1.本发明涉及行人识别技术领域,具体为一种多尺度批量特征丢弃网络的行人重识别方法。
背景技术:
2.行人重识别(person reid),旨在通过多个不重叠的相机检索感兴趣的人。行人重识别在智能视频监控系统、智慧安防和人机交互中有着很多的应用,如搜索犯罪嫌疑人、跨境追踪和轨迹分析等,并逐渐成为维护公共安全和社会稳定的重要手段。因此行人重识别的课题研究意义重大,同时也伴随着挑战。
3.为了消除行人图像中不相关的部分分散注意力,将更多注意力放在行人主体部分,设计了端对端网络(mgn),通过缩小表示区域的区域并作为分类任务来学习局部特征,并且结合全局特征,获得强大的行人特征表示,取得了不错的效果,提出卷积层正则化方法 (dropblock),通过特征映射连续区域内随机丢弃单元,提高了模型的准确性和鲁棒性,提出批处理删除块(bdb)网络,该方法随机丢弃一个批量特征图的某一部分,覆盖输入特征图的语义部分用一种强迫的方式获得局部特征,提出了ibn-net50-a网络架构,能极大提升网络的域自适应能力,对行人重识别识别率提升有明显作用,但是单纯的ibn-net50-a网络并不能解决行人的遮挡和姿势变化问题。
技术实现要素:
4.(一)解决的技术问题
5.针对现有技术的不足,本发明提供了一种多尺度批量特征丢弃网络的行人重识别方法,解决了行人重识别存在的遮挡和姿势变化问题以及目前网络识别率低的缺陷的问题。
6.(二)技术方案
7.为实现以上目的,本发明通过以下技术方案予以实现:一种多尺度批量特征丢弃网络的行人重识别方法。
8.一种多尺度批量特征丢弃网络的行人重识别方法,具体包括如下步骤:
9.s1、利用ibn-net50-a为基础骨干网络提取特征;
10.s2、对最后两层卷积层融合批量特征丢弃方法;
11.s3、拼接不同维度的特征,能够包含更多浅层、深层的有用信息。
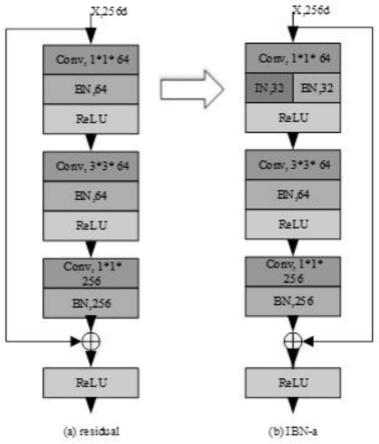
12.优选的,在步骤s1中,ibn包括in和bn,in提取的鲁棒特征是不随一些外观变化而变化的,如颜色、风格、虚拟/真实,bn则是保留与内容相关的信息。
13.优选的,在步骤s1中,ibn-net50-a只在resnet50前面3个group (conv2_x~conv_4-x)中加入in,其他组不变。
14.优选的,在步骤s2中,给定主干网络从一批输入图像计算出的特征图t,批量特征丢弃层随机丢弃相同的特征图t区域,丢弃区域内的所有单位均为零。
15.优选的,在步骤s2中,以ibn-net50-a为基础骨干网络,对最后两层卷积层融合批量特征丢弃方法,以增强局部区域的专注特征学习;
16.对融合批量特征丢弃方法采用全局最大池化,对其他采用全局平均池化,分别采用卷积降维处理,提高网络的学习效率,改进后的行人重识别网络结构主要有骨干网络、卷积层、fd模块、池化层以及全连接层。
17.优选的,ibn-net50-a整体网络由3个部分组成:
18.1)主要负责从模型不同深度提取不同尺度的特征图(f1、f2、 f3),f1的尺度为48
×
16
×
512,f2的尺度为24
×8×
1024,最后一个卷积的步长设为1,f3的尺度为24
×8×
2048;
19.2)对提取到的特征图进行处理,分为4个部分,对f2、f3分别融合批量特征丢弃方法,采用全局最大池化层得到特征向量f2维数为1024,f3维数为2048,强迫网络获得局部细节特征,对f3特征图不做其他处理,采用全局平均池化层得到特征向量ff3维数为2048,最后卷积核为1
×
1的进行降维,其维数进一步减少到512,最后归一化特征进行拼接,以获得最后的特征包含不同层次信息;
20.3)对处理后的特征向量进行分类和度量学习,采用标签平滑损失和三元组损失的联合损失函数进行,不同尺度特征图池化层之后的特征用三元组损失函数,最后全连接层用标签平滑损失函数,测试推理时,则将所有的输出特征拼接起来,然后通过计算欧式距离的方式进行排序。
21.优选的,行人重识别任务中,三元组损失优化过程为针对目标样本和正样本以及负样本之间的距离,使得相同行人(类内)距离更近,不同行人(类间)距离更远。
22.优选的,一个三元组可以被描述为(a,p,n),则三元组损失的思想用欧氏距离形式化表示为式(1),其中,p为行人id数,k为每个行人图片数量,margin表示一个强制间隔;
[0023][0024]
交叉熵损失函数是分类任务常用的损失函数,如式(2)所示,其中n为数据集行人id数,n是行人标签,pi是网络预测该行人属于标签i行人的概率;
[0025][0026]
标签平滑损失函数,如式(3)所示,ε为错误率,则1-ε为真实标签,在本文,设置ε=0.1;
[0027][0028]
全连接层用标签平滑函数优化,如式(4)所示:
[0029][0030]
(三)有益效果
[0031]
本发明提供了一种多尺度批量特征丢弃网络的行人重识别方法。与现有技术相比
具备以下有益效果:
[0032]
以ibn-net50-a为骨干网的改进的网络模型,对最后两层卷积层融合批量特征丢弃方法,以增强局部区域的专注特征学习。采取多尺度特征融合策略,对不同的分支输出的特征图采用不同的池化,提升网络的鲁棒性、学习效率以及识别率。
附图说明
[0033]
图1为本发明ibn模块结构示意图;
[0034]
图2为本发明批量特征丢弃特征处理过程结构示意图;
[0035]
图3为本发明同-batsh不同丢弃方法比较结构示意图;
[0036]
图4为本发明一种多尺度批量特征丢弃网络的行人重识别网络结构结构示意图;
[0037]
图5为本发明三元组损失学习结构示意图。
具体实施方式
[0038]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。一种本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0039]
请参阅图1-5,本发明实施例提供一种技术方案:一种多尺度批量特征丢弃网络的行人重识别方法,具体包括如下步骤:
[0040]
s1、利用ibn-net50-a为基础骨干网络提取特征;
[0041]
具体的,在步骤s1中,ibn是in(instance normalization) 和bn(batch normalization)的精心组合,in提取的鲁棒特征是不随一些外观变化而变化的,如颜色、风格、虚拟/真实等,而bn则是保留与内容相关的信息;它们都有各自的局限性,bn使用一个小批量均值和方差规范每个特征通道,in则使用单个样本统计信息,显而易见,bn在加快训练速度方面有巨大优势。ibn合理地组合使用in和bn,同时提升了学习能力和泛化能力;
[0042]
ibn-net50-a只在resnet50前面3个group(conv2_x~conv_4-x) 中加入in,其他group不变,对于残差块,将第一个卷积输出的前面一半通道用in,后面一半通道用bn,in的添加和bn的精心组合使ibn-net50-a有更好的泛化能力和更健壮的识别能力;
[0043]
s2、对最后两层卷积层融合批量特征丢弃方法;
[0044]
具体的,在步骤s2中,给定主干网络从一批输入图像计算出的特征图t,批量特征丢弃层随机丢弃相同的特征图t区域,丢弃区域内的所有单位均为零,对特征图处理过程如图2所示;
[0045]
丢弃区域的高度和宽度因任务而异,一般来说,矩形区域为丢弃区域,行人重识别中整个宽度为矩形宽部分,与dropblock不同的是,在批量特征丢弃层的训练中不需要改变丢弃概率超参数;
[0046]
以ibn-net50-a为基础骨干网络,对最后两层卷积层融合批量特征丢弃方法,以增强局部区域的专注特征学习,为了提升网络的鲁棒性和融合了批量特征丢弃方法的有效性,对融合批量特征丢弃方法采用全局最大池化,对其他采用全局平均池化,分别采用卷积降维处理,提高网络的学习效率,改进后的行人重识别网络结构主要有骨干网络、卷积层、
fd模块、池化层以及全连接层,fd表示feature dropping;
[0047]
ibn-net50-a整体网络由3个部分组成:
[0048]
1)主要负责从模型不同深度提取不同尺度的特征图(f1、f2、 f3),f1的尺度为48
×
16
×
512,f2的尺度为24
×8×
1024,最后一个卷积的步长设为1,f3的尺度为24
×8×
2048;
[0049]
2)对提取到的特征图进行处理,分为4个部分,对f2、f3分别融合批量特征丢弃方法,采用全局最大池化层得到特征向量f2维数为1024,f3维数为2048,强迫网络获得局部细节特征,此外为了帮助这些融合了fd模块的分支训练,对f3特征图不做其他处理,采用全局平均池化层得到特征向量ff3维数为2048,最后卷积核为1
×
1 的进行降维,其维数进一步减少到512,最后归一化特征进行拼接,这样是为了获得最后的特征包含不同层次信息;
[0050]
3)对处理后的特征向量进行分类和度量学习,采用标签平滑损失和三元组损失的联合损失函数进行,不同尺度特征图池化层之后的特征用三元组损失函数,最后全连接层用标签平滑损失函数,测试推理时,则将所有的输出特征拼接起来,然后通过计算欧式距离的方式进行排序;
[0051]
三元组损失函数一开始是为了人脸识别打造的,由于行人重识别任务的度量学习也被广泛应用,行人重识别任务中,三元组损失优化过程为针对目标样本和正样本以及负样本之间的距离,使得相同行人 (类内)距离更近,不同行人(类间)距离更远,
[0052]
一个三元组可以被描述为(a,p,n),则三元组损失的思想用欧氏距离形式化表示为式(1),其中,p为行人id数,k为每个行人图片数量,margin表示一个强制间隔;
[0053][0054]
交叉熵损失函数是分类任务常用的损失函数,如式(2)所示,其中n为数据集行人id数,n是行人标签,pi是网络预测该行人属于标签i行人的概率;
[0055][0056]
但交叉熵损失函数假设行人标签全部正确,一些行人可能出现错误标签,容易造成训练过拟合的现象,为避免出现这种情况,标签平滑(label smoothing),希望网络能接受少量的错误标签,本文分类损失函数使用标签平滑损失函数,如式(3)所示,ε为错误率,则 1-ε为真实标签。在本文,设置ε=0.1;
[0057][0058]
为了提取更强泛化能力的特征,本文使用三元组损失函数和标签平滑损失函数优化网络。损失函数的不同,最后网络学习提取的特征信息会有较大差别。
[0059]
行人重识别任务既有度量又有分类,因此三元组损失和标签平滑损失被应用到本文,但是,两个损失函数的机理不同,三元组损失函数是减小相同行人之间的欧式距离,增大不同行人之间的欧式距离,标签平滑损失函数是度量两个概率分布之间的不同,是为了分类任务,则他们同时作用一个目标会发生损失函数不下降问题;
[0060]
故本文将特征图池化层之后的特征用三元组损失函数优化,最后全连接层用标签平滑函数优化。故式(4)损失函数应用到本文;
[0061][0062]
s3、拼接不同维度的特征,能够包含更多浅层、深层的有用信息。
[0063]
从表2中看出将基础网络更换为带ibn的resnet50深度网络和批量特征丢弃模块应用到基础的resnet50深度网络中,精度都有相应的提升。其中ibn表示将基础网络resnet50更换成带有 ibnibn-net50-a深度网络,fd表示在网络中嵌入批量特征丢弃模块。
[0064]
对于market1501数据集,通过基础网络添加批量特征丢弃模块的行人重识别精度有一定提升,而将基础网络resnet50更换成 ibn-net50-a深度网络也有提升,其中rank1准确率提升了1.3%,map 提升了2.1%,通过将基础网络更换成ibn-net50-a深度网络和嵌入批量特征丢弃模块效果也有较大提升,其中rank1准确率提升了1.5%, map提升了2.8%;
[0065]
对于dukemtmc-reid数据集,通过将基础网络更换成带有 ibn-net50-a深度网络和嵌入批量特征丢弃模块可以得出rank1准确率提升了1.8%,map提升了2.8%。
[0066]
可视化示例选取了具有遮挡、姿势变化的样本,对于 dukemtmc-reid数据集中给出的样本被行人、车辆和障碍物严重遮挡,而本文通过批量特征丢弃方法迫使网络不仅提取全局特征,也提取出更细节的局部特征如背包、发型等从而正确的匹配出同一个人,可视化结果表明,本文方法对行人重识别存在的遮挡和姿势变化问题以及目前网络识别率低的缺陷适应力较好。
[0067]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
