值。
[0029]
mil配置为将从所述数字图像导出的所有块处理为同一块包的成员。
[0030]
根据实施例,该方法进一步包括经由gui向用户输出分类结果。此外,或替代性地,
该方法包括将分类结果输出到另一应用程序。例如,mil程序可以是图像分类应用程序的一部分或者可以与图像分类应用程序互操作,该图像分类应用程序被配置成生成向用户显示分类的结果的gui。例如,所接收的数字图像中的每一个都可以与指示类别的标签相关联地在gui上显示,该类别根据mil程序生成的分类结果包括相应的数字图像。
[0031]
根据实施例,mil程序为二进制mil程序。至少两个类别包括称为“正类别”的第一类别和称为“负类别”的第二类别。如果mil模型针对图像的块中的至少一个块预测这个块的特征向量包括针对“正类别”的证据,则这个图像分类为“正类别”。如果mil模型针对图像的所有的块预测其各自的特征向量均不包括针对“正类别”的证据,则这个图像分类为“负类别”。例如,足够数量的块是否包括针对“正类别”的足够证据的问题可以包括使用基于确定性值的池化函数来确定聚合的预测值是否超过阈值。
[0032]
在一些实施例中,针对块计算出的特征向量可以包括一个或多个“正特征值”和一个或多个“负特征值”。“负特征值”是针对“负类别”提供证据的特征的值。“正特征值”是针对“正类别”提供证据的特征的值。在这种情况下,mil程序被配置成考虑负特征值和正特征值两者来对图像进行分类。
[0033]
图像在特定类别中的预测类别隶属关系可以实现为将指示类别类别隶属关系的类别标签分配给图像。分配给特定数字图像的“类别标签”也可以称为“包标签”,因为图像表示“包”,从图像生成的块表示包的“实例”。
[0034]
例如,mil程序可以为二进制mil程序,其中为每个包分配一个二进制标签。如果这个图像的实例(块)中的至少一个包含标签的证据,则mil程序已习得并被配置成预测,特定数字图像具有“正”包标签。如果所有实例都未包含“正”类别标签的证据,则图像被预测为具有“负”包标签。
[0035]
更正式地说,每个包(图像)由一组实例{x1,...,xk}组成,其中k是包的尺寸,即从数字图像生成的块的数量。k可以在包(所接收的数字图像)之间变化。二进制类别标签y∈{0,1}与每个包(图像)相关联。每个实例(块)j也具有一个标签yj∈{0,1},但是假设实例标签(块标签)是隐藏的。“0”表示负实例或包标签,并且“1”表示正实例或包标签。mil程序被配置成通过在所有实例标签上应用池化函数来计算/预测包标签来预测包(图像)的二进制包标签(类别隶属关系)y。例如,使用最大池化函数的最先进的mil程序将根据以下公式计算二元包标签y:y={0,iffσyk=0,otherwise 1}。然而,根据本发明实施例的mil程序使用考虑模型不确定性的新池化函数。
[0036]
mil程序包含池化函数,该池化函数用于聚合实例预测(基于单独块的预测)h以产生包(图像)的预测(分类结果)。
[0037]
基于基于块的预测值的方法i
[0038]
根据实施例,mil程序使用基于确定性值的池化函数来将针对图像的块计算出的预测值聚合成聚合的预测值。该方法包括通过mil程序针对块中的每一个块计算预测值中的一个预测值(根据本发明的实施例在本文中称为“h”)。每个预测值都被计算为从块中提取的特征向量的函数。预测值是指示块的特征向量对从其导出块的图像的分类的贡献的数据值。当计算特定块的预测值时,mil程序优选地仅考虑从其导出特征向量的块的特征向量(而不考虑任何其他块的特征向量)。
[0039]
根据实施例,基于确定性值的池化函数为基于确定性值的最大池化函数。基于确
定性值的池化函数的使用包括针对图像中的每一个图像的子方法a)或b,分别包括:
[0040]-a1)利用针对块中的每一个块计算出的确定性值(例如称为“c”)对这个块的预测值(例如称为“h”)进行加权,从而获得加权的预测值(例如称为“wh”);例如,加权包括将针对块中的一个块计算出的确定性值(c)与针对该一个块计算出的预测值(h)相乘以计算该块的加权的预测值(wh);例如,对于被拆分为k个块的特定图像im,k个块中的任何一个块的加权的预测值wh
m_k
可被计算为:wh
m_k
=h
m_kxcm_k
;
[0041]-a2)识别针对图像的所有块计算出的所有加权的预测值中的最大值(例如称为“wh
最大”);例如,最大值根据以下公式进行计算:并且
[0042]-a3)使用最大加权的预测值(wh
最大
(im))作为聚合的预测值;或
[0043]-b)使用具有最大确定性值(c
最大
)的块的预测值(h)作为聚合的预测值。
[0044]
如果具有最大确定性值(c)的块的预测值(h)被用作聚合的预测值,则确定性值c仅被计算以便选择预测值h。在这种情况下,选择的预测值h被认为是通过确定性值“隐式”加权的,因为其被选择作为取决于针对图像的块计算出的确定性值的聚合的预测值。
[0045]
然后聚合的预测值被用于对输入图像进行分类。例如,如果wh
最大
超过训练期间确定的阈值,则数字图像可以分类为“描绘肿瘤的图像”。否则,该图像分类为“描绘健康组织的图像”。
[0046]
使用基于确定性值的最大池化函数可能具有以下优点:在测试或训练的情况下,当包(图像)中的大量负实例(具有“负类别”块标签的块)可能会掩盖正实例(具有“正类别”标签的块)并可能产生假负包类别预测,mil程序更稳健。
[0047]
根据实施例,提供mil程序包括在训练图像集上训练mil程序,其中在训练阶段期间基于确定性值的最大池化函数被用作池化函数。这可能具有以下优点:因为在训练mil时生成的预测模型强烈反映了块中描述的组织模式,该块具有相对于包的标签具有最高预测能力的特征向量。该模型不受与标签无关的组织区域/块的负面影响。但是,最大运算将忽略除最高得分的块之外的所有块中包含的所有信息。因此,可能会错过也可能相关的块/组织模式的预测能力。
[0048]
根据实施例,提供mil程序包括在训练图像集上训练mil程序,其中在训练阶段期间基于确定性值的均值池化函数被用作池化函数。这可能是有益的,因为在训练mil程序时生成的预测模型考虑了所有块中描绘的组织模式。然而,考虑与特定标签的出现实际上无关的组织模式和相应块可能导致经训练的mil的预测准确性的恶化和降低。
[0049]
根据实施例,基于确定性值的池化函数为基于确定性值的均值池化函数。基于确定性值的池化函数的使用包括针对图像中的每个图像:
[0050]-利用针对块中的每个块计算出的确定性值(例如称为“c”)对这个块的预测值(例如称为“h”)进行加权,从而获得加权的预测值(例如称为“wh”);例如,加权包括将针对块中的一个块计算出的确定性值(c)与针对该一个块计算出的预测值(h)相乘以计算该块的加权的预测值(wh);例如,对于被拆分为k个块的特定图像im,由图像im的模型针对k个块中的任何一个块生成的加权的预测值wh
m_k
可被计算为:wh
m_k
=h
m_kxcm_k
;
[0051]-计算针对图像的所有块计算出的所有加权的预测值wh的均值(例如称为“wh
均值”);例如,均值根据以下公式进行计算:);例如,均值根据以下公式进行计算:根据替代
实施例,均值根据以下公式进行计算:
[0052]-以及使用均值加权的预测值(wh
均值
(im))作为聚合的预测值。
[0053]
使用基于确定性值的均值池化函数可能具有以下优点:对于假正预测(即在低证据率包的上下文中,图像是“正类别”的成员),mil程序比基于最大运算子的池化函数更稳健。“低证据率包”为实例包,其中正实例(带有“正类别”标签的块)的数量与实例(块)的总数相比非常小。如果使用最大池化,则单个假正实例预测将破坏所得的包预测并产生假正分类结果。
[0054][0055]
基于全局聚合的特征向量的方法ii
[0056]
根据替代实施例,mil程序使用基于确定性值的池化函数用于从图像的块中提取的特征向量聚合成全局(“聚合的”)特征向量,该全局(“聚合的”)特征向量再次用于计算聚合的预测值.该方法包括:
[0057]-将池化函数应用于针对图像的块计算出的特征向量和确定性值以计算图像的全局特征向量,全局特征向量的计算考虑块的特征向量和确定性值;以及
[0058]-使用全局特征向量来计算聚合的预测值。
[0059]
根据实施例,基于确定性值的池化函数为基于确定性值的最大池化函数。
[0060]
根据一个实施例,基于确定性值的最大池化函数的使用包括针对图像中的每一个图像的子方法c)或d),分别包括:
[0061]-c1)利用针对块中每一个块计算的确定性值(例如称为“c”)对这个块的特征向量(例如称为“fw”)进行加权,从而获得加权的特征向量(例如称为“wfv”);例如,特征向量的特征可能仅由数值特征向量组成;加权包括将针对块中的一个块计算的确定性值(c)与针对该一个块计算的特征向量(fv)中的每个特征值相乘以获得该块的加权的特征向量(fv);
[0062]-c2)识别针对图像的所有块计算出的所有加权的特征向量中的最大值(wfv
最大
);或
[0063]-d)使用具有最大确定性值(c
最大
)的块的特征向量(fv)作为全局特征向量。
[0064]
例如,在特征向量包括未能通过简单乘法加权的顺序值的情况下,可以使用根据子方法d)的实施例。
[0065]
根据其他实施例,基于确定性值的池化函数为基于确定性值的均值池化函数。基于确定性值的池化函数的使用包括针对图像中的每一个图像:
[0066]-利用针对块中每一个块计算出的确定性值(例如称为“c”)对从这个块中提取的特征向量(例如称为“h”)进行加权,从而获得加权的特征向量(例如称为“wfv”);例如,每个特征向量可以包括多个数字特征值,并且将特征向量的每个数字特征值与确定性值相乘,以获得存储在特定块的加权的特征向量中的加权的特征向量值;
[0067]-从针对图像计算出的所有加权的特征向量(wfv)中计算均值加权的特征向量;例如,均值加权的特征向量的特征值可以被计算为存储在同一向量位置的图像的加权的特征向量中的所有加权特征值的均值;
[0068]-和使用针对图像计算出的均值加权的特征向量作为图像的全局特征向量,该全局特征向量用于计算聚合的预测值。
[0069]
进一步的实施例(方法i和ii)
[0070]
根据其他实施例,该方法包括针对图像中的每一个图:通过对确定性值应用softmax函数来归一化为针对图像计算出的确定性值。基于确定性值的池化函数被配置成将预测值聚合成聚合的预测值作为归一化确定性值的函数,或者将特征向量聚合成全局特征向量作为归一化确定性值的函数,其中全局特征值用于计算聚合的预测值。
[0071]
softmax函数(也称为softargmax或归一化指数函数)为将k个实数(例如针对图像im的k个块中的每一个块计算出的k个确定性值ck)的数组作为输入的函数,并将其归一化为由与输入数字的指数成比例的k个概率组成的概率分布。即,在应用softmax之前,一些数组分量可能是负数,或者大于一;并且它们的和可能不等于1;但是在应用softmax之后,每个分量都会在区间(0,1)内,并且分量的总和是1,使得就它们可以被解释为概率。此外,更大的输入分量将对应更大的概率。softmax将网络的非归一化输出映射到预测输出类别或范围内的概率分布。
[0072]
例如,softmax函数可用于将确定性值归一化为介于0与1之间的值范围的数值。使用softmax函数对确定性值进行归一化可能具有以下优点:增加了针对不同块和/或不同图像获得的确定性值的可比性。
[0073]
根据实施例,mil程序包括并且被配置成执行基于确定性值的池化函数而不是以下(常规)池化函数中的一个或多个:
[0074]
·
最大池化函数,该最大池化函数被配置成识别并返回根据从图像的块中提取的所有特征向量中计算出的所有预测值h中的最大值;例如,特定图像im的常规聚合的预测值可被计算为ah
常规
(im)=最大(h
k_m
);
[0075]
·
均值池化函数,该均值池化函数被配置成识别并返回根据从图像的块中提取的所有特征向量中计算出的所有预测值h的均值;例如,特定图像im的常规聚合的预测值可被计算为为
[0076]
·
注意力池化函数,该注意力池化函数被配置成识别并返回特征向量中的一个特征向量的预测值h,在从图像的块中提取的所有特征向量中,该一个特征向量已通过注意力学习技术识别为具有关于从其导出块的图像的类别隶属关系的最高预测能力;例如,特定图像im的常规聚合的预测值可被计算为的常规聚合的预测值可被计算为
[0077]
因此,根据本发明的实施例,新的基于确定性值的池化函数替代(通常或选择性地在训练阶段或测试阶段)在常规mil程序中使用的常规池化函数。根据本发明实施例的mil程序不包括或使用上述三种常规池化函数中的任何一种来(通常或选择性地在训练阶段或测试阶段)确定包标签/执行图像分类任务。
[0078]
根据实施例,mil程序为神经网络。确定性值是在神经网络模型的训练和/或测试时使用丢弃技术来计算出的。
[0079]
丢弃为从全连接层随机关闭一些神经元的技术。通常,丢弃(仅)在训练期间应用。丢弃迫使全连接层以不同的方式学习相同的概念。丢弃意味着特定层的一部分神经元被随机失活(“丢弃”)。这提高了经训练的模型的泛化能力,因为其上应用了丢弃的层被迫学习具有不同组互连神经元的相同“概念”。因此,丢弃为可用于避免神经网络在训练期间过度拟合的技术。一般来讲,模型/神经网络的学习能力越强(层数越多,神经元越多),模型/神
经网络越容易发生过度拟合。
[0080]
使用丢弃技术来计算每个块预测的模型确定性可能具有以下优点:许多神经网络架构和程序已经包括一个或多个丢弃层,因此现有程序库和软件工具可用于计算模型不确定性。此外,申请人已观察到,在数字病理学上下文中使用的神经网络通常面临过度拟合的问题,因为用于执行图像分析和分类任务的神经网络通常包括许多层,并且因为训练数据集的大小通常是有限的。
[0081]
根据实施例,在训练阶段应用丢弃意味着创建许多不同的丢弃层,分别包括全连接层的节点的随机选择的子组,其中每个丢弃层充当掩膜(包括“零”节点和“一”节点)。掩膜在正向传播期间进行创建,在训练期间分别应用于层输出,并且被缓存以供将来在反向传播中使用。应用在层上的丢弃掩膜被保存,以允许识别在反向传播步骤期间被激活的神经元。现在,在选择了那些已识别的神经元的情况下,神经元的输出被反向传播。通常,丢弃层仅在训练阶段期间被创建和使用,并以失活的附加层的形式保存在经训练的网络中。
[0082]
根据一些实施例,丢弃层仅在训练期间被使用。
[0083]
这可能具有以下优势,即经训练的mil程序在训练阶段期间已经学习到使用丢弃掩膜利用许多不同网络架构来评估针对特定块的特征向量计算出的预测值的可变性。如果训练图像与测试时使用的组织图像相似,则计算出的基于块的预测值的模型不确定性/可变性被固有地编码在经训练的ml程序中,并将准确反映模型关于测试图像中所描绘的各种组织结构的不确定性。
[0084]
本发明的一些实施例仅在全连接层上使用丢弃,但其他实施例另外在最大池化层之后使用丢弃,从而产生某种类型的图像噪声增强。
[0085]
在测试阶段期间,丢弃层通常在最先进的机器学习程序中失活。然而,根据一些实施例,在模型的训练和测试时使用丢弃技术。例如,丢弃层的创建或重新激活和应用允许以许多不同的方式学习(在训练时)或预测(在测试时)相同的概念,从而允许评估模型的不确定性和由给定输入的模型生成的各种预测。根据实施例,确定性值被计算为蒙特卡罗丢弃(mc丢弃)。
[0086]
monte-carlo丢弃(mc丢弃)背后的关键思想是通过使用丢弃来评估模型不确定性。mc丢弃使用丢弃技术来计算模型不确定性(并且因此也隐式地计算模型确定性),即通过随机使用神经网络架构的不同子网络从网络中为同一预测任务获取多个不同结果并评估“确定性”作为结果的“一致性”。mc指的是monte carlo,因为丢弃过程类似于对神经元进行采样。
[0087]
例如,根据本发明的一些实施例,在测试时,利用随机丢弃将相同的输入提供给网络多次,例如几百次,每次都使用不同的丢弃掩膜。然后计算针对每个块获得的所有多个预测的均值,并生成覆盖所有这些预测的预测区间或预测可变性/模型不确定性的另一种度量。
[0088]
在测试时应用丢弃可能具有降低整体模型准确度的缺点。然而,在组织图像分析的上下文中,已经观察到,该缺点实际上是一个益处,因为该步骤在应该并且可以减少过度拟合的地方施加了模型不确定性。例如,当输入数据与在其上训练模型的数据相距甚远时,在测试时使用许多不同的丢弃掩膜针对同一输入块获得的预测的可变性将指示模型不确定如何解释该类型的块。在组织图像分析领域,存在大量健康的以及由疾病引起的组织结
构。由于存在许多不同的染色方案、许多不同的染色剂以及执行染色方案的单独的人的特征可能对染色的组织切片产生影响并因此可能对数字组织图像产生影响这一事实,因此导致了额外的变化性。因此,训练数据集不太可能涵盖健康和患病组织结构以及不同染色方法的所有可设想的变化和组合。因此,使用mc丢弃将提供mil程序,该mil程序能够在测试时并且单独地针对每个块自动评估模型的不确定性,该模型被配置成根据该特定块的特征来预测图像的正确类别。
[0089]
根据一些实施例,mc丢弃均值-std(mc丢弃均值标准偏差)(包括经许多前向传递运行测量模型的方差)用于计算模型关于特定分类任务的确定性,并且用于计算块中的每一个块的确定性值。特征向量不包括模型的足够和/或适当信息以可靠且准确地确定包标签的块将在训练期间生成较低的预测值。yarin gal等人在“deep bayesian active learning with image data”,mar 2017,arxiv:1703.02910v1中详细描述了用于计算mc丢弃标准std的示例。
[0090]
根据实施例,mil程序的基于确定性值的池化函数被配置成针对图像的块中的每一个块计算用mc丢弃均值std加权的预测值wh,如下所示:
[0091]
针对图像im的k个块中的每一个块,确定性值(也称为“实例c
k_m
确定性”)被计算为基于mc丢弃的均值-std的倒数,其由mil程序的模型在softmax或sigmoid层之后在测试时计算出。根据c
k_m
给出针对每个实例(块)k的确定性公式,其中σ(xk)是实例k的mc丢弃均值std。ε是防止被零除的小数。
[0092]
可以使用如上c
k_m
文针对本发明实施例所述的基于最大值或基于均值的基于确定性值的池化函数来聚合图像的所有块的确定性值。如果使用基于确定性值的最大池化函数,则选择具有最高预测值h的实例(块),该预测值由mil程序的模型生成作为输出,该模型由其确定性值c加权。如果使用基于确定性值的均值池化函数,则根据本发明的实施例,通过softmax函数(其可以实现为网络的层)传递k个块中的每一个块的确定性值c以获得总和为1的平均权重。然后使用确定性值c作为权重来计算实例预测h的加权均值wh。因此,whk为实例(块)k的预测网络的输出。
[0093]
本发明的实施例提供了一种新的基于确定性值的池化函数,其使用分配给单独实例的确定性值来聚合包实例。基于确定性值的池化函数可以在训练期间应用,但也可以用于改进在测试时利用丢弃来训练的预训练mil程序。
[0094]
根据实施例,在测试时而不是在模型的训练时使用基于确定性值的池化函数(其可以使用丢弃技术来计算模型不确定性)。
[0095]
这意味着根据本发明的实施例,图像分类方法可以“现成”地应用于预训练的mil模型,以显著提高它们的性能,尽管在训练期间,可能没有使用基于确定性值的池化函数.这可能具有以下优势:即使在没有使用基于确定性值的池化函数(利用或不利用丢弃技术)的情况下训练mil程序,图像分析方法也可用于对图像进行分类,其中现有的(但最初在测试使用时失活)丢弃层应用于在测试时针对特定图像块生成各种预测,从而评估模型相对于块相关预测的确定性。
[0096]
例如,在训练数据集上训练的mil程序在训练时可能不包括任何丢弃层,并且在训练时使用的池化函数不考虑模型不确定性。例如,mil程序在训练时使用的池化函数可以是
常规最大池化或均值池化函数。在测试时针对块中任一个块计算确定性值包括在测试时向经训练的mil程序添加一个或多个丢弃层。可以在测试时使用添加的丢弃层来计算每个输入块的确定性值,其反映经训练的模型的不确定性。
[0097]
根据实施例,神经网络包括一个或多个失活丢弃层。失活丢弃层是在训练时激活并在训练完成时失活的丢弃层。在测试时针对块中的任一个块计算确定性值包括在测试时重新激活一个或多个丢弃层。
[0098]
根据实施例,在测试时针对块中的任一个块计算确定性值包括,在测试时已添加或重新激活一个或多个丢弃层之后:
[0099]-针对块中的每个块,基于从块中提取的特征向量多次计算预测值(hd);每次计算预测值(hd)时,一个或多个重新激活或添加的丢弃层丢弃网络的节点的不同子集;以及
[0100]-针对块中的每个块,作为针对块计算出的多个预测值hd的可变性的函数来计算块的确定性值c,其中可变性越大,确定性值c越小。
[0101]
这可能具有以下优势:如果网络的现有丢弃层在训练阶段完成后已失活或在训练阶段期间已在显著不同的数据集上使用,或者如果用作mil程序的神经网络在测试时不包括任何丢弃层,则在测试时现有层的重新激活或丢弃层的添加允许在测试时针对特定图像块生成各种预测,从而评估模型相对于块相关预测的确定性,即使经训练的模型的网络架构不允许直接计算该变化性。
[0102]
例如,mil程序可能已经在与测试时使用的组织图像显著不同的数字组织图像上进行了训练。例如,训练和测试时图像可能已源于患有不同类型癌症的患者,或者可能已经用相似但不同的染色剂染色,或者可能描绘了相同类型但在不同的组织中的癌细胞。在这些情况下,经训练的模型可能无法针对在测试时分析的组织图像和图像块提供高度准确的预测。然而,通过在测试时应用丢弃技术,可以自动评估由经训练的模型针对从块中提取的特征向量生成的预测值h的准确度,并将其考虑用于对在测试时作为输入提供的组织图像进行分类。
[0103]
根据实施例,所接收的数字图像包括组织样品的数字图像,该组织样品的数字图像的像素强度值与非生物标志物特异性染色剂,特别是苏木精染色剂或h&e染色剂的量相关。
[0104]
例如,每包块可代表对特定药物的应答已知的相应患者。该患者专用包中包含的实例是从该特定患者的相应组织样品导出的一个或多个图像的块,该组织样品已用非生物标志物特异性染色剂(诸如h&e)染色。该患者的所有组织图像以及由此导出的所有块已分配标签“患者对药物d有应答=真”。h&e染色的组织图像表示染色组织图像的最常见形式,并且仅这种类型的染色已揭示大量可用于预测患者相关属性值的数据,例如特定肿瘤的亚型或分期。此外,许多医院包括从过去多年治疗的患者导出的h&e染色的组织图像的大型数据库。通常,医院还拥有关于特定患者是否对特定治疗有应答和/或疾病发展的速度或严重程度的数据。因此,可以得到可用相应的结果(例如,通过特定药物治疗是/否成功、无进展存活期超过一年、无进展存活期超过两年等)用标签标记的训练图像的大量语料库。
[0105]
根据实施例,所接收的数字图像包括组织样品的数字图像,该组织样品的数字图像的像素强度值与生物标志物特异性染色剂的量相关。生物标志物特异性染色剂是适于对组织样品中包含的生物标志物选择性染色的染色剂。例如,生物标志物可为特定蛋白质,诸
如her-2、p53、cd3、cd8等。生物标志物特异性染色剂可为与选择性结合上述生物标志物的抗体偶联的明视野显微镜或荧光显微镜染色剂。
[0106]
此外,或替代性地,所接收的数字图像包括组织样品的数字图像,其像素强度值与生物标志物特异性染色剂的量相关,该生物标志物特异性染色剂适于选择性地对组织样品中包含的生物标志物进行染色。
[0107]
例如,每包块可代表对特定药物的应答已知的相应患者。该患者专用包中包含的实例是从该特定患者的相应组织样品导出的一个或多个图像的块。一个或多个组织样品已用一种或多种生物标志物特异性染色剂染色。例如,块可从一个、两个或三个组织图像导出,所有组织图像都描绘了同一患者的相邻组织载玻片已用her2-特异性染色剂染色。根据另一示例,块可从描绘已用her2-特异性染色剂染色的第一组织样品的第一组织图像导出,并且从描绘已用p53特异性染色剂染色的第二组织样品的第二组织图像导出,以及从描绘已用fap-特异性染色剂染色的第三组织样品的第三组织图像导出。第一、第二和第三组织样品从同一患者导出。例如,它们可为相邻的组织样品切片。尽管所述三个组织图像描绘了三个不同的生物标志物,但所有组织图像从同一患者导出,且因此由此衍生的所有块已分配标签“患者对药物d有应答=真”。基于像素强度值与生物标志物特异性染色剂的量相关的数字图像的图像块训练mil程序可能具有以下优势:识别组织中一种或多种特定生物标志物的存在和位置可揭示关于特定疾病和疾病亚型的高度特异性和预后信息。预后信息可包括观察到的两种或更多种生物标志物的存在的正相关和负相关。例如,已观察到某些疾病(诸如肺癌或结肠癌)的推荐治疗方案和预后在很大程度上取决于癌症的突变特征和表达谱。有时,单独的单个标志物的表达不具有预测能力,但多个生物标志物的组合表达和/或特定的另外的生物标志物的缺失可能具有相对于特定患者相关属性值的高预测能力。
[0108]
根据实施例,所接收的数字图像包括该组织样品的像素强度值与第一生物标志物特异性染色剂的量相关的组织样品的数字图像的组合和该组织样品的像素强度值与非生物标志物特异性染色剂的量相关的组织样品的数字图像的组合。生物标志物特异性染色剂是适于对组织样品中包含的生物标志物选择性染色的染色剂。mil程序被训练为将描绘相同组织样品和/或描绘来自同一患者的相邻组织样品的所有数字图像分类为同一类别。
[0109]
这种方法的优势在于,组合由h&e染色揭示的富含信息的组织特征,识别组织中一种或多种特定生物标志物的存在和位置,可提供关于特定疾病和疾病亚型的高度特异性和预后信息。预后信息可包括观察到的两种或更多种生物标志物的存在的正相关和负相关和/或通过h&e染色在视觉上揭示的组织特征。
[0110]
根据实施例,提供mil程序包括训练mil程序的模型。训练包括:
[0111]-提供组织样品的一组数字训练图像,每个数字训练图像都已经分配了指示至少两个类别中的一个类别的类别标签;
[0112]-将每个训练图像拆分成训练图像块,每个训练块已经分配了与从中导出训练块的数字训练图像的类别标签相同的类别标签;
[0113]-针对块中的每个块,通过图像分析系统,计算训练特征向量,该训练特征向量包括从所述块中选择性地提取的图像特征;和/或
[0114]-重复调整mil程序的模型,使得损失函数的误差最小化,损失函数的误差指示训练块的预测类别标签与实际分配给该训练块的类别标签之间的差异,该预测类别标签已由
模型基于训练块的特征向量计算得出。
[0115]
根据实施例,该方法进一步包括,针对所接收的数字图像中每一个:
[0116]-以针对块中的每个块计算出的确定性值c对这个块的预测值h进行加权,从而获得加权的预测值wh;
[0117]-通过mil程序识别针对其计算出最高加权的预测值wh的图像的块中的一个块;
[0118]-针对图像的其他块中的每个块,通过将其他块的加权的预测值wh与最高加权的预测值进行比较来计算相关度指标,其中该相关度指标是与所比较的加权的预测值的差异呈负相关的数值;
[0119]-作为相关度指标针的函数计算图像的相关度热图,相关度热图的像素颜色和/或像素强度指示针对所述图像中的块计算出的相关度指标;以及
[0120]-在gui上显示相关度热图。
[0121]
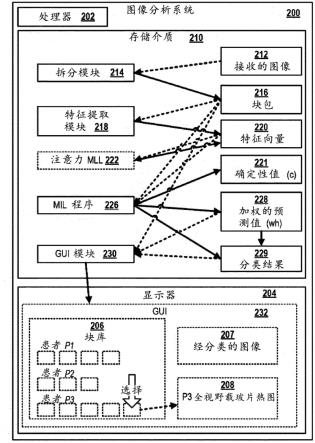
这可能是有利的,因为这可以使病理学家能够识别其中描绘的相对于图像在特定类别中的成员隶属关系具有最高预测值的块和组织结构。因此,可以产生以前在生物医学文献中尚未描述的新的生物医学知识。例如,通过输出和突出显示1000个图像块中的一个,该图像块描述了对图像类别标签“将从治疗x中受益的癌症患者的组织”具有高度预测性的特定组织结构,可以揭示描绘了这个块的组织结构与以前可能没有被发现和发布过的特定图像类别之间的相关性或因果关系。此外,即使在对特定图像类别具有预测性的组织结构是已知的情况下,热图或图形表示具有最高预测值wh的块的任何其他形式可能具有以下优势:病理学家能够更快且更准确地识别包括相对于特定生物医学问题的最有趣的组织结构的一个或多个块。
[0122]
例如,具有与图像的最高分块的加权的预测值高度相似的加权的预测值wh的图像区域和相应块可在相关度热图中用第一颜色(例如“红色”)或高强度值来指示,并且其加权的预测值与这个图像的所有块的最高wh值相异的图像区域和相应块可在相关度热图中用不同于第一颜色的第二颜色(例如“蓝色”)或低强度值来表示。
[0123]
这可能是有利的,因为gui自动计算并呈现相关度热图,该相关度热图指示具有高预测能力(或“预后值”)wh的组织区域和相应图像块的位置和覆盖范围,该高预测能力已利用模型相对于这个块的确定性值进行了加权。相关度热图可突出显示具有高相关度指标的组织区域。块通常只是全视野载玻片图像的小子区域,热图和/或根据块的wh值排序的块库可能无法提供对整个组织样品的概览。关于具有高预测相关度的组织模式的位置和覆盖范围的概览信息可由优选以高度直观和智能的方式与全视野载玻片组织图像的原始图像组合的相关度热图提供。
[0124]
计算和显示基于加权的预测值的热图可能是有利的,因为该热图指示关于用于训练mil的端点的块的预测能力。因此,向用户显示相关度热图使用户能够快速识别具有可预测全视野载玻片图像内的特定标签的组织模式的块的位置和覆盖范围。
[0125]
根据实施例,该方法进一步包括在屏幕的gui上显示所接收的图像。根据分类的结果,图像在gui中被分组到至少两个不同类别。
[0126]
根据实施例,至少两个类别中的每一个选自包括以下项的组:
[0127]-对特定药物有反应的患者;
[0128]-已发展出转移或特定形式的转移(例如,微转移)的患者;
[0129]-对特定疗法表现出特定缓解,例如病理完全缓解(pcr)的癌症患者;
[0130]-表现出特定形态学状态或微卫星状态的癌症患者组织;
[0131]-已对特定药物发展出不良反应的患者;
[0132]-具有特定遗传属性,例如特定基因特征的患者;和/或
[0133]-具有特定rna表达谱的患者。
[0134]
这些标签可能有助于诊断以及寻找治疗疾病的合适药物。然而,上述标签仅是示例。其他患者相关属性也可用作标签(即,训练mil程序的端点),如上所述。术语“患者相关”还可以包括治疗相关,因为疾病的特定治疗的有效性也与接受治疗的患者有关。
[0135]
本发明的实施例用于识别指示患者相关属性值的组织模式。这种方法可能是有利的,因为它可将基于明确生物医学专家知识的图像分析方法的优势与机器学习方法的优势结合起来。
[0136]
根据实施例,基于确定性值的池化函数是基于确定性值的最大池化函数、均值池化函数或注意力池化函数。
[0137]
根据实施例,该方法进一步包括:
[0138]-提供经训练的注意力mll,该经训练的注意力mll已经学习了哪些由块导出的特征向量对于预测块的类别隶属关系最相关;
[0139]-通过注意力mll作为相应块的特征向量的函数来计算块中的每个块的注意力权重(aw),该注意力权重是这个块的特征值关于这个块相对于类别的隶属关系的相关度的指标;
[0140]
将块的注意力权重(aw)与块的特征向量值相乘,以获得具有针对块的注意力加权的特征值的基于注意力的特征向量;以及,使用基于注意力的特征向量作为输入到mil程序的特征向量以用于计算载玻片的预测值(h)、确定性值(c)和/或加权的预测值(wh)、预测值(h)、确定性值(c)和/或加权的预测值(wh),从而经计算为基于注意力的预测值、基于注意力的确定性值和/或经计算为基于注意力的加权的预测值;或
[0141]-将块的注意力权重(aw)与块的预测值(h)、确定性值(c)或与由mil计算的块的加权的预测值(wh)相乘,以获得基于注意力的预测值、基于注意力的确定性值和/或基于注意力的加权的预测值。
[0142]
例如,可以如maximilian ilse等人在以下中描述来计算注意力权重:“attention-based deep multiple instance learning”,arxiv.org,cornell university library,201olin library cornell university ithaca,ny 14853,2018年2月13日,xp081235680,其描述了基于注意力的多实例学习器(mil)在组织病理学数据集上的应用,如参照公式(9)所描述。
[0143]
注意力权重和确定性值的组合可能特别有利,因为当图像数据有噪声和/或与训练阶段期间使用的图像显著不同时,单独计算注意力权重可能会提供较差(不准确)的分类结果。然而,基于注意力的权重的缺点和缺乏稳健性可以通过将确定性值也考虑在内来弥补:即使在针对特定的向量/块获得了高注意力权重的情况下,如果针对这个块获得的确定性值较低,则这个块/向量的贡献将在很大程度上被忽略,从而避免假正分类结果。
[0144]
应注意,“注意力权重”和“确定性值”涉及完全不同的概念:“确定性值”指示预测模型关于向量/块对分类结果的贡献的确定性,而“注意力权重”指示特征向量/块相对于分
类结果的相关度(预测能力)。例如,第一特征向量可以从图像的第一块导出,并且第二向量可以从同一图像的第二块导出。
[0145]
例如,注意力mll可以基于第一特征向量确定图像示出“肿瘤组织”,因为第一特征向量指示第一块包括与组织类型类别“肿瘤组织”高度相关/相对于组织类型类别“肿瘤组织”具有高预测值的第一模式。因此,注意力mll将针对第一块计算出高注意力权重,因为识别的模式对类别“肿瘤组织”具有很强的预测性。
[0146]
此外,注意力mll可以基于第二特征向量确定图像示出“肿瘤组织”,因为第二特征向量指示第二块包括与分类“肿瘤组织”弱正相关的另一个模式。这意味着,在包括具有该模式的块的所有图像中,约60%的图像确实是肿瘤组织图像,而约40%的这些图像可能包括具有该模式但仍可能示出“健康”组织的块。
[0147]
如果确定性未被计算/考虑,则可能会发生以下情况:尽管第一模式与“肿瘤类别标签”的相关性可能很强(带有具有第一模式的至少一个块的所有训练图像确实是肿瘤组织图像,并且没有一个“健康组织”训练图像包括具有该第一模式的块),但是针对类别“肿瘤组织”的确定性值可能较低。例如,训练集中具有第一模式的块的总数可能较小,并且因此基于该第一模式的任何预测的“确定性”可能较低。因此,注意力mll有可能针对一个块计算出相对于特定类别标签的高预测相关度,而针对这个块计算出的确定性值较低,反之亦然。对于第二块,注意力权重会较低,因为第二模式似乎不能很好地预测类别隶属关系,并且确定性值可能较高或较低,这取决于包括第二模式的训练数据集中的示例的质量和丰度。
[0148]
将注意力权重和确定性值两者都考虑在内,确保训练数据集中可能与某个类别隶属关系密切相关/对其具有高度预测性的模式被忽略或至少在针对该预测的训练数据基础(以针对该预测/分类计算出的模型的确定性值表示)较低的情况下被降低权重。
[0149]
例如,只有在由确定性值加权的基于注意力的预测值超过预定义阈值的情况下,最大池化函数才可以将图像分类为特定类别的成员。
[0150]
根据实施例,针对单独块计算出的预测值h和/或加权的预测值wh可以与库中相关联块的图形表示一起输出。例如,库中的块可根据针对每个块计算出的数值wh进行排序。在这种情况下,块在库中的位置允许病理学家或其他人类用户识别经发现对特定标签具有高度预测性的块中描绘的组织模式。此外,或替代性地,数值可显示为空间上接近其相应块,从而使用户能够检查和理解在一个或多个块中描绘的组织的组织模式,所述一个或多个块具有与特定标签相似的数值。
[0151]
库可以在训练阶段结束时基于训练图像而输出和/或可以在测试时基于测试图像而输出。作为经训练的mil程序的输出而生成的图像块库可揭示相对于患者的特定患者相关属性值具有预测性的组织特征。组合图像块呈现数值可能具有以下好处:至少在许多情况下,病理学家可通过比较具有相似数值的库中的若干块与具有高得多或低得多的数值的其他块并且通过比较报告库中块的这些子集中描绘的组织特征来识别和表述预测组织模式(也可称为“组织特征”)。
[0152]
在另外的方面,本发明涉及一种用于对组织图像进行分类的图像分析系统。该图像分析系统包括至少一个处理器和易失性或非易失性存储介质。存储介质包括分别描绘患者组织样品的数字图像。
[0153]
图像分析系统进一步包括图像拆分模块,该图像拆分模块可由至少一个处理器执行并且被配置成将图像中的每个图像拆分成一组图像块。
[0154]
图像分析系统进一步包括特征提取模块,可由至少一个处理器执行并且配置成针对块中的每个块计算特征向量,该特征向量包括从所述块选择性地提取的图像特征。
[0155]
图像分析系统进一步包括多实例学习(mil)程序。mil程序可由至少一个处理器执行并且配置成使用模型来基于从任何所述输入图像的所有块中提取的特征向量,将输入图像分类为至少两个不同类别中的一个类别的成员。mil程序进一步配置成用于:
[0156]-针对块中的每个块计算确定性值,该确定性值指示模型关于块的特征向量对从中导出块的图像的分类的贡献的确定性;
[0157]-针对图像中的每个图像:
[0158]
■
通过mil程序使用基于确定性值的池化函数用于将从图像中提取的特征向量聚合成全局特征向量作为图像的块的确定性值的函数,并且从全局特征向量计算聚合的预测值(根据本发明的实施例在本文中称为“ah”);或
[0159]
■
通过mil程序从图像的特征向量中的相应特征向量计算预测值,并且通过mil程序使用基于确定性值的池化函数用于将图像的预测值聚合成聚合的预测值(“ah”)作为图像的块的确定性值的函数;以及
[0160]-基于聚合的预测值将图像中每个图像分类为至少两个不同类别中的一个类别的成员。
[0161]
根据实施例,该系统包括用于输出分类结果的界面。例如,该界面可以是机器对机器界面,例如,用于将分类结果发送给软件应用程序的应用程序界面。此外,或替代性地,该界面可以是或可以包括人机界面,例如,配置成显示包括分类结果的图形表示的gui的屏幕。例如,mil程序可以配置成通过gui将分类结果输出给用户。
[0162]
根据实施例,gui使用户能够选择是基于块的预测值h还是基于块的加权的预测值wh计算热图(也称为“相关度热图”)。这可以允许用户评估考虑模型不确定性的影响。
[0163]
特征提取方法
[0164]
根据实施例,在训练时和/或在测试时针对块中的每个块计算特征向量包括:从块中提取一个或多个图像特征,并在特征向量中以一个或多个特征的形式表示提取的特征。任选地,计算特征向量还包括:接收组织样品被描绘在块中的患者的患者相关数据,并在特征向量中以一个或多个特征的形式表示患者相关数据。患者相关数据可以是,例如基因组数据、rna序列数据、患者的已知疾病、年龄、性别、体液中的代谢物浓度、健康参数和当前用药。
[0165]
根据实施例,特征向量的计算由经训练的机器学习逻辑执行,特别是由包括至少一个瓶颈层的经训练的全卷积神经网络执行。
[0166]
根据实施例,用于特征提取(“特征提取mll”)的经训练的机器学习逻辑通过采用包括瓶颈的全卷积网络类型的mll(如unet)在监督方法中接受训练。“unet”架构由olaf ronneberger、philipp fischer和thomas brox在“u-net:用于生物医学图像分割的卷积网络”中描述,德国弗莱堡大学计算机科学系及bioss生物信号研究中心(arxiv:1505.04597v1,2015年5月18日)。该文件可通过康奈尔大学图书馆https://arxiv.org/abs/1505.04597下载。
[0167]
例如,可训练特征提取mll来执行组织图像分割任务,由此待识别的片段包括两个或更多个以下组织图像片段类型:肿瘤组织、健康组织、坏死组织、包括特定对象的组织,诸如如肿瘤细胞、血管、基质、淋巴细胞等以及背景区域。根据一些实施例,使用分类网络(诸如resnet、imagenet或segnet)以监督的方式训练特征提取mll,通过训练它对具有特定预定类别或对象的图像块进行分类。
[0168]
在特征提取mll经训练后,mll被拆分成“编码器”部分(包括输入层、一个或多个中间层和瓶颈层)和“解码器”,即输出生成部分。根据本发明的实施例,使用“编码器”部分达到经训练的mll的瓶颈层来提取和计算每个输入块的特征向量。瓶颈层是神经网络的一层,该瓶颈层包含明显少于输入层的神经元。例如,瓶颈层可以是包含小于输入层的60%或甚至小于20%的“神经元”的层。根据不同的网络架构,不同层中神经元的数量和比例可能会有很大差异。瓶颈层是一个隐藏层。
[0169]
根据一个示例,特征提取mll的网络具有基于unet的网络架构。它有一个具有512*512*3(512x512 rgb)个神经元的输入层和具有9*9*128个神经元的瓶颈层。因此,瓶颈层的神经元数量约为输入层的神经元数量的1.5%。
[0170]
根据一个示例,特征提取mll的网络具有resnet架构,该架构实现了监督式或无监督式学习算法。输入层包含512x512x3个神经元,瓶颈层和瓶颈层输出的对应特征向量通常包含1024或2048个元素(神经元/数字)。
[0171]
根据实施例,特征提取由在imagenet自然图像数据集上训练的resnet-50(he et al.,2016)架构的特征提取程序模块执行。pierre courtiol,ericw中描述了一些基于此架构从图像中提取特征的详细示例。tramel、marc sanselme和gilles wainrib:,,仅使用全球标签的组织病理学分类和疾病定位:弱监督方法”,arxiv:1802.02212,于2018年2月1日提交,可通过康奈尔大学图书馆https://arxiv.org/pdf/1802.02212.pdf在线获取。
[0172]
根据实施例,将特定块的经训练的特征提取mll的其中一层生成的输出用作mil程序从块提取的特征向量。这一层可以是,特别地,瓶颈层。根据实施例,特征提取mll以无监督或自监督的方式训练,如mathilde caron和piotr bojanowski以及armand joulin和matthijs douze中所述:“视觉特征无监督式学习的深度聚集”,corr,1807.05520,2018可通过https://arxiv.org/abs/1807.05520以电子方式获取。
[0173]
替代性地,可以根据spyros gidaris、praveer singh、nikos komodakis训练特征提取mll:“通过预测图像旋转进行无监督表示学习”,2018年2月15日,iclr 2018会议电子版可通过https://openreview.net/forum?id=s1v4n2l0-获取。
[0174]
另外替代性地,根据elad hoffer,nir ailon可训练特征提取mll。“通过度量嵌入进行半监督深度学习”,2016年11月4日,iclr 2017可通过https://openreview.net/forum?id=r1r5z19le以电子方式获取。
[0175]
用于训练特征提取mll的数据集可以是另一个组织图像数据集和/或稍后用于训练mil程序的一组组织图像。在训练阶段,特征提取mll不会评估或以其他方式使用与训练图像相关联的任何标签,因为特征提取mll经训练用于识别组织类型和相应的图像片段,而不是识别患者的患者相关属性值(用作mil程序学习阶段的终点)。
[0176]
利用基于接近性相似性标签的特征提取方法
[0177]
根据实施例,特征向量由特征提取机器学习逻辑(“特征提取mll”)计算,该逻辑已
经在包括用标签标记的块对的训练数据集上训练,由此每个标签表示由块对描绘的两个组织模式的相似性,且作为块对中两个块的空间距离的函数进行计算。
[0178]
根据优选实施例,标签被完全自动地分配给训练数据集中的块对。
[0179]
由于多种原因,这种方法可能是有益的:两个图像区域的空间接近度是组织样品的每个数字图像中始终且固有可用的特征。问题在于图像和相应组织区域本身的空间接近度通常不会揭示相对于生物医学问题的任何相关信息,诸如组织类型分类、疾病分类、特定疾病持久性的预测或图像分割任务。申请人惊奇地观察到,两个图像区域(“块”)的空间接近度传达的信息是两个图像区域的相似性的准确指标,至少是否在mll的训练阶段期间分析了大量块及其相应距离。因此,通过利用两个块的“空间接近度”的固有可用信息来为两个进行比较的块自动分配组织模式相似性标签,可自动提供可用于训练mll的大型注释数据集。经训练的mll可用于自动确定作为输入所接收的两个图像或图像块是否描绘了相似或相异的组织模式。然而,该数据集还可以用于其他且更复杂的任务,例如图像相似性搜索、图像分割、组织类型检测和组织模式聚集。因此,申请人惊奇地观察到,块的空间接近度传达的信息可用于自动创建带注释的训练数据,允许训练可靠地确定图像相似性的mll,此外还可以训练输出特征向量的mll,所述特征向量可由额外的数据处理单元用于数字病理学中的多个复杂图像分析任务。这些方法都不需要领域专家手动注释训练数据。
[0180]
当包含许多不同组织模式(例如“非肿瘤”和“肿瘤”)的训练图像被拆分成许多不同的块时,两个块之间的距离越小,两个相比较块描绘相同组织图的概率就越高,例如“非肿瘤”。然而,在描绘不同组织模式的两个不同模式的边界旁边会有一些块对(例如,第一块“肿瘤”,另一块“非肿瘤”)。这些块对产生噪声,因为它们描绘了不同的组织模式,尽管它们在空间上彼此非常接近。申请人惊奇地观察到,由跨越不同组织模式之间的边界的块对组合简化假设(空间接近度指示所描绘的组织模式的相似性)产生的这种噪声不会显著降低经训练的mll的准确性。事实上,申请人观察到根据本发明的实施例训练的mll的准确性能够胜过现有的基准方法。
[0181]
在进一步的有益方面,现在可以快速且完全自动地针对许多不同的图像集创建训练数据。目前,缺乏可用的注释数据集来捕捉组织病理学图像中的自然和实际可变性。例如,即使现有的大型数据集(如camelyon)也只包含一种染色(苏木精和曙红)和一种癌症(乳腺癌)。在来自不同癌症类型、不同组织染色类型和不同组织类型的图像中,组织病理学图像纹理和对象形状可能会有很大差异。此外,组织病理学图像包含许多具有不同领域特定含义的不同纹理和对象类型(例如基质、肿瘤浸润淋巴细胞、血管、脂肪、健康组织、坏死等)。因此,本发明的实施例可以允许针对多种不同癌症类型、癌症亚型、染色方法和患者组(例如治疗/未治疗、男性/女性、比阈值年龄年长/年幼、正生物标志物/负生物标志物等)中的每一个自动创建注释数据集。因此,本发明的实施例可允许自动创建注释训练数据并基于训练数据训练相应的mll,使得经训练的mll适于以高度特定的方式准确解决多个不同患者组中的每一个的生物医学问题。与在手动注释的乳腺癌数据集上训练的mll针对结肠癌患者提供次优结果的现有技术方法相反,本发明的实施例可允许分别针对不同患者组中的每一个创建mll。
[0182]
根据实施例,指示两个组织模式的相似性程度的标签是二进制数据值,即可以具有两个可能选项中的一个的值。例如,标签可以是“1”或“相似”,并且指示两个块描绘相似
的组织模式。替代性地,标签可以是“0”或“相异”,并且指示两个块描绘不同的组织模式。根据其他实施例,标签可为更细粒度,例如,可以是选自三个或更多数据值的有限集合的数据值,例如“相异”、“相似”和“高度相似”。根据另一些实施例,标签可为更细粒度并且可为数值,其中数值的量与相似性程度呈正相关。例如,可以将数值计算为将成对的两个块之间的空间距离线性和逆变换为表示组织模式相似性的数值的函数。空间距离越大,指示组织模式相似性的数值越小。存在多种mll架构,可以处理和使用训练数据集中不同类型的标签(例如序数或数值)。选择mll的类型,使其能够处理训练数据集的自动创建的标签。
[0183]
根据实施例,在自动注释的训练数据集上训练并且将用于特征提取的mll适于根据监督式学习算法进行学习。监督学习是关于找到将一组输入特征转换为一个或多个输出数据值的成员的映射。输出数据值在训练期间作为标签提供,例如作为二元期权标签“相似”或“相异”或作为相似性定量度量的数值。换句话说,在训练过程中,将要预测的数据值以训练数据标签的形式显式地提供给mll的模型。监督式学习带来的问题是需要用标签标记训练数据,以便为每个样品定义输出空间。
[0184]
根据实施例,至少一些或所有块对分别描绘包含在同一组织切片中的两个组织区域。组织切片中的每一个在所接收的数字图像中的相应一个中描绘。块之间的距离是在2d坐标系内计算的,该坐标系由所接收的从中导出该对中的块数字图像的x和y维度定义。
[0185]
根据实施例,通过在多个不同图像的每一个内随机选择块对来生成块对。基于随机选择确保每对中的块之间的空间距离会有所不同。对相似性标签,例如以与两个块之间的距离成反比的数值形式进行计算并分配给每对。
[0186]
根据其他实施例,通过选择每个所接收的图像的至少一些或所有块作为起始块来生成块对;针对每个起始块,选择所有或预定义数量的“附近块”,其中“附近块”是以起始块为中心的第一圆内的块,由此该圆的半径与第一空间接近度阈值相同;针对每个起始块,选择全部或预定义数量的“远处块”,其中“远处块”是在以起始块为中心的第二圆之外的块,其中所述圆的半径与第二空间度接近阈值相同;可以通过在相应图像区域内随机选择该数量的块来执行预定义数量的选择。第一接近阈值和第二接近阈值可以相同,但优选地,第二接近阈值大于第一接近阈值。例如,第一接近阈值可以是1mm并且第二接近阈值可以是10mm。然后,选择第一块对集,由此每个块对包括起始块和位于第一圆内的附近块。第一集中的每个块对都被分配了“相似”组织模式的标签。此外,选择第二块对集,由此所述集中的每一对包括起始块和“远处块”之一。第二集中的每个块对都被分配了“相异”组织模式的标签。例如,该实施例可用于创建“相似”或“相异”的“二进制”标签。
[0187]
根据实施例,在从中导出块的数字图像的x轴和y轴定义的2d坐标系内测量块之间的距离。这些实施例可用于以下情况:其中多个组织样品图像可用,所述多个组织样品图像描绘不同患者和/或同一患者内的不同区域的组织样品,由此所述不同区域彼此远离或由此精确位置所述两个区域相对于彼此是未知的。在这种情况下,块之间的空间接近度仅在由数字图像定义的2d像素平面内测量。基于图像采集设备(例如显微镜的相机或载玻片扫描仪)的已知分辨率因子,原始图像的块之间的距离可用于计算由两个块描绘的组织样品中的组织区域之间的距离。
[0188]
根据实施例,至少一些或所有块对描绘一堆相邻组织切片的两个不同组织切片中包含的两个组织区域。组织切片中的每一个在所接收的数字图像中的相应一个中描绘。所
接收的图像(该图像描绘一堆相邻组织切片的组织切片)在3d坐标系中彼此对齐。块之间的距离是在3d坐标系内计算的。
[0189]
例如,一些或所有所接收的数字图像可描绘相邻组织切片的组织块内的切片的组织样品。在这种情况下,数字图像可在公共3d坐标系中彼此对齐,使得数字图像在3d坐标系中的位置再现组织块内分别描绘的组织切片的位置。这可以允许确定3d坐标系中的块距离。“附近”和“远处”块的选择可以如上文所描述的针对2d坐标系情况执行,唯一的区别在于至少一些块对中的块是从所接收的图像中的不同图像导出的。
[0190]
根据一些实施例,带注释的训练数据包括从相同数字图像导出的块对以及从已在公共3d坐标系中彼此对齐的不同图像导出的块对。这可能是有益的,因为在只有少量相应组织样品的图像可用的情况下,考虑第三维(代表不同组织样品中组织区域的块的空间接近度)可能会极大地增加训练数据中的块数量,由此组织样品属于同一个细胞块,例如3d活体组织检查细胞块。
[0191]
根据实施例,每个块描绘具有小于0.5mm,优选地小于0.3mm的最大边缘长度的组织或背景区域。
[0192]
小块尺寸可具有以下优点:描述不同组织模式的混合物的块的数量和面积分数减少。这可以帮助减少由描绘两个或更多个不同组织模式的块和由描绘两个不同组织模式的“组织模式边界”旁边的块对产生的噪声。此外,小块尺寸可以允许生成和用标签标记大量块对,从而增加用标签标记的训练数据的量。
[0193]
根据实施例,块对的自动生成包括:使用第一空间接近度阈值生成第一块对集;由第一集中的每个块对的两个块描绘的两个组织区域由小于第一空间接近阈值的距离彼此分开;使用第二空间接近度阈值生成第二块对集;由第二集中的每个块对的两个块描绘的两个组织区域由大于第二空间阈值的距离彼此分开。例如,这可以通过选择多个起始块、基于每个起始块周围的第一空间接近度阈值和第二空间接近度阈值计算第一圆和第二圆并选择包括起始块和“附近块”(第一集)或“远处块”(第二集),如上文针对本发明的实施例所述。
[0194]
根据实施例,第一空间接近度阈值和第二空间接近度阈值是相同的,例如1mm。
[0195]
根据优选实施例,第二空间接近度阈值比第一空间接近度阈值至少大2mm。这可能是有利的,因为在组织模式从一种模式逐渐变为另一种模式的情况下,“远处块”中描绘的组织模式与“附近”块中描绘的组织模式之间的差异可更清楚并且学习效果可得到提高。
[0196]
根据实施例,第一空间接近度阈值是小于2mm、优选小于1.5mm、特别是1.0mm的距离。
[0197]
此外或替代性地,第二空间接近度阈值是大于4mm、优选大于8mm、特别是10.0mm的距离。
[0198]
这些距离阈值指的是数字图像中描绘的组织区域(或切片背景区域)与相应块的距离。基于图像采集设备的已知放大倍数和数字图像的分辨率,该距离可在数字图像的2d或3d坐标系内转换。
[0199]
例如,可以测量块(以及其中描绘的组织区域)之间的距离,例如2d或3d坐标系中两个块的中心之间。根据替代性实施变型,在2d或3d坐标系中彼此最靠近的两个块边缘(图像区域边缘)之间测量距离。
[0200]
已经观察到上述阈值可提供用标签标记的训练数据,该数据允许自动生成经训练的mll,该经训练的mll能够准确识别乳腺癌患者的相似和相异的组织模式。在一些其他实施示例中,第一空间接近度阈值和第二空间接近度阈值可以具有其他值。特别是在使用显示不同组织类型或癌症类型的不同所接收的数字图像集的情况下,第一空间接近度阈值和第二空间接近度阈值可具有不同于以上所提供的距离阈值的其他值。
[0201]
根据实施例,该方法进一步包括创建用于训练特征提取mll的训练数据集。该方法包括接收多个数字训练图像,每个图像描绘组织样品;将所接收的训练图像中的每一个拆分成多个块(“特征提取训练块”);自动生成块对,每个块对已分配标签,该标签指示在该对的两个块中描绘的两个组织模式的相似性程度,其中相似性程度作为该对中的两个块的空间接近度的函数进行计算,其中距离与相异性正相关;训练机器学习逻辑
–
mll
–
使用用标签标记的块对作为训练数据来生成经训练的mll,经训练的mll已学习从数字组织图像中提取特征向量,所述数字组织图像以相似的图像具有相似的特征向量并且相异的图像具有相异的特征向量的方式表示图像;并且使用所述经训练的mll或其分量作为用于计算块的特征向量的特征提取mll。
[0202]
这种方法可能是有益的,因为可以根据每个数字病理图像中包含的固有的信息自动创建训练数据集的标签,可以创建带注释的数据集,用于训练特征提取mll,该特征提取mll特别适于当前解决的生物医学问题,只需选择相应的训练图像。所有进一步的步骤,如拆分、标记和机器学习步骤,都可以全自动或半自动执行。
[0203]
根据实施例,经训练的mll是孪生神经网络,包括通过它们的输出层连接的两个神经元子网络。经训练的孪生神经网络的子网络中的一个单独存储在存储介质上,并用作经训练的mll的分量,该mll用于计算特征向量。
[0204]
根据实施例,mil程序在训练阶段学习以将特征向量转换为可以表示特定包标签(即,图像类别隶属关系)的概率的预测值h。该标签可以表示类别(例如,对特定药物d治疗有应答的患者或指示应答程度的数字范围)。这种学习可以在数学上描述为非线性变换函数的学习,该函数将特征值转换为训练期间所提供的标签之一。根据一些实施例,在测试时,一些小的结构改变被应用于经训练的mil程序(例如禁用丢弃层等)并且不发生测试数据的采样。在测试时应用经训练的mil程序的主要变化是,mil程序分析测试数据包中的所有实例(块)以计算最终数值,该数值指示块中的每个块以及在训练阶段所提供的多个标签的预测能力。最后,通过聚合针对多个标签的图像的块计算出的(加权)预测值,针对整个图像或特定患者计算最终数值。将经训练的mil程序应用于患者的一张或多张图像的最终结果是具有最高概率的标签之一(例如“患者将对药物d的治疗有应答!”)。此外,可以在报告图像块库中呈现相对于该标签具有最高预测能力的块之一,该库在结构上等同于上文针对训练阶段描述的报告图像块库。
[0205]
根据实施例,该方法还包括自动选择或使用户能够选择一个或多个“高预测力块”。“高预测能力块”是其预测值或加权的预测值指示其特征向量相对于特定标签的预测能力超过高预测能力阈值的块。
[0206]
此外或替代性地,该方法还包括自动选择或使用户能够选择一个或多个“伪影块”。伪影块是一种块,其数值指示其特征向量相对于特定标签的预测能力低于最小预测能力阈值或描绘一个或多个伪影。
[0207]
响应于对一个或多个高预测能力块和/或伪影块的选择,自动重新训练所述mil程序,从而从训练集中排除高预测能力块和伪影块。
[0208]
这些特征可能具有重新训练的mil程序可能更准确的优点,因为在重新训练期间将不再考虑排除的伪影块。因此,通过基于不包括伪影块的训练数据集的简化版本重新训练mil程序,可以避免和消除由训练数据集中描述伪影的块引起的学习转换中的任何偏差。
[0209]
使用户能够从训练数据集中移除高预测性的块可能违反直觉,但仍然提供了重要的益处:有时,某些组织模式相对于某些标签的预测能力是不言而喻的。
[0210]
例如,包含许多表达肺癌特异性生物标志物的肿瘤细胞的组织切片当然是疾病肺癌存在的重要预后标志物。然而,病理学家可能对一些不太明显的组织模式更感兴趣,例如非肿瘤细胞的存在和/或位置,例如fap 细胞。
[0211]
根据实施例,mil程序基于这个块的特征向量针对特定块计算的预测值h指示关于包的(图像的)标签的块的预测能力。
[0212]
根据一些实施例,通过将针对块计算的模型的确定性值c与这个块的预测值h相乘来计算块的加权的预测值wh。
[0213]
根据其他实施例,该方法包括针对块中的每个块计算加权的特征向量形式的特征向量。加权的特征向量被计算为作为模型的确定性值c针对所述块计算出的权重的和通过特征提取程序针对所述块计算出的特征向量的函数。特别地,可以将确定性值c与这个块的特征向量相乘。
[0214]
根据一个实施例,实施mil的训练,使得针对包的块计算的模型的确定性值cs与块的特征向量作为mil程序的输入一起提供。实施mil的训练,使得mil从特征向量具有较高确定性值(即,权重)的块中学到的比从特征向量具有较低权重的块中学到较多。换句话说,在训练期间,mil程序学习将块及其特征向量对块的预测值的影响与针对被用作权重的特定块计算的确定性值相关联。
[0215]
如本文所用的“组织样品”是可通过本发明的方法分析的细胞的2d或3d组件。细胞组件可以是体外细胞块的切片。例如,样品可以在从患者收集的组织中制备,例如来自癌症患者的肝脏、肺、肾脏或结肠组织样品。样品可以是显微镜载玻片上的全组织或tma切片。制备载玻片固定组织样品的方法是本领域众所周知的并且适用于本发明。
[0216]
可以使用任何试剂或生物标志物标记对组织样品进行染色,诸如直接与特定生物标志物或各种类型的细胞或细胞区室反应的染料或染色剂、组织化学物质或免疫组织化学物质。并非所有染色剂/试剂都兼容。因此,应充分考虑所用染色剂的类型及其应用顺序,但本领域技术人员可以容易地确定。此类组织化学物质可以是透射显微镜可检测的发色团或荧光显微镜可检测的荧光团。通常,可以将含有细胞的样品与包含至少一种组织化学物质的溶液一起孵育,所述组织化学物质将与靶标的化学基团直接反应或结合。一些组织化学物质通常与媒染剂或金属共同孵育以进行染色。可以将含有样品的细胞与至少一种对目标组分染色的组织化学物质和用作复染剂并结合目标组分外的区域的另一种组织化学物质的混合物一起孵育。替代性地,可以在染色中使用多种探针的混合物,并提供一种鉴定特定探针位置的方法。对含有细胞的样品进行染色的程序是本领域公知的。
[0217]
如本文所用的“图像分析系统”是一种系统,例如计算机系统,适于评估和处理数字图像,特别是组织样品的图像,以便帮助用户评估或解释(例如分类)图像和/或为了提取
隐式地或显式地包含在图像中的生物医学信息。例如,计算机系统可以是标准的台式计算机系统或分布式计算机系统,例如云系统。通常,计算机化组织病理学图像分析系统将由相机捕获的单通道或多通道图像作为其输入,并且试图提供附加的定量信息以帮助诊断或治疗。可以直接地从相机接收图像,也可以从本地或远程存储介质读取图像。
[0218]
本发明的实施例可用于对组织图像进行分类,例如为了执行基于肿瘤分期的图像和/或确定较大患者组中的哪个患者的亚组可能会从特定药物中受益。个性化医学(pm)是一个新的医学领域,其目的是根据个人的基因组、表观基因组和蛋白质组学特征提供有效的、量身定制的治疗策略。pm不仅尝试治疗患者,还防止患者受到因无效治疗的副作用。肿瘤发展时经常发生的一些突变会引起对某些治疗的抵抗。因此,可以至少部分地通过生物标志物特异性染色的组织样品的组织图像揭示的患者的突变谱将允许经训练的mil程序明确决定特定治疗是否对个体患者有效。目前,有必要通过试错法来确定处方药对患者是否有效。试错过程可能会产生许多副作用,诸如不希望的和复杂的药物相互作用、处方药物的频繁更换、有效药物被识别之前的长时间延迟、疾病进展等。根据本发明的实施例执行的图像分类可用于将个体分层为亚群,该亚群对对其特定疾病的治疗剂的应答各不相同。例如,一些alk激酶抑制剂是用于治疗约5%的alk基因表达升高的nsclc肺癌患者的有用药物。然而,一段时间后,由于alk基因或alk信号级联下游其他基因的突变,激酶抑制剂变得无效。.因此,肺癌患者的智能分子表征允许通过患者分层优化使用某些突变特异性药物。因此,从中获取训练图像或测试图像的“患者组”可以是诸如“100名乳腺癌患者”、100名her 乳腺癌患者、“200名结肠癌患者”等的组。
[0219]
如本文所用的“数字图像”是二维图像的数字表示,通常是二进制的。通常,组织图像是光栅类型的图像,意味着该图像是分别已经分配了至少一个强度值的像素的光栅(“矩阵”)。一些多通道图像可能具有每个颜色通道具有一个强度值的像素。数字图像包含固定数量的像素行和列。像素是图像中最小的单独元素,保存着代表给定颜色在任何特定点的亮度的过时值。通常,像素作为光栅图像或光栅地图(小整数的二维数组)存储在计算机内存中。这些值通常以压缩形式传输或存储。可以获取数字图像,例如通过数码相机、扫描仪、坐标测量机、显微镜、载玻片扫描装置等。
[0220]
如本文所用的“标签”是数据值,例如字符串或数值,表示并指出患者相关属性值和/或具有此属性值的一类患者。标签的示例可以是“患者对药物d的应答=真”、“患者对药物d的应答=假”、“无进展存活时间>6个月”、“患者具有微转移”等。
[0221]
如本文所用的“图像块”或“块”是数字图像的子区域。通常,从数字图像创建的块可以具有任何形状,例如圆形、椭圆形、多边形、矩形、正方形等,并且可以重叠或不重叠。根据优选实施例,从图像生成的块是矩形的,优选地重叠块。使用重叠块可具有的优势在于,否则将被块生成过程破碎的组织模式也在包中表示。例如,两个重叠块的重叠可以覆盖20-30%,例如单个块面积的25%。
[0222]“池化函数”是置换不变性变换,其基于所有块针对块包生成单个聚合数值。池化函数可以允许指定在训练和/或测试阶段如何考虑在包的所有块中编码的信息,以计算图像分类结果。mil程序在训练阶段使用池化函数,且经训练的mil程序在测试阶段使用相同或不同的池化函数。根据优选实施例,mil程序在训练时和在测试时使用的池化函数是基于确定性值的池化函数。例如,在训练时使用的池化函数是基于确定性值的均值池化函数,且
在测试时使用的池化函数是基于确定性值的最大池化函数。
[0223]“基于确定性值的池化函数”是一种池化函数,它显式地或隐式地考虑通过mil程序针对图像的块中的每个块计算的确定性值。
[0224]
如本文所用的“特征向量”是包含描述对象的特征的信息的数据结构。数据结构可以是单维或多维数据结构,其中特定类型的数据值存储在该数据结构内的相应位置。例如,数据结构可以是向量、数组、矩阵等。特征向量可以被认为是代表某个对象的数值特征的n维向量。在图像分析中,特征可以有多种形式。图像的简单特征表示是每个像素的原始强度值。然而,更复杂的特征表示也是可能的。例如,从图像或图像块中提取的特征也可以是sift描述符特征(规模不变特征变换)。这些特征捕捉了不同线条方向的普遍性。其他特征可以指示图像或图像块的对比度、梯度方向、颜色组成和其他方面。
[0225]“嵌入”是将高维向量转换成低维空间。理想情况下,嵌入在嵌入空间中通过将语义相似的输入放在一起来捕获输入的一些语义。在本技术的上下文中,嵌入被认为是特征向量的一种,因为嵌入是由最初提取的特征向量通过数学变换的方式导出的,并且因此在嵌入中的结果参数值也可以被认为是从特定块提取的“特征值”。
[0226]
如本文所用的“机器学习逻辑(mll)”是程序逻辑,例如软件,如神经元网络或支持向量机等,已经训练或可以在训练过程中进行训练,并且其包括预测模型-作为训练阶段的结果-已经学习根据所提供的训练数据执行一些预测和/或数据处理任务(例如图像分类)。因此,mll可以是至少部分未由程序员明确指出的程序代码,但在从样品输入构建一个或多个隐含或明确模型的数据驱动学习过程中隐含学习和修改。机器学习可以采用监督式或无监督式学习。
[0227]
如本文所用的表达“多实例学习”(mil)是指一种(弱)监督机器学习方法。学习器不是接收单独用标签标记的实例集,而是接收用标签标记的包的集合,每个集合包含许多实例。在多实例二元分类的简单情况下,如果包中的所有实例都是负,则该包可用标签标记为负。在另一方面,如果包中至少一个实例为正,则该包用标签标记为正。从一组用标签标记的包中,学习器尝试(i)引入将正确用标签标记单独示例的概念,或(ii)学习如何在不引入概念的情况下用标签标记包。在babenko,boris."multiple instance learning:algorithms and applications"(2008)中给出了mil的方便和简单的示例。然而,根据一些实施例的mil程序还涵盖基于两个以上不同标签(终点)的训练。
[0228]
根据本发明的实施例,mil程序用于计算包中的每个实例(块)(数字组织图像的多个块或优选地所有块)的预测值并且因此也适用于在块中分别描绘的组织模式。在这一步中,mil程序可识别新的生物医学知识,因为在训练数据中,图像和相应块的标签作为训练的终点,但不是从块中导出的特征向量的个体特征,块与标签强烈(正或负)相关,因此可预测该标签。
[0229]
换句话说,mil指的是(弱监督)机器学习的一种形式,其中属于公共实体的训练实例以实例集的形式提供,该集合称为包。在训练时,为整个包提供指示包在特定类中的隶属关系的标签(“类别标签”),而个体实例的标签是未知的。例如,数字训练图像在类别中的隶属关系是已知的,其可被拆分成图像块。训练图像已经分配了类别标签,并且从训练图像生成的块都可以被隐式地分配有训练图像的类别标签,但没有分配标签来指示该特定块是否包括任何特征,其存在意味着图像属于类别标签中指示的类别,其中块是从图像中导出来
的。因此,该训练数据表示弱注释数据。学习的目的是训练模型,该模型已经学习识别实例的特征,这些特征高度预测特定类别中对应包的隶属关系,并且因此,它已经学习针对每个块计算预测值h,以便根据为包的实例中的每一个生成的类别标签预测函数,正确地将类别标签分配给图像(即,分配给实例的包)。为了从/或针对包的所有实例生成的多类别标签预测中生成包的类别标签,置换不变池化函数应用于为包实例中的每一个生成的预测。
[0230]“mil程序”是根据上述mil方法配置成训练或已经训练的软件程序。
[0231]
如本文所用的“确定性值”是数据值,特别是数值,其指示机器学习程序的模型关于块的特征向量对从中导出块的图像的分类的贡献的确定性。例如,如果模型基于在块中观察到的模式预测图像属于特定图像类别,则确定性值表示该预测正确的概率。例如,基于从这个图像的多个块中的一个提取的特征向量(包括对被称为“嵌入”的特征向量进行归一化)来计算确定性值。为了提供更具体的示例性说明,预测模型可能已经学习通过在多维数据空间中用超平面划得分据点来对分别代表块的数据点进行分类。远离超平面的数据点可能代表具有“高确定性值”的分类结果,而非常靠近超平面的数据点/块可能代表具有低确定性值的分类结果(数据点的属性/特征值中的微小变化可能导致数据点位于超平面的另一侧,并且从而进入另一类别中)。根据本发明的实施例,确定性值由参数“c”表示。
[0232]
如本文所用的“预测值”是数据值,特别是数值数据值,指示块的特征向量对从中导出块的图像的分类的贡献。特别是,预测值表示块的特征向量在特定类别内对从中导出块的图像的隶属关系的贡献。例如,“贡献”可以描述为图像在特定类别中的隶属关系的证据程度。当针对特定块计算预测值时,mil程序优选地仅考虑导出特征向量的块的特征向量以及任选地的一些非基于图像的特征(但不考虑任何其他块的特征向量)。根据本发明的实施例,预测值由参数“h”表示。已经针对特定块计算并且已经加权的预测值,例如针对这个块获得的确定性值由参数“wh”表示。根据本发明的实施例,预测值也可以被描述为数值,该数值指示块的特征向量为图像的隶属关系提供的证据程度,其中这个块的特征向量是在至少两个类别中的特定的一个,从该图像的隶属关系中导出的。
[0233]
如本文所用的“基于确定性值的池化函数”是配置成用于将已经从图像的所有块的特征向量导出的特征向量或预测值聚合成聚合的预测值,从而考虑针对块中的每个块计算的确定性值的函数。
[0234]
如本文所用的“聚合的预测值”是通过对多个输入值应用聚合函数以及任选地一个或多个进一步的数据处理步骤而获得的数据值(例如数值)。例如,输入值可以是特征向量(fv)的预测值(h)或从其导出来的值。例如,聚合函数可以是池化函数,其配置成将多个特征向量聚合成全局特征向量(也称为“聚合的特征向量”)或将多个预测值聚合成聚合的预测值,由此池化函数考虑确定性值。例如,一个或多个进一步的数据处理步骤可以是通过经训练的机器学习模型(mil程序的训练模型)从全局特征向量计算聚合的预测值。例如,聚合的预测值可以是指示特定图像属于特定类别的可能性的数值。
[0235]
如本文所用的“热图”是数据的图形表示,其中矩阵中包含的单独值以颜色和/或强度值表示。根据一些实施例,热图是不透明的并且包括组织载玻片图像的至少一些结构,热图是基于这些结构创建的。根据其他实施例,热图是半透明的并且显示为用于创建热图的组织图像顶部的覆盖层。根据一些实施例,热图通过相应的颜色或像素强度指示多个相似性得分或相似性得分范围中的每一个。
[0236]
如本文所用的“生物标志物特异性染色剂”是对特定生物标志物(例如,特定蛋白质如her或特定dna序列)选择性染色,但一般不对其他生物标志物或组织成分进行染色的染色剂。
[0237]
如本文所用的“非生物标志物特异性染色剂”是具有更一般的结合行为的染色剂。非生物标志物特异性染色剂不会选择性地染色单独蛋白质或dna序列,而是染色具有特定物理或化学特性的更大组的物质和亚细胞以及超细胞结构。例如,苏木精和曙红分别是非生物标志物特异性染色剂。苏木精是一种呈碱性/阳性的深蓝色或紫色染色剂。苏木精与嗜碱性物质(诸如dna和rna,呈酸性且带负电荷)结合。细胞核中的dna/rna和粗面内质网核糖体中的rna都是酸性的,因为核酸的磷酸骨架带负电荷。这些骨架与含有正电荷的碱性染料形成盐。因此,像苏木精这样的染料与dna和rna结合并将它们染成紫色。曙红是一种呈酸性且呈阴性的红色或粉红色染色剂。曙红与嗜酸物质结合,诸如带正电荷的氨基酸侧链(例如赖氨酸、精氨酸)。某些细胞的细胞质中的大多数蛋白质是碱性的,因为精氨酸和赖氨酸氨基酸残基使它们带正电荷。这些与含有负电荷的酸性染料(如曙红)形成盐。因此,曙红与这些氨基酸/蛋白质结合并将它们染成粉红色。这包括肌肉细胞中的细胞质细丝、细胞内膜和细胞外纤维。
[0238]
如本文所用的术语“强度信息”或“像素强度”是在数字图像的像素上捕获或由数字图像的像素表示的电磁辐射(“光”)量的量度。如本文所用,术语“强度信息”可包括额外的、相关的信息,例如特定颜色通道的强度。机器学习程序(例如,mil程序)可以使用该信息用于以计算方式提取衍生信息,诸如包含在数字图像中的梯度或纹理,并且可以在训练期间和/或在由经训练的机器学习程序进行特征提取期间从数字图像中隐式或显式地提取衍生信息。例如,表达“数字图像的像素强度值与一种或多种特定染色剂的强度相关”可以暗示强度信息(包括颜色信息)允许机器学习程序并且还可以允许用户标识组织样品中已经被所述一种或多种染色剂中的一种特定染色剂染色的区域。例如,描绘用苏木精染色的样品区域的像素在蓝色通道中可能具有高像素强度,描绘用快速红染色的样品区域的像素在红色通道中可以具有高像素强度。
[0239]
如本文所用的术语“生物标志物”是可以在生物样品中作为组织类型、正常或致病过程或对治疗干预的反应的指标进行测量的分子。在一个特定实施例中,生物标志物选自:蛋白质、肽、核酸、脂质和碳水化合物。更特别地,生物标志物可以是特定的蛋白质,例如egrf、her2、p53、cd3、cd8、ki67等。某些标志物是特定细胞的特征,而其他标志物已识别为与特定疾病或病症相关。
[0240]
基于组织样品图像的图像分析来确定特定肿瘤的阶段,可能需要用多种生物标志物特异性染色剂对样品进行染色。组织样品的生物标志物特异性染色通常涉及使用选择性结合目标生物标志物的一抗。特别是这些一抗,以及染色方案的其他组分,可能很贵,因此在许多应用场景中,特别是高通量筛选,由于成本原因,可能会排除可用的图像分析技术的使用。通常,组织样品用背景染色(“反染色”)染色,例如苏木精染色剂或苏木精和曙红染色剂的组合(“h&e”染色),以揭示大规模组织形态以及细胞和细胞核的边界。除了背景染色之外,可以根据要回答的生物医学问题应用多种生物标志物特异性染色剂,例如肿瘤的分类和分期,检测组织中某些细胞类型的数量和相对分布等。
[0241]
如本文所用的“全卷积神经网络”是由卷积层组成的神经网络,没有任何通常在网
络末端发现的全连接层或多层感知器(mlp)。全卷积网络在每层学习过滤器。甚至网络末端的决策层也学习过滤器。全卷积网络试图学习表示并根据局部空间输入做出决策。
[0242]
根据实施例,全卷积网络是仅具有以下形式的层的卷积网络,其激活函数在满足以下特性的特定层中的位置(i,j)生成输出数据向量y
ij
:
[0243]yij
=f
ks
({x
si
δ
i,sj
δj}0≤δi,δj≤k)
[0244]
其中x
ij
为特定层中位置(i;j)的数据向量,y
ij
为以下层所述位置的数据向量,其中y
ij
为网络激活函数产生的输出,其中k称为内核尺寸,s是步幅或子采样因子,f
ks
确定层类型:卷积或平均池化的矩阵乘法,最大池化的空间最大值,或激活函数的元素非线性等其他类型层。这种函数形式在组合下保持不变,内核尺寸和步幅遵循转换规则:
[0245][0246]
虽然一般深度网络计算一般非线性函数,但只有这种形式的层的网络计算非线性过滤器,也称为深度滤波器或全卷积网络。fcn自然地对任意尺寸的输入进行操作,并产生对应(可能重新采样)空间维度的输出。有关若干全卷积网络的特征的更详细描述,请参阅jonathan long、evan shelhamer和trevor darrell:“用于语义分割的全卷积网络”,cvpr 2015。
[0247]
本文使用的“注意力机器学习逻辑程序”是经训练的以将权重分配给特定参数的mll,由此权重指示重要性以及其他程序可能在分析这些参数上花费的注意力。这些权重也称为“注意力权重”,并且指示嵌入或块(但不是基于这个块的特征执行分类预测的确定性)的预测能力。注意力mll背后的想法是模拟人脑选择性地关注与当前上下文特别相关的可用数据子集的能力。使用注意力mll,例如在文本挖掘领域,有选择地针对特定单词分配权重和计算资源,这些单词对于从句子中获取含义特别重要。并非所有词都同等重要。其中一些比其他更能表征一个句子。通过基于训练数据集训练注意力mll生成的注意力模型可以指出句子向量可以对“重要”词有更多的注意力。根据一个实施例,经训练的注意力mll适于计算检查的每个特征向量中的每个特征值的权重,以及计算每个特征向量中所有特征值的加权和。这个加权和体现了块的整个特征向量。
[0248]
根据实施例,mll是注意力mll。注意力mll是包括神经注意力机制的mll,该神经注意力机制适用于使神经网络能够具有专注于其输入(或特征)的子集的能力:它针对每个输入计算一个注意力值ag,并基于注意力值选择特定的输入。根据实施例,设x∈rd为输入向量,z∈rk为特征向量,a∈[0,1]k为注意力向量,g∈rk为注意力一瞥(attention glimpse),以及fφ(x)为具有参数φ的注意力网络。注意力值计算为ag=fφ(x),=a
⊙
z,其中
⊙
是逐元素相乘,而z是另一个具有参数θ的神经网络fθ(x)的输出。根据实施例,注意力值被用作软注意力,即以零到一之间的(软)掩膜注意力值将特征相乘,或者硬注意力,当这些值被约束为恰好为零或一时,也就是a∈{0,1}k。在后一种情况下,使用硬注意力掩膜直接为特征向量编索引:g~=z[a](以matlab符号),这会改变其维数,现在g~∈rm,m≤k。
附图说明
[0249]
在以下实施例中,仅通过示例,参考附图更详细地解释本发明,其中:
[0250]
图1描绘了根据本发明的实施例的方法的流程图;
[0251]
图2描绘了根据本发明实施例的图像分析系统的框图;
[0252]
图3描绘了示出比较测试结果的第一表;
[0253]
图4描绘了示出比较测试结果的第二表;
[0254]
图5描绘了在网络层架构上应用丢弃的效果;
[0255]
图6描绘了根据本发明实施例的特征提取mll程序的网络架构;
[0256]
图7描绘了具有有图像块库的gui;
[0257]
图8描绘了具有相似性搜索有图像块库的gui;
[0258]
图9说明了2d和3d坐标系中块的空间距离;
[0259]
图10描绘了根据本发明的实施例的孪生神经网络的架构;
[0260]
图11描述了作为截短的孪生神经网络实现的特征提取mll;
[0261]
图12描述了在图像数据库中基于相似性搜索使用特征向量的计算机系统;
[0262]
图13显示了基于它们的空间接近度用标签标记的“相似”和“相异”块对;
[0263]
图14显示了基于相似性搜索结果的特征向量,该特征向量由在接近度的相似性标签上训练的特征提取mll提取;
[0264]
图15显示了用于图像分类的方法i,该方法基于将池化函数应用于预测值;并且
[0265]
图16显示了用于图像分类的方法ii,该方法基于将池化函数应用于特征向量以获得全局特征向量。
具体实施方式
[0266]
图1示出了根据本发明的实施例的方法流程图。该方法可用于对患者的组织图像进行分类。例如,可以执行该分类以预测患者的属性值,诸如,例如,生物标志物状态、诊断、治疗结果、特定癌症(诸如结直肠癌或乳腺癌)的微卫星状态(mss)、淋巴结微转移以及诊断活检中的病理完全缓解(pcr)。该预测基于使用考虑模型的不确定性的经训练的mil程序对组织学载玻片的数字图像进行的分类。在图1的以下描述中,还将参考图2、15和16的元素。
[0267]
方法100可用于识别迄今为止未知的预测性组织学特征和/或用于高度准确地对组织样品进行分类。
[0268]
在第一步骤102中,图像分析系统200(例如,参考图2所描述的)接收多个数字组织图像212。例如,每个组织图像可以描绘取自患者(例如癌症患者)的全视野载玻片组织样品。对于一组患者中的每个患者,接收至少一个数字组织图像。例如,数字组织图像可以从本地或远程易失性或非易失性存储介质210(例如关系数据库)中读取,或者可以直接从图像采集设备(诸如显微镜或载玻片扫描仪)接收。例如,所接收的图像可以分别描绘,例如,以ffpet组织块切片的形式提供的组织样本。在测试时,每个所接收的图像的“端点”或“类别标签”是未知的,这意味着不知道从其获得组织样品的患者是否有特定疾病或疾病分期,或者该患者是否会对特定的治疗有应答。
[0269]
接下来在步骤104中,图像分析系统将每个所接收的图像拆分成一组重叠或非重叠的图像块216。例如,可以通过拆分模块214来执行拆分。
[0270]
根据一个实施例,所接收的图像以及生成的块是多通道图像。
[0271]
接下来在步骤106中,图像分析系统为块中的每一个计算特征向量220。特征向量包括从所述块中描绘的组织模式选择性地提取的图像特征。任选地,特征向量还可以包括
遗传特征或其他患者或患者相关数据,这些数据可用于从中导出图像和相应块的患者。根据一些实施例,特征提取由经训练的特征提取模块218执行。特征提取模块可以是经训练的mil程序的子模块,或者可以是单独的应用程序或程序模块。特别地,特征提取模块218可以是经训练的mll。特征提取mll可以针对每个块生成特征向量,同时保留特征-向量-块和特征-向量-图像的关系。其他实施例可以使用按惯例实现的特征提取模块,手工编码软件程序包括特征提取算法以提供多种特征,这些特征描述了计算特征向量的块中描绘的组织区域。由于特征向量的特征已经完全地或至少部分地从相应块中包含的图像信息中提取并且不包含从图像的其他块中的任何一个块中提取的特征,所以特征向量表示这个块中描绘的组织区域的光学特性。因此,特征向量可以视为块中描绘的组织的电子组织特征。
[0272]
接下来在步骤108中,提供多实例学习(mil)程序226。例如,mil程序可以是经训练的mil程序,其安装和/或实例化在图像分析系统200上(例如电脑)。然后,经训练的、实例化mil程序在测试时处理所接收的数字组织图像的块,以便对所接收的组织图像进行分类。
[0273]
图1示出使用经训练的mil程序在测试时对组织图像进行分类。为了生成在步骤108中提供的经训练的mil程序,需要从具有预定和预知的端点(例如存活、反应、基因特征等)的患者身上提取组织块,并且获取这些组织样品的数字训练图像。端点被用作每个训练图像的类别标签来用于训练mil程序。例如,组织块被切片,并且切片设置在显微镜载玻片上。然后,切片用一种或多种组织学相关的染色剂染色,例如h&e和/或各种生物标志物特异性染色剂。训练图像取自染色的组织切片,例如使用载玻片扫描显微镜。训练图像可以是多年前获取的组织样品图像。旧图像数据集的优势在于许多相关事件的结果,例如治疗成功、疾病进展、副作用等同时是已知的并且可用于创建训练数据集,该训练数据集包括将已知事件已经分配为标签的组织图像。在一些实施例中,训练图像数据集可以包括每位患者的一个或多个训练图像。例如,可以根据不同的染色方案对相同的组织样品进行多次染色,由此对于每个染色方案获取训练图像。替代性地,若干相邻的组织样品切片可分别用相同或不同的染色方案染色,并且针对组织样品载玻片中的每一个获取训练图像。所接收的训练图像中的每一个已分配至少两个不同的预定义标签中的一个。每个标签指示在用标签标记的训练图像中描绘其组织的患者的患者相关属性值。属性值可以是任何类型,例如布尔值、数字、字符串、序数参数值等。标签可以手动地或自动地分配给所接收的训练图像。例如,用户可配置载玻片扫描仪的软件,使得所获取的图像在其获取过程中用特定标签自动标记。这在依次获取具有相同患者相关属性值/端点的大量患者的组织样品图像的场景中可能是有帮助的,例如已知显示对特定药物d有应答的第一组100名乳腺癌患者的100个组织图像以及已知未显示出这种应答的第二组120名乳腺癌患者的120个组织图像。用户可能必须在获取第一组训练图像之前仅一次设置要分配给捕获图像的标签,然后在获取第二组训练图像之前第二次设置标签。然后,将每个训练图像拆分成多个在本文中称为“训练块”的块。通过创建具有不同尺寸、放大级别和/或包括一些模拟伪影和噪声的现有训练块的修改副本,可以增加训练块的数量以丰富训练数据集。在一些情况下,可以通过如本文针对本发明的实施例所描述的对包中的实例重复采样并将所选实例放置在额外的包中来创建多个包。这种“取样”也可能具有丰富训练数据集的积极作用。mil程序将同一图像的每一组块视为需要确定其包标签的块包。该标签确定对应于对图像进行分类的任务,因为图像类别对应于要确定的标签。
[0274]
在测试时从每个所接收的数字组织图像中提取的向量作为对经训练的mil程序226的输入来提供。特征向量能够以原始获得的特征向量的形式提供,或者以也称为“嵌入”的归一化形式提供。
[0275]
接下来在步骤110中,mil程序针对块中的每个块计算确定性值221。例如,特定块k的模型确定性值ck可以通过以下方式计算:a)使用由丢弃技术生成的n个不同丢弃层计算多个不同的预测值h
k1
、h
k2
…hkn
,b)确定预测值h
k1
、h
k2
…hkn
的可变性,以及c)作为该可变性的函数来计算确定性值ck,其中可变性与确定性值呈负相关。基于不同丢弃网络架构计算的预测值h
k1
、h
k2
…hkn
的巨大可变性意味着经训练的mil程序的模型不能“确定”从块导出来的特征对图像分类结果的贡献。
[0276]
为了计算任意预测值h,mil程序分析块的特征向量220以便针对块中的每个块计算被称为预测值“h”的数值228。预测值“h”指示与块相关联的特征向量相对于待潜在地分配给图像的特定类别标签的预测能力。换句话说,该数值表示特定特征向量对在特定类别中从中导出块的图像的隶属关系的预测能力,即“预后值/能力”(基于这个块中描绘的组织模式)。例如,经训练的mil程序可以已经学习了预测从块中提取的特征值对从中导出块的图像的类别隶属关系的贡献。例如,该“贡献”可以是在考虑到当前分析的块的特征向量的情况下,与图像属于特定类别的可能性相关和/或指示图像属于特定类别的可能性的数值。
[0277]
可以遵循两种图像分类方法:
[0278]
根据一种方法,在步骤113中,对于要分类的图像的块中的每个块,由mil程序计算预测值h,998作为从这个块提取的特征向量的函数。该步骤113可能已经作为步骤110的一部分执行。然而,如果应该在不使用预测值h的情况下计算确定性值,则需要执行步骤113。接下来在步骤114中,将基于确定性值的池化函数996应用于预测值998,从而计算聚合的预测值997,该聚合的预测值不仅整合针对图像的块计算的预测值,还整合确定性值221。例如,在图15中对这种通过步骤113和114的方法进行说明。
[0279]
根据替代性方法,在步骤111中,将从图像的相应块提取的特征向量输入到基于确定性值的池化函数996中,该池化函数从特征向量220计算全局特征向量995,从而考虑针对相应块计算的确定性值221。全局特征向量不仅整合针对图像的块计算的特征向量,而且整合确定性值221。然后,全局特征向量被输入到mil程序的预测模型999中,用于在步骤112中计算聚合的预测值887。例如,在图15中对这种通过步骤111和112的方法进行说明。
[0280]
最后在步骤116中,根据聚合的预测值,对在测试时所接收的数字组织图像212中的每一个进行分类。例如,如果池化函数是最大池化函数,则如果从该图像的所有块中获得的最大加权的预测值wh超过预定义阈值,则这个图像将被分类为特定“正”类别的成员。如果不是,则该图像被分类为不是该特定类别的成员。在二元类别设置中,这个结果意味着该图像是两个可能的类别中的另一个隶属关系。
[0281]
在某些情况下,额外的经训练的注意力mll 222了哪些特征向量与提供的预测类别隶属关系最相关。块的相关度表示为通过注意力mll计算的“注意力权重”aw。在某些情况下,通过注意力mll针对每个块计算出的注意力权重乘以每个块的特征向量值。作为乘法的结果,为每个块获得了具有加权特征值的特征向量,并且该特征向量被用作mil程序的输入以计算预测值h、确定性值c和加权的预测值wh。在其他实施例中,通过注意力mll计算出的注意力权重aw乘以通过mil针对每个块的特征向量计算出的预测值h或加权的预测值wh。这
会创建一个加权数值pp,用作特定块及其相对于类别隶属关系的特征值的预测能力的指标。
[0282]
根据实施例,经训练的mil程序和图像分类结果可用于对患者组进行分层。这意味着将患者按给定治疗之外的因素进行划分。可以根据在训练mil程序时不用作标签的患者相关属性执行分层。例如,这种患者相关属性可以是年龄、性别、其他人口统计因素或特定的遗传或生理性状。gui使用户能够基于未用作标签的所述患者相关属性中的任何一个选择其组织图像用于训练mil程序的患者的亚群,并选择性地在该亚群上计算经训练的mll的预测精度。例如,亚群可以由女性患者或60岁以上的患者组成。针对相应亚群选择性获得的准确性,例如女性/男性或60岁以上/60岁以下的患者可能会在某些亚群中揭示经训练的mil的特定高或低准确性。这可能允许混淆变量(研究人员正在研究的变量以外的变量),从而使研究人员更容易检测和解释变量之间的关系,并识别将从特定药物中受益最大的患者群体。
[0283]
图2描绘了根据本发明实施例的图像分析系统200的框图。
[0284]
图像分析系统200包括一个或多个处理器202和易失性或非易失性存储介质210。例如,存储介质可以是硬盘驱动器,例如电磁或闪存驱动器。它可以是磁性的、基于半导体的或光学的数据存储。存储介质可以是易失性介质,例如主存储器,仅临时包含数据。
[0285]
存储介质包括来自具有未知端点的患者的组织样品的多个数字图像212。
[0286]
图像分析系统包括拆分模块214,该模块配置为将图像212中的每一个拆分成多个块。块分组到包216中,由此通常同一包中的所有块从自同一患者导出。包的标签表示图像在两个或多个不同类别中的一个类别中的隶属关系,并且需要由经训练的mil程序226确定和预测。
[0287]
特征提取模块218被配置为从块216中的每一个中提取多个图像特征。在一些实施例中,特征提取模块218可以是经训练的mll或经训练的mll的编码部分。提取的特征作为特征向量220与从它们中导出来的块一起存储在存储介质210中。任选地,特征向量可以用从其他来源导出的患者特征来丰富,例如基因组数据,例如微阵列数据。
[0288]
图像分析系统包括多实例学习程序(mil程序226)。在训练期间,mll程序226接收特征向量220(或通过考虑模型不确定性并且任选地另外考虑由注意力mll 222输出的注意力得分而生成的加权的特征向量)以及分配给相应训练块的标签。作为训练的结果,提供了经训练的mil程序226。经训练的mil程序已学习了针对块中的每个块计算加权的预测值wh,该加权的预测值wh指示块的预测能力和其中描绘的图像的类别标签的组织模式,其中块是从图像中导出来的,由此权重表示模型确定性(并且因此,隐含地,也表示模型不确定性)相对于基于特定块的特征向量计算的类别隶属关系预测。图像的块的这些加权的预测值也可以称为“数值块相关度得分”。
[0289]
图像分析系统进一步包括模块230,该模块配置为生成显示在图像分析系统的屏幕204上的gui 232。
[0290]
gui配置成显示由mil程序为一个或多个所接收的图像212中的每一个生成的分类结果207。例如,gui可以显示具有通过mil程序输出的类别标签的图像或图像块。
[0291]
任选地,gui包括块库206,该报告块库包括至少一些块和针对这些块计算出的数值228。数值228可以显式地显示为,例如相应块上方的覆盖层,和/或根据块的相应的数值
228隐式地,例如以块的排序顺序的形式进行排序。当用户选择块中的一个时,显示最初从中导出块的图像的全视野载玻片热图。在其他实施例中,除了默认的块库206之外,还显示热图。
[0292]
程序模块214、215、218、222、226、230中的每一个可以实现为大型mil应用程序或mil训练框架软件应用的子模块。替代性地,一个或多个模块可以分别实现为与图像分析系统的其他程序和模块互操作的独立软件应用程序。每个模块和程序可以是例如用java、python、c#或任何其他合适的编程语言编写的软件。
[0293]
任选地,图像分析系统可以包括采样模块(未示出),该模块适于选择用于训练的图像样品(子集)并在剩余的图像块上测试经训练的mil。采样模块可以在执行采样之前首先基于它们的特征向量对块执行聚集。
[0294]
任选地,图像分析系统可以包括注意力mll程序222,该程序配置成除了基于模型确定性的权重外,还计算特征向量中的每一个和相应块的权重。通过注意力mll程序计算的权重可以在训练阶段与特征向量一起用作mil程序226的输入和/或用于通过mil程序针对块中的每个块对预测值h或在测试时计算的加权的预测值wh进行加权。
[0295]
图3和图4分别描绘了示出使用基于mil的图像分类器的比较测试结果的表格,该图像分类器的池化函数考虑到了相对于针对每个图像块计算的模型输出的模型不确定性。本发明的实施例使用基于确定性的池化函数,例如最大池化函数或均值池化函数,以便对组织图像进行分类。对多个数据集执行了测试,包括图3中描绘的大型的具有挑战性的真实数据集(camelyon16)。这两个测试表明,本发明的实施例,并且特别是基于确定性的池化函数的使用提高了大多数任务的预测精度。在camelyon16数据集上,本发明实施例还显著提高了实例级预测精度auc。
[0296]
结果进一步表明,在大多数情况下,通过同时考虑在训练时和/或在测试时的确定性值,可以显著提高不同方法的测试时预测。能够改进现有模型的测试时预测是理想的特性。在大型数据集上训练mil方法需要昂贵的基础设施。现有模型的测试时改进避免了重新训练它们的需要。使用基于确定性值的最大池化函数提高了mil程序在测试时的精度。
[0297]
图3描绘了第一表300,其示出根据用作camelyon-16淋巴结转移检测竞赛的基础的数据集获得的比较测试结果。本实验的目的是将使用基于确定性值的池化函数的mil程序和基于具有挑战性的真实数据集的其它mil程序进行比较。该数据集可在https://camelyon16.grand-challenge.org/data/下获得。camelyon16数据集由400个取自前哨淋巴结的苏木精和曙红(h&e)染色的全视野载玻片图像(wsi)组成,该前哨淋巴结要么是健康的,要么表现出某种形式的转移。除了wsi本身以及它们的标签(健康、包含转移)之外,还针对每个wsi提供了像素级分割掩膜。分割掩膜被丢弃,并仅使用全局载玻片级别标签为mil程序创建基准。通过对lab颜色空间通道的平均值和标准差(std)进行归一化,使它们与来自camelyon16训练集的参考图像中的相同,简单的染色剂归一化步骤被应用在于训练图像上。更高级的归一化可以进一步改进结果。从训练图像中生成了较大的一组256x256非重叠训练块,训练块的分辨率为20x(临床病理学家用于评述载玻片的工作放大倍数)。通过自动识别和丢弃背景(白色)块来减少该组训练块。例如在pierre courtiol等人,“仅使用全局标签进行组织病理学中的分类和疾病定位:弱监督方法”,2018年2月1日,arxiv:1802.02212中描述了白色块的自动背景检测。训练块被分组到训练块包中,其中每个包对
应于训练数据集中的载玻片/载玻片图像。应用称为染色剂归一化的步骤来对不同载玻片和相应训练图像中的组织染色进行归一化。
[0298]
提供了以resnet50的形式基于imagenet预训练的mil程序(kaiming he,xiangyu zhang,shaoqing ren,and jian sun.deep residual learning for image recognition.in proc.ieee conf.on computer vision and pattern recognition,pp.770
–
778,june 2016),并且针对从网络的第二层到最后一层的每个块提取了大小为2048的特征向量(嵌入)。
[0299]
用作mil程序的预测网络由5个全连接层组成,其中,隐藏层含有1024个神经元,丢弃率为30%,并且使用relu激活函数。在应用注意力网络的情况下,使用了4个全连接层(隐藏层中含有1024、512和256个神经元),由此利用relu、批量归一化和30%丢弃率来训练网络。在所有情况下,使用adam优化器时所用的参数是其默认参数。在训练期间从每个包中选择了128个随机实例。据观察,这种采样策略大大改善了结果并防止了快速过拟合。对于每种方法,都选择了基于留出验证集(训练集的20%)表现最佳的模型,并基于camelyon-16测试集测试了所选模型。在测试过程中,没有执行实例采样,而是分析了整个包。此外,使用来自camelyon16数据集的专家病理学家肿瘤注释,通过测量实例级分类器预测精度来量化分类器对肿瘤与非肿瘤块正确进行分类的能力。此外,在测试时对所有测试方法应用了不同的池化函数,以评估和比较使用基于确定性值的池化函数方法的mil程序与使用其他池化策略的mil程序,在推理期间应用于预训练模型时的性能。以“曲线下面积-auc”测量的结果的精度显示在图3中描绘的表1中。基于确定性值的池化函数被称为“不确定性(平均或最大)池化”,并提供具有所有mil程序中精度最高的实例级预测。
[0300]
图4描绘了第二表400,其示出在结肠癌数据集上获得的比较测试结果(sirinukunwattana,等人:“用于检测和分类常规结肠癌组织学图像中的细胞核的局部敏感深度学习”,ieee transactions on medical imaging,35(5):1196
–
1206,2016)。该数据集包括100张h&e图像。该数据集被用作mil程序的训练数据集,其中每个包对应训练图像,并包含从训练图像中提取的27x27块。包含恶性区域的包标记为1,否则标记为0。使用了与(maximilian ilse,jakub m.tomczak,max welling:“基于注意力的深度多实例学习”,2018年6月28日(v4),icml 2018论文,arxiv:1802.04712)中相同的网络和学习配置,不同之处在于该学习不限于100代。训练数据集被拆分成30%/70%用于训练和测试。将20%的训练集作为验证集留存,并基于最高验证得分选择模型。结果在表400中示出。包括基于确定性值的均值池化函数的mil在实例和包级别均实现了最高精度。
[0301]
在进一步的测试(未显示)中,基于综合生成的训练和测试集评估了包括用于关键实例检索的基于确定性值的池化函数的mil程序的可用性。在此测试中,创建了100个包,其中每个包都具有1,000个由224x224图像块组成的实例。所有包中的100个实例设置为纯红色图像。在一半的包中的100个实例设置为蓝色,并将它们的标签设置为1。每个包中的其余块设置为来自camelyon-16数据集的随机图像。使用在imagenet上预训练的resnet50将图像转换为2048个嵌入。在yarin gal等人,“deep bayesian active learning with image data”,mar 2017,arxiv:1703.02910v1中提出的注意力网络用于为每个块分配注意力值。基于这些得分从包中检索关键实例,因为这些会影响每个块对输出的贡献。首先,提出的注意力网络在80%的包上训练了500代,并在剩余的20%上测试了100%的auc。使用注意力得
分和确定性得分由高到低对实例进行排名。据观察,对于注意力网络,所有包都有的红色实例出乎意料地获得了最高注意力。红色图像不是关键实例,因为它们不会触发任何标签。蓝色图像出乎意料地获得了最低注意力。因此,在此示例中,观察到使用注意力得分来提供次优结果。相反,基于确定性值的得分将蓝色图像排在顶部,并将红色图像排在底部。这个综合问题代表现实生活问题。在组织学数据集中,尽管进行了预处理,但主要包含背景或污垢的非信息性图像可能构成数据集的很大部分,并出现在所有类别的包中。在像这样的数据集上训练注意力网络并通过它们的注意力得分来检索图像,可能会导致检索到非信息性图像。申请人在现实生活数字病理组织图像中确实观察到了这种不希望的效果。另一方面,由于红色图像出现在所有包中,并在训练期间从两个标签接收梯度,我们预计模型不确定它们的标签,并且它们确实具有最高不确定性。类似地,蓝色图像仅与单个标签相关联,导致网络对它们非常确定。
[0302]
图5述了在网络层架构上应用丢弃的效果。网络架构502描绘了神经网络的三个全连接层的神经元及它们的连接。网络504显示在一个或多个层上应用丢弃层(掩膜)之后的相同网络,从而如网络架构504中所描绘的,使每个层的节点的随机选择的子集失活,其中具有阴影的节点是失活的节点。
[0303]
在训练期间应用丢弃层是通过保持较小的网络权重(正则化方法)来寻求减少过拟合(减少泛化误差)的技术。更具体地说,正则化是指添加额外信息以将不适定问题转换为更稳定的适定问题的一类方法。应用丢弃层意味着训练期间在一个或多个网络层中概率性地删除一些节点和相应输入
[0304]
机器学习中的一个常见问题是容量太少的模型无法学习该问题,而容量太大的模型可以很好地学习该问题并过拟合训练数据集。在两种场景中,模型都不能很好地泛化。在训练神经网络时减少过拟合的一种方法是改变网络复杂性。神经网络模型的容量,它的复杂性,由依据节点和层的结构以及依据权重的参数两者来定义。因此,可以通过改变网络结构(权重的数量)和/或通过改变网络参数(权重的值)来降低神经网络的复杂性以减少过拟合。例如,可以通过在神经网络的全连接层上应用多个不同的丢弃层来调整结构,直到找到合适数量的节点和/或层来减少或移除问题的过拟合。
[0305]
图6根据本发明的实施例描绘了特征提取mll程序的网络架构600,该网络架构支持用于特征向量生成的监督式学习方法。由一系列自动编码器604组成的深度神经网络以分层方式在图像块中提取的多个特征上进行训练。经训练的网络能够稍后执行分类任务,例如基于从图像块中提取的光学特征,将块中描绘的组织分类为“基质组织”、“背景载玻片区域”、“肿瘤细胞”、“转移组织”等类别之一的成员。网络架构包括瓶颈层606,该瓶颈层具有比输入层603少得多的神经元并且随后可以是进一步的隐藏层和分类层。根据一个示例,瓶颈层包括输入层神经元数量的大约1.5%。输入层和瓶颈层之间可能有数百甚至数千个隐藏层,并且瓶颈层提取的特征可以称为“深度瓶颈特征”(dbnf)。
[0306]
图7描绘了具有也称为“报告块库”的图像块库的gui 700。报告库(行标签702、704、706和708下方的块矩阵)允许用户探索由mil程序识别的组织模式,以对特定标签具有高预测能力。库包括相对于目标特定标签(或“类别”)具有最高数值的块中的一个,例如通过mil程序计算的“对药物d治疗有应答=真”。基于组织载玻片图像(以及相应患者)对块进行分组,并根据为类别标签计算的其相应预测值在它们的组内进行排序。
[0307]
在图7所描绘的示例中,使用注意力mll对预测值进行加权的mil程序被用于计算权重,但如果根据加权的预测得分对块进行排序,考虑到模型不确定性,库看起来会很相似。因此,根据本发明的实施例,gui700包括报告块库,该报告块库的块根据它们分别计算的加权的预测值wh来选择和排序,其中权重对应于确定性值c。图7和8中描绘的块库仅用于说明,因为块的排序顺序对于基于预测值或加权的预测值的排序顺序是相似的。然而,申请人已经观察到,当使用包括基于确定性值的池化函数的mil程序时,分类的精度和识别特定类别的最相关/预测块的精度是最佳的。
[0308]
图7中描绘的报告库可包括针对库中的块中的每个块,在训练之后可能已经自动确定的整体预测精度。此外,或替代性地,报告库可包括分配给相应图像的标签和针对该标签获得的每个包的预测准确性。例如,“基本事实=0”可以代表标签“患者对药物d有应答”,“基本事实=1”可以代表标签“患者对药物d没有应答”。通过mil计算出的特定图像的所有块的最高数值显示为从所述图像导出的块组顶部的“预测值”h或“加权的预测值”wh。
[0309]
在所描绘的库中,块行702显示第一患者的六个块。所述块中的第一个已分配最高预测值(预后值)指示特定组织载玻片/全视野载玻片图像相对于标签的预测能力。每个载玻片组的第一块可以额外地或替代性地已经分配从特定组织载玻片图像导出的所有块的最高组合值(从由mil所提供的数值和由注意力mll计算出的权重导出)。
[0310]
如图7中所示的gui描绘,最高预测值可以显示在每位患者的最高得分块顶部。
[0311]
仅包括具有最高预测值或最高加权的预测值的块的子集的报告块库可能是有利的,因为病理学家不需要检查全视野载玻片。相反,病理学家的注意力自动指向每个全视野载玻片图像的少量子区域(块),该图像的组织模式已识别相对于目标标签具有最高预测能力。
[0312]
根据图7中描绘的实施例,报告图像块库显示从h&e染色图像导出的图像块。报告图像块库的组织方式如下:
[0313]
行702包括已经分配了通过基于注意力的mil程序计算出的最高数值(指示预测能力,即预后值)的六个块,这些块在从第一患者的特定全视野载玻片图像712导出的所有块内。根据其他实施例,基于与通过mil计算出的预测值相同的得分值或者是通过mil计算出的数值(例如,加权的预测值wh)的导数值来执行排序。
[0314]
用于生成其中一些显示在行712中的块的第一患者的组织样品的相应全视野载玻片图像712在空间上接近于该高度相关的块的所选集712。
[0315]
此外,显示的任选的相关度热图722突出显示了所有全视野载玻片图像区域,其通过mil计算出的加权的预测值类似于图像712的一个块的数值,其中最高数值指示预测能力已计算。在这种情况下,自动识别和选择计算出的最高数值的块之一(例如,在行712中第一位置的块)并用作计算相关度热图722的基础。根据替代性实施方式,相关度热图722不表示块的数值与针对图像的所有块计算出的最高数值的相似性,而是表示块与针对图像的所有块计算出的最高组合得分的相似度。组合得分可以是由注意力mll针对块计算出的权重的与由mil计算出的指示块相对于图像标签的预测能力的数值的组合,例如乘积。根据更进一步的实施例,相关度热图722表示由注意力mll计算出的块的权重与由注意力mll针对图像的所有块计算出的最高权重的相似度。
[0316]
列704包括已经分配了通过mil程序计算出的所有块内最高数值的六个块,这些块
从第二患者的特定全视野载玻片图像714导出。显示相应的全视野载玻片图像714在空间上接近这个所选的高度相关的块集。此外,显示的相关度热图724突出显示了所有全视野载玻片图像区域,该图像区域由mil计算出的相应数值与由mil计算出的最高数值的全视野载玻片图像714的块高度相似。
[0317]
列706包括已经分配了通过mil程序计算出的所有块内最高数值的六个块,这些块从第三患者的特定全视野载玻片图像716导出。相应的全视野载玻片图像716在空间上接近所选的高度相关的块集。此外,显示的相关度热图726突出显示了所有全视野载玻片图像区域,该图像区域由mil计算出的相应数值与由mil计算出的最高数值的全视野载玻片图像716的块高度相似。
[0318]
列708包括已经分配了通过mil程序计算出的所有块内最高数值的六个块,这些块从患者的特定全视野载玻片图像718导出。相应的全视野载玻片图像718在空间上接近所选的高度相关的块集。此外,显示的相关度热图728突出显示了所有全视野载玻片图像区域,该图像区域由mil计算出的相应数值与由mil计算出的最高数值的全视野载玻片图像718的块高度相似。
[0319]
根据实施例,在报告块库中呈现的相关度热图指示预测能力、或基于注意力的权重和/或基于确定性值的权重、或它们的组合。在所描绘的示例中,热图中的亮像素描绘了图像中块具有高预测值、高基于确定性值的权重或它们的组合的区域。根据实施例,相关度热图的计算包括确定块的得分(例如,数值、权重或组合值)是否高于图像的最高得分块的得分的最小百分比值。如果是,则相关度热图中的相应块由第一颜色或“亮”强度值表示,例如“255”。如果不是,则相关度热图中的相应块由第二种颜色或“暗”强度值表示,例如“0”。
[0320]
用户可以选择报告块库中的每个块以启动相似性搜索(例如,通过双击块或通过单击选择块,然后选择gui元素“搜索”),然后将显示一个相似性搜索块库,例如如图8所示。
[0321]
可选gui元素710集合中的“黑名单”和“重新训练”元素使用户能够定义块的黑名单并基于除黑名单中的块和与黑名单中的块高度相似的块之外的所有块重新训练mil程序。例如,黑名单可以包括手动选择的具有特别低数值(预测值)的块集,例如因为它们包含伪影,或具有特别高的数值(排除具有非常高预测能力的块可增加mil识别额外的、迄今为止未知的组织模式的能力,这些模式相对于目标标签也具有预测能力)。图像分析系统可以配置为响应于用户将特定块添加到黑名单,自动识别其特征向量与添加到黑名单的块的特征向量的相似度超过最小相似度阈值的所有块。识别出的块也自动添加到黑名单中。当用户选择重新训练-gui元素时,除了黑名单中的块外,mil将在训练数据集的所有块上进行重新训练。
[0322]
图8描绘了根据本发明的实施例的具有相似性搜索图像块库的gui800。相似性搜索通过基于用户的对报告库700中830块的选择触发。
[0323]
该搜索在从全视野载玻片图像812-818中的每一个生成的块内识别例如基于比较特征向量的相似性的六个最相似的块的子集。在相似性搜索中识别的块按每个全视野载玻片图像或每个患者分组,并根据它们与选择触发相似性搜索的块830(“查询块”)的相似性以降序进行排序。
[0324]
全视野载玻片图像812-818和相似性热图822-828指示其特征向量(以及因此所描绘的组织模式)与所选块的特征向量最相似的块的位置。
[0325]
任选地,相似度搜索块库还包括以下一项或多项数据:
[0326]-分配给从中导出描绘的块的图像的标签;图8中描绘的一个标签是“基本事实:0”;
[0327]-通过mil程序计算出的每个包(图像)相对于包的标签的预测精度;
[0328]-全视野载玻片图像中类似块的计数和/或相似块与相异块比较的百分比(得分)(例如,通过阈值处理)
[0329]-全视野载玻片图像中所有块的相似性值的平均值、中值或直方图。
[0330]
例如,用户可以选择报告库的块830中的一个,该报告库已分配最高预测值(例如最高h或wh)且因此关于图像标签/类别隶属关系的最高预测能力。通过选择块,用户可以跨块和许多不同患者的图像发起基于块的相似性搜索,这些患者可能已经分配了与当前选择的块不同的标签。相似性搜索是基于特征向量和块的比较,以基于相似特征向量来确定相似块和相似组织模式。通过评估并显示与所选块(及其组织模式)相似但具有与所选块的标签不同的标签(例如“患者对药物d有应答=假”而不是“患者对药物d有应答=真”)的块(及相应组织模式)的数量和/或分数。
[0331]
因此,病理学家可以通过选择通过mil程序返回的称为“高度预后”的块来轻松检查通过mil程序识别的组织模式的预测能力,特别是敏感性和特异性,以执行相似性搜索,揭示数据集中多少具有相似特征向量的块已分配与所选块相同的标签。与最新的机器学习应用程序相比,这是一个巨大的优势,机器学习应用程序也可提供组织图像预后特征的指示,但我们不允许用户识别和验证这些特征。基于报告库和相似性搜索库,人类用户可以验证所提出的高预后组织模式,并且还可以用语言表述在所有具有高预测能力的块中显示并与相似特征向量相关联的共同特征和结构。
[0332]
报告库中的块是可选的并且选择触发执行相似性搜索以识别和显示具有与用户选择的块相似的特征向量/组织模式的其他块的特征可使用户能够自由选择他或她感兴趣的报告块库中的任何图像。例如,病理学家可能对如上所述的具有最高预测能力(由mil计算出的最高数值)的组织模式和相应块感兴趣。替代性地,病理学家可对通常具有特别低的预测能力(特别低的数值)的伪影感兴趣。另外替代性地,病理学家可以出于任何其他原因对特定组织模式感兴趣,例如,因为它揭示了药物的一些副作用或任何其他相关的生物医学信息。病理学家可自由选择相应报告块库中的任何一个块。从而,病理学家触发相似性搜索以及以相似性块库的形式计算和显示结果。完成相似性搜索后,可以自动刷新显示和gui。
[0333]
根据一些实施例,相似性搜索库的计算和显示包括相似性热图822-828的计算和显示。热图以颜色和/或像素强度对相似块和相应特征向量进行编码。具有相似特征向量的图像区域和块在热图中以相似颜色和/或高或低像素强度表示。因此,用户可快速获得全视野载玻片图像中特定组织模式特征的分布的概览。只需选择不同的块即可轻松刷新热图,因为该选择会根据新选择的块的特征向量自动诱导特征向量相似性的重新计算。
[0334]
根据实施例,相似性搜索库包括相似性热图。该方法包括通过子方法创建相似性热图,该子方法包括:
[0335]-选择报告库中的一个块;
[0336]-针对一些或所有所接收的图像的其他块中的每一个,通过将从相同图像的其他
块的特征向量与所选块的特征向量进行比较来计算关于所选块的相似性得分;
[0337]-针对块用于计算相应的相似性得分的图像中的每一个,计算相应的相似性热图作为相似性得分的函数,相似性热图的像素颜色和/或像素强度指示所述图像中的块与所选块的相似性;以及
[0338]-显示相似性热图。
[0339]
根据实施例,相似性搜索库中显示的图像块也是可选择的。
[0340]
相似性热图可以提供有价值的概览信息,该信息允许人类用户轻松感知目标特定组织模式在特定组织中或在具有特定标签的患者亚群的组织样品中出现的广泛程度。用户可以自由选择搜索库中的任意块,从而分别诱导基于分配给当前所选块的特征向量重新计算相似性热图,以及自动刷新包含相似性热图的gui。
[0341]
根据实施例,报告库和/或相似性搜索块库中的图像块基于从患者组织样品图像导出的块进行分组。根据替代实施例,报告库和/或相似性搜索块库中的图像块基于分配给从中导出块的图像的标签进行分组。
[0342]
通常,从同一患者导出的所有图像将具有相同的标签,并且来自特定患者的那些图像的所有块将被mil处理为同一“包”的成员。但是,在某些特殊情况下,可能是同一患者的不同图像已经分配了不同的标签。例如,如果第一图像描绘了患者的第一转移,且第二图像描绘了同一患者的第二转移,并且观察结果是第一转移对药物d的治疗作出应答而消失,而第二转移继续生长,则患者相关属性值可按图像方式进行分配,而不是按患者方式进行分配。在这种情况下,每个患者可能会有多包块。
[0343]
根据另一示例,在用特定药物治疗之前和之后拍摄的患者组织样品的图像以及用于训练mil程序和/或应用经训练的mil程序的终点(标签)是属性值“组织状态=用药物d治疗后”或属性值“组织状态=用药物d治疗前”。基于所述患者相关属性值训练mil程序可具有识别组织模式的优势,该模式指示药物对肿瘤的活性和形态学影响。这种已识别的与药物效应相关的组织模式可以验证和探索药物的作用方式以及潜在的药物副作用。
[0344]
根据实施例,该方法进一步包括:通过创建额外一组块以计算方式增加块包的数量,每个额外一组块被mil程序处理为额外的块包,该块包已经分配了与生成源块的组织图像相同的标签。额外的块集的创建特别地包括:对至少块的子集应用一个或多个伪影生成算法以创建包括伪影的新块。此外,或替代性地,额外的块包的创建可包括提高或降低至少块的子集的分辨率以创建比它们相应的源块粒度更细或粒度更粗的新块。
[0345]
例如,可以通过随机选择从所述患者获得的一个或多个组织图像的一些或所有块为患者中的每一个获得子集。伪影生成算法模拟图像伪影。图像伪影可以是,例如,在组织制备、染色和/或图像采集期间产生的伪影类型(例如边缘伪影、过度染色、染色不足、灰尘、斑点伪影(通过高斯模糊等进行模拟)。此外,或替代性地,伪影可以是通用噪声类型(例如通过遮挡、颜色抖动、高斯噪声、椒盐噪声、旋转、翻转、歪斜失真等进行模拟)。
[0346]
额外的块包的创建可能具有从有限的可用训练数据集生成额外的训练数据的优势。额外的训练数据代表图像数据,该图像数据的质量可能会因经常发生在样品制备和图像采集的情况下的常见的失真、伪影和噪声而降低。因此,扩大的训练数据集可确保避免训练期间mil程序基础模型的过拟合。
[0347]
根据实施例,该方法进一步包括计算从一个或多个所接收的数字图像获得的块群
集,其中块基于它们的特征向量的相似性被分组到群集中。优选地,针对患者中的每一个计算群集。这意味着如果块的特征向量足够相似,则来自描绘同一患者的不同组织载玻片的不同图像的块可分组到同一群集中。
[0348]
根据其他实施例,针对源自所有患者的所有块一起计算群集。
[0349]
在这两种聚集块的方法中(不同患者的所有块在一起或每个患者的所有块),看起来彼此相似(即具有相似特征向量)的块被聚集到同一群集中。
[0350]
例如,在“不同患者聚集的所有块”的情况下,聚集的结果可能是生成例如64组(群集)块用于所有患者的所有块。64个群集中的每一个都包含从不同患者导出的相似块。相反,在每个患者聚集的情况下,每个患者将拥有自己的64个群集。
[0351]
如果为每个患者创建群集,则可能是患者图像没有包含脂肪的块或包含脂肪的块非常少。在这种情况下,可能不会创建“脂肪群集”,因为没有足够的数据来学习围绕“脂肪”特征向量的群集。但是对所有患者的所有块一起执行聚集方法可具有以下优势:可使用最大数量的可用数据识别更多的群集/组织类型:在“所有患者块”聚集中,可能会识别出“脂肪”组织模式的群集,因为至少有些患者的活体组织检查中有一些脂肪细胞。因此,数据集中描绘块的脂肪细胞数量足够的概率,将创建脂肪细胞群集(也适用于脂肪细胞含量非常少的患者)。如果为所有患者的所有块在一起创建群集,并且一个群集代表脂肪细胞,则所有含有来自所有患者的脂肪细胞的块都将被分组到该群集中。这意味着针对专用的患者/包,所有带有脂肪细胞的块都将在所述群集中进行分组,并且如果群集采样用于包,则选择属于所述群集的一定数量的块(来自当前患者/包)。
[0352]
块的聚集可能是有利的,因为该操作可揭示在特定患者中可观察到的组织模式的数量和/或类型。根据一些实施例,gui包括用户可选择的元素,该元素使用户能够在聚集库视图中触发块的聚集以及块群集的呈现。这可以帮助用户直观且快速地理解在患者的特定组织样品中观察到的重要类型的组织模式。
[0353]
根据实施例,mil程序的训练包括对块集进行重复地采样以便从块集中挑选块的子集,并基于块的子集训练mil程序。
[0354]
本文使用的术语“采样”是在数据分析或训练机器学习算法的情况下使用的技术,该技术包括从数据集(从患者的一个或多个图像中获得的块的总体)中的多个n数据项(实例、块)中挑选特定数量的l样品。根据实施例,“采样”包括根据假定在统计学上表示训练数据集中的n块的总体的概率分布,从n数据项的数量内选择数据项的子集。这可以允许更准确地了解整个人群的特征。概率分布代表了指导机器学习过程并使“从数据中学习”可行的统计假设。
[0355]
根据一些实施例,通过随机选择块的子集以提供采样的块包来执行采样。
[0356]
根据实施例,聚集和采样组合如下:采样包括从针对患者获得的块群集中的每一个选择块,使得在采样中创建的块的每个子集中的块数量对应于取自所述块的群集的大小。
[0357]
例如,可以从特定患者的数字组织图像创建1000个块。聚集创建了显示包括300个块的背景组织载玻片区域的第一群集,显示包括400个块的基质组织区域的第二群集,显示包括200个块的转移性肿瘤组织的第三群集,显示包括40个块的特定染色伪影的第四群集,显示包括60个块的具有微血管的组织的第五群集。
[0358]
根据一个实施例,采样包括从群集中的每一个选择特定部分的块,例如50%。这将意味着来自群集1的150个块、来自群集2的200个块、来自群集3的100个块、来自群集4的20个块和来自群集5的30个块。
[0359]
根据优选实施例,采样包括从每个群集中选择相等数量的块。这种采样方法可具有以下优势:从不同类型的聚集中抽取相同数量的块/组织模式示例,从而使训练数据集更加平衡。如果期望的预测特征在训练数据集中很少见,这可增加经训练的mil和/或经训练的注意力mll的准确性。
[0360]
聚集和采样的组合可能是特别有利的,因为可以通过采样增加用于训练的数据基础,而不会无意中“丢失”实际上具有高预测能力的少数块。通常在数字病理学的背景下,组织样品的绝大多数区域不包括由特定疾病或其他患者相关属性修改或预后的组织区域。例如,组织样品的仅一个小的子区域可能实际上包含肿瘤细胞,其余部分可能显示正常组织。通过首先执行块聚集且然后从群集中的每一个选择块可确保显示预后组织模式的至少一些块,例如,确保肿瘤细胞或微血管始终是样品的一部分。
[0361]
图9示出了2d和3d坐标系中块的空间距离,这些坐标系用于基于从块的空间接近度自动导出的相似性标签自动将相似性标签分配给块对。因此,提供了用于训练特征提取mll的训练数据集,该数据集不需要领域专家手动注释图像或块。
[0362]
图9a示出了由数字组织样品训练图像900的x轴和y轴定义的2d坐标系中块的空间距离。训练图像900描绘了患者的组织样品。从患者获得组织样品后,将样品置于显微镜载玻片上并用一种或多种组织学相关的染色剂染色,例如h&e和/或各种生物标志物特异性染色剂。训练图像900是从染色的组织样品中获取的,例如使用载玻片扫描显微镜。根据一些实施变型,所接收的训练图像中的至少一些是从不同患者和/或是从同一患者的不同组织区域(活组织检查)导出的并且因此不能在3d坐标系中彼此对齐。在这种情况下,可以在由如下所述的图像的x和y坐标定义的2d空间内计算块距离。
[0363]
训练图像900拆分成多个块。出于说明目的,图9a中的块尺寸大于通常的块尺寸。
[0364]
可以通过以下方法自动用标签标记训练数据集:首先,选择起始块902。然后,确定围绕该这个起始块的第一圆区域。第一圆的半径也称为第一空间接近度阈值908。这个第一圆内的所有块,例如块906,被认为是起始块902的“附近”块。此外,还确定了围绕这个起始块的第二圆区域。第二圆的半径也称为第二空间接近度阈值910。这个第二圆之外的所有块,例如块904是相对于起始块902的“远处”块。
[0365]
然后,创建第一块对集,其中第一集的每个块对包括起始块和起始块的“附近”块。例如,该步骤可包括创建与第一圆中包含的附近块一样多的块对。替代性地,该步骤可包括随机选择可用附近块的子集并通过将起始块添加到所选附近块来为所选附近块中的每一个创建块对。
[0366]
创建第二块对集。第二集的每个块对包括起始块和相对于起始块的“远处”块。例如,该步骤可包括创建与在第二圆之外的图像800中包含的远处块一样多的块对。替代性地,该步骤可包括随机选择可用的远处块的子集并通过将起始块添加到所选远处块来为所选远处块中的每一个创建块对。
[0367]
然后,图像900内的另一块可以用作起始块并且可以类似地执行上述步骤。这意味着使用新的起始块作为中心重新绘制第一圆和第二圆。从而,识别相对于新的起始块的附
近块和远处块。第一块集补充有基于新的起始块识别的附近块对,而第二块集补充有基于新的起始块识别的远处块对。
[0368]
然后,可以选择图像900内的另一块作为起始块并且可以重复上述步骤,从而进一步用更多的块对补充第一块对集和第二块对集。可以执行新的起始块的选择,直到图像中的所有块都曾经选为起始块或者直到已经选择了预定数量的块作为起始块。
[0369]
针对第一集中的块对中的每一个,例如对912,分配“相似”标签。针对第二集中的块对中的每一个,例如对914,分配“相异”标签。
[0370]
图9b示出了由数字组织样品图像900的x轴和y轴以及对应于彼此对齐的图像900、932、934的堆叠高度的z轴定义的3d坐标系中的块的空间距离根据由训练图像900、932、934分别描绘的组织块的组织切片的相对位置。训练图像分别描绘从特定患者的单个组织块导出的组织样品。所描绘的组织样品属于一堆多个相邻的组织切片。例如,该堆组织切片可以从ffpet组织块离体制备。将组织块切片,并将切片放置在显微镜载玻片上。然后,对切片进行染色,如参考图8a针对图像900所述。
[0371]
由于该堆内的组织样品从单个组织块导出,因此可以在公共3d坐标系内对齐数字图像900、932、934,由此z轴与组织切片正交。z轴是与组织切片正交的轴。图像在z方向上的距离对应于所述图像所描绘的组织切片的距离。如果一对的两个块从同一图像导出,则在2d空间内计算块对的块距离。此外,可以创建块对,该块对的块从在公共3d坐标系中彼此对齐的不同图像导出。在这种情况下,一对中两个块的距离是使用3d坐标系计算的。
[0372]
将对齐的数字图像中的每一个拆分成多个块。出于说明目的,图9b中的块尺寸大于通常的块尺寸。
[0373]
可以通过以下方法自动用标签标记训练数据集:首先,选择起始块902。然后,如下所述识别的和用标签标记的包括起始块和附近块的块对以及包括起始块和远处块的块对。
[0374]
确定围绕这个起始块的第一3d球体。出于说明目的,仅显示了第一球体的横截面。第一球体的半径也称为第一空间接近度阈值936。这个第一球体内的所有块,例如图像900中的块906以及图像934中的块940被认为是起始块902的“附近”块。此外,还确定了围绕这个起始块的第二球体。第二球体的半径也称为第二空间接近度阈值938。这个第二球体之外的所有块,例如图像900的块904以及图像934的块942是相对于开始块902的“远处”块。
[0375]
创建第一块对集,其中第一集的每个块对包括起始块和起始块的“附近”块。例如,该步骤可以包括创建与第一球体中包含的附近块一样多的块对。替代性地,该步骤可包括随机选择可用附近块的子集并通过将起始块添加到所选附近块来为所选附近块中的每一个创建块对。
[0376]
创建第二块对集。第二集的每个块对包括起始块和相对于起始块的“远处”块。例如,该步骤可以包括创建与在第二球体外的图像900、932、934中包含的远处块一样多的块对。替代性地,该步骤可包括随机选择可用的远处块的子集并通过将起始块添加到所选远处块来为所选远处块中的每一个创建块对。
[0377]
然后,图像900内或图像932、934内的另一块可以用作起始块并且可以类似地执行上述步骤。这意味着第一球体和第二球体使用新的起始块作为中心重新绘制。从而,识别相对于新的起始块的附近块和远处块。第一块集补充有基于新的起始块识别的附近块对,而第二块集补充有基于新的起始块识别的远处块对。
[0378]
可以重复上述步骤,直到所接收的图像900、932、934中的每一个的每个块都选为起始块(或直到满足另一终止标准),从而用进一步的块对进一步补充第一块对集和第二块对集。
[0379]
针对第一集中的块对中的每一个,例如对912和913,分配“相似”标签。针对第二集中的块对中的每一个,例如对914和915,分配“相异”标签。
[0380]
图9a和9b中所示的基于圆和球的距离计算只是用于计算基于距离的相似性标签的示例,在这种情况下,二进制标签应该是“相似”或“相异”。可能会使用其他方法,例如计算2d或3d坐标系中两个块之间的欧几里得距离,并计算与两个块的欧几里德距离呈负相关的数值相似度性。
[0381]
由于一毫米组织对应的像素数量取决于各种因素,例如图像捕获设备的放大倍数和数字图像的分辨率,本文将针对所描绘的真实物理对象指出所有距离阈值,即组织样品或组织样品覆盖的载玻片。
[0382]
图10描绘了根据本发明实施例训练的孪生网络的架构,用于提供能够从图像块提取具有生物医学意义的特征向量的子网络,该图像块适用于执行基于特征向量的相似性搜索和/或基于特征向量的块的聚集。该孪生网络1000在自动用标签标记的训练数据集上根据包括具有基于接近度的相似性标签的块对进行训练,该基于接近度的相似性标签(例如参考图9a和/或9b所描述的)是自动创建的。
[0383]
孪生神经网络1000由在其输出层1024处连接的两个相同子网络1002、1003组成。每个网络包括输入层1005、1015,适于接收作为输入的单个数字图像(例如块)954、914。每个子网络包括多个隐藏层1006、1016、1008、1018。通过两个子网络中的相应一个从两个输入图像之一中提取一维特征向量1010、1020。因此,每个网络的最后隐藏层1008、1018适于计算特征向量并将特征向量提供给输出层1024。输入图像的处理是严格分开的。这意味着,该子网络仅处理输入图像1054,并且子网络仅处理输入图像1014。当输出层比较两个向量以确定向量相似性时,两个输入图像中传达的信息唯一结合的点是在输出层中,并且从而确定两个输入图像中描绘的组织模式的相似性。
[0384]
根据实施例,每个子网络1002、1003基于修改的resnet-50架构(he等人,deep residual learning for image recognition,2015,cvpr’15)。根据实施例,resnet-50预训练子网络902、903在imagenet上进行预训练。最后一层(通常输出1,000个特征)用全连接层1008、1018替换,其尺寸具有特征向量的期望尺寸,例如尺寸128。例如,每个子网络的最后一层1008、1018可以被配置为从倒数第二层提取特征,由此倒数第二层可以提供比最后一层1008、1018多得多的特征数量(例如2048)。根据实施例,优化器,例如使用pytorch中的默认参数(学习率为0.001,beta为0.9,0.999)的adam优化器,并且在训练期间使用了256的批量尺寸。针对数据增强,随机水平和垂直翻转和/或高达20度的随机旋转,和/或亮度、对比度饱和度和/或色调值为0.075的颜色抖动增强可以应用于块以增加训练数据集。
[0385]
当孪生神经网络在自动用标签标记的图像对上进行训练时,学习过程的目标是相似图像应该具有彼此相似的输出(特征向量),而相异的图像应该具有彼此相异的输出。这可以通过最小化损失函数来实现,例如衡量两个子网络提取的特征向量之间差异的函数。
[0386]
根据实施例,使用损失函数在块对上训练孪生神经神经元网络,使得由两个子网络针对该对的两个块提取的特征向量的相似性分别与该对的两个块中描绘的组织模式的
相似性相关。
[0387]
例如,孪生神经网络可以是,如bromley等人在“使用
‘
孪生神经’时间延迟神经网络的特征验证,1994,nips’1994”中所述的孪生神经网络。孪生神经网络的每个子网络适于从作为输入所提供的两个图像块中的相应一个提取多维特征向量。该网络在多个已自动标注有基于邻近度的组织模式相似性标签的块对上进行训练,目标是描绘相似组织模式的块对应具有彼此接近(相似)的输出(特征向量),以及描绘相异组织模式的块对应该具有彼此远离的输出。根据一个实施例,这是通过执行对比损失来实现的,例如hadsell等人所描述的,通过学习不变映射进行降维,2006,cvpr`06。在训练期间,将对比损失最小化。可以例如,根据以下计算对比损失cl cl=(1-y)2(f1-f2) y*最大(0,m-l2(f1-f2)),
[0388]
其中f1,f2是两个相同子网络的输出,并且y是块对的基本事实标签:如果它们用标签标记为“相似”(第一块对集),则为0,如果它们用标签标记为“相异”(第二块对集),则为1。
[0389]
孪生神经网络1000的训练包括向网络1000供给多个自动用标签标记的相似912、913和相异914、915块对。每个输入训练数据记录1028包括块对的两个块及其自动分配的、基于空间接近度的标签1007。基于接近度的标签10007作为“基本事实”提供。输出层1024适合于计算针对两个输入图像1004、1014的预测相似性标签,作为两个相比较的特征向量1008、1018的相似性的函数。孪生神经网络的训练包括一个反向传播过程。预测标签926与输入标签1007的任何偏差都被视为以损失函数的形式测量的“错误”或“损失”。孪生神经网络的训练包括通过迭代使用反向传播来最小化通过损失函数计算出的误差。例如,可以实现孪生神经网络1000,如bromley等人在“使用
‘
孪生神经’时间延迟神经网络的特征验证”,1994,nips’1994中所述。
[0390]
图11描绘了例如参考图10所述的作为截短的孪生神经网络实现的特征提取mll 950。
[0391]
特征提取mll 950可以,例如,通过分别存储经训练的孪生神经网络1000的子网络1002、1003之一来获得。与经训练的孪生神经网络相反,用作特征提取mll的子网络1002、1003仅需要单个图像952作为输入,并且不输出相似性标签,而是输出特征向量954,该特征向量选择性地包括限定特征集,该限定特征集在孪生神经网络1000的训练期间被识别为针对特定组织模式具有特定特征,并且特别适合通过从两个图像中提取和比较该特定的特征集来确定两个图像中描绘的组织模式的相似性。
[0392]
图12描绘了在图像数据库中使用基于特征向量的相似性搜索的计算机系统980。例如,相似性搜索可用于计算搜索块库,图8中描绘了一个示例。计算机系统980包括一个或多个处理器982和经训练的特征提取mll 950,该mll 950可以是经训练的孪生神经网络(“截短的孪生神经网络”)的子网络。系统980适用于使用特征提取mll来执行图像相似性搜索,以分别从搜索图像和从搜索图像(块)中的每一个中提取特征向量。
[0393]
例如,计算机系统可以是标准计算机系统或由数据库992组成或操作上与之耦合的服务器。例如,数据库可以是相关的bdsm,包括描绘多个患者的组织样品的成百上千的全视野载玻片图像。优选地,针对数据库中的图像中的每一个,数据库包括已经由特征输出mll 950从数据库中的所述图像提取的相应特征向量。优选地,在接收任何此类请求之前,在单个预处理步骤中执行数据库中每个图像的特征向量的计算。然而,也可以响应于搜索
请求动态地计算和提取数据库中图像的特征向量。搜索可以限于从特定数字图像导出的块,例如用于识别描绘与搜索图像986中描绘的组织模式相似的组织模式的单个全视野载玻片图像内的块。搜索图像986可以是例如包含在由用户选择的报告块库中的块。
[0394]
计算机系统包括使用户984能够选择或提供用作搜索图像986的特定图像或图像块的用户界面。经训练的特征提取mll 950适用于从输入图像中提取特征向量988(“搜索特征向量”)。搜索引擎990从特征输出mll 950接收搜索特征向量988并在图像数据库中执行基于向量的相似性搜索。相似性搜索包括将搜索特征向量与数据库中图像的特征向量中的每一个进行比较,以计算相似性得分作为两个相比较的特征向量的函数。相似性得分指示搜索特征向量与数据库中图像的特征向量的相似性程度,并且从而指示两个相比较图像中描绘的组织模式的相似性。搜索引擎990适用于向用户返回并输出搜索结果994。搜索结果可以是,例如,数据库的计算出最高相似性得分的一个或多个图像。
[0395]
例如,如果搜索图像986是已知描绘乳腺癌组织的图像块,则系统980可用于识别描绘类似乳腺癌组织模式的多个其他块(或包括此类块的全视野载玻片图像)。
[0396]
图13显示了两个块矩阵,每个矩阵由三列组成,每列包含六个块对。第一(上)矩阵显示了第一块对集(a),该第一块对集由彼此靠近的以及已被自动分配了标签“相似”的块对的块组成。第二(下)矩阵显示了第二块对集(b),彼此相距很远,并且已被自动分配了标签“相异”的块对。在某些情况下,用标签标记“相似”的块看起来相异,而用标签标记“相异”的块看起来相似。这种噪声的起因是:在两个不同组织模式相接的边界处,两个附近的块可能描绘不同的组织模式,并且甚至远处的组织区域也可能描绘相同的组织模式。这是数据集生成过程中预期的固有噪声。
[0397]
申请人已经观察到,尽管存在这种噪声,但在自动用标签标记的数据集上训练的特征提取mll能够准确地识别和提取特征,从而明确区分相似和相异的块对。申请人假设所观察到的经训练的mll对这种噪声的稳健性是基于这样一个事实:即区域边界的面积通常小于区域的非边界面积。
[0398]
根据实施例,自动生成的训练数据集的质量是在第一步中使用先前经训练的相似性网络或imagenet预训练网络来评估块对的相似性,然后在第二步中基于本文所述的针对本发明的实施例描述的块的空间接近度生成相似性标签,并且然后纠正成对标签,其中观察到一方面在第一步中确定的和另一方面在第二步中确定的两个块的相似性的强烈偏差。
[0399]
图14显示了基于相似性搜索结果的特征向量,该特征向量由在接近度的相似性标签上训练的特征提取mll提取。这5个肿瘤查询块称为a、b、c、d和e。查询块用于图像检索任务,用于分别识别和检索除查询载玻片(a1-a5、b1-b5、c1-c5、d1-d5、e1-e5)以外的5个块,按从低到高的距离进行排序,使用特征提取mll提取的特征向量,该特征提取mll在具有基于接近度的标签自动用标签标记的数据上进行训练。目标类别(例如肿瘤)仅占搜索到的块的3%。即使某些检索到的块看起来与查询块(例如c3和c)非常不同,但除a4之外的所有检索到的块都已由专家病理学家验证包含肿瘤细胞(即正确的类别检索)。
[0400]
图15显示了对输入图像212进行分类的方法i。图像212被拆分成多个块216,并且如前文所述,从图像的块中的每个块中提取相应的特征向量220。将特征向量依次输入到mil程序226的机器学习模型999中。该模型配置成针对输入到模型的每个特征向量计算和输出预测值h998和确定性值221。
[0401]
然后,池化函数997用于计算聚合的预测值997作为预测值998和确定性值221两者的函数。例如,池化函数可以聚合加权的预测值228,即,通过由mil模型999针对块计算的确定性值加权的预测值,所述预测值是针对所述块计算的。替代性地,可以通过池化函数评估确定性值以识别特定预测值,例如图像的所有块中确定性值最高的块的预测值。然后,聚合的预测值通常是归一化为0到1范围内的值的数值,用于对图像212进行分类。例如,在聚合的预测值887小于0.75的情况下,mil程序可以将图像分类为“负类别”的成员,否则分类为“正类别”的成员。
[0402]
图16显示了对图像212进行分类的替代性方法ii。在此种方法中,池化函数996不是应用于预测值,而是应用于从图像的块216提取的特征向量。该池化函数考虑针对块计算的确定性值221。池化函数计算聚合的特征向量,也称为“全局特征向量”995。该全局特征向量传递从图像212的块的多个特征和多个确定性值聚合的信息。在计算了全局特征向量995之后,该向量以与图像的块的“正常”特征向量fv1、fv2...fv2相同的方式输入到mil程序的机器学习模型999。mil程序从全局特征向量计算聚合的预测值997,计算方式与它从相应块特定特征值计算预测值998中的任何一个预测值的方式相同,但是由于全局向量包括从所有块导出的信息,因此从全局值计算出的预测值是聚合的预测值。最后,聚合的预测值用于对图像212进行分类。
[0403]
参考编号列表
[0404]
100
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
方法
[0405]
102-116
ꢀꢀꢀꢀꢀ
步骤
[0406]
200
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
图像分析系统
[0407]
202
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
处理器
[0408]
204
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
显示器
[0409]
206
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
图像块库
[0410]
207
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
经分类的图像
[0411]
208
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片加热m达ap
[0412]
210
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
存储介质
[0413]
212
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
数字图像
[0414]
214
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
拆分模块
[0415]
216
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用标签标记的块的包
[0416]
218
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
特征提取模块
[0417]
220
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
特征向量
[0418]
221
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
确定性值
[0419]
222
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
注意力机器学习逻辑程序
[0420]
224
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
特征向量权重
[0421]
226
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
多实例学习程序
[0422]
228
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
块的数值相关度得分
[0423]
229
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
分类结果
[0424]
230
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
gui生成模块
[0425]
232
ꢀꢀꢀꢀꢀꢀꢀꢀ
gui
[0426]
300
ꢀꢀꢀꢀꢀꢀꢀꢀ
表1
[0427]
400
ꢀꢀꢀꢀꢀꢀꢀꢀ
表2
[0428]
502
ꢀꢀꢀꢀꢀꢀꢀꢀ
标准神经网络
[0429]
504
ꢀꢀꢀꢀꢀꢀꢀꢀ
丢弃后的神经网络
[0430]
600
ꢀꢀꢀꢀꢀꢀꢀꢀ
特征提取mll的网络架构
[0431]
602
ꢀꢀꢀꢀꢀꢀꢀꢀ
用作输入的图像块
[0432]
603
ꢀꢀꢀꢀꢀꢀꢀꢀ
输入层
[0433]
604
ꢀꢀꢀꢀꢀꢀꢀꢀ
多层
[0434]
606
ꢀꢀꢀꢀꢀꢀꢀꢀ
瓶颈层
[0435]
700
ꢀꢀꢀꢀꢀꢀꢀꢀ
包含报告块库的gui
[0436]
702
ꢀꢀꢀꢀꢀꢀꢀꢀ
相似块的第一子集第一组织模式
[0437]
704
ꢀꢀꢀꢀꢀꢀꢀꢀ
代表第二组织模式的相似块的第二子集
[0438]
706
ꢀꢀꢀꢀꢀꢀꢀꢀ
代表第三组织模式的相似块的第三子集
[0439]
708
ꢀꢀꢀꢀꢀꢀꢀꢀ
代表第四组织模式的相似块的第四子集
[0440]
710
ꢀꢀꢀꢀꢀꢀꢀꢀ
可选择gui元素集
[0441]
712
ꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0442]
714
ꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0443]
716
ꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0444]
718
ꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0445]
722
ꢀꢀꢀꢀꢀꢀꢀꢀ
相关度热图
[0446]
724
ꢀꢀꢀꢀꢀꢀꢀꢀ
相关度热图
[0447]
726
ꢀꢀꢀꢀꢀꢀꢀꢀ
相关度热图
[0448]
728
ꢀꢀꢀꢀꢀꢀꢀꢀ
相关度热图
[0449]
800
ꢀꢀꢀꢀꢀꢀꢀꢀ
包含相似性搜索块库的gui
[0450]
802
ꢀꢀꢀꢀꢀꢀꢀꢀ
相似块的第一子集第一组织模式
[0451]
804
ꢀꢀꢀꢀꢀꢀꢀꢀ
代表第二组织模式的相似块的第二子集
[0452]
806
ꢀꢀꢀꢀꢀꢀꢀꢀ
代表第三组织模式的相似块的第三子集
[0453]
808
ꢀꢀꢀꢀꢀꢀꢀꢀ
代表第四组织模式的相似块的第四子集
[0454]
812
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0455]
814
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0456]
816
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0457]
818
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
全视野载玻片图像
[0458]
822
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
相似性热图
[0459]
824
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
相似性热图
[0460]
826
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
相似性热图
[0461]
828
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
相似性热图
[0462]
830
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
查询块
[0463]
900
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
数字组织图像切成多个块
[0464]
902
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
块t1
[0465]
904
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
块t2
[0466]
906
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
块t3
[0467]
908
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第一空间接近度阈值(2d)
[0468]
910
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第二空间接近度阈值(2d)
[0469]
912
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用标签标记“相似”的块对
[0470]
913
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用标签标记“相似”的块对
[0471]
914
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用标签标记“相异”的块对
[0472]
915
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用标签标记“相异”的块对
[0473]
916
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
训练数据
[0474]
932
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
与图像900对齐的数字组织图像
[0475]
934
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
与图像932对齐的数字组织图像
[0476]
936
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第一空间接近度阈值(3d)
[0477]
938
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第二空间接近度阈值(3d)
[0478]
940
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
块t4
[0479]
942
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
块t5
[0480]
1000
ꢀꢀꢀꢀꢀꢀꢀꢀ
孪生神经网络
[0481]
1002
ꢀꢀꢀꢀꢀꢀꢀꢀ
子网络
[0482]
1003
ꢀꢀꢀꢀꢀꢀꢀꢀ
子网络
[0483]
1004
ꢀꢀꢀꢀꢀꢀꢀ
第一输入块
[0484]
1005
ꢀꢀꢀꢀꢀꢀꢀ
第一网络n1的输入层
[0485]
1006
ꢀꢀꢀꢀꢀꢀꢀ
隐藏层
[0486]
1007
ꢀꢀꢀꢀꢀꢀꢀ
基于接近度(“测量”)的相似性标签
[0487]
1008
ꢀꢀꢀꢀꢀꢀꢀ
用于针对第一输入块计算特征向量的隐藏层
[0488]
1010
ꢀꢀꢀꢀꢀꢀꢀ
从第一输入块中904中提取的特征向量
[0489]
1014
ꢀꢀꢀꢀꢀꢀꢀ
第二输入块
[0490]
1015
ꢀꢀꢀꢀꢀꢀꢀ
第二网络n2的输入层
[0491]
1016
ꢀꢀꢀꢀꢀꢀꢀ
隐藏层
[0492]
1018
ꢀꢀꢀꢀꢀꢀꢀ
适用于针对第二输入块计算特征向量的隐藏层
[0493]
1020
ꢀꢀꢀꢀꢀꢀꢀ
从第二输入块914中提取的特征向量
[0494]
1022
ꢀꢀꢀꢀꢀꢀꢀ
输入块对
[0495]
1024
ꢀꢀꢀꢀꢀꢀꢀ
连接网络n1、n2的输出层
[0496]
1026
ꢀꢀꢀꢀꢀꢀꢀ
预测相似度标签
[0497]
1028
ꢀꢀꢀꢀꢀꢀꢀ
训练数据集的单独数据记录
[0498]
950
ꢀꢀꢀꢀꢀꢀꢀꢀ
特征提取mll
[0499]
952
ꢀꢀꢀꢀꢀꢀꢀꢀ
单独输入图像/块
[0500]
954
ꢀꢀꢀꢀꢀꢀꢀꢀ
特征向量
[0501]
980
ꢀꢀꢀꢀꢀꢀꢀꢀ
计算机系统
[0502]
982
ꢀꢀꢀꢀꢀꢀꢀꢀ
处理器
[0503]
984
ꢀꢀꢀꢀꢀꢀꢀꢀ
用户
[0504]
986
ꢀꢀꢀꢀꢀꢀꢀꢀ
单独输入图像/块
[0505]
988
ꢀꢀꢀꢀꢀꢀꢀꢀ
搜索特征向量
[0506]
990
ꢀꢀꢀꢀꢀꢀꢀꢀ
基于特征向量的搜索引擎
[0507]
992
ꢀꢀꢀꢀꢀꢀꢀꢀ
包含多个图像或块的数据库
[0508]
994
ꢀꢀꢀꢀꢀꢀꢀꢀ
返回的相似性搜索结果
[0509]
995
ꢀꢀꢀꢀꢀꢀꢀꢀ
全局特征向量
[0510]
996
ꢀꢀꢀꢀꢀꢀꢀꢀ
基于确定性值的池化函数
[0511]
997
ꢀꢀꢀꢀꢀꢀꢀꢀ
聚合的预测值
[0512]
998
ꢀꢀꢀꢀꢀꢀꢀꢀ
预测值
[0513]
999
ꢀꢀꢀꢀꢀꢀꢀꢀ
预测模型
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。