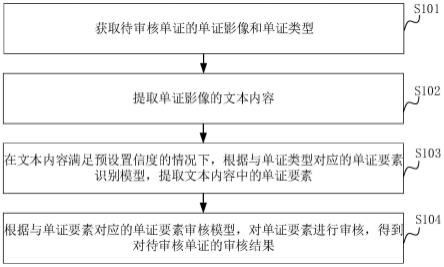
using gradient boosting decision tree[c]//2020 ieee 91st vehicular technology conference(vtc2020-spring).ieee,2020:1-5.[4]qu jingyi,cao lei,chen min,et al.cliquenet flight delay prediction model based on cluster random connection[j].journal of computer applications,2020,40(08):2420-2427.[屈景怡,曹磊,陈敏,等.基于团簇随机连接的cliquenet航班延误预测模型[j].计算机应用,2020,40(08):2420-2427.][5]zhang chengwei,luo feng’e,dai yi.prediction method of flight delay in designated flight plan based on data mining[j].computer science,2020,47(s2):464-470 485.[张成伟,罗凤娥,代毅.基于数据挖掘的指定航班计划延误预测方法[j].计算机科学,2020,47(s2):464-470 485.][6]wu rb,zhao t,qu j.flight delay prediction model based on deep se-densenet[j].journal of electronics and information technology,2019,41(6):1510-1517.[7]gui g,liu f,sun j,et al.flight delay prediction based on aviation big data and machine learning[j].ieee transactions on vehicular technology,2020,69(1):140-150.[8]wu w,cai k,yan y,et al.an improved svm model for flight delay prediction[c]//2019ieee/aiaa 38th digital avionics systems conference(dasc).ieee,2019:1-6.[9]eu.the official gdpr wedsite[eb/ol].[2022-1-14.]https://ec.europa.en/commission/priorities/justice-and-fundamental-rights/data-pro tection/2018-reform-eu-data-protection-reles_en,2020.
技术实现要素:
本发明为解决公知技术中存在的技术问题,本发明旨在保护高标准的隐私,不仅保护个人实体,而且在可行的程度上保护模式不被披露。提出纵向联邦学习框架融合改进逻辑回归模型,在不泄露航空公司和机场底层数据的前提下,允许将数据的使用和模型训练分离;通过改进逻辑回归算法使其能够结合paillier加密技术保证模型参数传递安全,解决纵向联邦学习中参与方之间通信不安全的问题;提供一种基于纵向联邦学习的航班延误预测方法及系统。本发明的第一目的是提供一种基于纵向联邦学习的航班延误预测方法,至少包括:在联邦数据预处理阶段,集中式建模采用不同的机场对各自的航班信息数据进行单独处理,不同的机场有不同的处理方法和标准。在联邦学习应用场景下,为保证各自构建的特征数据能够正常训练,使用统一的数据预处理标准,使各机场按照该标准对数据进行清洗。
①
缺失值的处理。航班延误预测数据集包括航班的基本信息和延误因素等重要信息,但是,部分数据的缺失可能影响特征提取和模型训练。针对缺失程度和特征影响程度,可以分为不同的处理方式。对于缺失数量大于总数量的一半的属性,采用拉格朗日中值填充法。对于延误时间等重要的数据特征,可以采用精准填充方法。对于无法填充的异常数据和缺
失数据可以采用零填充。
②
数据融合。为了使预测结果更加准确,将天气数据和机场数据进行融合,筛选出天气数据中对应出发机场和到达机场的天气情况与对应机场拼接。
③
one-hot编码。一些属性表示不同类别的离散值,需要转换这些属性提取适合联邦学习算法的特征。比如出发机场id10397可以用00001表示。
④
散列程度。为了减小离散值,将机场风速根据大小划分空间分为8个等级,将机场的降水量划分为6个等级。这样就把航班延误预测问题退化为一个二分类问题。在加密实体对齐阶段。由于机场和航空公司所拥有的实体和特征不同,需使用一种基于非对称加密rsa算法和哈希函数,在此过程由航空公司方产生公钥发送给机场方,这样可以去除第三方来求双方共有的数据交集航班号id。在加密模型训练阶段,在确定共有的实体id后,机场和航空公司可以利用这些共有的实体数据协同训练一个机器学习模型。训练过程如下:步骤1协调者生成密钥对,并将公钥分别发送给机场和航空公司。步骤2机场和航空公司以加密的方式交换中间参数。中间参数用于计算梯度和损失函数值。步骤3机场和航空公司计算梯度值并加密,机场方作为主动方计算加密损失函数值,双方将加密结果分别发送给协调者。步骤4协调者利用私钥对双方传来的加密数据解密,并将结果返回给机场和航空公司。双方根据返回的梯度信息来更新模型参数。对本地的数据进行更新和分类,为航班延误预测做出依据。在输出阶段,采用部分指标作为航班延误预测模型性能的评估,准确率(accuracy,acc)作为最直观的衡量指标,用来衡量预测延误与否结果正确的航班数占总航班数的百分比,代表整体分类的准确性,选取准确率作为评估指标之一,所述准确率指的是所有预测结果为正确的占总的航班数的比例。由于数据集是关于航班延误预测,具有很大的有偏性,即延误与不延误比例不平衡,仅选取准确率有时候会产生机器欺骗,使预测指标变得没有意义。因此引入召回率(recall)、f1-score很有必要。召回率recall代表对于发生延误航班情况的预测结果正确的航班数量占总延误航班数的百分比;f1-score是对召回率和精确率的调和平均数,f1-score越高,模型越好。本发明第二目的是提供一种基于纵向联邦学习的航班延误预测系统,所述系统包括:联邦数据预处理层,集中式建模采用不同的机场对各自的航班信息数据进行单独处理,不同的机场有不同的处理方法和标准。在联邦学习应用场景下,为保证各自构建的特征数据能够正常训练,使用统一的数据预处理标准,使各机场按照该标准对数据进行清洗。通过对数据进行数据清洗、数据融合、one-hot编码和散列程度处理提高系统的预测准确率。加密实体对齐层,参与系统的所有参与方中寻找数据样本的公共集合,可以通过基于加密的数据库交集算法进行样本对齐。加密模型训练齐层,各自的敏感数据存储在本地。同时,为了防止第三方从机场方和航空公司方学习到相关模型信息而泄露隐私,将加密的梯度信息加上加密的随机掩码,掩藏矩阵能保证随机性和安全性。
输出层,任何一方接收到的关于其他方的唯一私有信息都是基于同态加密方法得到的,每一方对其他方的数据结构是未知的,并且只能获得自己持有的特征相关的模型参数。本发明的第三个目的是提供一种信息数据处理终端,用于实现上述基于纵向联邦学习的航班延误预测方法。本发明的第四目的是提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行上述基于纵向联邦学习的航班延误预测方法。本发明具有的优点和积极效果是:通过采用上述技术方案,本发明通过航空公司提供的数据和五个关联机场数据并融合天气因素,部署单服务器-多客户端的架构,同时引入paillier同态加密技术保证全局模型参数安全,使多源异构的参与方在不泄露底层敏感数据的前提下协同训练一个联合模型。本发明提供的技术方案,在数据传输过程中,传输的都是加密数据,并且在模型训练过程中采用的模型和参数也是经过同态加密的,进一步保障数据安全,系统生产的模型可以被安全的部署到生产中。本发明为航班延误预测中的数据隐私保护提供一种新的方案。
附图说明
图1为本发明实施例提供的航班延误预测层次架构图;图2为本发明实施例提供的特征相关程度热图;图3为本发明实施例提供的到达延迟时长和出发延迟时长之间的关系;图4为本发明实施例提供的飞行距离和到达延误时间之间的关系;图5为本发明实施例提供的迭代次数的优化;图6为本发明实施例提供的recall1曲线变化图;图7为本发明实施例roc曲线对比图。
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下:联邦学习:联邦学习旨在建立一个基于分布数据集的联邦学习模型。联邦学习包括两个过程,分别是模型训练和模型推理。在模型训练过程中,模型的相关信息能够在各方之间以加密的形式交换,但数据不能。已训练好的联邦学习模型可以置于联邦学习系统的各参与方,也可以在多方之间共享。
[0029]
纵向联邦学习:联合多个参与者的具有相同样本的不同特征进行联邦学习。
[0030]
paillier同态加密算法:paillier在1999年提出一种可证的安全加密系统,该技术允许在无需解密的前提下对密文进行加法运算,能够计算其没有明文访问权限的数据,为多方间信息或知识共享提供高级别的安全性,从而保护每一方的数据隐私和模型的安全。通过这种方式实现计算数据的任意复杂函数。
[0029]
密钥生成(pk,sk)
←
keygen(
·
)。随机选择两个大素数p,q满足gcd(pq,(p-1),(q-1))=1,计算n=pq和λ=lcm(p-1,q-1)其中,lcm表示最小公倍数,|n|为n的比特长度。随机
选择定义计算μ=(l(g
λ
mod n2))-1mod n,公钥pk:(n,g),私钥sk:(λ,μ)。
[0031]
加密算法c
←
enc(pk,m)。输入明文消息m,0≤m《n。选取随机数r满足0≤r《n且r∈z
n
。计算密文c=g
mrn mod n2。
[0032]
解密算法dec(sk,c)。输入密文c,满足计算明文消息m=l(c
λ
mod n2)
·
μmod n。
[0033]
加法同态加密运算。对于明文空间中任意两个元素u,v,其加密结果分别为[[u]],[[v]]。满足dec([[u]] [[v]])=dec([[u v]])=u v。如图1至图7所示,本发明的技术方案为:一种基于纵向联邦学习的航班延误预测方法,包括:联邦数据预处理,集中式建模采用不同的机场对各自的航班信息数据进行单独处理,不同的机场有不同的处理方法和标准。在联邦学习应用场景下,为保证各自构建的特征数据能够正常训练,使用统一的数据预处理标准,使各机场按照该标准对数据进行清洗。
①
缺失值的处理。航班延误预测数据集包括航班的基本信息和延误因素等重要信息,但是,部分数据的缺失可能影响特征提取和模型训练。针对缺失程度和特征影响程度,可以分为不同的处理方式。对于缺失数量大于总数量的一半的属性,采用拉格朗日中值填充法。对于延误时间等重要的数据特征,可以采用精准填充方法。对于无法填充的异常数据和缺失数据可以采用零填充。
②
数据融合。为了使预测结果更加准确,将天气数据和机场数据进行融合,筛选出天气数据中对应出发机场和到达机场的天气情况与对应机场拼接。
③
one-hot编码。一些属性表示不同类别的离散值,需要转换这些属性提取适合联邦学习算法的特征。比如出发机场id10397可以用00001表示。
④
散列程度。为了减小离散值,将机场风速根据大小划分空间分为8个等级,将机场的降水量划分为6个等级。这样就把航班延误预测问题退化为一个二分类问题。加密实体对齐,由于机场和航空公司所拥有的实体和特征不同,需使用一种基于非对称加密rsa算法和哈希函数,在此过程由航空公司方产生公钥发送给机场方,这样可以去除第三方来求双方共有的数据交集航班号id。加密模型训练,在确定共有的实体id后,机场和航空公司可以利用这些共有的实体数据协同训练一个机器学习模型。训练过程如下:步骤1协调者生成密钥对,并将公钥分别发送给机场和航空公司。步骤2机场和航空公司以加密的方式交换中间参数。中间参数用于计算梯度和损失函数值。步骤3机场和航空公司计算梯度值并加密,机场方作为主动方计算加密损失函数值,双方将加密结果分别发送给协调者。步骤4协调者利用私钥对双方传来的加密数据解密,并将结果返回给机场和航空公司。双方根据返回的梯度信息来更新模型参数。对本地的数据进行更新和分类,为航班延误预测做出依据。输出,采用部分指标作为航班延误预测模型性能的评估,准确率(accuracy,acc)所述准确率指的是所有预测结果为正确的占总的航班数的比例;作为最直观的衡量指标,用来衡量预测延误与否结果正确的航班数占总航班数的百分比,代表整体分类的准确性,
选取准确率作为评估指标之一。由于数据集是关于航班延误预测,具有很大的有偏性,即延误与不延误比例不平衡,仅选取准确率有时候会产生机器欺骗,使预测指标变得没有意义。因此引入召回率(recall)、f1-score很有必要。召回率recall代表对于发生延误航班情况的预测结果正确的航班数量占总延误航班数的百分比;f1-score是对召回率和精确率的调和平均数,f1-score越高,模型越好。结合航班延误层次架构模型,算法的详细设计主要是隐私保护的逻辑回归算法,其包括采用paillier同态加密算法及其对梯度进行加密计算和隐私保护的训练过程。在纵向联邦学习框架中,两个参与方分别是机场和航空公司,设机场的训练数据集{x
api
,y}={x
ap1
,x
ap2
,x
ap3
,
…
,x
apn
,y},航空公司数据集{x
dli
}={x
dl1
,x
dl2
,x
dl3
,...,x
dln
},其中n表示双方包含的特征个数,机场数据{x
api
,y}包括延误与否作为y标签,y∈(0,1)0代表没有延误,1代表发生延误。通过学习到的模型训练出一组参数,使得样本映射到(0,1)。定义1主动方:数据的提供方,拥有训练特征和标签数据。定义2被动方:数据的提供方,只提供训练特征,没有样本标签。定义3协调方:在联邦学习参与方训练过程起辅助协调的作用,辅助多方完成联合建模,用来聚合梯度或者模型,可以为机构或组织。本发明将航班延误与否视为二分类问题,所以输出结果为两个值,并利用logistic函数将产生的预测值映射到0~1之间表示要学习的权重参数,b表示偏差,g
ω,b
(x)≥0.5时标签为1,g
ω,b
(x)≤0.5时标签为0。纵向联邦学习将不同参与方的特征加密聚合,由此推断基于纵向联邦学习框架的逻辑回归算法损失函数在每一个训练轮次中,参与方从第三方服务器上下载全局模型,在本地进行计算更新梯度,上传至服务器。第三方服务器进行更新判断模型是否收敛。在这期间,敌手利用模型梯度信息,观察到权重的更新推理出参与方的数据信息。表1总结了基于纵向联邦学习的安全逻辑回归模型的训练步骤。在加密样本对齐阶段和安全的模型训练过程中,各自的敏感数据存储在本地。同时,为了防止第三方从机场方和航空公司方学习到相关模型信息而泄露隐私,将加密的梯度信息加上加密的随机掩码,掩藏矩阵能保证随机性和安全性。训练结束时,任何一方接收到的关于其他方的唯一私有信息都是基于同态加密方法得到的,每一方对其他方的数据结构是未知的,并且只能获得自己持有的特征相关的模型参数。在不受隐私保护的前提下,表1中的训练过程对损失函数和梯度的计算结果与集中式建模方式所得到结果相同。因此,联合建模方式是无损的,最佳性能也得到保证。表1.隐私保护模型训练过程
实验环境及数据开发语言:python操作系统:ubuntu运行内存:8g硬盘空间:40g处理器:inter(r)core(tm)i5-3407 cpu@3.2hz。要对所提出的模型进行无偏评估,将模型的训练数据分成两部分,即训练集和测试集。训练集用来对模型参数进行拟合,测试集用来把训练好的模型进行评估模型性能。训练集和测试集以8:2的比例进行划分。前9547条作为训练集数据,后1685条作为测试集数据。根据上面提出的航空公司数据和机场数据的特征作为预测建模的输入,机场每天的航班延误情况作为基于原始数据计算的标签。在航班延误预测模型中有很多指标可以被选取作为模型性能的评估,准确率(accuracy,acc)作为最直观的衡量指标,用来衡量预测延误与否结果正确的航班数占总航班数的百分比,代表整体分类的准确性,选取准确率作为评估指标之一。由于数据集是关于航班延误预测,具有很大的有偏性,即延误与不延误比例不平衡,仅选取准确率有时候会产
生机器欺骗,使预测指标变得没有意义。因此引入召回率(recall)、f1-score很有必要。召回率recall代表对于发生延误航班情况的预测结果正确的航班数量占总延误航班数的百分比;f1-score是对召回率和精确率的调和平均数,f1-score越高,模型越好。在航班延误预测问题中需要增强对数据结构的理解和确定最能决定分类的特征值,以提高预测模型的准确率。利用python实现数据可视化,使数据关系更加直观清晰。图2表示机场数据特征之间的相关系数,其中可以看出出发延误与到达延误相关程度系数为0.91,数值越大,表明二者之间具有很强的联系。图3显示了具体的出发延迟时长和到达延迟时长之间的强相关性。图4表示飞行距离和到达延误时间之间的关系散点图,可以直观的看出到1500英里的飞行距离以内延误时间大多不超过300分钟(正数大于15表示延误时长超过15分钟,负数表示提前到达,0表示准点到达)。为了尽可能以低的计算成本实现理想的预测精度,需要在学习率、特征提取、迭代次数之间取得平衡。尤其是确定理想的迭代次数。如图5所示,随着迭代次数的增加,预测准确率逐渐上升,但是超过1100次预测精度降低,因此选择1100次迭代来训练理想模型。对于每个本地客户端进行训练时,最大网速配置为10mb/s,用于模型上传和下载,权重衰减系数设置0.0001。学习率设为0.01,批处理大小设置为256,迭代次数为1100次。实验结果对比分析本发明将纵向联邦学习框架融合逻辑回归模型和将五个机场的数据和航空公司数据融合在一起的集中式建模逻辑回归模型和集中式建模xgboost模型进行比较。对于模型的性能对比,即二元分类器在不同阈值上的诊断能力,选取roc曲线下的面积。roc曲线有助于理解跨不同阈值的true positive rate(tpr)和false positive rate(fpr)之间的权衡准确率acc值随着阈值的变化,基本趋于一致达到96%,但是召回率recall值随着阈值的变化,有明显改变。分别选取阈值为0.75,0.5,0.25时,召回率recall变化曲线如图6所示,随着阈值的增大,到达延误预测召回率降低;当阈值减小时,不延误样本和延误样本的不均衡比例减小,模型性能得以进一步提高,也可以看出分类器的可扩展性。roc曲线能够尽量降低不平衡数据带来的干扰,更加客观地衡量模型本身的性能,roc曲线图是真正例率(tpr,true positive rate)与反正例率(fpr,false positive rate)的关系图。但是对于两个roc曲线相近的模型的比较单纯看曲线并不能明显的区分哪个模型好,auc(area under curve)代表roc曲线下涵盖的面积值,位于0.1到1之间。可以更准确的评价分类器的好坏,值越大越好。三种方法的roc曲线以及其auc值的比较如图7所示,x轴为tpr表示真正例率,y轴为fpr表示反正例率,纵向联邦学习框架融合逻辑回归模型的auc值为0.98,而集中式建模逻辑回归模型的auc值为0.98,两者达到相同的性能,而集中式建模xgboost模型的auc值为0.70,说明对于本文做二值分类预测问题逻辑回归模型性能更好。表2随机提取不同参与方对应数据集中2000、4000、5000、8000、9000、11232个样本分别实验,可得最后的航班延误预测平均准确率达到92.41%。随着样本数量的增加,航班延误预测准确率高达96.8%。表2.预测准确率分析
准确率相比于集中式建模逻辑回归算法和集中式建模xgboost算法[18]分别提升1.8%和11.8%。同时,纵向联邦学习框架也体现出了相比于集中式建模在隐私保护和学习能力上的优势。不同模型的不同性能指标对比见表3。表3.不同模型的不同性能指标对比算法性能分析加解密计算开销和通信开销。集中式建模中通信成本相对较小,计算成本占主导地位,而纵向联邦学习在通信成本占主导地位,通常会受到有限带宽的影响,模型的效率依赖于双方通信开销和数据加解密计算开销。在每一轮迭代中,双方传输的信息量随相同实体数量的增长而增加。在paillier同态加密算法中一般设置默认参数q为127bit大素数,安全密钥大小为2048位。为了保证隐私数据不易被破解的前提下,可以将安全密钥大小设为1024位来达到安全和运算效率的平衡。在inter(r)core(tm)i5-3407 cpu@3.2hz计算机上进行加解密计算时间分别为:加密时间t_enc,执行1000次耗时大约为19s。解密时间t_dec,执行1000次耗时大约为6s。加法时间t_add,执行1000次2个密文相加运算耗时大约为0.05s。乘法时间t_mul,执行1000次得到大约平均耗时0.85s。在全局模型训练轮次中,每一个参与方都需要给协调方发送完整的模型参数更新,并且通信开销会随着参与方和迭代轮次的增加而增加。一个迭代过程中各开销的时间复杂度见表4。表4.时间复杂度开销类型时间复杂度
加密计算o(n
×
t_enc)解密计算o(n
×
t_dec)机场方梯度计算o(n
×dap
×
t_mul)航空公司方梯度计算o(n
×ddl
×
t_mul)损失函数计算o(n
×
t_mul)通信开销为2(3
×n×
cs cs),其中n表示batch_size大小,d
ap
,d
dl
分别表示机场和航空公司的特征维数,cs表示一条密文大小。在批处理大小为256,密文大小为256b,一个迭代过程中通信开销大约为48k。安全性。对敏感数据采用paillier加法同态加密技术,表1中所采用的协议不会向协调方泄露任何信息,航空公司在每一步都会学习它的梯度,但是根梯度公式可知,航空公司方并不能学习到机场方的任何信息,根据标量积协议(scalar product protocol)的安全性建立在只要样本数量远远大于特征数量就无法解出任何信息。同理,机场方也不能学习到航空公司方的任何信息。由此可以证明该协议的安全性。一种基于联邦学习的航班延误预测系统,包括:联邦数据预处理层,集中式建模采用不同的机场对各自的航班信息数据进行单独处理,不同的机场有不同的处理方法和标准。在联邦学习应用场景下,为保证各自构建的特征数据能够正常训练,使用统一的数据预处理标准,使各机场按照该标准对数据进行清洗。通过对数据进行数据清洗、数据融合、one-hot编码和散列程度处理提高系统的预测准确率。加密实体对齐层,参与系统的所有参与方中寻找数据样本的公共集合,可以通过基于加密的数据库交集算法进行样本对齐。加密模型训练齐层,各自的敏感数据存储在本地。同时,为了防止第三方从机场方和航空公司方学习到相关模型信息而泄露隐私,将加密的梯度信息加上加密的随机掩码,掩藏矩阵能保证随机性和安全性。输出层,任何一方接收到的关于其他方的唯一私有信息都是基于同态加密方法得到的,每一方对其他方的数据结构是未知的,并且只能获得自己持有的特征相关的模型参数。以上所述仅是对本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。