1.本发明实施例涉及一种适用于神经网络算法的计算装置。
背景技术:
2.深度神经网络(dnn)和卷积神经网络(cnn)大量应用于图像分类、自然语言处理等领域,提高了大规模识别任务的准确性。神经网络算法中存在大量卷积层运算。目前,通常使用cpu gpu架构来处理神经网络算法,需要将数据、权重和偏置从内存移动到处理单元,然后将中间结果存储回内存。这种模式的计算延迟较大,功耗较高。随着神经网络规模的扩大,以cpu gpu架构处理神经网络算法的模式逐渐遇到了速度和功耗的瓶颈。
技术实现要素:
3.本发明提供了一种适用于的神经网络算法的计算装置。计算装置包括处理器和sram模块。所述sram模块包括sram阵列、加法器以及卷积运算输入电路。在卷积运算模式,所述sram阵列的第一部分用于存储卷积运算的权重矩阵,所述sram阵列的第二部分用于存储所述卷积运算的偏置项。在卷积运算时钟的多个周期,所述卷积运算输入电路将所述卷积运算的输入矩阵中的输入数据逐位输入所述sram模块的第一部分,所述卷积运算输入电路将所述偏置项的激活数据逐位输入所述sram模块的第二部分。在所述卷积运算时钟的所述多个周期中的每个周期,所述sram阵列的第一部分用于获得所述输入数据的1位和所述权重矩阵中对应权重数据的乘积。所述加法器用于对所述卷积运算时钟的所述多个周期获得的多个乘积进行移位加法运算,所述偏置项的激活数据使得所述sram阵列的第二部分中存储的偏置项在所述卷积运算时钟的所述多个周期中的最后一个周期被输入所述加法器。
4.在本发明的另一实现方式中,所述sram阵列包括多个sram单元、多条字线、多条输入线以及多组输出线,每个sram单元包括存储子单元和乘法子单元,所述乘法子单元的第一输入端连接所述存储子单元,第二输入端连接对应的输入线,输出端连接对应一组输出线中的一个输出线,所述乘法子单元用于实现1位乘法。
5.在本发明的另一实现方式中,所述乘法子单元为异或门。
6.在本发明的另一实现方式中,所述卷积运算的权重矩阵为a行b列的矩阵,所述sram阵列的第一部分包括所述sram阵列中的a*b行,所述a*b行中的每行用于存储所述权重矩阵中的一个权重数据。
7.在本发明的另一实现方式中,所述sram阵列的第二部分包括所述sram阵列中的一行。
8.在本发明的另一实现方式中,所述输入矩阵的精度为i位,在所述卷积运算时钟的i个周期,以从最高位到最低位的顺序,所述卷积运算的输入矩阵的输入数据逐位输入所述sram阵列的第一部分中的对应行的输入线。
9.在本发明的另一实现方式中,所述sram模块还包括控制器,所述控制器包括:精度计数器和偏置项激活数据产生电路。所述精度计数器在所述卷积运算时钟的第i个周期产
生触发信号。在所述卷积运算时钟的i个周期中的每个周期,所述偏置项激活数据产生电路产生所述激活数据的1位,在所述偏置项激活数据没有接收到所述触发信号的情况下,产生的所述激活数据的1位为0,在所述偏置项激活数据接收到所述触发信号的情况下,产生的所述激活数据的1位为1。
10.在本发明的另一实现方式中,所述计算装置还包括内存,当所述处理器向所述sram模块发送的使能信号为第一值时,所述sram模块进入卷积运算模式,当所述处理器向所述sram模块发送的使能信号为第二值时,所述sram模块进入高速缓冲存储器模式。
11.在本发明的另一实现方式中,所述计算装置为边缘计算装置。
12.在本发明实施例的一个方面,计算装置的sram模块执行卷积运算时,权重矩阵和偏置项都存储在sram阵列中,输入数据和权重数据的乘积与偏置项的加法由sram模块的加法器执行,相比于由处理器的加法器执行偏置项的加法,节省了从内存读取偏置项的步骤,提高了计算效率。
13.在本发明实施例的另一个方面,偏置项激活数据产生电路基于卷积运算时钟产生激活数据,精度计数器在所述卷积运算时钟的第i个周期产生触发信号,在偏置项激活数据接收到触发信号的情况下,产生的所述激活数据的1位为1。通过精度计数器和偏置项激活数据产生电路,实现卷积运算中的偏置项的加法运算。
14.在本发明实施例的又一个方面,计算装置的sram模块可以根据待处理运算的类型设置为卷积运算模式和高速缓冲存储器模式。在高速缓冲存储器模式,sram模块作为处理器和内存之间的高速缓冲存储器,对于并行运算较少、乘积累加运算较少的运算具有较高的效率。在卷积运算模式,sram模块用于执行乘积累加运算,能够提高神经网络算法的效率。因此,计算装置能够适用更多应用场景。
附图说明
15.此处的附图被并入说明书中并构成本说明书的一部分,这些附图示出了符合本发明的实施例,并与说明书一起用于说明本发明的技术方案。下文将参照附图以示例性而非限制性的方式详细描述本发明的一些具体实施例。附图中相同的附图标记标示了相同或类似的部件或部分。本领域技术人员应该理解,这些附图未必是按比值绘制的。
16.图1为本发明的实施例提供的计算装置的结构框图。
17.图2为本发明的实施例提供的sram模块的结构框图。
18.图3为本发明的实施例提供的sram阵列的结构框图。
19.图4为本发明的实施例提供的sram单元的电路图。
20.图5为本发明的实施例提供的控制器的结构框图。
21.图6为本发明的实施例提供的sram模块进行乘积累加运算的示意图。
具体实施方式
22.下面将结合附图,对本发明实施例中的技术方案进行描述。本发明阐述了各种细节,因为这些细节涉及某些实施例。然而,本发明也可以以与本文描述的方式不同的方式实现。在不脱离本发明的情况下,本领域技术人员可以对所讨论的实施例进行修改。因此,本发明不限于本文公开的特定实施例。
23.图1是本发明的实施例提供的计算装置的结构框图。计算装置10包括:处理器200、sram(static random-access memory,静态随机存储器)模块100、内存300和输入输出模块400。计算装置10可执行多种运算,例如神经网络算法。处理器200例如为arm架构或x86架构。内存300例如为动态随机存储器(dynamic random access memory,dram)。内存300中存储可由处理器200执行的指令以及这些指令相关的数据。通过输入输出模块400,计算装置10连接其他装置,例如图像传感器、语音传感器等。处理器200、sram模块100、内存300和输入输出模块400封装在一起。处理器200和sram模块100可制作在同一芯片上。
24.在一些实施例中,计算装置10具有两种工作模式。在计算装置10的第一工作模式,sram模块100处于高速缓冲存储器模式,sram模块100作为处理器200和内存300之间的高速缓冲存储器(cache)。sram模块100包括读写速度比内存300更快的存储器。当处理器200从内存300中读出数据时,该数据也被存储到高速缓冲存储器中,当处理器200再次需要这些数据时,处理器200就从高速缓冲存储器读取数据,而不是访问较慢的内存300。当然,如需要的数据不在高速缓冲存储器,处理器200会再去读取内存300中的数据。在计算装置10的第二工作模式,sram模块100处于卷积运算模式,执行卷积运算中的乘积累加(multiply accumulate,mac)运算。
25.处理器200通过使能信号控制sram模块100在卷积运算模式和高速缓冲存储器模式间切换。例如,当处理器200判断待处理运算为卷积运算时,处理器200向sram模块100发送的使能信号为第一值(例如高电平),使sram模块100进入卷积运算模式,当所述处理器判断待处理运算为非卷积运算时,处理器200向sram模块100发送的使能信号为第二值(例如低电平),使sram模块100进入高速缓存模式。因此,计算装置10能够根据计算类型选择适合的计算模式,能够适用更多应用场景。
26.在一些实施例中,计算装置10作为边缘计算(edge computing)装置,应用于人工智能物联网(aiot)场景。在aiot场景,数据不是在远程服务器上处理,而是在接近传感器(数据源头)的计算装置10上处理。例如,计算装置10连接图像传感器或语音传感器,对图像传感器产生的图像数据或语音传感器产生的语音数据进行压缩,特征识别。
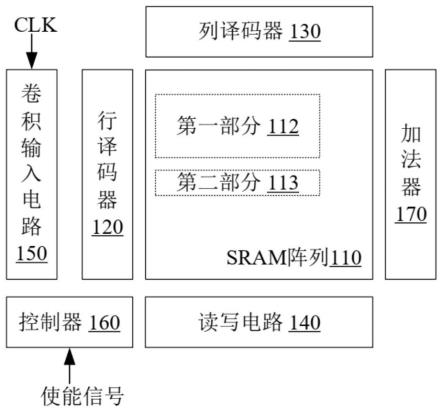
27.图2为本发明的实施例提供的sram模块的结构框图。如图2所示,sram模块100包括:sram阵列110、行译码器120、列译码器130、读写电路140、卷积运算输入电路150、控制器160和加法器170。
28.图3为本发明的实施例提供的sram阵列的示意图。如图3所示,sram阵列110包括:排列为多行多列的sram单元111、多条字线wl、多个位线对bl和blb、多条输入线input和多组输出线output。在图3所示的实施例中,sram阵列110包括q行m列的sram单元111。同一行的sram单元111连接同一字线wl、同一输入线input和同一组输出线output。一组输出线output包括m条输出线。每个sram单元111连接该组输出线output中的一条对应输出线。一行sram单元111对应的一组输出线output用于传输多位数据。同一列的sram单元111连接同一位线对(位线bl和其互补位线blb)。行译码器120连接该多条字线wl,用于根据行地址在多条字线wl中选择目标字线。列译码器130连接该多个位线对,用于根据列地址在多个位线对中选择目标位线对。读写电路140也连接该多个位线对。卷积运算输入电路150连接该多条输入线input。加法器170连接多组输出线output。加法器170例如为超前进位加法器。
29.sram阵列110包括多个sram单元。每个sram单元110包括:存储子单元和乘法子单
元。乘法子单元的第一输入端连接存储子单元,第二输入端连接sram单元110对应的输入线,输出端连接sram单元110对应的输出线。乘法子单元用于实现1位乘法。存储子单元例如为6-t结构或8-t的sram存储子单元。乘法子单元可以是任何能够实现1位乘法的电路,例如异或门。
30.图4为示例性sram单元的电路图。图4示出了sram阵列110的第一行中的前两个sram单元。如图4所示,sram单元111包括:第一反相器inv1、第二反相器inv2、第一选择晶体管t1、第二选择晶体管t2以及异或门xor。其中,存储子单元包括:第一反相器inv1、第二反相器inv2、第一选择晶体管t1、第二选择晶体管t2。乘法子单元包括异或门xor。
31.第一反相器inv1的输入端连接第二反相器inv2的输出端,第二反相器inv2的输入端连接第一反相器inv1的输出端。第一反相器inv1的输入端通过第一选择晶体管t1连接位线bl,第一反相器inv1的输入端记为节点q。第二反相器inv2的输入端通过第二选择晶体管t2连接互补位线blb,第二反相器inv2的输入端记为节点qb。第一选择晶体管t1和第二选择晶体管t2的栅极连接sram单元111对应的字线wl。异或门xor的第一输入端连接节点q,第二输入端连接sram单元111对应的输入线input,输出端连接sram单元111对应的输出线output。在一些实施例中,异或门xor的第一输入端连接节点qb,输入线input通过反相器连接异或门xor的第二输入端。在mac运算中,由异或门xor实现1位的乘法运算。
32.每个存储子单元存储1位(bit)的数据。数据存储在节点q和qb,节点q和qb存储相反的数据。当向sram单元111写入数据时,在字线wl施加高电平,第一选择晶体管t1和第二选择晶体管t2导通,读写电路140在位线bl和其互补位线blb上施加对应的目标电压,数据写入sram单元111。当从sram单元111中读出数据时,在字线wl施加高电平,第一选择晶体管t1和第二选择晶体管t2导通,读写电路140通过位线bl和互补位线blb读出节点q或qb的数据。
33.在卷积运算模式,sram阵列110的第一部分112用于存储卷积运算的权重矩阵,sram阵列110的第二部分113用于存储卷积运算的偏置项。在卷积运算时钟clk的多个周期,卷积运算输入电路150将卷积运算的输入矩阵中的输入数据逐位输入sram模块110的第一部分112的输入线input,卷积运算输入电路150将偏置项的激活数据逐位输入sram模块100的第二部分113的输入线input。在卷积运算时钟clk的所述多个周期中的每个周期,所述sram阵列110的第一部分用于获得所述输入数据的1位和所述权重矩阵中对应权重数据的乘积。加法器170用于对所述卷积运算时钟clk的所述多个周期获得的多个乘积进行移位加法运算,所述偏置项的激活数据使得所述sram阵列的第二部分113中存储的偏置项在所述卷积运算时钟clk的所述多个周期中的最后一个周期被输入所述加法器170。
34.神经网络算法中涉及大量卷积运算。部分卷积运算中涉及偏置项。以2x2的输入矩阵和权重矩阵为例,带偏置项的卷积运算如下:
[0035][0036]
其中,为输入矩阵,为权重矩阵,bias为偏置项。权重矩阵例如是卷积核矩阵。输入矩阵包括多个元素(输入数据),权重矩阵包括多个元素(权重数
据)。卷积运算包括输入数据和权重数据之间的乘法,输入数据和权重数据的乘积之间的加法。在卷积运算涉及偏置项时,卷积运算还包括偏置项的加法运算。下文通过具体实施例描述sram模块100实现卷积运算的过程。
[0037]
在sram模块100处于卷积运算模式时,sram模块100接收输入矩阵、权重矩阵和偏置项。控制器160在sram阵列110中选择用于存储权重矩阵的第一部分112和用于存储偏置项bias的第二部分113。读写电路140将权重矩阵写入sram阵列110的第一部分112,将偏置项bias写入sram阵列110的第二部分113。例如,卷积运算的权重矩阵为a行b列的矩阵,包括a*b个权重数据,sram阵列110的第一部分112包括sram阵列112中的a*b行,a*b行中的每行用于存储所述权重矩阵中的一个权重数据。每个权重数据占据的sram单元111的数量决定于权重矩阵的精度,权重矩阵的精度是指权重数据的位数。sram阵列110的第二部分113包括sram阵列110中的一行。读写电路140将权重矩阵中的每个权重数据写入sram阵列100的第一部分112中与该权重数据对应一行,将偏置项bias写入sram阵列100的第一部分113的一行。
[0038]
例如,如图6所示,2x2的权重矩阵中的权重数据w
11
、w
12
、w
21
和w
22
分别写入sram阵列110的第一行到第四行,偏置项bias写入sram阵列110的第五行。根据权重数据w
11
、w
12
、w
21
和w
22
以及偏置项bias的位数,确定权重数据w
11
、w
12
、w
21
和w
22
以及偏置项bias使用的sram单元111的数量。例如权重数据w
11
、w
12
、w
21
和w
22
以及偏置项bias是i位,则权重数据w
11
、w
12
、w
21
和w
22
以及偏置项bias分别使用i个sram单元111存储。例如,w
11
、w
12
、w
21
、w
22
和bias分别为3、5、7、9、4,读写电路140将0011、0101、0111、1001、0100分别写入第一行的4个sram单元111、第二行的4个sram单元111、第三行的4个sram单元111、第四行的4个sram单元111和第五行的4个sram单元111。
[0039]
在sram模块100处于卷积运算模式时,卷积运算输入电路150基于卷积运算时钟clk将输入矩阵的数据和偏置项的激活数据ba提供到对应输入线input。输入矩阵的精度为i位,在卷积运算时钟clk的i个周期,以从最高位到最低位的顺序,输入数据逐位输入sram阵列110的第一部分112中的对应行的输入线。输入数据的位的值为1,卷积运算输入电路150在输入线input输入高电平,输入数据的位的值为0,卷积运算输入电路150在输入线input输入低电平。同时,在卷积运算时钟clk的i个周期,偏置项bias的激活数据ba,以从最高位到最低位的顺序,逐位输入sram阵列110的第二部分113中的对应行的输入线input,偏置项的激活数据ba的最低位为1,其他位为0。在卷积运算时钟clk的每个周期,sram阵列110的第一部分112实现输入数据的1位和权重数据的乘法。
[0040]
如图6所示,输入数据a
11
、a
12
、a
21
和a
22
分别提供到输入线input1、输入线input2、输入线input3和输入线input4。输入数据和对应的权重数据的乘法运算通过异或门xor实现。在卷积运算时钟clk的每个周期cycle,卷积运算输入电路150将输入数据的1位提供到对应的输入线。输入数据的最高位为1sb,最低位为isb,在卷积运算时钟clk的i个周期,以从最高位1sb到最低位isb的顺序,将i位的输入数据提供到对应的输入线。
[0041]
以2x2的权重矩阵和输入矩阵为例,如图6所示,在卷积运算时钟clk的第1个周期,实现输入数据的最高位1sb和对应权重数据的乘法,a
11
的最高位1sb和w
11
的乘积p11,a
12
的最高位1sb和w
12
的乘积p21,a
21
的最高位1sb和w
21
的乘积p31,a
22
的最高位1sb和w
22
的乘积p41分别通过输出线组output1至output4输出到加法器170,加法器170对乘积p11、p21、p31
和p41进行加法获得部分和sum1,并进行移位(向高位移1位)。在卷积运算时钟clk的第2个周期,实现输入数据的次高位2sb和权重数据的乘法,a
11
的次高位2sb和w
11
的乘积p12,a
12
的次高位2sb和w
12
的乘积p22,a
21
的次高位2sb和w
21
的乘积p32,a
22
的次高位2sb和w
22
的乘积p42分别通过输出线组output1至output4输出到加法器170,加法器170对乘积p12、p22、p32、p42以及部分和sum1进行加法获得部分和sum2,并进行移位。在卷积运算时钟clk的第i个周期,实现输入数据的最低位isb和权重数据的乘法,a
11
的最低位isb和w
11
的乘积p1i,a
12
的最低位isb和w
12
的乘积p2i,a
21
的最低位isb和w
21
的乘积p3i,a
22
的最低位isb和w
22
的乘积p4i分别通过输出线组output1至output4输出到加法器170,加法器170对乘积p1i、p2i、p3i、p4i以及部分和sum(i-1)进行加法获得输入矩阵和权重矩阵的卷积。在卷积运算时钟clk的第i个周期,加法器170不再对加法运算结果进行移位操作。即,仅在卷积运算时钟clk的第1个周期到第i-1个周期,触发加法器170的移位操作。在卷积运算时钟clk的i个周期,通过sram阵列110和加法器170实现了输入矩阵和权重矩阵的卷积运算。
[0042]
在卷积运算涉及偏置项时,卷积运算输入电路150还基于卷积运算时钟clk将偏置项的激活数据ba提供到偏置项所存储的sram阵列110的第二部分113对应的输入线input。偏置项的激活数据ba的最低位为1,其他位为0,即在卷积运算时钟clk的第i个周期,将1提供到输入线input,在其他周期,将0提供到输入线input。也就是,偏置项bias在卷积运算时钟clk的第i个周期提供到加法器170,加法器170再将输入数据和权重数据的乘积加上该偏置项bias。
[0043]
图5为本发明的实施例提供的控制器的结构框图。如图5所示,控制器160包括:精度译码器161、使能电路162、时钟发生器163、精度计数器164和偏置项激活数据产生电路165。使能电路162接收使能信号。当使能信号为第一值时,使能电路162使得sram模块100进入卷积运算模式,时钟发生器163产生卷积运算时钟clk。精度译码器161接收精度信号,对精度信号进行译码,确定输入矩阵的精度。输入矩阵的精度是指输入矩阵中的输入数据的位数。例如,输入数据a
11
、a
12
、a
21
和a
22
分别为3、5、7、9,则输入矩阵的精度为4,输入数据a
11
、a
12
、a
21
和a
22
转为二进制数需要4位。精度计数器164根据输入矩阵的精度i控制将i个周期的卷积运算时钟clk提供到卷积输入电路150。例如,精度计数器164从0开始计数,卷积运算时钟clk的每个周期计数值加1,当计数值到达i,卷积运算时钟clk的i个周期提供到了卷积输入电路150,之后卷积运算时钟clk不再提供到卷积输入电路150。偏置项激活数据产生电路165用于产生偏置项激活信号ba。偏置项激活数据产生电路165接收偏置项信号。当卷积运算不包括偏置项时,偏置项信号为非有效,偏置项激活数据产生电路165不产生偏置项激活数据ba。当卷积运算包括偏置项时,偏置项信号为有效,偏置项激活数据产生电路165根据输入矩阵的精度确定偏置项激活数据的位数,将偏置项激活数据的最低位设置为1,其他位设置为0。在一些实施例中,偏置项激活数据产生电路165在卷积运算时钟clk的每个周期产生1位的信号,精度计数器164在卷积运算时钟clk的第i个周期产生触发信号。在没有接收到该触发信号时,偏置项激活数据产生电路165产生的该1位的信号为0,在接收到该触发信号时,偏置项激活数据产生电路165产生的该1位的信号为1,从而产生了i位的偏置项激活数据ba。
[0044]
本发明实施例的一个方面,计算装置的sram模块可以根据待处理运算的类型设置为卷积运算模式和高速缓冲存储器模式。在高速缓冲存储器模式,sram模块作为处理器和
内存之间的高速缓冲存储器,对于并行运算较少、乘积累加运算较少的运算具有较高的效率。在卷积运算模式,sram模块用于执行乘积累加运算,能够提高神经网络算法的效率。因此,计算装置能够适用更多应用场景。在本发明实施例的另一个方面,计算装置的sram模块执行卷积运算时,权重矩阵和偏置项都存储在sram阵列中,输入数据和权重数据的乘积与偏置项的加法由sram模块的加法器执行,相比于由处理器的加法器执行偏置项的加法,节省了从内存读取偏置项的步骤,提高了计算效率。
[0045]
以上所述仅为本发明的实施例而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。