1.本发明涉及一种测算碳排规模的统计学建模方法。
背景技术:
2.现就碳排放规模进行分析研究的方法大多数是定性方法,例如排放因子法,stirpat模型等,根据简单的模型设置,定性地得出影响碳排放规模的因素。但由于此类方法精确度低,且无法满足碳排放数据带有偏斜的情况,因此无法应用于实际领域,难以推广。
3.现有技术中stirpat模型根据人口城镇化水平、产业增值比重、第三产业增值比重、人均gdp,绿化覆盖面积等建立简单模型,计算得出某个地区的碳排放总量。此种方法难以适应多个区域的碳排放总量的测算,效率低,精度差。
4.为解决上述问题,提供一种测算碳排放规模的统计学建模方法。
技术实现要素:
5.本发明的目的在于提供提供一种测算碳排放规模的统计学建模方法,以解决上述背景技术中提出的问题。
6.为实现上述目的,本发明提供如下技术方案:一种测算碳排放规模的统计学建模方法,使用混合专家回归模型对碳排放数据进行预测。其中,所述混合专家模型的建立依赖于碳排放数据服从偏正态分布,具体表达式为:
[0007][0008]
设z∈{1,2,
…
,m}是类别的随机变量,混合专家模型moe(mixtureof expert)如下:
[0009][0010]
式中,wj是混合比例,v是解释变量,α是混合比例模型的参数。步骤7包括以下步骤:步骤7-1,根据碳排放数据的响应变量,即碳排放规模进行单位归一化,得到一致的数据;步骤7-2,利用q-q图、偏度及峰度检验,对碳排放规模数据进行偏正态检验,得到符合模型的数据;步骤7-3,针对研究区域,划分数据集,将全数据划分为多个子数据集,每个数据集对应一个偏正态回归模型,综合以上子模型,得到混合专家回归模型;步骤7-4,利用em算法就建立的模型进行参数估计,得到碳排放数据的统计学模型;步骤7-5,利用上述步骤建立的模型进行预测。式中,若对n=4个区域进行研究,则建立如下偏正态分布下混合专家模
型:
[0011][0012]
与现有技术相比,本发明的有益效果是:本发明结构设置合理,功能性强,具有以下优点:
[0013]
1.本发明中通过设置混合比例,在多区域测算碳排放规模上考虑了异质数据的差异性,相较单一区域进行测算,实用性更强;
[0014]
2.本发明通过考虑碳排放数据带有偏斜特征,将混合专家模型推广至偏正态分布下,相较正态情况进行测算,精度更高。
附图说明
[0015]
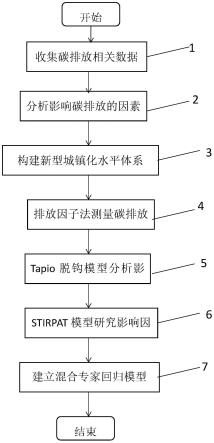
图1是本发明实施中碳排放模型的统计学建模方法流程图;
[0016]
图2是本发明实施中混合数目为2时的模型示意图
具体实施方式
[0017]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结果实施例及附图对发明的测算碳排放规模的统计学建模方法作具体阐述。
[0018]
《实施例》
[0019]
图1是本发明实施例中的测算碳排放规模的统计学建模方法流程图,图2是本发明实施例中混合专家模型在混合数据取2时的模型示意图。
[0020]
步骤1,收集多个地区的碳排放数据。
[0021]
本实施例中通过采集,收集到西南地区四省市的碳排放数据,分别为云南、四川、贵州、重庆。将这四个地区的碳排放规模数据作为样本,输入量从2005年到2018年。如选取的样本量过少,则训练得到的统计模型不具有统计意义。
[0022]
步骤2,分析影响碳排放规模的因素,找寻关于新型城镇化相关数据。本实施例通过分析影响碳排放规模的因素,相关变量包括人口城镇化水平、人均gdp、城镇建设用地面积、第二产业增加值、建成区绿化覆盖率、第三产业增加值、医疗卫生机构数,以上体现为新型城镇化水平。
[0023]
步骤3,构建新型城镇化评价体系以界定城镇化水平。步骤3包含以下步骤:
[0024]
步骤3-1,构建基于人口、经济、社会环境差异的新型城镇化指标体系。
[0025]
步骤3-2,对数据进行归一化处理。对于收集的衡量新型城镇化的相关指标,各个指标的性质、量纲、数量级不同,分析原始数据时,数值较高的指标在综合分析中的作用会被放大,数值较小的指标的作用会被削弱。因此,需要对原始数据进行归一化处理。公式如下:
[0026][0027]
步骤3-3,综合评价函数的确立。对于评价新型城镇化的相关指标,采用赋权方法
对各个指标赋予权重,构建综合评价函数对地区新型城镇化总体水平进行衡量。构建的新型城镇化综合评价函数如下:
[0028][0029]
其中,l为新型城镇化综合水平;x
ij-归一化处理后的数值;w
i-第i项权重。采用熵值法确立各个指标的具体权重。过程如下:
[0030][0031][0032][0033]
其中,0≤hi≤1,k为样本个数,f
ij
为第i项指标下第j个样本占该指标的比重。
[0034]
步骤4,使用排放因子法估算区域的碳排放量。排放因子法更加适用于测算区域的碳排放量,具体的估算公式如下:
[0035][0036]
其中,i表示第i种化石能源种类,n为化石能源种类总数,此处n=8,分别为八种主要化石能源。total_co
2-碳排放量,c
i-碳排放量,e
i-化石能源消费量。ncv
i-转换因子,平均低位发热量;cef
i-含碳量,化石能源单位热值含碳量;cof
i-碳氧化率;表示碳原子质量和二氧化碳分子质量间的转化系数。以上四项的乘积组成二氧化碳排放系数ccoi。
[0037]
步骤5,利用tapio脱钩模型分析各个区域的碳排放数据,找出个体差异与共性。使用tapio脱钩模型描述新型城镇化与二氧化碳排放之间的关系。出于全面揭示省级新型城镇化碳排放关系,从碳排放解耦状态的角度,构建碳排放总量、人均碳排放、碳排放强度等三个解耦指标,分别计算三种指标与新型城镇化水平的弹性值。模型如下:
[0038]
t1=δtc(%)/δntur(%)
[0039]
t2=δpc(%)/δntur(%)
[0040]
t3=δgc(%)/δntur(%)
[0041]
其中,δtc(%)-碳排放总量增长、δpc(%)-人均碳排放量增长、δgc(%)-碳强度增长;δntur(%)表示从基期到比较期,新型城镇化水平的增长幅度;t1、t1、t1分别为三种指标的脱钩弹性值。
[0042]
步骤6,采用stirpat模型研究影响碳排放规模的因素,用主成分分析法降低多重共线性,模型如下:
[0043]
e=a
×
pb×ac
×
td×ve
×
uf×cg
×
rh[0044]
式中e为中国西南地区某省的碳排放总量(亿吨);p为该省人口城镇化水平;t为第二产业增值比重;v为第三产业增值比重;a为该省人均gdp(万元);u为城镇建设用地面积(平方千公里);c为医疗卫生机构数(个/千人),r为建成区绿化覆盖率。b、c、d、e、f、g、h表示各个影响因素的指数,即当p、a、t、v、u、c、r每发生1%变化,将会引起该省总碳排放量b%,c%,d%,e%,f%,g%,h%的变化。
[0045]
步骤7,使用混合专家回归模型对碳排放数据进行预测。所述混合专家模型的建立依赖于碳排放数据服从偏正态分布,具体表达式为:
[0046][0047]
设z∈{1,2,
…
,m}是类别的随机变量,混合专家模型moe(mixtureof expert)如下:
[0048][0049]
式中,wj是混合比例,v是解释变量,α是混合比例模型的参数。具体实施步骤为:
[0050]
步骤7-1,根据碳排放数据的响应变量,即碳排放规模进行单位归一化,得到一致的数据;
[0051]
步骤7-2,利用q-q图、偏度及峰度检验,对碳排放规模数据进行偏正态检验,得到符合模型的数据;
[0052]
步骤7-3,针对研究区域,划分数据集,将全数据划分为多个子数据集,每个数据集对应一个偏正态回归模型,综合以上子模型,得到混合专家回归模型;
[0053]
步骤7-4,利用em算法就建立的模型进行参数估计,得到碳排放数据的统计学模型;
[0054]
步骤7-5,利用上述步骤建立的模型进行预测。
[0055]
式中,若对n=4个区域进行研究,则建立如下偏正态分布下混合专家模型:
[0056][0057]
由上述步骤最终得到测算碳排放的方法相较现有方法考虑了数据来源异质的情况,也考虑了碳排放数据带有偏斜的情形,精度相对要高。尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以对模型进行模拟,简化或提升模型精度,适应实际情况,上述实施例中选取的地区、混合数目仅用于说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
