一种基于swin transformer的双流人脸伪造检测方法
技术领域
1.本发明涉及一种基于swintransformer的双流人脸伪造检测方法,应用于解决现有人脸伪造检测方案的部分局限性-泛化能力弱的问题,同时还提出了双流框架来提升模型一定的抗压缩能力,使其更符合日常生活中常见的人脸视频质量。
背景技术:
2.在过去的几十年中,随着互联网的快速崛起,新兴的社交网络融入人们的生活,使得数字图像和视频成为常见的数字数据对象。据报告,每天近20亿张图片在互联网上传播,随着数字图像的巨大使用和传播,最初随之而来的是使用像photoshop这样的编辑软件来改变图像内容的技术,但随着计算机视觉和图像处理技术取得最新进展,同时伴随着高性能计算机和gpu并行加速技术的突破,现在已经能做到在图像和视频中实时合成极其逼真的人脸,并且这种强大的人脸伪造技术仍在继续强化。这项技术的背后是无限的应用空间,但其中的某些滥用行为却为我们拉响了安全警报。现在人脸伪造技术的发展使得恶意用户可以通过操纵人脸图像来发动攻击,从而成功地识别出真实用户信息。例如最近有不法分子利用该项技术伪装成政界人物发表虚假言论,在社会上引起了很大的轰动。因此,致力于一般人脸图像和视频伪造检测的研究领域正在蓬勃发展,为了减轻伪造人脸攻击造成的负面影响,同时有利于公共安全和隐私保护,开发有效的可视化取证方案对抗这些威胁至关重要。
3.当前对人脸伪造图像的检测主要是通过深度学习的方式。深度学习是一个很有前景的研究方向,不论是在计算机视觉、自然语言还是语音识别或是其他领域,都能被派上用场。现在主流的人脸检测网络使用的是卷积神经网络(cnn),它被广泛运用在特征学习和图像分类等领域,使用卷积神经网络在训练大批量的真假人脸图像时,可以在保证速度和效率的前提下,已经达到较为理想的检测性能。还有一种方式就是利用图像的频域信息,对真实的人脸图像进行伪造,虽然留下的伪造痕迹大多数无法被人眼辨别出来,但是被频域上可以发现人脸真假图像存在不同,现有的检测方案也利用了这一特性。但是上述的检测方法存在一定的局限性,首先就是泛化能力不强,往往更换数据集后,这些方案的检测性能急剧下降。还有就是无法很好的抵御压缩,这样就不能应用检测在实际生活场景中出现的人脸图像或视频。所以现在的人脸检测方案正在不断探索及应用其它领域。
技术实现要素:
4.本发明的目的是要解决现有人脸检测方法泛化能力不足以及抗压缩能力差的问题,提供了一种基于swin transformer的双流人脸伪造检测方法,在解决现有人脸伪造检测方案的部分局限性即泛化能力弱的问题的同时,还通过双流框架提升模型抗压缩能力,使其更符合日常生活中常见的人脸视频质量。
5.为达到上述发明目的,本发明的构想是:
6.利用深度学习来进行人脸伪造图像的检测。整体搭建了一个深度学习网络模型,
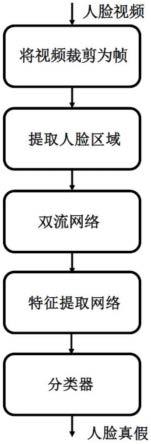
网络模型分为三部分:双流网络、特征提取网络和分类器。由于现在公开的人脸伪造数据集全部是视频,因此首先需要利用opencv将视频裁剪成帧图片。除此之外,由于帧图片包含了大量的背景信息,因此需要利用人脸定位算法将人脸区域裁剪出来。然后将得到的人脸区域图像输入到双流网络和特征提取网络中提取并学习特征。最后将学习到的特征输入到分类器中,进行人脸图像真假的识别。
7.根据上述发明构思,本发明采用下述技术方案:
8.一种基于swin transformer的双流人脸伪造检测方法,包括以下步骤:
9.(1)准备人脸视频数据集:
10.准备人脸伪造视频数据集,选择了公共的人脸伪造视频数据集:faceforensics ;
11.(2)将视频裁剪为帧:
12.考虑到训练目标是判断人脸图像的真假,将视频数据集进行处理,具体为:
13.对于所有真实或伪造的人脸视频,采用opencv工具库将其划分为不重叠的视频帧,具体做法是每秒至少截取15帧;
14.(3)提取人脸区域:
15.通过人脸检测器来定位人脸区域,去掉周围不相关的背景信息,提取人脸区域,得到人脸区域图片数据集;
16.(4)数据集的划分:
17.使用上一步得到的人脸区域图片数据集进行训练、验证和测试任务,使用了7-2-1的划分方式,训练集占70%,验证集占20%,测试集占10%;将测试集的预测结果作为评判模型的好坏的标准;本发明使用验证集的好处在于可以更好的选择出最佳的训练模型,以便防止训练过程中过拟合现象的发生;
18.(5)经双流网络检测人脸图像:
19.采用双流网络,包括rgb流和噪声流;rgb流的输入是原始的rgb图像,用于直接提取原始图像特征,通过对比度差异、不自然边界找出伪造的痕迹;噪声流的输入是噪声图片,噪声图像是将rgb图像通过srm(steganalysis rich model)卷积核得到的噪声特征图像;
20.(6)特征提取和分类:
21.对于上述双流网络得到了两种不一样的图像-rgb图像和噪声图像,首先将这两种图像结合起来一起训练,学习到更丰富的特征;使用swin transformer作为特征提取网络对图像进行端对端的训练,最后将由transformer学习的特征送到最后的分类器中,分类器主要是一层全连接层,由两个神经元组成,用以生成目标图像被识别为真与假的概率值;特征提取和分类,从而检测出人脸图像的真假。
22.优选地,在所述步骤(1)中,faceforensics 数据集利用deepfakes,faceswap,face2face,neuraltextures这四种人脸伪造方法创建了不同类别的假视频,进行面部身份替换和面部表情重建,模拟互联网上传播的人脸视频,建立人脸伪造视频数据集。本发明选择了公共的人脸伪造视频数据集:faceforensics 。faceforensics 数据集是第一个大规模的人脸伪造视频数据集,它利用deepfakes,faceswap,face2face,neuraltextures这四种人脸伪造技术创建了不同类别的假视频,前两种技术是面部身份替换,后两种是面部
表情重建。此数据集还同时对真假视频均进行h.264编码中的c0,c23,c40三种参数压缩,这样做是为了更好地模拟互联网上传播的人脸视频质量,以求更接近于实际生活中使用的人脸视频。
23.优选地,在所述步骤(3)中,人脸检测器采用dlib工具包,对于得到的视频帧,利用dlib得到最小的人脸矩形框,再以该人脸框为基准扩大至少1.3倍,作为新的裁剪区域进行保存,从而提取人脸区域。本发明机提取人脸区域,通过人脸检测器来定位人脸区域,去掉周围大量不相关的背景信息,因为人脸伪造技术只关注人脸,不关注背景区域。这里选择的人脸检测器是dlib工具包,对于得到的视频帧,利用dlib可以得到最小的人脸矩形框,再以该人脸框为基准扩大至少1.3倍作为新的裁剪区域进行保存。
24.优选地,在所述步骤(5)中,srm卷积核用于进行隐写分析,包括发现图像中真实区域和被伪造区域的噪声间的不一致的卷积核组。本发明方法经双流网络检测人脸图像时,为了有效地检测人脸图像是否经过换脸或表情重建等伪造,采用一种双流网络-rgb流和噪声流。rgb流的输入是原始的rgb图像,用于直接提取原始图像特征,通过对比度差异、不自然边界等找出伪造的痕迹。噪声流的输入是噪声图片,噪声图像是将rgb图像通过srm(steganalysis rich model)卷积核得到的噪声特征图像,srm卷积核常用于隐写分析领域,是专门设计的一种可以有效发现图像中真实区域和被伪造区域的噪声间的不一致的卷积核组。
25.本发明在特征提取和分类时,利用双流网络得到了两种不一样的图像-rgb图像和噪声图像,首先将这两种图像结合起来一起训练,以便学习到更丰富的特征。本发明使用swin transformer作为特征提取网络对图像进行端对端的训练,这样可以检测出人脸图像的真假。transformer有其特有的自注意力机制,可以进一步的发现伪造区域与未伪造区域的不同,因此会将重点关注伪造区域,学习到更多有用的特征用于辨别真假。最后将由transformer学习的特征送到最后的分类器中,分类器主要是一层全连接层,由两个神经元组成,用以生成目标图像被识别为真与假的概率值。
26.本发明与现有技术比较,具有如下显而易见的突出实质性特点和显著优点:
27.1.本发明首次使用swin transformer来进行人脸伪造图片的检测,利用transformer特有的自注意力机制来重点关注伪造区域与伪造区域的不同,这个可以有效提高模型网络的泛化能力,并且swin transformer是一种层次化视觉transformer,它可以用作计算机视觉的通用骨干网络,本发明就是使用它来深层次的提取特征;
28.2.本发明提出了一种双流网络,目的在于同时利用rgb图像特征和噪声图片特征来进行学习,这样加强了伪造痕迹的特征信息,可以在一定程度上抵抗压缩,使其能够检测真实生活中出现的人脸图像。
附图说明
29.图1为本发明优选实施例基于swin transformer的双流人脸伪造检测方法流程图。
30.图2为本发明优选实施例方法整体网络结构图。
具体实施方式
31.本发明的优选实施例结合附图作进一步说明:
32.实施例一
33.参见图1,一种基于swin transformer的双流人脸伪造检测方法,包括以下步骤:
34.(1)准备人脸视频数据集:
35.准备人脸伪造视频数据集,选择了公共的人脸伪造视频数据集:faceforensics ;
36.(2)将视频裁剪为帧:
37.考虑到训练目标是判断人脸图像的真假,将视频数据集进行处理,具体为:
38.对于所有真实或伪造的人脸视频,采用opencv工具库将其划分为不重叠的视频帧,具体做法是每秒至少截取15帧;
39.(3)提取人脸区域:
40.通过人脸检测器来定位人脸区域,去掉周围不相关的背景信息,提取人脸区域,得到人脸区域图片数据集;
41.(4)数据集的划分:
42.使用上一步得到的人脸区域图片数据集进行训练、验证和测试任务,使用了7-2-1的划分方式,训练集占70%,验证集占20%,测试集占10%;将测试集的预测结果作为评判模型的好坏的标准;
43.(5)经双流网络检测人脸图像:
44.采用双流网络,包括rgb流和噪声流;rgb流的输入是原始的rgb图像,用于直接提取原始图像特征,通过对比度差异、不自然边界找出伪造的痕迹;噪声流的输入是噪声图片,噪声图像是将rgb图像通过srm(steganalysis rich model)卷积核得到的噪声特征图像;
45.(6)特征提取和分类:
46.对于上述双流网络得到了两种不一样的图像-rgb图像和噪声图像,首先将这两种图像结合起来一起训练,学习到更丰富的特征;使用swin transformer作为特征提取网络对图像进行端对端的训练,最后将由transformer学习的特征送到最后的分类器中,分类器主要是一层全连接层,由两个神经元组成,用以生成目标图像被识别为真与假的概率值;特征提取和分类,从而检测出人脸图像的真假。
47.本实施例基于swin transformer的双流人脸伪造检测方法,在解决现有人脸伪造检测方案的部分局限性即泛化能力弱的问题的同时,还通过双流框架提升模型抗压缩能力,使其更符合日常生活中常见的人脸视频质量。
48.实施例二
49.本实施例与实施例一基本相同,特别之处在于:
50.一种基于swin transformer的双流人脸伪造检测方法,包括以下步骤:
51.(1)准备人脸视频数据集:
52.首先需要准备人脸伪造视频数据集。选择了公共的人脸伪造视频数据集:faceforensics ;faceforensics 数据集是第一个大规模的人脸伪造视频数据集,它利用deepfakes,faceswap,face2face,neuraltextures这四种人脸伪造技术创建了不同类别
的假视频,前两种技术是面部身份替换,后两种是面部表情重建;此数据集还同时对真假视频均进行h.264编码中的c0,c23,c40三种参数压缩,这样做是为了更好地模拟互联网上传播的人脸视频质量,以求更接近于实际生活中使用的人脸视频;
53.(2)将视频裁剪为帧:
54.训练目标是判断人脸图像的真假,因此需要进一步将视频数据集进行处理,首先,对于所有真实或伪造的人脸视频,采用opencv工具库将其划分为不重叠的视频帧,具体做法是每秒截取15帧;
55.(3)提取人脸区域:
56.通过人脸检测器来定位人脸区域,去掉周围大量不相关的背景信息,因为人脸伪造技术只关注人脸,不关注背景区域;本实施例选择的人脸检测器是dlib工具包,对于得到的视频帧,利用dlib可以得到最小的人脸矩形框,再以该人脸框为基准扩大1.3倍作为新的裁剪区域进行保存;
57.(4)数据集的划分:
58.使用上一步得到的人脸区域图片数据集进行训练、验证和测试任务,这里使用了7-2-1的划分方式,训练集占70%,验证集占20%,测试集占10%;使用验证集的好处在于可以更好的选择出最佳的训练模型,以便防止训练过程中过拟合现象的发生;最后的测试集的预测结果作为评判模型的好坏;
59.(5)经双流网络检测人脸图像:
60.为了有效地检测人脸图像是否经过换脸或表情重建等伪造,提出了一种双流网络-rgb流和噪声流;rgb流的输入是原始的rgb图像,用于直接提取原始图像特征,通过对比度差异、不自然边界等找出伪造的痕迹;噪声流的输入是噪声图片,噪声图像是将rgb图像通过srm(steganalysis rich model)卷积核得到的噪声特征图像,srm卷积核常用于隐写分析领域,是专门设计的一种可有效发现图像中真实区域和被伪造区域的噪声间的不一致的卷积核组;
61.(6)特征提取和分类:
62.上述双流网络得到了两种不一样的图像-rgb图像和噪声图像,首先将这两种图像结合起来一起训练,以便学习到更丰富的特征;这里使用swin transformer作为特征提取网络对图像进行端对端的训练,这样可以检测出人脸图像的真假;transformer有其特有的自注意力机制,可以进一步的发现伪造区域与未伪造区域的不同,因此会将重点关注伪造区域,学习到更多有用的特征用于辨别真假;最后将由transformer学习的特征送到最后的分类器中,分类器主要是一层全连接层,由两个神经元组成,用以生成目标图像被识别为真与假的概率值。
63.本实施例使用swin transformer来进行人脸伪造图片的检测,利用transformer特有的自注意力机制来重点关注伪造区域与伪造区域的不同,这个可以有效提高模型网络的泛化能力,并且swin transformer是一种层次化视觉transformer,它可以用作计算机视觉的通用骨干网络,本实施例就是使用它来深层次的提取特征;本实施例采用双流网络,目的在于同时利用rgb图像特征和噪声图片特征来进行学习,这样加强了伪造痕迹的特征信息,可以在一定程度上抵抗压缩,使其能够检测真实生活中出现的人脸图像。本实施例基于swin transformer的双流人脸伪造检测方法。利用深度学习来进行人脸伪造图像的检测。
整体搭建了一个深度学习网络模型,网络模型分为三部分:双流网络、特征提取网络和分类器。由于现在公开的人脸伪造数据集全部是视频,因此首先需要利用opencv将视频裁剪成帧图片。除此之外,由于帧图片包含了大量的背景信息,因此需要利用人脸定位算法将人脸区域裁剪出来。然后将得到的人脸区域图像输入到双流网络和特征提取网络中提取并学习特征。最后将学习到的特征输入到分类器中,进行人脸图像真假的识别。本实施例方法应用于解决现有人脸伪造检测方案的部分局限性——泛化能力弱的问题,同时还通过双流框架提升模型抗压缩能力,使其更符合日常生活中常见的人脸视频质量。
64.实施例三
65.本实施例与上述实施例基本相同,特别之处在于:
66.在本实施例中,一种基于swin transformer的双流人脸伪造检测方法,如图1所示,包括以下步骤:
67.首先需要对视频数据集进行预处理,这里的视频数据集使用的是faceforensics ,这个数据集包含了四个子数据集,分别是基于人脸交换伪造方式的deepfakes和faceswap,以及基于面部表情重建的face2face和neuraltexture,每一个视频子数据集都包含了1000个视频,加上真实的1000个人脸视频,总共有5000个视频,是一个相对庞大的公开视频数据集。为了模拟真实生活场景传播的视频质量,这个faceforensics 数据集还提供了三种不同压缩质量的视频,分别是c0(无压缩),c23(轻度压缩)和c40(重度压缩)。
68.进行视频预处理的步骤主要分为两步,首先是利用视频处理工具库-opencv,将视频剪切成帧图像,以便送到神经网络模型中进行训练,对于每个视频采取了每秒截取15帧,这样可以加大图像数据集。因为帧图像的人脸周围存在大量不相关的背景信息,因此需要利用人脸定位算法得到最小的人脸矩形框,去出不相关的背景信息,再以该人脸框为基准扩大1.3倍作为新的裁剪区域进行保存,作为最后的输入图像。
69.图2所示就是整体网络结构图。模型包括双流网络、特征提取网络和分类器。双流网络主要是rgb流和噪声流,噪声流主要是将原本的rgb图像通过srm(steganalysis rich model)卷积核得到的噪声特征图像,使用srm卷积核可以有效发现人脸图像中真实区域和被伪造区域的噪声间的不一致,可以帮助神经网络模型更好地学习到伪造人脸的特征。特征提取网络使用的是swin transformer,swin transformer是一种新型视觉transformer,它可以用作计算机视觉的通用骨干网络,同时它也是一种层次化视觉transformer,它的设计思想吸取了卷积神经网络的精华,从局部到全局,将transformer设计成逐步扩大感受野的工具。本发明是首先将rgb图像和噪声图像结合在一起,然后对结合的图片进行分块,展平成序列,输入进原始swin transformer模型的编码器encoder部分,利用transformer模型的self-attention(自注意力机制)学习真实区域和伪造区域的不同,让模型重点关注于伪造区域。最后将swin transformer模型学习到的特征输入到分类器中进行分类。分类器主要是接入一个全连接层对图片进行分类,由两个神经元组成,用以生成目标图像被识别为真与假的概率值。
70.本实施例基于swin transformer的双流人脸伪造检测方法,目的在于受启发于现在transformer在cv领域取得的巨大成功以及transformer特有的自注意力机制,利用层次化视觉transformer可以解决现有人脸伪造检测方案的部分局限性,比如泛化能力弱的问题,还有就是本发明提出了双流框架来提升模型一定的抗压缩能力,使其更符合日常生活,
具有较大的实际应用价值。网络分为三部分:双流网络、特征提取网络和分类器。双流网络是将输入的人脸图片经过上下两条流,分别是rgb流和噪声流。噪声流利用人脸图像的噪音特征从而一定程度抵御人脸图像压缩的不良影响。然后将不同的图像信息融合,利用swin transformer从不同维度学习到图像的特征。特征提取网络采用的是新型骨干网络-swin transformer,将融合的图像特征经过transformer特有的自注意力机制,可以发现人脸高级语义特征图片不同区域信息的差别和联系。最后将深层特征信息输入到分类器中,判别人脸图像的真假。
71.上面对本发明实施例结合附图进行了说明,但本发明不限于上述实施例,还可以根据本发明的发明创造的目的做出多种变化,凡依据本发明技术方案的精神实质和原理下做的改变、修饰、替代、组合或简化,均应为等效的置换方式,只要符合本发明的发明目的,只要不背离本发明的技术原理和发明构思,都属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。