基于强化学习的5g配网分布式保护装置的优化布置方法
技术领域
1.本发明属于配网保护领域,具体的说是一种基于强化学习的5g配网分布式保护装置的优化布置方法。
背景技术:
2.配网具有电压等级多,网络结构复杂,设备类型多样,作业点多面广,安全环境相对较差等特点,安全风险因素相对较多,为了给各类用户提供电力能源,对配网的安全可靠运行提出更高的要求,因此需要布置保护装置来保护配网。然而配网数量多,分布广,同时受技术的影响,如何布置保护装置成为一个难题。目前大部分的配网保护装置的配置方案仍然沿用传统思路,无法保证在可靠性范围内布置最优的配网保护装置。
技术实现要素:
3.本发明是为了解决上述现有技术存在的不足之处,提出一种基于强化学习的5g配网分布式保护装置的优化布置方法。以期在满足可靠性的前提下找出最优的5g配网分布式保护系统保护装置的布置,从而确保配网能安全高效的运行。
4.本发明为达到上述发明目的,采用如下技术方案:
5.本发明一种基于强化学习的5g配网分布式保护装置的优化布置方法的特点在于,包括以下步骤:
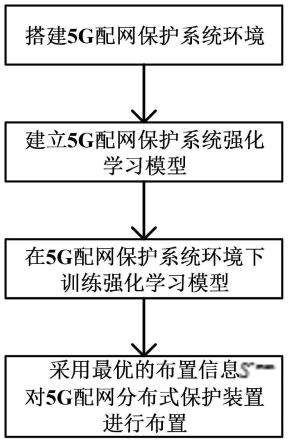
6.步骤1、搭建5g配网保护系统环境;
7.令l=[l1,l2,...,li,...,ln]表示5g配网的n个节点是否布置保护装置,若li=0,表示第i个节点未布置保护装置,若li=1,表示第i个节点布置保护装置,且每个节点最多只能布置一个保护装置,i=1,2,...,n;
[0008]
令d=[d1,d2,...,di,...,dn]表示5g配网的n个节点与5g基站的实际距离,di表示第i个节点与5g基站的实际距离,当li=0时,di=0;i=1,2,...,n;
[0009]
令s=[l,d]表示5g配网保护系统的保护装置的布置信息;
[0010]
初始化5g配网的n个节点均布置有保护装置,即{li=1,i=1,2,...,n};
[0011]
步骤2、建立5g配网保护系统的强化学习模型,其中,强化学习模型由策略体和执行体组成:
[0012]
所述策略体由两层神经元网络组成,所述策略体的输入层输入所述5g配网保护系统的保护装置的布置信息s,所述策略体的输出层输出所有动作a的概率π(a),其中,π(a)通过策略π(θ)和softmax函数得出,θ是神经元网络参数的集合;
[0013]
所述执行体用于执行动作从而改变5g配网保护系统的保护装置的布置信息,所述执行体中的奖励模块计算奖励;
[0014]
步骤3、在5g配网保护系统环境下训练强化学习模型;
[0015]
步骤3.1、定义回合数为m,并初始化m=1;
[0016]
步骤3.2、定义每回合训练的次数为t,并初始化t=1;
[0017]
定义第m回合第t次训练保护系统保护装置的布置信息为并初始化
[0018]
步骤3.3、所述策略体的输入层输入所述布置信息
[0019]
步骤3.4、所述策略体通过策略和softmax函数输出所有动作a的概率其中是第m回合第t次训练策略,是第m回合第t次训练神经网络参数的集合,是第m回合第t次训练所有动作a的概率;
[0020]
步骤3.5、在5g配网保护系统环境下,所述执行体根据策略体输出的所有动作a的概率选择动作所述执行体第m回合第t次训练下执行动作从而改变第i个节点的m个邻接点上的保护装置的数量,即改变5g配网保护系统的保护装置的布置信息并输出第m回合第t 1次训练时的布置信息
[0021]
仅当li=0时,所述执行体为第i个节点的m个邻接点分别增加一个保护装置;li 1,i=1,2,...,n;
[0022]
仅当li=1时,所述执行体为第i个节点的m个邻接点分别减少一个保护装置;l
i-1,n=1,2,...,n;
[0023]
步骤3.6、判断式(1)是否成立,若成立,则执行步骤3.7,否则,返回执行步骤3.4:
[0024][0025]
式(1)中,s是保护系统的可靠性,pi是第i个节点上的保护装置出现故障的概率,s
ex
是在5g配网正常运行时期望的可靠性;
[0026]
步骤3.7、所述执行体的奖励模块通过式(2)-式(5)计算第m回合第t次训练下的奖励
[0027][0028][0029][0030][0031]
式(2)-式(5)中,是第m回合第t次训练下保护装置与5g基站的距离的奖励,是第m回合第t次训练下保护装置数量的奖励,是第m回合第t次训练下保护系统可靠性的奖励;是第m回合第t次训练下保护装置数量的奖励;
[0032]
步骤3.8、策略体通过式(6)和式(7)更新第m回合第t次训练下的参数从而得到第m回合第t 1次训练下的参数
[0033][0034][0035]
式(6)和式(7)中,α是学习率,是参数的偏导,是在下的值函数,是在下的策略,是值函数的期望;
[0036]
步骤3.9、将t 1赋值给t后,判断t》c1是否成立,若成立,结束当前第m回合训练,得到当前第m回合下最优的布置信息并将存储在集合中后,执行步骤3.10,否则,返回执行步骤3.3顺序执行;其中,c1是每回合最大迭代次数;
[0037]
步骤3.10、将m 1赋值给m后,判断m》c2是否成立,若成立,则结束所有训练,从集合中得到最优的布置信息s
*max
;否则,返回执行步骤3.2顺序执行,其中,c2是最大迭代回合数;
[0038]
步骤4、采用最优的布置信息s
*max
对5g配网分布式保护装置进行布置。
[0039]
与现有技术相比,本发明的有益效果在于:
[0040]
1、本发明利用强化学习与环境不断交互不断学习的优势,并且考虑到配网数量多、分布广的特点,在5g配网保护系统环境下,多维的改变保护装置的数量和布置情况,通过强化学习的迭代学习,找到最优的保护装置的布置,从而实现了对配网的保护,确保了配网安全可靠运行;
[0041]
2、本发明利用5g通信技术为配网保护业务提供了低延时、高可靠的信息通道,从而解决传统配网保护选择性较弱,故障定位不够精确,切除故障用时较长,配网线路无法实现故障切除后的自愈的问题。
附图说明
[0042]
图1为本发明一种基于强化学习的5g配网分布式保护装置的优化布置方法的流程图;
[0043]
图2为本发明5g配网保护系统环境图;
[0044]
图3为本发明强化学习训练过程图。
具体实施方式
[0045]
在本实施例中,如图1所示,一种基于强化学习的5g配网分布式保护装置的优化布置方法,其特征在于,包括以下步骤:
[0046]
步骤1、如图2所示,搭建5g配网保护系统环境;
[0047]
令l=[l1,l2,...,li,...,ln]表示5g配网的n个节点是否布置保护装置,若li=0,表示第i个节点未布置保护装置,若li=1,表示第i个节点布置保护装置,且每个节点最多只能布置一个保护装置,i=1,2,...,n;
[0048]
令d=[d1,d2,...,di,...,dn]表示5g配网的n个节点与5g基站的实际距离,di表示
第i个节点与5g基站的实际距离,当li=0时,di=0;i=1,2,...,n;
[0049]
令s=[l,d]表示5g配网保护系统的保护装置的布置信息;
[0050]
初始化5g配网的n个节点均布置有保护装置,即{li=1,i=1,2,...,n};
[0051]
步骤2、建立5g配网保护系统的强化学习模型,其中,强化学习模型由策略体和执行体组成:
[0052]
策略体由两层神经元网络组成,策略体的输入层输入5g配网保护系统的保护装置的布置信息s,策略体的输出层输出所有动作a的概率π(a),其中,π(a)通过策略π(θ)和softmax函数得出,θ是神经元网络参数的集合;
[0053]
执行体用于执行动作从而改变5g配网保护系统的保护装置的布置信息,执行体中的奖励模块计算奖励;
[0054]
步骤3、如图3所示,在5g配网保护系统环境下训练强化学习模型;
[0055]
步骤3.1、定义回合数为m,并初始化m=1;
[0056]
步骤3.2、定义每回合训练的次数为t,并初始化t=1;
[0057]
定义第m回合第t次训练保护系统保护装置的布置信息为并初始化
[0058]
步骤3.3、策略体的输入层输入布置信息
[0059]
步骤3.4、策略体通过策略和softmax函数输出所有动作a的概率其中是第m回合第t次训练策略,是第m回合第t次训练神经网络参数的集合,是第m回合第t次训练所有动作a的概率;
[0060]
步骤3.5、在5g配网保护系统环境下,执行体根据策略体输出的所有动作a的概率选择动作执行体第m回合第t次训练下执行动作从而改变第i个节点的m个邻接点上的保护装置的数量,即改变5g配网保护系统的保护装置的布置信息并输出第m回合第t 1次训练时的布置信息
[0061]
仅当li=0时,执行体为第i个节点的m个邻接点分别增加一个保护装置;li 1,i=1,2,...,n;
[0062]
仅当li=1时,执行体为第i个节点的m个邻接点分别减少一个保护装置;l
i-1,n=1,2,...,n;
[0063]
简单的改变保护装置的数量,无法应对配网数量多、分布广的实际情况,考虑到复杂的配网的实际情况,每回合执行不同的动作,确保在满足配网可靠性的前提下提高保护效果;
[0064]
步骤3.6、判断式(1)是否成立,若成立,则执行步骤3.7,否则,返回执行步骤3.4:
[0065][0066]
式(1)中,s是保护系统的可靠性,pi是第i个节点上的保护装置出现故障的概率,s
ex
是在5g配网正常运行时期望的可靠性;
[0067]
步骤3.7、执行体的奖励模块通过式(2)-式(5)计算第m回合第t次训练下的奖励
[0068][0069][0070][0071][0072]
式(2)-式(5)中,是第m回合第t次训练下保护装置与5g基站的距离的奖励,是第m回合第t次训练下保护装置数量的奖励,是第m回合第t次训练下保护系统可靠性的奖励;是第m回合第t次训练下保护装置数量的奖励;保护装置与5g基站的距离会影响保护系统的可靠性;
[0073]
步骤3.8、策略体通过式(6)和式(7)更新第m回合第t次训练下的参数从而得到第m回合第t 1次训练下的参数
[0074][0075][0076]
式(6)和式(7)中,α是学习率,是参数的偏导,是在下的值函数,是在下的策略,是值函数的期望;
[0077]
步骤3.9、将t 1赋值给t后,判断t》c1是否成立,若成立,结束当前第m回合训练,得到当前第m回合下最优的布置信息并将存储在集合中后,执行步骤3.10,否则,返回执行步骤3.3顺序执行;其中,c1是每回合最大迭代次数;
[0078]
步骤3.10、将m 1赋值给m后,判断m》c2是否成立,若成立,则结束所有训练,从集合中得到最优的布置信息s
*max
;否则,返回执行步骤3.2顺序执行,其中,c2是最大迭代回合数;
[0079]
步骤4、采用最优的布置信息s
*max
对5g配网分布式保护装置进行布置。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。