1.本发明属于计算机应用技术领域,涉及一种融合albert与图注意力机制的问答推理方法。
背景技术:
2.对自然语言进行推理和推理的能力是人工智能的重要方面。自动问答任务提供了一种可量化的客观方法来测试人工智能系统的推理能力,正逐渐成为一种人与机器进行自然交互的新趋势,能够更准确地理解以自然语言描述的用户问题,并依据用户的真实意图返回给用户更精准的答案,它将成为下一代搜索引擎的新形态。
3.问答一直是自然语言处理领域的热门话题,qa为评估nlp系统在语言理解和推理方面的能力提供了一种量化的方法,深度学习模型的发展使得机器阅读理解领域和问答领域取得了长足的进步,甚至在包括squad在内的单段问答基准上超过了人类,但是以前的大多数工作都集中在从单一段落中寻找证据和答案,很少测试底层模型的深层推理能力,若要跨越机器和人类之间的问答鸿沟,面临着提升模型推理能力的挑战,单段问答模型倾向于在与问题匹配的句子中寻找答案,不涉及复杂的推理并且当单个文档不足以找到正确答案时,仍然缺乏对多个文档进行推理的能力。因此,多跳问答成为下一个需要攻克的前沿。
4.图神经网络已经成为深度学习领域最炽手可热的方向之一。作为一种代表性的图卷积网络,图注意力机制引入了注意力算法来实现更好的结点聚合,在图注意力机制中,模型会通过线性变换来获得表达能力更强的特征,以满足深度学习中的各项下游任务。原始的图注意力机制(gat)通过由a∈r
2f
1参数化的单层前馈网络来计算系数。而点积注意力机制是通过图中各个节点表示学习后所获取的,采用了与注意力机制相同的推理公式。通过学习邻居的权重,图注意力机制(gat)可以实现对邻居的加权聚合。因此,图注意力机制(gat)不仅能处理带噪声的邻接点,注意力机制也赋予了模型可解释性。
技术实现要素:
5.本发明的目的旨在针对现有问答模型的不足,提供一种能有效应用于多条问答的问答推理模方法。
6.为了实现上述目的,本发明提供的技术是基于图注意力机制的深度学习问答推理方法,包括以下步骤:
7.步骤1、对数据进行表征抽取:
8.bert模型凭借masked lm、双向transformer encoder和句子级负采样获得了一个深度双向编码的描述了字符级、词级、句子级甚至句间关系的特征的预训练模型,而albert模型的参数相比bert而言小了很多,相反地,准确率比bert高,所以使用albert模型进行表征抽取。部分输入的是问题q和相关的段落p,输出的是对应问题q和段落的词向量p,以及从中提取出的语义向量(semantic)。首先,将问题[q1,q2...qn]和段落[p1,p2...pm]输入模型。然后,albert基于词元(token)、类别(type)和位置(position)的嵌入为每个词元生成表
示,输出的表示q=[q1,q2...qn]∈rm×d,p=[p1,p2...pm]∈rn×d,同时语义向量(semantic)也随表示输出。在附图2中演示了模型的架构。
[0009]
步骤2、提取输入句子的实体:
[0010]
通过albert获取到表征之后,本步骤使用斯坦福科伦普工具包从q和p中识别命名实体,提取的实体的数量表示为n。实体嵌入e
t-1
=[e
t-1
,1,...,e
t-1
,n]。e
t-1
的大小为2d
×
n,其中n是实体的数量,d是维度,此模块为t2g。
[0011]
步骤3、进行实体计算推理过程:
[0012]
在经过步骤1,步骤2后,模型用图神经网络将结点信息传播到每一个邻结点。如附图3所示为本方法所采用的一种动态的图注意力机制来实现推理过程。在推理过程中,图中每个结点都与邻结点进行信息的交互,与实体信息关联越多的结点接受到的信息越多。本发明通过在实体上关联问题来查询相关的节点,使用查询问题嵌入和实体嵌入之间的联系,把问题的输出表示和实体表示相结合,再乘以抽取出的语义向量,其目的是表示第t个推理步骤中的开始实体e
(t-1)
[0013]q′
(t-1)
=meanpooling(q
(t-1)
)#(1)
[0014]e′
(t-1)
=[q
′
(t-1)ei(t-1)s…q′
(t-1)en(t-1)
s]#(2)
[0015]
其中q
(t-1)
是问题表示,e
i(t-1)
是第i个实体表示。通过将问题表示q
(t-1)
和初实体表示e
i(t-1)
以及语义向量s嵌入相乘,将期望的开始实体突显,而其他实体弱化。
[0016]
步骤4、在获得实体之后,下一步是在动态图中传播信息:
[0017]
本发明受图注意力机制(gat)的启发通过以下公式计算实体间的关联程度β
i,j
:
[0018]hi(t)
=u
tei
′
(t-1)
b
t
#(3)
[0019]
α
i,j(t)
=(w
thit-1
)
t w
thjt-1
#(4)
[0020][0021]ut
、w
t
是线性参数。这里,β的第i行表示将被分配给实体i的邻居的信息的比例。
[0022]
本模型中的信息流不同于大多数以前的图注意力机制(gat)。在点乘图注意力机制中,每个结点通过与邻结点相关联,求邻结点信息的加权和,与邻结点相关联的信息会更新到结点。
[0023][0024]
接着就能得到信息更新后的实体e
(t)
=(e
1(t)
…en(t)
)
[0025]
步骤5、进行结果预测:
[0026]
5-1在经过上面的步骤之后,利用实体抽取和图注意力机制,实现了实体的推理。然而,实体过于复杂不利于答案的追溯。为了解决这个问题,本发明开发了一个graph2doc模块来保持信息从实体流回到上下文中的向量。因此,与答案有关的文本可以在上下文中定位到。
[0027]
5-2本方法使用的预测层结构框架有四个输出维度,包括1.支持句,2.答案的开始位置,3.答案的结束位置,4.答案的类型。本研究使用连续的结构来保证输出结果的相关联性,其中四个lstm fi是逐层相关联的。最后融合块的上下文表示被发送到第一lstm f0。每个fi输出logit o∈rm
×
d2,并计算这些logit上的交叉熵损失。
[0028]
本发明的另一个目的是提供一种新的用以解决大规模的多跳问答的推理装置,包括:
[0029]
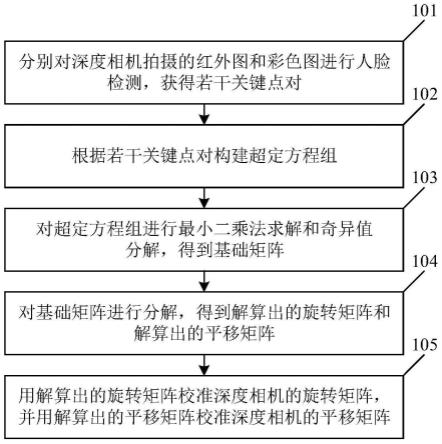
albert表征抽取模块,用于对数据集进行表征抽取,albert基于词元(token)、类别(type)和位置(position)的嵌入为每个词元生成表示,输出的表示q=[q1,q2...qn]∈rm×d,p=[p1,p2...pm]∈rn×d,同时语义向量(semantic)也随表示输出。
[0030]
2t2g模块,使用斯坦福科伦普工具包从q和p中识别命名实体,提取的实体的数量表示为n。实体嵌入e
t-1
=[e
t-1
,1,...,e
t-1
,n]。e
t-1
的大小为2d
×
n,其中n是实体的数量,d是维度。
[0031]
点乘注意力机制的图注意力机制(gat)模块,采用的是一种动态的图注意力机制来实现推理过程的方法。通过在实体上关联问题来查询相关的节点,使用查询问题嵌入和实体嵌入之间的联系,把问题的输出表示和实体表示相结合,再乘以抽取出的语义向量,其目的是表示第t个推理步骤中的开始实体e
(t-1)
。
[0032]
graph2doc模块,用于结果预测,保持信息从实体流回到上下文中的向量。
[0033]
本发明的又一个目的是一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述的方法。
[0034]
本发明的再一个目的是一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述的方法。
[0035]
本发明具有以下优势:本发明得益于图注意力机制的结构,能在对话式问答和推荐系统的应用上大有可为,图注意力机制(gat)中的结点循环可通过加入逻辑性变量来提高可靠性。此外,通过优化系统之间的交互,结合微调和基于特征的表征抽取将提高albert的容量。可以推广到其他智能对话任务和顺序推荐。
附图说明
[0036]
图1为模型的总体架构图;
[0037]
图2为用于表征提取的albert示意图;
[0038]
图3为动态图注意力机制推理过程图。
具体实施方式
[0039]
下面结合具体实施例对本发明做进一步的分析。
[0040]
本发明的基于图注意力机制的深度学习问答推理方法,包括以下步骤:
[0041]
步骤1、对数据进行表征抽取:
[0042]
先使用albert模型进行表征抽取,bert模型凭借masked lm、双向transformer encoder和句子级负采样获得了一个深度双向编码的描述了字符级、词级、句子级甚至句间关系的特征的预训练模型,而albert模型的参数相比bert而言小了很多,相反地,准确率比bert高,所以使用albert模型进行表征抽取。部分输入的是问题q和相关的段落p,输出的是对应问题q和段落的词向量p,以及从中提取出的语义向量semantic。首先,将问题[q1,q2...qn]和段落[p1,p2...pm]输入模型。然后,albert基于词元(token)、类别(type)和位置(position)的嵌入为每个词元生成表示,输出的表示q=[q1,q2...qn]∈rm×d,p=[p1,p2...pm]∈rn×d,同时语义向量(semantic)也随表示输出。在附图2中演示了模型的架构。
[0043]
步骤2、提取输入句子的实体:
[0044]
通过albert获取到表征之后,本步骤使用斯坦福科伦普工具包从q和p中识别命名实体,提取的实体的数量表示为n。实体嵌入e
t-1
=[e
t-1
,1,...,e
t-1
,n]。e
t-1
的大小为2d
×
n,其中n是实体的数量,d是维度,此模块为t2g。
[0045]
步骤3、进行实体计算推理过程:
[0046]
在经过步骤1,步骤2后,模型用图神经网络将结点信息传播到每一个邻结点。如附图3所示为本方法所采用的一种动态的图注意力机制来实现推理过程。在推理过程中,图中每个结点都与邻结点进行信息的交互,与实体信息关联越多的结点接受到的信息越多。本发明通过在实体上关联问题来查询相关的节点,使用查询问题嵌入和实体嵌入之间的联系,把问题的输出表示和实体表示相结合,再乘以抽取出的语义向量,其目的是表示第t个推理步骤中的开始实体e
(t-1)
[0047]q′
(t-1)
=meanpooling(q
(t-1)
)#(1)
[0048]e′
(t-1)
=[q
′
(t-1)ei(t-1)s…q′
(t-1)en(t-1)
s]#(2)
[0049]
其中q
(t-1)
是问题表示,e
i(t-1)
是第i个实体表示。通过将问题表示q
(t-1)
和初实体表示e
i(t-1)
以及语义向量s嵌入相乘,将期望的开始实体突显,而其他实体弱化。
[0050]
步骤4、在获得实体之后,下一步是在动态图中传播信息:
[0051]
本发明受图注意力机制(gat)的启发通过以下公式计算实体间的关联程度β
i,j
:
[0052]hi(t)
=u
tei
′
(t-1)
b
t
#(3)
[0053]ai,j(t)
=(w
thit-1
)
t w
thjt-1
#(4)
[0054][0055]ut
、w
t
是线性参数。这里,β的第i行表示将被分配给实体i的邻居的信息的比例。
[0056]
本模型中的信息流不同于大多数以前的图注意力机制(gat)。在点乘图注意力机制中,每个结点通过与邻结点相关联,求邻结点信息的加权和,与邻结点相关联的信息会更新到结点。
[0057][0058]
接着就能得到信息更新后的实体e
(t)
=(e
1(t)
…en(t)
)
[0059]
步骤5、进行结果预测:
[0060]
5-1在经过上面的步骤之后,利用实体抽取和图注意力机制,实现了实体的推理。然而,实体过于复杂不利于答案的追溯。为了解决这个问题,本发明开发了一个graph2doc模块来保持信息从实体流回到上下文中的向量。因此,与答案有关的文本可以在上下文中定位到。
[0061]
5-2本方法使用的预测层结构框架有四个输出维度,包括1.支持句,2.答案的开始位置,3.答案的结束位置,4.答案的类型。本研究使用连续的结构来保证输出结果的相关联性,其中四个lstm fi是逐层相关联的。最后融合块的上下文表示被发送到第一lstm f0。每个fi输出logit o∈rm
×
d2,并计算这些logit上的交叉熵损失。
[0062]
实验过程:
[0063]
本实验使用的hotpotqa数据集由11.3万个人工设计的问题组成,每个问题都可以
用两篇维基百科文章中的段落来回答。在构建数据集的过程中,研究人员从维基百科中选择到问题的二元语法tf-idf距离最短的前8个文档作为干扰项,形成总共10个文档的上下文段落。hotpotqa中有两种不同的设置,其中在干扰项设置中,每个例子包含从维基百科检索到的2个黄金段落和8个干扰项段落。在完整的维基设置中,模型被要求从整个维基百科中检索黄金段落。在发明中,所有的实验都是在干扰项的设置下进行的。
[0064][0065][0066]
表1:模型在hotpotqa测试集fullwiki设置下的实验结果。
[0067]
在表1中,与给出了不同模型在hotpotqa测试集上的性能比较。通过对比可知本agtf模型取得了先进的结果。
[0068][0069]
表2:hotpotqa测试集在干扰器(distractor)设置下的实验结果。
[0070]
截至2020年12月,使用albert做上下文编码以及使用图注意力机制(gat)做推理的agtf取得了优异的结果。
[0071][0072][0073]
表3:hotpotqa测试集在fullwiki设置下的实验结果。
[0074]
截至2020年12月,使用albert做上下文编码以及使用图注意力机制(gat)做推理的agtf取得了优异的结果。
[0075]
表2和表3总结了hotpotqa的隐藏测试集上的结果。在干扰器(distractor)设置中,agtf在每个指标上的表现均优于其他模型,em/f1联合得分达到42.4/70.4。在fullwiki设置中,尽管使用了劣质的预测器,但agtf仍在联合em/f1上获得了最新的结果。当使用与(yang et al.,2018)中相同的预测器时,本方法明显优于其他方法,证明了本发明的多跳推理方法的有效性。本模型在所有指标上的表现都超过所有基线。性能的飞跃主要源于模型框架相对于传统方法而言较大的优势。
[0076]
为了验证预训练语言模型的效果,将agtf与使用相同预训练语言模型的现有技术进行了比较。表4中的结果表明,agtf胜过dfgn和sae,良好的模型设计使得性能得到了提高。
[0077]
[0078]
表4:hotpotqa测试集上使用不同的预训练语言模型得到的结果。
[0079]
因此可以得出,本发明具有以下优势:提出的基于图点乘注意力算法的推理模型agtf,针对问答中的多跳问题,提出了融合albert与图注意力机制(gat)的混合模型,该模型包含了编解码层和图神经网络预测层,经过实验结果表明,agtf模型有效的提高了多跳问答的推理能力。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。