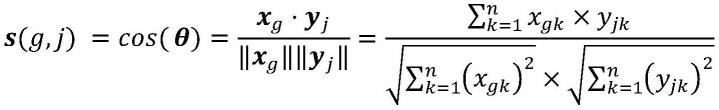
1.本发明属于模式识别技术领域,具体涉及一种视频行人重识别方法。
背景技术:
2.行人识别问题是目前公共安全监控领域的难点和重点,其目的在于匹配不同摄像头下属于同一行人的图像或者视频数据,其在刑事侦查、预警分析和智慧城市等方面具有广阔的应用前景。
3.目前,基于图像的行人重识别技术已经比较成熟,基于视频的行人重识别方法因其具有丰富的目标信息,能够建立更为鲁棒的重识别方法,越来越受到学界的关注。
4.陈莉、王洪元等(《联合均等采样随机擦除和全局时间特征池化的视频行人重识别方法》,计算机应用,2021,41(1):164-169)针对为解决视频监控中遮挡、背景物干扰,以及行人外观、姿势相似性等因素导致的视频行人重识别准确率较低的问题,提出了联合均等采样随机擦除和全局时间特征池化的视频行人重识别方法。首先针对目标行人被干扰或部分遮挡的情况,采用了均等采样随机擦除的数据增强方法来有效地缓解遮挡,提高模型的泛化能力,更准确地匹配行人;其次为了进一步提高视频行人重识别的精度,学习更有判别力的特征表示,使用三维卷积神经网络提取时空特征,并在网络输出行人特征表示前加上全局时间特征池化层,这样既能获取上下文的空间信息,又能细化帧与帧之间的时序信息。但是该方法仍然存在如下问题:
5.(1)三维卷积网络参数量大,计算量大,网络收敛慢;
6.(2)缺乏对行人目标运动特性的分析,所提取的特征不能全面反映行人的目标特征。
技术实现要素:
7.为了克服现有技术的不足,本发明提供了一种基于目标运动特性的视频行人重识别方法,首先建立目标特征提取基础网络,再建立目标运动特性提取层,再将基础网络的各个模块与运动特性提取层依次进行组合,搭建得到视频行人特征提取网络,对视频行人特征提取网络进行训练;将待识别行人数据和数据库中的存储数据分别输入训练完成的视频行人特征提取网络进行特征提取,得到待识别行人数据特征向量和存储数据特征向量;分别计算待识别行人数据特征向量和每个存储数据特征向量之间的余弦相似度,并取待识别行人数据与数据库中存储数据中余弦相似度最高的样本作为成功匹配的样本,即为视频行人重识别结果。本发明中充分利用了视频数据时空信息,增强了对行人目标的特征提取能力。
8.本发明解决其技术问题所采用的技术方案包括如下步骤:
9.步骤1:建立目标特征提取基础网络,基础网络由残差卷积神经网络resnet-50的五个卷积模块组成,将这五个模块分别记为l0、l1、l2、l3、l4;
10.步骤2、建立目标运动特性提取层,记为m0、m1、m2、m3,具体如下:
11.步骤2-1:从视频中截取t帧图像,将t帧图像分别独立输入l0,提取图像特征分别为fi,i=1,...,t;
12.步骤2-2:计算参考特征
[0013][0014]
其中,w为待学习的参数;c、h和w分别为图像特征的通道数、高度和宽度;为了保证与fi具有相同的尺寸,通道数设为1;
[0015]
步骤2-3:计算运动特性特征:
[0016][0017]
其中,a是和fi的关系矩阵,gi为运动特性特征,与fi具有相同的尺寸;
[0018]
步骤2-4:将gi分别独立输入l1,提取图像特征作为fi,重复步骤2-2和步骤2-3,依次遍历l2、l3、l4;
[0019]
步骤2-5:将l0到l1中间的目标运动特性提取层记为m0,将l1到l2中间的目标运动特性提取层记为m1,将l2到l3中间的目标运动特性提取层记为m2,将l3到l4中间的目标运动特性提取层记为m3,得到视频行人特征提取网络,该网络构成为l0、m0、l1、m1、l2、m2、l3、m3、l4依次排列;l4输出的特征通过平均池化层进行降维,最终输出视频行人重识别特征;
[0020]
步骤3:训练步骤2所创建的视频行人特征提取网络,得到训练完成的视频行人特征提取网络;训练过程中采用三元损失函数和softmax交叉熵损失函数进行联合训练;
[0021]
步骤4:将待识别行人数据和数据库中的存储数据分别输入训练完成的视频行人特征提取网络进行特征提取,得到待识别行人数据特征向量和存储数据特征向量;
[0022]
步骤5:分别计算待识别行人数据特征向量和每个存储数据特征向量之间的余弦相似度,并取待识别行人数据与数据库中存储数据中余弦相似度最高的样本作为成功匹配的样本,即为视频行人重识别结果。
[0023]
优选地,所述余弦相似度采用如下公式计算:
[0024][0025]
其中,n是特征向量的维度,xg为第g个行人对应的特征向量,g=1,...,n,n为待识别行人数,yj为第j个目标对应的特征向量,j=1,...,m,m为数据库中的存储数据数量。
[0026]
本发明的有益效果如下:
[0027]
1、本发明的深度卷积神经网络针对视频行人重识别进行优化,克服了现有的行人重识别技术识别精度较低,所采用的三维卷积网络参数量大、计算量大,网络收敛慢,并且所提取的特征不能全面反映行人的目标特征,缺乏对行人的运动特性的分析利用的缺陷。
[0028]
2、本发明中加入的目标运动特性提取模块,充分利用了视频数据时空信息,通过参考多帧图像全局特征信息挖掘出图像特征的有用信息,同时去除其无用信息,实现对目标运动特性的挖掘利用,增强了对行人目标的特征提取能力。与现有方法比较,识别rank1
准确率在mars数据集上提升了5.0%。
附图说明
[0029]
图1是本发明视频行人特征提取网络目标运动特性提取网络的结构图。
[0030]
图2是本发明目标运动特性提取层结构图。
[0031]
图3是本发明方法流程图。
具体实施方式
[0032]
下面结合附图和实施例对本发明进一步说明。
[0033]
一种基于目标运动特性的视频行人重识别方法,包括如下步骤:
[0034]
步骤1:建立目标特征提取基础网络,基础网络由残差卷积神经网络resnet-50的五个卷积模块组成,将这五个模块分别记为l0、l1、l2、l3、l4;
[0035]
步骤2、建立目标运动特性提取层,记为m0、m1、m2、m3,具体如下:
[0036]
步骤2-1:从视频中截取t帧图像,将t帧图像分别独立输入l0,提取图像特征分别为fi,i=1,...,t;
[0037]
步骤2-2:计算参考特征
[0038][0039]
其中,w为待学习的参数;c、h和w分别为图像特征的通道数、高度和宽度;为了保证与fi具有相同的尺寸,通道数设为1;
[0040]
步骤2-3:计算运动特性特征:
[0041][0042]
其中,a是和fi的关系矩阵,gi为运动特性特征,与fi具有相同的尺寸;
[0043]
步骤2-4:将gi分别独立输入l1,提取图像特征作为fi,重复步骤2-2和步骤2-3,依次遍历l2、l3、l4;
[0044]
步骤2-5:将l0到l1中间的目标运动特性提取层记为m0,将l1到l2中间的目标运动特性提取层记为m1,将l2到l3中间的目标运动特性提取层记为m2,将l3到l4中间的目标运动特性提取层记为m3,得到视频行人特征提取网络,该网络构成为l0、m0、l1、m1、l2、m2、l3、m3、l4依次排列;l4输出的特征通过平均池化层进行降维,最终输出视频行人重识别特征;
[0045]
步骤3:训练步骤2所创建的视频行人特征提取网络,得到训练完成的视频行人特征提取网络;训练过程中采用三元损失函数和softmax交叉熵损失函数进行联合训练;
[0046]
步骤4:将待识别行人数据和数据库中的存储数据分别输入训练完成的视频行人特征提取网络进行特征提取,得到待识别行人数据特征向量和存储数据特征向量;
[0047]
步骤5:分别计算待识别行人数据特征向量和每个存储数据特征向量之间的余弦相似度,并取待识别行人数据与数据库中存储数据中余弦相似度最高的样本作为成功匹配的样本,即为视频行人重识别结果。
[0048]
具体实施例:
[0049]
本发明提出的深度卷积神经网络分为2部分,第一部分以resnet-50的5组卷积模块为骨干网络,第二部分是目标运动特性层。通过resnet-50和目标特性提取层的有机统一,实现对视频数据时空信息的有效提取,得到维度为2048的特征向量。并经过余弦相似度排序产生识别结果。
[0050]
以重识别为实例说明本发明的具体实施方式,但本发明的技术内容不限于所述的范围,以本发明在mars数据集上的实现作为实例,具体实施方式包括以下步骤:
[0051]
1、构建视频行人特征提取网络的基础模块,建立重识别网络目标特征提取基础网络,基础网络由残差卷积神经网络resnet-50的五个卷积模块组成,将这五个模块分别记为l0、l1、l2、l3、l4。
[0052]
2、目标运动特性提取层的结构如图2所示,建立四种不同粒度的目标运动特性提取层,记为m0、m1、m2、m3,其依据t帧特征提取目标运动特性。
[0053]
建立的目标运动特性提取层的运算过程分为以下步骤:
[0054]
2.1根据t帧视频帧的特征计算参考特征采取的计算公式为:
[0055][0056]
其中,w为待学习的参数,可以通过t
×1×
1卷积操作实现;t帧特征1卷积操作实现;t帧特征fi为第i帧对应的特征表示,c、h和w分别为特征的通道数、高度和宽度。为了保证与fi具有相同的尺寸,上述卷积输出的通道数为1。
[0057]
2.2计算运动特性特征时,所采取的计算公式为:
[0058][0059]
其中,a是和fi的关系矩阵,包含了t帧特征的所有信息,且其作为参考能够反映全局信息,同时抑制噪声,进而挖掘fi,(i=1,...,t)中的有用信息,去除无用信息。gi为所得的运动特性特征,与fi具有相同的尺寸。
[0060]
3、将第1步中得到的基础网络的各个模块与第2步中得到的运动特性提取层依次进行组合,搭建得到视频行人特征提取网络,该网络构成为l0、m0、l1、m1、l2、m2、l3、m3、l4照顺序排列,如图1所示。
[0061]
4、训练第3步所创建的视频行人特征提取网络,并对训练得到的网络参数进行保存。
[0062]
5、利用第3步的视频行人特征提取网络,并将第4步得到的网络参数加载到网络中。利用加载参数后的网络对数据库中存储数据和待识别数据分别进行特征提取,将每个样本对应的存储数据特征向量和待识别数据特征向量进行存储。
[0063]
6、计算第5步得到的存储数据特征向量和待识别数据特征向量之间的余弦相似度,并取存储数据中与待识别数据余弦相似度最高的样本作为成功匹配的样本,最终得到属于同一行人的视频图像数据。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
