1.本发明应用于深度学习和社交机器人领域,具体是一种应用于社交机器人的微表情识别方法。
背景技术:
2.人类的表情可以分为宏表情和微表情两种。相比宏表情,微表情持续时间更短、面部肌肉运动幅度更小,是人类不经意的情感透露,往往更能表现人内心的真实情感。
3.而社交机器人作为一种可以以娱乐和类人的方式与人们进行互动的机器人,需要实时地捕捉用户的微表情状态,从而采取不同的相应手段。因此,业界需要在社交机器人的应用中使用一种具有较高准确性的微表情识别方法。
技术实现要素:
4.本发明所要解决的技术问题是针对现有技术的不足,提供一种应用于社交机器人的微表情识别方法。
5.为解决上述技术问题,本发明的一种应用于社交机器人的微表情识别方法,其包括如下具体步骤:
6.s1、社交机器人利用摄像头获取视觉输入信息,并输入社交机器中央处理单元;
7.s2、社交机器人中央处理单元对输入的视觉输入信息中的每帧图片进行人脸定位操作;
8.s3、社交机器人中央处理单元对提取的人脸图像和该人的中性脸提取光流信息;
9.s4、社交机器人中央处理单元将提取信息输入带有深度特征增强的分块卷积网络中输出获取该帧人脸图片的微表情状态;
10.s5、社交机器人将获取的微表情状态传输给交互层,交互层根据不同的微表情状态来进行对应响应。
11.本发明采用以上技术方案,具有以下有益效果:
12.1.本发明设计一个全新的分块卷积网络,对输入的光流图片分块进行特征提取,符合微表情运动幅度小的特点,可以更好地提取块特征,从而提高微表情的识别准确率。
13.2.本发明使用一个改进的isda_w损失函数,该损失函数在深度特征上进行数据增强,从而解决微表情数据样本量不足的缺点,从而提高识别准确率。
附图说明
14.下面结合附图与具体实施方式对本发明做进一步详细的说明:
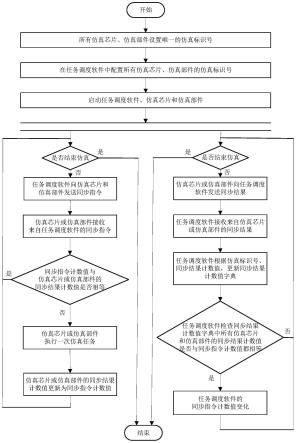
15.图1为本发明的整体流程图;
16.图2为本发明中社交机器人的功能模块和数据交互图;
17.图3为本发明中viola-jones算法haar特征的四种矩形特征;
18.图4为本发明中光流信息提取的示意图;
19.图5为本发明中设计出的带有深度特征增强的分块卷积网络的总体框架图;
20.图6为本发明分块卷积网络中的分块模块结构图。
具体实施方式
21.为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述。
22.步骤一:社交机器人使用3d深度摄像头从环境和用户中获取视觉输入,并返回给社交机器人的中央处理单元。
23.步骤二:社交机器人的中央处理单元使用drmf方法对于输入的每帧图片进行人脸定位,具体步骤包括:
24.(1)对输入图片进行去噪处理,去除冗余信息;
25.(2)使用viola-jones算法来识别图片中人脸区域,如果存在人脸区域,用矩形框圈出;若不存在人脸区域,则结束流程。
26.(3)截取矩形框,形成含有人脸区域的图像数据。
27.步骤三:中央处理单元对提取的人脸图像和该人的中性脸提取四种光流信息,具体步骤包括:
28.(1)处理层使用tv_l1方法提取横向光流信息u,纵向光流信息v和光学应变信息os;
29.(2)处理层再使用flownet网络来提取从深度模型中学习到的光流信息vis;
30.(3)最终提取到了一个含有四张光流图片的输入组{u,v,os,vis},
31.并将四张光流图片缩放成同样尺寸大小。
32.步骤四:社交机器人的中央处理单元将输入组送入我们设计的带有深度特征增强的分块卷积网络中得到该帧人脸图片的微表情状态,具体步骤包括:
33.(1)将四张光流图片进行分块,每块依次使用三个卷积层和一个最大池化层进行特征提取;其中,第一个和第3个卷积层的卷积核大小为1
×
1,第二个的卷积核大小为3
×
3,所有卷积核的步长都设置为1,最大池化层的卷积核大小设置为3
×
3。
34.(2)将每张图片的每个小块提取到的特征进行拼接,并将拼接的特征进行展平。
35.(3)经过两层全连接层得到最终的概率,其中第一层全连接层后还跟着一个dropout层,并输出人脸微表情识别的结果;。
36.(4)最终使用我们改进的isda_w损失函数对该网络进行训练,从而达到数据增强的效果。
37.步骤五:社交机器人将得到的微表情状态传输给交互层,交互层根据不同的微表情状态来进行相应的响应。
38.进一步的,基于步骤二,使用viola-jones算法来识别图片中人脸区域的具体步骤如下:首先利用haar特征来描述人脸特征,基于haar特征,算法使用了四种矩形特征,见附图3,haar特征分别对白色区域和黑色区域的像素求和,然后求这两种和的差;然后建立积分图像,对于积分图像中的任何一点,该点的积分图像值等于位于该点左上角所有像素之和;紧接着对积分图像的特征利用adaboost算法依次训练弱分类器和强分类器;最后使用级联分类器来进行人脸检测,把若干个adaboost分类器级联起来,一开始使用少量特征将
绝大部分的非人脸区域剔除掉,后面再利用更复杂的特征将更复杂的非人脸区域剔除掉。若没有检测到人脸区域,则结束流程;反之则用一个矩形框将具体的人脸区域框柱。
39.进一步的,基于步骤三,光流信息u,v和os的计算是基于亮度恒定性方程的:
[0040][0041][0042]
其中i(x,y,t)代表时间t在点(x,y)的图像强度函数,是空间变化梯度,而it表示时间变化梯度。(dx,dy)和dt分别是点和时间的位移矢量。p和q分别代表水平运动矢量和垂直运动矢量,所以u,v可以通过下面公式得到:
[0043][0044][0045]
而光学应变信息os则可以通过一个矩阵来表征:
[0046][0047]
其中,主对角线项(∈xx,∈yy)是正常的对角应变分量,(∈xx,∈yy)是非对角线的剪切应变分量。最终,光学应变os的大小可以计算如下式:
[0048][0049]
光流信息vis则是通过flownet训练得到的,光流信息提取的示例图见附图4。
[0050]
进一步的,基于步骤五,我们设计的基于深度特征增强的分块卷积网络来用于进行微表情分类任务,网络的具体框架图见附图5。首先四种光流信息分别进入一个分块模块去提取每个小块的块特征,分块模块的结构图见附图6。在分块模块中,每个图像被划分为x
×
y个小块,其中x=w/s, y=h/s,s是每个块的边缘长度,h和w是图片的高和宽。然后,每个图像特征可以表示为:
[0051][0052]
其中代表光流图片ik的第i行第j列的小块。随后,每个小块都经过三个卷积层和最大池化层得到每一个小块的块特征其中第一个和第三个卷积层的卷积核大小为1
×
1,第二个的卷积核大小为3
×
3,将每张图片的块特征拼接得到fk:
[0053]
[0054]
接下来将四张光流图片的信息拼接到一起:
[0055]
f=concat(f1,f2,f3,f4)
[0056]
然后将拼接的特征进行展平,最后再经过两个全连接层得到最终的分类概率,其中第一个全连接层后还跟着一个dropout层,起到加快模型训练速度的作用。
[0057]
此外,我们网络使用了改进后的名为isda_w损失函数,该损失函数的使用可以在深度特征层进行数据增强,并可以进一步缓解微表情数据集标签分布不均衡的问题。isda_w损失函数的具体公式如下:
[0058][0059][0060]
其中,n是训练集样本的数量,λ是控制语义数据增强强度的正系数,w=[w1,
…
,we]
t
∈r
l
×e和b=[b1,
…
,be]
t
∈re是最后一层全连接层的参数, l代表最后一层全连接层的神经元个数,e代表微表情分类的类别数量。然后v
jyi
=w
j-w
yi
,∑yi是从类yi中的样本中估计得到的类条件协方差矩阵。nj代表类j的样本的数量,μ=[μ1,
…
,μe]是一个损失权重向量。具体地,μj代表类j的损失权重值。u是通过网格搜索来使得模型识别准确率最高得来的。
[0061]
以上所述为本发明的实施例,对于本领域的普通技术人员而言,根据本发明的教导,在不脱离本发明的原理和精神的情况下凡依本发明申请专利范围所做的均等变化、修改、替换和变型,皆应属本发明的涵盖范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。