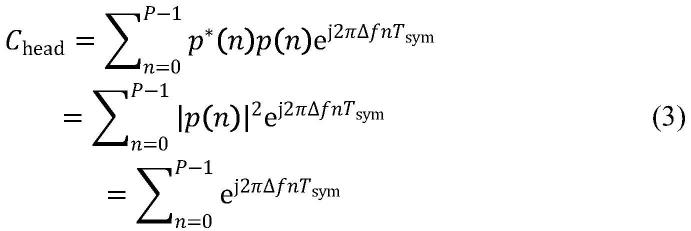1.本发明涉及软件定义网络技术,特别是一种基于网络演算的软件定义网络性能上界分析方法。
背景技术:
::2.软件定义网络(sdn,softwaredefinednetwork)提供了一种网络可编程方法,将网络的控制与管理逻辑从网络设备中分离出来,并向用户提供网络可编程能力,这使得网络功能的更新只需简单的软件更改,而不需要硬件模块的更改。随着sdn的不断发展,计算和衡量网络性能,从而根据用户对传输流的需求灵活选择相应的服务质量(qos,qualityofservice)策略,更有效地实现带宽分配,充分利用网络资源等显得愈发重要。网络演算是基于最小加代数分析网络性能的理论工具,该理论将计算机网络抽象描述为相互连接的网络元素,对网络中的数据流提供处理、传输服务。数据流的流量特征由到达曲线来描述,网元的服务能力由服务曲线来描述,从而分析推导出网络性能的上界。3.排队论可用于性能计算,可与基于openflow的sdn模型结合,计算分组平均转发时延,但不为确界,且复杂度较高。而国内外在使用网络演算计算sdn网络性能边界时,不太注重openflow规范中的细节,如流的转发必须依据流条目、流条目下发目标、流条目过期时交换机是否存储后续包等,且对流的到达曲线的分析不甚严格,常使用仿射到达曲线,无法准确描述流表超时机制导致流表未命中时数据包的到达情况,进而导致流表未命中时网络时延与积压上界计算结果的准确性低,无法为流表超时机制中的超时时间设置,以及路由和队列管理等技术提供支持。技术实现要素:4.本发明要给出一种能提升sdn网络性能计算准确性的基于网络演算的软件定义网络性能上界分析方法。5.为了实现上述目的,本发明的技术方案如下:一种基于网络演算的软件定义网络性能上界分析方法,包括以下步骤:6.a、sdn数据流处理流程描述7.在sdn中,交换机负责网络数据的高速转发,是网络转发平面;交换机由逻辑集中的控制器进行全局控制,控制器在建立openflow通道时,给交换机设置初始流条目,以使交换机将流表未命中的数据包送往控制器,控制器进行路由决策,在计算出下一端口时下发流条目给交换机,交换机完全依赖于流条目转发数据包。流经过sdn的处理流程描述如下:8.设a1表示进入交换机的流,经过流表管道处理后,会出现两种情形:流表命中流h1和流表未命中流m1。h1在管道处理过程结束后执行动作集,所述动作集包括转发、丢弃、排队和修改域;流表未命中时交换机向控制器发送一个异步消息packet-in,该消息中包含完整的数据包或仅包含包头,但交换机要对数据包进行缓存,且消息中包含缓冲区id。控制器对packet-in消息处理后,向交换机发送packet-out消息,将数据包从交换机的指定端口转发出去,相应的,消息中含有完整数据包或缓冲区id。若控制器在决策时得到数据包的下一跳,发送flow-mod消息,以向流表中添加相应流条目,防止后续数据包再次触发packet-in消息。m1*实线表示控制器对packet-in消息处理后,向交换机发送packet-out消息;m1*虚线表示控制器向流表中添加相应流条目;m2和m2*分别表示来自其他交换机的未命中流和控制器的输出流。9.b、建立网络演算中的基本定义10.定义1:广义增函数集11.设f(·)是非负实数集上的函数,如果对任意非负实数s,t有:[0012][0013]则称f是广义增函数集。[0014]定义2:最小加卷积[0015]设f(·),g(·)∈f,它们的最小加卷积为[0016][0017]式中,为卷积运算符,inf为函数的下确界。[0018]定义3:到达曲线[0019]设α(t),t≥0是一个广义增函数,r(t)是数据流的累积输入函数,如果对于0≤s≤t,有r(t)-r(s)≤α(t-s),则称α(t)为r(t)的到达曲线。[0020]仿射到达曲线用表示。参数ρ和σ分别称为平均速率和突发量。[0021]定义4:服务曲线[0022]设有一个系统s和通过系统s的流,该流的累积输入和输出函数分别为r(t)和r*(t),如果β(t)是广义递增的,β(0)=0且则称系统s向流提供了一条服务曲线β(t)。[0023]系统s提供给流的服务曲线是系统s保证给流的服务能力的下界。使用延迟-速率函数β(t)=r(t-t) 表示服务曲线。这里的r为系统服务速率,t为系统服务延迟,(t-t) =max{0,t-t}。[0024]定义5:时延上界与积压上界[0025]给定一个流,进入系统s时被到达曲线α(t)约束,通过系统s时系统s提供服务曲线β(t),在任意时刻t,时延上界为[0026][0027]其中h(α,β)为α与β的水平距离。数据积压上界为[0028][0029]其中sup是函数的上确界。[0030]c、分析流表命中时的网络性能[0031]在sdn中,设流经网络的数据流具有仿射到达曲线α(t)=ρt σ,路径上有n个交换机,第i个交换机为该流提供的延迟-速率服务曲线为βi(t)=ri(t-ti) ,i∈{1,2,…,n},ri和ti分别为第i个交换机的服务速率和服务延迟,d为交换机间的线路的时延,它提供服务曲线为δd(t)。多服务节点串联分析在网络演算理论中遵循“pay-bursts-only-once”。故由串联属性得整个网络为该流提供的服务曲线为:[0032][0033]则当ρ≤ri,i=1,2,…,n时,网络端到端时延上界和数据积压上界的计算公式为:[0034][0035][0036]d、分析流表未命中时网络性能[0037]流表未命中时,交换机向控制器发送packet-in消息,在交换机安装流条目之前,该流后续数据包进入交换机后依旧触发流表未命中的问题,分为数据包被缓存在交换机和数据包被转发至控制器两种情况,具体步骤如下:[0038]d1、未命中时数据包被缓存在交换机[0039]为防止包头相同的数据包再次触发packet-in消息,交换机为该流建立hold流条目,流后续数据包匹配此流条目而被缓存在交换机中。若为网络最差情况,后续流在此交换机所经历的额外时延表示为:[0040][0041]其中tsd为交换机处理时延,tcq为控制器中排队时延,tcd为控制器中处理时延,dc为openflow控制通道时延。m为sdn中流的数量,lmax表示数据包的最大长度,rs是交换机的服务速率,rc是控制器的服务速率。[0042]流在交换机i处发生流表未命中,则此交换机i与控制器视为提供了服务曲线δtmiss为未命中后续流所经历的额外时延,根据最小加运算的交换律、结合律,则整个网络提供的服务曲线表示为:[0043][0044]设到达曲线为仿射函数α(t)=ρt σ,当ρ≤ri,i=1,2,…,n时,网络端到端时延上界d(t)和积压上界b(t)计算公式为:[0045][0046][0047]d2、未命中时数据包被转发至控制器[0048]交换机安装控制器下发的流条目前,后续数据包均流表未命中,匹配table-miss流条目而被送往控制器。因流条目timeout字段,在两终端通信的过程中,流表命中及未命中两种情况会交替出现,即a1=h1 m1,在同一时刻,h1与m1其中之一的速率为0,两者相当于a1的两个分量。确定性网络演算理论是计算网络发生最差情况时的性能边界,若在t1时刻流表未命中,在t2时刻流条目下发且被安装好,在t3时刻流条目被删除,网络最差情况为:在时间段(t1,t2]内,数据包被交换机送往控制器;在时间段内(t2,t3]无数据包到达交换机,导致流条目因idle_timeout字段设置的超时被删除,即t2 idle=t3,其中idle为超时的时间。交换机删除此流条目后,后续数据包因流表未命中重复此过程。在此情形下,为了得到更准确的sdn网络端到端时延上界和积压上界,设置流的到达曲线为自定义函数αm1(t),该到达曲线比仿射到达曲线更为严格,即αm1(t)≤α(t)。[0049][0050]其中为下取整函数,若控制器为流m1提供的服务曲线为βc,则整个网络为流m1提供的服务曲线表示为:[0051][0052]其中,rc是控制器为在tmiss阶段送往控制器的流提供的服务速率,tc是控制器的服务延迟。[0053]则此时的端到端时延上界与仿射到达曲线的时延上界相同,即:[0054][0055]令r=min{r1,…,rn,rc},x=tmiss idle,根据到达曲线的特点,在每个((n-1)x,nx]内讨论数据积压。[0056]令当t∈((n-1)x,t1]时,数据积压上界在t处取得,即将t带入积压上界计算公式可得:[0057][0058]当t∈(t1,nx],因r·(nx-t)<min{ρ·idle,σ},数据积压上界在nx处取得,于是有数据积压上界的计算公式为:[0059]b(t)≤σ n[ρtmiss min{ρ·idle,σ}]-r[n(tmiss idle)-t]ꢀꢀꢀꢀꢀ(16)[0060]与现有技术相比,本发明具有以下有益效果:[0061]1、在控制器为路由路径上的所有交换机下发流条目时,针对由于流表超时机制导致的流表未命中问题,本发明依据网络最差情况出现的数据流,引入流表超时时间idle,提出了比传统仿射函数更为严格的到达曲线am1,进而提升了sdn网络性能计算准确性。[0062]2、基于上述到达曲线am1,提出流表未命中时,sdn网络时延和积压上界计算方法,将为流表超时机制中的超时时间的设置,软件定义网络的路由设计、队列管理等提供依据。附图说明[0063]图1是sdn数据流处理流程描述图。[0064]图2是ρ·idle>σ时的到达曲线αm1(t)。[0065]图3是0<ρ·idle≤σ时的到达曲线αm1(t)。[0066]图4是仿真网络拓扑。[0067]图5是路径跳数与端到端时延上界。[0068]图6是突发量与端到端时延上界。[0069]图7是发送速率与网络积压上界。具体实施方式[0070]下面结合附图对本发明进行进一步说明。一种基于网络演算软件定义网络性能上界分析方法,具体步骤如下:[0071]step1:流经过sdn的处理流程用图1表示,并描述如下:设a1表示进入交换机的流,经过流表管道处理后,会出现两种情形:流表命中流h1和流表未命中流m1。h1在管道处理过程结束后执行动作集,通常是转发;流表未命中时交换机向控制器发送一个异步消息packet-in,该消息中包含完整的数据包或仅包含包头,但交换机要对数据包进行缓存,且消息中包含缓冲区id。控制器对packet-in消息处理后,向交换机发送packet-out消息,将数据包从交换机的指定端口转发出去,相应的,消息中含有完整数据包或缓冲区id。若控制器在决策时得到数据包的下一跳,会发送flow-mod消息,以向流表中添加相应流条目,防止后续数据包再次触发packet-in消息。m1*实线表示控制器对packet-in消息处理后,向交换机发送packet-out消息;m1*虚线表示控制器向流表中添加相应流条目;m2和m2*表示来自其他交换机的未命中流和控制器的输出流。[0072]step2:当流表命中时,设流经网络的数据流具有仿射到达曲线α(t)=ρt σ,路径上有n个交换机,每个交换机为该流提供的延迟-速率服务曲线为βi(t)=ri(t-ti) ,i∈{1,2,…,n},ri和ti分别为每个交换机的服务速率和服务延迟,d为交换机间的线路的时延,它提供服务曲线为δd(t)。在ρ≤ri,i=1,2,…,n情况下,使用如下公式计算网络端到端时延上界和数据积压上界:在sdn中,[0073][0074][0075]step3:当流表未命中,数据包被缓存在交换机时,源节点发出第一个分组,路由路径上第一个交换机触发packet-in消息,至交换机安装该业务流对应的流条目,该时间段为tmiss,可用下式计算:[0076][0077]其中tsd为交换机处理时延,tcq为控制器中排队时延,tcd为控制器中处理时延,dc为openflow控制通道时延。m为sdn中流的数量,lmax表示数据包的最大长度,rs是交换机的服务速率,rc是控制器的服务速率,则此交换机i与控制器视为提供了服务曲线为未命中后续流所经历的额外时延,且ρ≤ri,i=1,2,…,n时,用下式计算网络端到端时延上界和积压上界:[0078][0079][0080]step4:针对同一路由路径的业务流,因到达曲线的聚合属性,可将多个业务流视为一个业务流,也可分别单独计算。突发量和平均速率为业务流的预设属性,也可通过测试计算。[0081]源节点发出第一个分组,路由路径上第一个交换机触发packet-in消息,至交换机安装该业务流对应的流条目,该时间段为tmiss;查看控制器处理packet-in消息的模块,其中下发流条目的子模块会设置idletimeout字段,得出公式中变量idle。得出本发明提出的自定义到达曲线:[0082][0083]其中为下取整函数。[0084]不同情况下,到达曲线的形状不同,当ρ·idle>σ时,到达曲线如图2所示。当0<ρ·idle≤σ时,到达曲线如图3所示。[0085]step5:针对路由路径上的交换机、链路以及控制器,其为业务流的服务能力可预设,也可测试计算,再使用网络演算的最小加卷积运算,得出网络为业务流提供的网络服务曲线。[0086][0087]其中,β1为网络中一条路径中的交换机该流提供的服务曲线,βc为控制器为流m1提供的服务曲线,rc是控制器为tmiss阶段送往控制器的流提供的服务速率,tc是控制器的服务延迟。[0088]step6:此时的端到端时延上界计算公式为:[0089][0090]step7:令r=min{r1,…,rn,rc},x=tmiss idle,[0091]当t∈((n-1)x,t1]时,数据积压上界在t处取得,即将t带入积压上界计算公式可得:[0092][0093]当t∈(t1,nx],因r·(nx-t)<min{ρ·idle,σ},数据积压上界在nx处取得,于是有数据积压上界的计算公式为:[0094]b(t)≤σ n[ρtmiss min{ρ·idle,σ}]-r[n(tmiss idle)-t]ꢀꢀꢀꢀꢀ(16)[0095]仿真使用的网络拓扑如图4所示,其中hi为终端用户、si为交换机,c0为控制器。得出图5-7的仿真结果与理论结果比较图。[0096]实验一:设置终端的发送速率为2mbit/s,突发量为20kbits,调整两终端通信路径的交换机数量进行测试,结果如图5所示。显然,随路径跳数增加,无论流表命中还是未命中,仿真结果与本发明提出的计算方法得到的端到端时延都增大,且本发明提出的计算方法得到的端到端时延很好反映时延的变化情况。[0097]实验二:设置终端的发送速率为2mbit/s,两终端路径跳数为5,受发包工具ipef的局限,突发量通过更改发包速率来实现,仿真结果如图6所示。突发量较大时,在第一个分组因流表未命中被送往控制器请求路由时,从该时刻到流条目被交换机安装的时间段内,后续多个分组仍会匹配table-miss流条目,积压在控制器的缓冲队列中,这是突发量在流表未命中情况下sdn网络端到端时延的主要影响因素。随突发量增加,仿真最大值逐渐趋向理论值,这是因为理论值中的σ/min{r1,…,rn,rc}占比随突发量的增大而增大,降低了网元服务曲线延时t对理论值的影响。本发明提出的计算方法得到的端到端时延很好反映时延的变化情况并给出较准确的时延上界解析表达式。[0098]实验三:设置两终端路径跳数为5,突发量σ为0.1mbits,流表超时时间为20ms,调整发包速率与发包时间使其在流表命中的情况下符合仿射到达曲线,在流表未命中的情况下符合本发明给出的到达曲线。通过wireshark监听发、收两端连接的交换机端口,当监听到数据包进入网络时,进入网络的数据包累积量加1;当监听到数据包离开网络时,离开网络的数据包累积量加1。仿真时间10秒,期间两者的最大差值即为仿真中数据流的网络积压最大值,仿真结果如图7所示。显然,随发包速率增加,网络积压增大。当发送速率较小时,仿真积压与理论计算积压上界较为接近。当前第1页12当前第1页12
背景技术:
::2.软件定义网络(sdn,softwaredefinednetwork)提供了一种网络可编程方法,将网络的控制与管理逻辑从网络设备中分离出来,并向用户提供网络可编程能力,这使得网络功能的更新只需简单的软件更改,而不需要硬件模块的更改。随着sdn的不断发展,计算和衡量网络性能,从而根据用户对传输流的需求灵活选择相应的服务质量(qos,qualityofservice)策略,更有效地实现带宽分配,充分利用网络资源等显得愈发重要。网络演算是基于最小加代数分析网络性能的理论工具,该理论将计算机网络抽象描述为相互连接的网络元素,对网络中的数据流提供处理、传输服务。数据流的流量特征由到达曲线来描述,网元的服务能力由服务曲线来描述,从而分析推导出网络性能的上界。3.排队论可用于性能计算,可与基于openflow的sdn模型结合,计算分组平均转发时延,但不为确界,且复杂度较高。而国内外在使用网络演算计算sdn网络性能边界时,不太注重openflow规范中的细节,如流的转发必须依据流条目、流条目下发目标、流条目过期时交换机是否存储后续包等,且对流的到达曲线的分析不甚严格,常使用仿射到达曲线,无法准确描述流表超时机制导致流表未命中时数据包的到达情况,进而导致流表未命中时网络时延与积压上界计算结果的准确性低,无法为流表超时机制中的超时时间设置,以及路由和队列管理等技术提供支持。技术实现要素:4.本发明要给出一种能提升sdn网络性能计算准确性的基于网络演算的软件定义网络性能上界分析方法。5.为了实现上述目的,本发明的技术方案如下:一种基于网络演算的软件定义网络性能上界分析方法,包括以下步骤:6.a、sdn数据流处理流程描述7.在sdn中,交换机负责网络数据的高速转发,是网络转发平面;交换机由逻辑集中的控制器进行全局控制,控制器在建立openflow通道时,给交换机设置初始流条目,以使交换机将流表未命中的数据包送往控制器,控制器进行路由决策,在计算出下一端口时下发流条目给交换机,交换机完全依赖于流条目转发数据包。流经过sdn的处理流程描述如下:8.设a1表示进入交换机的流,经过流表管道处理后,会出现两种情形:流表命中流h1和流表未命中流m1。h1在管道处理过程结束后执行动作集,所述动作集包括转发、丢弃、排队和修改域;流表未命中时交换机向控制器发送一个异步消息packet-in,该消息中包含完整的数据包或仅包含包头,但交换机要对数据包进行缓存,且消息中包含缓冲区id。控制器对packet-in消息处理后,向交换机发送packet-out消息,将数据包从交换机的指定端口转发出去,相应的,消息中含有完整数据包或缓冲区id。若控制器在决策时得到数据包的下一跳,发送flow-mod消息,以向流表中添加相应流条目,防止后续数据包再次触发packet-in消息。m1*实线表示控制器对packet-in消息处理后,向交换机发送packet-out消息;m1*虚线表示控制器向流表中添加相应流条目;m2和m2*分别表示来自其他交换机的未命中流和控制器的输出流。9.b、建立网络演算中的基本定义10.定义1:广义增函数集11.设f(·)是非负实数集上的函数,如果对任意非负实数s,t有:[0012][0013]则称f是广义增函数集。[0014]定义2:最小加卷积[0015]设f(·),g(·)∈f,它们的最小加卷积为[0016][0017]式中,为卷积运算符,inf为函数的下确界。[0018]定义3:到达曲线[0019]设α(t),t≥0是一个广义增函数,r(t)是数据流的累积输入函数,如果对于0≤s≤t,有r(t)-r(s)≤α(t-s),则称α(t)为r(t)的到达曲线。[0020]仿射到达曲线用表示。参数ρ和σ分别称为平均速率和突发量。[0021]定义4:服务曲线[0022]设有一个系统s和通过系统s的流,该流的累积输入和输出函数分别为r(t)和r*(t),如果β(t)是广义递增的,β(0)=0且则称系统s向流提供了一条服务曲线β(t)。[0023]系统s提供给流的服务曲线是系统s保证给流的服务能力的下界。使用延迟-速率函数β(t)=r(t-t) 表示服务曲线。这里的r为系统服务速率,t为系统服务延迟,(t-t) =max{0,t-t}。[0024]定义5:时延上界与积压上界[0025]给定一个流,进入系统s时被到达曲线α(t)约束,通过系统s时系统s提供服务曲线β(t),在任意时刻t,时延上界为[0026][0027]其中h(α,β)为α与β的水平距离。数据积压上界为[0028][0029]其中sup是函数的上确界。[0030]c、分析流表命中时的网络性能[0031]在sdn中,设流经网络的数据流具有仿射到达曲线α(t)=ρt σ,路径上有n个交换机,第i个交换机为该流提供的延迟-速率服务曲线为βi(t)=ri(t-ti) ,i∈{1,2,…,n},ri和ti分别为第i个交换机的服务速率和服务延迟,d为交换机间的线路的时延,它提供服务曲线为δd(t)。多服务节点串联分析在网络演算理论中遵循“pay-bursts-only-once”。故由串联属性得整个网络为该流提供的服务曲线为:[0032][0033]则当ρ≤ri,i=1,2,…,n时,网络端到端时延上界和数据积压上界的计算公式为:[0034][0035][0036]d、分析流表未命中时网络性能[0037]流表未命中时,交换机向控制器发送packet-in消息,在交换机安装流条目之前,该流后续数据包进入交换机后依旧触发流表未命中的问题,分为数据包被缓存在交换机和数据包被转发至控制器两种情况,具体步骤如下:[0038]d1、未命中时数据包被缓存在交换机[0039]为防止包头相同的数据包再次触发packet-in消息,交换机为该流建立hold流条目,流后续数据包匹配此流条目而被缓存在交换机中。若为网络最差情况,后续流在此交换机所经历的额外时延表示为:[0040][0041]其中tsd为交换机处理时延,tcq为控制器中排队时延,tcd为控制器中处理时延,dc为openflow控制通道时延。m为sdn中流的数量,lmax表示数据包的最大长度,rs是交换机的服务速率,rc是控制器的服务速率。[0042]流在交换机i处发生流表未命中,则此交换机i与控制器视为提供了服务曲线δtmiss为未命中后续流所经历的额外时延,根据最小加运算的交换律、结合律,则整个网络提供的服务曲线表示为:[0043][0044]设到达曲线为仿射函数α(t)=ρt σ,当ρ≤ri,i=1,2,…,n时,网络端到端时延上界d(t)和积压上界b(t)计算公式为:[0045][0046][0047]d2、未命中时数据包被转发至控制器[0048]交换机安装控制器下发的流条目前,后续数据包均流表未命中,匹配table-miss流条目而被送往控制器。因流条目timeout字段,在两终端通信的过程中,流表命中及未命中两种情况会交替出现,即a1=h1 m1,在同一时刻,h1与m1其中之一的速率为0,两者相当于a1的两个分量。确定性网络演算理论是计算网络发生最差情况时的性能边界,若在t1时刻流表未命中,在t2时刻流条目下发且被安装好,在t3时刻流条目被删除,网络最差情况为:在时间段(t1,t2]内,数据包被交换机送往控制器;在时间段内(t2,t3]无数据包到达交换机,导致流条目因idle_timeout字段设置的超时被删除,即t2 idle=t3,其中idle为超时的时间。交换机删除此流条目后,后续数据包因流表未命中重复此过程。在此情形下,为了得到更准确的sdn网络端到端时延上界和积压上界,设置流的到达曲线为自定义函数αm1(t),该到达曲线比仿射到达曲线更为严格,即αm1(t)≤α(t)。[0049][0050]其中为下取整函数,若控制器为流m1提供的服务曲线为βc,则整个网络为流m1提供的服务曲线表示为:[0051][0052]其中,rc是控制器为在tmiss阶段送往控制器的流提供的服务速率,tc是控制器的服务延迟。[0053]则此时的端到端时延上界与仿射到达曲线的时延上界相同,即:[0054][0055]令r=min{r1,…,rn,rc},x=tmiss idle,根据到达曲线的特点,在每个((n-1)x,nx]内讨论数据积压。[0056]令当t∈((n-1)x,t1]时,数据积压上界在t处取得,即将t带入积压上界计算公式可得:[0057][0058]当t∈(t1,nx],因r·(nx-t)<min{ρ·idle,σ},数据积压上界在nx处取得,于是有数据积压上界的计算公式为:[0059]b(t)≤σ n[ρtmiss min{ρ·idle,σ}]-r[n(tmiss idle)-t]ꢀꢀꢀꢀꢀ(16)[0060]与现有技术相比,本发明具有以下有益效果:[0061]1、在控制器为路由路径上的所有交换机下发流条目时,针对由于流表超时机制导致的流表未命中问题,本发明依据网络最差情况出现的数据流,引入流表超时时间idle,提出了比传统仿射函数更为严格的到达曲线am1,进而提升了sdn网络性能计算准确性。[0062]2、基于上述到达曲线am1,提出流表未命中时,sdn网络时延和积压上界计算方法,将为流表超时机制中的超时时间的设置,软件定义网络的路由设计、队列管理等提供依据。附图说明[0063]图1是sdn数据流处理流程描述图。[0064]图2是ρ·idle>σ时的到达曲线αm1(t)。[0065]图3是0<ρ·idle≤σ时的到达曲线αm1(t)。[0066]图4是仿真网络拓扑。[0067]图5是路径跳数与端到端时延上界。[0068]图6是突发量与端到端时延上界。[0069]图7是发送速率与网络积压上界。具体实施方式[0070]下面结合附图对本发明进行进一步说明。一种基于网络演算软件定义网络性能上界分析方法,具体步骤如下:[0071]step1:流经过sdn的处理流程用图1表示,并描述如下:设a1表示进入交换机的流,经过流表管道处理后,会出现两种情形:流表命中流h1和流表未命中流m1。h1在管道处理过程结束后执行动作集,通常是转发;流表未命中时交换机向控制器发送一个异步消息packet-in,该消息中包含完整的数据包或仅包含包头,但交换机要对数据包进行缓存,且消息中包含缓冲区id。控制器对packet-in消息处理后,向交换机发送packet-out消息,将数据包从交换机的指定端口转发出去,相应的,消息中含有完整数据包或缓冲区id。若控制器在决策时得到数据包的下一跳,会发送flow-mod消息,以向流表中添加相应流条目,防止后续数据包再次触发packet-in消息。m1*实线表示控制器对packet-in消息处理后,向交换机发送packet-out消息;m1*虚线表示控制器向流表中添加相应流条目;m2和m2*表示来自其他交换机的未命中流和控制器的输出流。[0072]step2:当流表命中时,设流经网络的数据流具有仿射到达曲线α(t)=ρt σ,路径上有n个交换机,每个交换机为该流提供的延迟-速率服务曲线为βi(t)=ri(t-ti) ,i∈{1,2,…,n},ri和ti分别为每个交换机的服务速率和服务延迟,d为交换机间的线路的时延,它提供服务曲线为δd(t)。在ρ≤ri,i=1,2,…,n情况下,使用如下公式计算网络端到端时延上界和数据积压上界:在sdn中,[0073][0074][0075]step3:当流表未命中,数据包被缓存在交换机时,源节点发出第一个分组,路由路径上第一个交换机触发packet-in消息,至交换机安装该业务流对应的流条目,该时间段为tmiss,可用下式计算:[0076][0077]其中tsd为交换机处理时延,tcq为控制器中排队时延,tcd为控制器中处理时延,dc为openflow控制通道时延。m为sdn中流的数量,lmax表示数据包的最大长度,rs是交换机的服务速率,rc是控制器的服务速率,则此交换机i与控制器视为提供了服务曲线为未命中后续流所经历的额外时延,且ρ≤ri,i=1,2,…,n时,用下式计算网络端到端时延上界和积压上界:[0078][0079][0080]step4:针对同一路由路径的业务流,因到达曲线的聚合属性,可将多个业务流视为一个业务流,也可分别单独计算。突发量和平均速率为业务流的预设属性,也可通过测试计算。[0081]源节点发出第一个分组,路由路径上第一个交换机触发packet-in消息,至交换机安装该业务流对应的流条目,该时间段为tmiss;查看控制器处理packet-in消息的模块,其中下发流条目的子模块会设置idletimeout字段,得出公式中变量idle。得出本发明提出的自定义到达曲线:[0082][0083]其中为下取整函数。[0084]不同情况下,到达曲线的形状不同,当ρ·idle>σ时,到达曲线如图2所示。当0<ρ·idle≤σ时,到达曲线如图3所示。[0085]step5:针对路由路径上的交换机、链路以及控制器,其为业务流的服务能力可预设,也可测试计算,再使用网络演算的最小加卷积运算,得出网络为业务流提供的网络服务曲线。[0086][0087]其中,β1为网络中一条路径中的交换机该流提供的服务曲线,βc为控制器为流m1提供的服务曲线,rc是控制器为tmiss阶段送往控制器的流提供的服务速率,tc是控制器的服务延迟。[0088]step6:此时的端到端时延上界计算公式为:[0089][0090]step7:令r=min{r1,…,rn,rc},x=tmiss idle,[0091]当t∈((n-1)x,t1]时,数据积压上界在t处取得,即将t带入积压上界计算公式可得:[0092][0093]当t∈(t1,nx],因r·(nx-t)<min{ρ·idle,σ},数据积压上界在nx处取得,于是有数据积压上界的计算公式为:[0094]b(t)≤σ n[ρtmiss min{ρ·idle,σ}]-r[n(tmiss idle)-t]ꢀꢀꢀꢀꢀ(16)[0095]仿真使用的网络拓扑如图4所示,其中hi为终端用户、si为交换机,c0为控制器。得出图5-7的仿真结果与理论结果比较图。[0096]实验一:设置终端的发送速率为2mbit/s,突发量为20kbits,调整两终端通信路径的交换机数量进行测试,结果如图5所示。显然,随路径跳数增加,无论流表命中还是未命中,仿真结果与本发明提出的计算方法得到的端到端时延都增大,且本发明提出的计算方法得到的端到端时延很好反映时延的变化情况。[0097]实验二:设置终端的发送速率为2mbit/s,两终端路径跳数为5,受发包工具ipef的局限,突发量通过更改发包速率来实现,仿真结果如图6所示。突发量较大时,在第一个分组因流表未命中被送往控制器请求路由时,从该时刻到流条目被交换机安装的时间段内,后续多个分组仍会匹配table-miss流条目,积压在控制器的缓冲队列中,这是突发量在流表未命中情况下sdn网络端到端时延的主要影响因素。随突发量增加,仿真最大值逐渐趋向理论值,这是因为理论值中的σ/min{r1,…,rn,rc}占比随突发量的增大而增大,降低了网元服务曲线延时t对理论值的影响。本发明提出的计算方法得到的端到端时延很好反映时延的变化情况并给出较准确的时延上界解析表达式。[0098]实验三:设置两终端路径跳数为5,突发量σ为0.1mbits,流表超时时间为20ms,调整发包速率与发包时间使其在流表命中的情况下符合仿射到达曲线,在流表未命中的情况下符合本发明给出的到达曲线。通过wireshark监听发、收两端连接的交换机端口,当监听到数据包进入网络时,进入网络的数据包累积量加1;当监听到数据包离开网络时,离开网络的数据包累积量加1。仿真时间10秒,期间两者的最大差值即为仿真中数据流的网络积压最大值,仿真结果如图7所示。显然,随发包速率增加,网络积压增大。当发送速率较小时,仿真积压与理论计算积压上界较为接近。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。