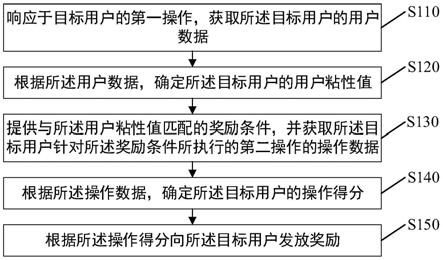
1.本发明涉及语义理解技术领域,具体涉及一种基于知识库应用的语义搜索方法。
背景技术:
2.依据于信息科技的发达,网络资源的爆发式增长,现有的资源搜索模式并未能考虑到用户群体的首要需求及语义等相关信息,因此,无法正确理解用户的真实查询意图,导致搜索效率下降。市面上主流知识库系统依据于用户输入的关键词在知识库中寻找相似问题,依据于问题对应人工编辑好的答案进行问题解答。检索精度及检索结果准确率低。
3.主流知识库系统依据于用户输入的关键词,根据关键词及其同义词进行问题搜索。对于客服等场景中,输入完整关键词耗时较长,用户体验差,影响效率。主流知识库在进行文章内检索等情况下,一般是基于关键词及其同义词进行检索,匹配关系一般都是手动进行配置管理。当超出该同义词定义范围之外就无法检索到结果。
技术实现要素:
4.为此,本发明提供一种基于知识库应用的语义搜索方法,以解决现有资源搜索速度慢、准确率低的问题。
5.为了实现上述目的,本发明提供如下技术方案:
6.本发明公开了一种基于知识库应用的语义搜索方法,其特征在于,所述方法为:
7.s1、录入文档,通过分词器将文档拆分为词语,统计词语出现的次数,记录词语和文档映射关系,将所有词语和映射关系放入内存当做索引;
8.s2、将索引分成多个分片,并对每个分片进行备份,每个分片和备份分布在多台服务器上,以分布式的方式提供查询服务;
9.s3、输入关键词进行智能搜索,基于关键词进行索引匹配和语义相似性扩展搜索,基于关键词图谱的语义扩展搜索具体实现逻辑;
10.s4、根据确定的基于用户行为的语义相似度及语义扩展结果,预测用户对知识库资源的评分,将评分高资源信息作为推荐列表返回给用户。
11.进一步地,所述s1步骤中,还包括将词语转换成成拼音和拼音首字母,建立索引结构并放入内存,根据拼音和拼音首字母能够检索查询文档;对词语配置同义词表达,检索词语时能够扩展同义词;词语中配置相应的屏蔽词,屏蔽用户违规查询。
12.进一步地,所述索引分片后,每个分片放在不同服务器,在管理服务器上记录分片和分片对应的服务器,针对每个分片进行备份,把备份分片分布不同服务器上,用户使用关键词查询时,请求被转给分片所在的服务器,请求被负载均衡到多个服务器;所述分片损坏时,管理服务器选择一个备份做为正式分片,继续提供服务,为查询提供了容灾性。
13.进一步地,所述智能搜索过程中,将关键字转换成拼音和拼音首字母,分别在汉字索引,拼音索引,拼音首字母索引,查找文章列表,获取文章列表后排重,提取关键字所在的句子,高亮显示关键字;
14.进行结果筛选,服务器按照关键词出现的次数作为权重自动排序,容许用户指定返回条数,通过日期筛选结果;
15.智能推荐,服务器会对关键字进行联想,做出推荐列表,方便用户选择。
16.进一步地,所述智能搜索过程中,能够进行句子查找,用户将句子录入,服务器将句子拆分为词语进行查找,在结果中反馈含有词语的文章;
17.在文章展示时同样能够进行搜索,按照关键词出现的位置建立目录,帮助用户直接定位到具体位置。
18.进一步地,所述智能搜索过程中,用户输入待查询的相关关键词,将关键词在内存中索引或数据存储库中进行概念性内容匹配,查询请求用于对应业务相关资源,如果其匹配成功,则相对应执行依据于本体搜索关键词进行进一步的语义扩展,如果其匹配失败,则执行基于关键词图谱的语义扩展功能。
19.进一步地,所述匹配失败,基于关键词图谱的语义扩展功能的依据为:
20.依据于用户搜索历史数据与当前用户行为语义的相似度进行关键词匹配;
21.依据于用户行为语义的相似性,极其相似的关联匹配度基于以上特征,预测用户对资源的匹配程度,将匹配信息作为推荐列表推送给搜索用户群体。
22.进一步地,所述匹配成功进行语义扩展,扩展内容为:
23.如若匹配成功,则所得关键词会映射到数据库中;计算的各个待扩展体概念与本体库中其他概念语义的相似度;将语义相似度大于预设的第一阈值时,其它的本体词汇将会作为待扩展的扩展词。
24.进一步地,所述语义相似度的表达式为:
[0025][0026]
其中,simont(c1,c2)表示基于本体的语义相似度,f1和f2分别表示实体概念c1和c2与最近的公共父节点之间的最短路径,d是c1和c2所在本体层次结构中的最大深度;
[0027]
如果执行失败,则进行拓展,根据构建的检索图谱,对待扩展实体概念与知识库内的本体概念各自进行继承关联及路径关联计算;关联值之和大于设置的第二阈值时,知识库图谱的本体概念将会作为待扩展实体概念扩展词。
[0028]
进一步地,所述继承关联计算公式为:
[0029][0030]
其中,inherit(ci,cj)表示实体概念ci和cj的继承关联值,k表示实体概念ci和cj的局部深度最大的共同祖先数量,an是ci和cj的局部深度最大的共同祖先,是an在本体层次结构中的深度,是an所在分支的最大深度;
[0031]
所述路径关联计算公式为:
[0032][0033]
其中,path(ci,cj)表示实体概念ci和cj的路径关联值,m表示实体概念ci和cj的路
径关联条数,lengthn为ci和cj之间第n条路径关联长度;关联值之和表示为:simkg(ci,cj)=inherit(ci,cj) path(ci,cj),其中,simkg(ci,cj)表示继承关联值和路径关联值的和。
[0034]
本发明具有如下优点:
[0035]
本发明公开了一种基于知识库应用的语义搜索方法,依据于语义进行模糊搜索,根据语义的问题匹配结果进行问题解答;支持基于拼音的快速搜索,减少重复操作情况下的工作量;依据于用户搜索行为,对无法精确匹配的内容进行语义扩展搜索和关键词自动扩展;降低了人力培训成本,提高了工作效率,并且提高了检索效率及检索结果的准确性,降低了使用者的使用门槛。
附图说明
[0036]
为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引申获得其它的实施附图。
[0037]
本说明书所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。
[0038]
图1为本发明实施例提供的一种基于知识库应用的语义搜索方法的流程图;
[0039]
图2为本发明实施例提供的索引关系示意图;
[0040]
图3为本发明实施例提供的索引分片示意图;
[0041]
图4为本发明实施例提供的关键字“短信”搜索示意图;
[0042]
图5为本发明实施例提供的关键字“短信”联想示意图;
[0043]
图6为本发明实施例提供的句子查找功能示意图;
[0044]
图7为本发明实施例提供的文章内搜索功能示意图。
具体实施方式
[0045]
以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0046]
实施例
[0047]
参考图1,本实施例公开了一种基于知识库应用的语义搜索方法,所述方法为:
[0048]
s1、录入文档,通过分词器将文档拆分为词语,统计词语出现的次数,记录词语和文档映射关系,将所有词语和映射关系放入内存当做索引;
[0049]
s2、将索引分成多个分片,并对每个分片进行备份,每个分片和备份分布在多台服务器上,以分布式的方式提供查询服务;
[0050]
s3、输入关键词进行智能搜索,基于关键词进行索引匹配和语义相似性扩展搜索,基于关键词图谱的语义扩展搜索具体实现逻辑;
[0051]
s4、根据确定的基于用户行为的语义相似度及语义扩展结果,预测用户对知识库资源的评分,将评分高资源信息作为推荐列表返回给用户。
[0052]
在s1步骤中,分词将文档拆分为词语,例如将文档“你们是祖国的花朵”拆分为词语“你们”、“祖国”、“花朵”;
[0053]
计算词语和文档之间的关系,例如词语“你好”与文档100和文档101质检单关系可以表示为:
[0054][0055]
后续查找“你好”这个词语时,能够快速列出相关文档;
[0056]
还包括将词语转换成成拼音和拼音首字母,建立索引结构并放入内存,例如将“你好”转换为“nh”和“nihao”,根据拼音和拼音首字母能够检索查询文档,用户使用“nh”和“nihao”能够查询文档;
[0057]
对词语配置同义词表达,检索词语时能够扩展同义词,例如将“你好”替换为“您好”、“hello”、“hi”,用户录入“hi”则能够替换为“你好”进行查询。
[0058]
词语中配置相应的屏蔽词,屏蔽用户违规查询,例如屏蔽“钱”、“支票”敏感词进行屏蔽。
[0059]
参考图2和图3,索引分片后,每个分片放在不同服务器,在管理服务器上记录分片和分片对应的服务器,针对每个分片进行备份,把备份分片分布不同服务器上,用户使用关
键词查询时,请求被转给分片所在的服务器,请求被负载均衡到多个服务器;所述分片损坏时,管理服务器选择一个备份做为正式分片,继续提供服务,为查询提供了容灾性。
[0060]
参考图4,智能搜索过程中,将关键字转换成拼音和拼音首字母,例如用户输入关键字“短信”,服务器将“短信”转换为“dx”和“duanxin”,分别在汉字索引,拼音索引,拼音首字母索引,查找文章列表,获取文章列表后排重,提取关键字所在的句子,高亮显示关键字;
[0061]
进行结果筛选,服务器按照关键词出现的次数作为权重自动排序,容许用户指定返回条数,通过日期筛选结果;在本实施例中筛选条件可以进行自定义,设置多个筛选条件,满足不同情况下的需求。
[0062]
参考图5,智能推荐,服务器会对关键字进行联想,做出推荐列表,方便用户选择。关键词关联文档重复次数当做关联指数。通过关联指数做出推荐列表。例如“短信”关联文档1,2,3。“验证码”关联文档2,3。验证码和短信的关联度是2。
[0063]
参考图6,智能搜索过程中,能够进行句子查找,用户将句子录入,服务器将句子拆分为词语进行查找,在结果中反馈含有词语的文章;例如:用户输入“短信群发平台”。句子被拆分成“短信”和“平台”。在结果中返回包含“短信”或“平台”的文章。
[0064]
参考图7,在文章展示时同样能够进行搜索,按照关键词出现的位置建立目录,帮助用户直接定位到具体位置。
[0065]
智能搜索过程中,用户输入待查询的相关关键词,将关键词在内存中索引或数据存储库中进行概念性内容匹配,查询请求用于对应业务相关资源,如果其匹配成功,则相对应执行依据于本体搜索关键词进行进一步的语义扩展,如果其匹配失败,则执行基于关键词图谱的语义扩展功能。
[0066]
匹配失败,基于关键词图谱的语义扩展功能的依据为:
[0067]
依据于用户搜索历史数据与当前用户行为语义的相似度进行关键词匹配;
[0068]
依据于用户行为语义的相似性,极其相似的关联匹配度基于以上特征,预测用户对资源的匹配程度,将匹配信息作为推荐列表推送给搜索用户群体
[0069]
匹配成功进行语义扩展,扩展内容为:
[0070]
如若匹配成功,则所得关键词会映射到数据库中;计算的各个待扩展体概念与本体库中其他概念语义的相似度;将语义相似度大于预设的第一阈值时,其它的本体词汇将会作为待扩展的扩展词。
[0071]
语义相似度的表达式为:
[0072][0073]
其中,simont(c1,c2)表示基于本体的语义相似度,f1和f2分别表示实体概念c1和c2与最近的公共父节点之间的最短路径,d是c1和c2所在本体层次结构中的最大深度;
[0074]
如果执行失败,则进行拓展,根据构建的检索图谱,对待扩展实体概念与知识库内的本体概念各自进行继承关联及路径关联计算;关联值之和大于设置的第二阈值时,知识库图谱的本体概念将会作为待扩展实体概念扩展词。
[0075]
继承关联计算公式为:
[0076][0077]
其中,inherit(ci,cj)表示实体概念ci和cj的继承关联值,k表示实体概念ci和cj的局部深度最大的共同祖先数量,an是ci和cj的局部深度最大的共同祖先,是an在本体层次结构中的深度,是an所在分支的最大深度;
[0078]
所述路径关联计算公式为:
[0079][0080]
其中,path(ci,cj)表示实体概念ci和cj的路径关联值,m表示实体概念ci和cj的路径关联条数,lengthn为ci和cj之间第n条路径关联长度;关联值之和表示为:simkg(ci,cj)=inherit(ci,cj) path(ci,cj),其中,simkg(ci,cj)表示继承关联值和路径关联值的和。
[0081]
在步骤s4中,用于根据确定的基于用户行为的语义相似度及语义扩展结果,预测用户对知识库资源的评分,将评分高资源信息作为推荐列表返回给用户。当检索“k” “d”系统会自动识别依据于用户的操作习惯及对应的语义检索检测出“宽带”,依据于“宽带”进而推荐出有关客服相关的练习内容。因此,在大小写语义匹配的同时,能够依据于大小写识别后的文字再进行问题的模糊检索。
[0082]
本实施例公开的一种基于知识库应用的语义搜索方法,依据于语义进行模糊搜索,根据语义的问题匹配结果进行问题解答;支持基于拼音的快速搜索,减少重复操作情况下的工作量;依据于用户搜索行为,对无法精确匹配的内容进行语义扩展搜索和关键词自动扩展;降低了人力培训成本,提高了工作效率,并且提高了检索效率及检索结果的准确性,降低了使用者的使用门槛。
[0083]
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。