1.本发明涉及的是数据分析领域,特别涉及一种基于多特征指标的股票趋势预测方法。
背景技术:
2.从行为金融学的角度,大量的研究已经证明了投资者情绪可以影响股票市场。shiller等甚至发现了情绪影响投资者行为是导致1987年10月股市崩盘的主要原因。chaffai等探讨了投资者情感和心理因素对突尼斯股市中影响。从投资收益的角度,有大量的研究证明投资者情绪指数可以用来预测股票的收益。wurgal等研究发现,当初期情绪指标较低时,新股、小盘股、收益较低股、高波动性股票和困境股具有较高的后续收益,并提出了从投资角度预测股票收益率的12项措施。statman等通过研究投资者情绪与股票市场收益之间的关系,发现投资者在市场预测和收益机会方面存在偏差。
3.情绪分析的来源可以是各种社交软件与网络平台,这些软件与平台鼓励用户传播与分享他们对金融证券产品和金融分析结果的情绪,这吸引了大量研究人员挖掘这些数据来预测股票趋势。例如,石善冲和朱颖楠通过对微信的文本挖掘来探究其与上证指数收盘价与成交量的相互关系。kharde等分析twitter数据发现推文中的观点是高度结构化与异构性的,并将这些推文分为正面、负面或中性的。此外,一些学者在探究新闻与股吧评论对股价的影响,甚至尝试利用新闻与股吧评论等舆情信息分类后的结果来构建等权的情绪指数。例如,张琳和张军试图探究宏观经济信息发布对股票市场收益率及其波动的影响。杨娟通过文本处理的技术将互联网财经新闻分为兼并收购类、盈利能力类、再融资类新闻,进而探究其对股票市场的影响。gillam等专注于用分类后的新闻的数量来量化包含在文本数据中的信息,研究发现量化后的情绪指数可以显著的提高收益。nguyen等提出了一个新的特征,叫做“话题情绪指数”,来分析社交网络平台上的公众情绪,以提高股市的预测性能。khan等利用社交媒体评论量和政治新闻文章预测股市走势。ren等提出了一种新颖的投资者情绪特征——每日情绪指数,它是由当日投资者的正面评论和负面评论的数量构建的,以提高股票趋势预测的准确率。但是,现有的研究中对于不同文本之间的权重考虑仍然较少,以及对于网络新闻分类的准则也较为模糊。
技术实现要素:
4.鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的一种基于多特征指标的股票趋势预测方法。
5.为了解决上述技术问题,本技术实施例公开了如下技术方案:
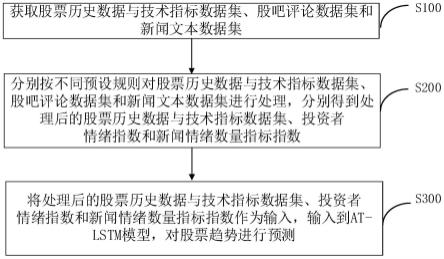
6.一种基于多特征指标的股票趋势预测方法,包括:
7.s100.获取股票历史数据与技术指标数据集、股吧评论数据集和新闻文本数据集;
8.s200.分别按不同预设规则对股票历史数据与技术指标数据集、股吧评论数据集和新闻文本数据集进行处理,分别得到处理后的股票历史数据与技术指标数据集、投资者
情绪指数和新闻情绪数量指标指数;
9.s300.将处理后的股票历史数据与技术指标数据集、投资者情绪指数和新闻情绪数量指标指数作为输入,输入到at-lstm模型,对股票趋势进行预测。
10.进一步地,s200中,对股票历史数据与技术指标数据集进行处理的预设规则为:对股票历史数据与技术指标数据集进行标准化和归一化处理后,得到处理后的股票历史数据与技术指标数据集。
11.进一步地,s200中,对股吧评论数据集进行处理的预设规则为:对股吧评论数据集进行预处理和情感表征,“非结构化数据”放入情感分析模型得到“结构化数据”,之后再将结构化数据放入“股票趋势预测模型”预测股票趋势。
12.进一步地,s200中,对新闻文本数据集进行处理的预设规则为:根据预设新闻的分类准则对新闻文本数据集进行判断,并根据判断结果对新闻文本数据集进行分析,得到各类新闻情绪数量指标。
13.进一步地,对股吧评论数据集进行预处理,具体包括:将股吧评论数据集中与股票无关的信息进行删除,包括url、html、代码、注释、广告和其他标记,然后通过区分标点符号,将每篇评论分割成若干个句子,完成中文词语的分段,最后删除中文停用字。
14.进一步地,构建加权情绪指数的公式为:
[0015][0016]
其中,s
t
为t日的加权情绪指数,n为t日的评论数量,ai为第i条评论的阅读数量,为每条评论的权重;ki的取值为-1、1与0分别表示该文本为消极、积极与中性;s
t
的取值范围始终是在-1到1,其中0表示人们持中性态度,如果s
t
大于0,则代表市场上的投资者多是持有积极的态度,否则投资者情绪持有消极的态度。
[0017]
进一步地,改进后的情绪指数公式为:
[0018]smodified-t
=e-2st-2
e-1st-1
e-0st
[0019][0020]
其中,st是股票市场过去价格加权平均值,t是积分变量,随着时间的推移,st的权重指数进一步下降;参数β决定了过去价格对现在的影响,当参数β较高时,市场情绪由最近的价格变化决定;s
modified
表示每个星期一改进后的情绪指数,st-2代表着周六的加权情绪值,st-1代表着周日的加权情绪值。
[0021]
进一步地,对新闻文本数据集进行处理,包括将新闻文本数据集进行分类,分为融资类新闻、财务类新闻和高管类新闻。
[0022]
进一步地,at-lstm模型由lstm层、dropout层、自注意力层以及全连接层组成;输入t天的目标股票特征数据,先经过lstm层顺序提取t天股票数据的时间序列特征,其中lstm的层数n通过实验调参确定;每层后面加入dropout层,通过随机删除一些神经元,防止模型过拟合;自注意力层进行序列间潜在关系的学习,通过对输入的滞后交易日数据之间的比较计算注意力分布概率,捕获数据之间的联系,突出输入中重要交易日特征数据的影响作用,自注意力机制可以进行并行运算,加快运算速度,最后添加全连接层输出预测值。
[0023]
本发明实施例提供的上述技术方案的有益效果至少包括:
[0024]
本发明公开的一种基于多特征指标的股票趋势预测方法,包括:获取股票历史数
据与技术指标数据集、股吧评论数据集和新闻文本数据集;分别按不同预设规则对股票历史数据与技术指标数据集、股吧评论数据集和新闻文本数据集进行处理,分别得到处理后的股票历史数据与技术指标数据集、投资者情绪指数和新闻情绪数量指标指数;将处理后的股票历史数据与技术指标数据集、投资者情绪指数和新闻情绪数量指标指数作为输入,输入到at-lstm模型,对股票趋势进行预测。本发明针对股票趋势预测难题,通过skep情感分析技术,提出了加权情绪指数的构建方法,并制定了新闻分类的准则,提升了现阶段股票趋势预测的准确率。
[0025]
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
[0026]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0027]
图1为本发明实施例1中,一种基于多特征指标的股票趋势预测方法的流程图;
[0028]
图2为本发明实施例1中,一种基于多特征指标的股票趋势预测方法的详细流程框图。
具体实施方式
[0029]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
[0030]
为了解决现有技术中存在的问题,本发明实施例提供一种基于多特征指标的股票趋势预测方法。
[0031]
实施例1
[0032]
本实施例公开了一种基于多特征指标的股票趋势预测方法,如图1,包括:
[0033]
s100.获取股票历史数据与技术指标数据集、股吧评论数据集和新闻文本数据集;具体的,如图2,本实施例是基于多特征体系进行股票趋势预测,可以将所有的特征分为金融市场与投资者情绪两个方面。根据特征的结构化程度,金融市场方面的数据作为结构化特征,具体包括股票价格数据与技术指标数据;投资者情绪作为非结构化特征,具体包括新闻文本数据与股吧文本数据。
[0034]
s200.分别按不同预设规则对股票历史数据与技术指标数据集、股吧评论数据集和新闻文本数据集进行处理,分别得到处理后的股票历史数据与技术指标数据集、投资者情绪指数和新闻情绪数量指标指数;
[0035]
具体的,对股票历史数据与技术指标数据集进行处理的预设规则为:对股票历史数据与技术指标数据集进行标准化和归一化处理后,得到处理后的股票历史数据与技术指标数据集。在金融市场方面,本专利使用的股票的历史数据包括:开盘价、收盘价、最高价、最低价、成交量、换手率、市盈率与市净率等,以及常用技术指标:kdj、dmi、bias、bbi、wr等,其中的股票基本指标与技术指标数据来源于wind金融数据库。
[0036]
在本实施例中,对股吧评论数据集进行处理的预设规则为:对股吧评论数据集进
行预处理和情感表征,将非结构化的文本信息转换为结构化的信息,将这些结构化的数据放入情感分析模型中,得到所需的情感数据集,构建加权情绪指数和改进的情绪指数,得到投资者情绪指数。具体的,对股吧评论数据集进行预处理,具体包括:将股吧评论数据集中与股票无关的信息进行删除,包括url、html、代码、注释、广告和其他标记,然后通过区分标点符号,将每篇评论分割成若干个句子,完成中文词语的分段,最后删除中文停用字。例如,句子“我不满意这股票(i’m not satisfied with this stock)”可以被分割成五个词,包括:“我”,“不”,“满意”,“这”与“股票”。如果我们把这些词直接放入情感向量空间里。句子会被认为是乐观的,因为有"满意"这个褒义词。因此,我们应该把"不"和"满意"视为一个整体"不满意"。
[0037]
在本实施例中,构建加权情绪指数的公式为:
[0038][0039]
其中,s
t
为t日的加权情绪指数,n为t日的评论数量,ai为第i条评论的阅读数量,为每条评论的权重;ki的取值为-1、1与0分别表示该文本为消极、积极与中性;s
t
的取值范围始终是在-1到1,其中0表示人们持中性态度,如果s
t
大于0,则代表市场上的投资者多是持有积极的态度,否则投资者情绪持有消极的态度。
[0040]
在本实施例中,改进后的情绪指数公式为:
[0041]smodified-t
=e-2st-2
e-1st-1
e-0st
[0042][0043]
其中,st是股票市场过去价格加权平均值,t是积分变量,随着时间的推移,st的权重指数进一步下降;参数β决定了过去价格对现在的影响,当参数β较高时,市场情绪由最近的价格变化决定;s
modified
表示每个星期一改进后的情绪指数,st-2代表着周六的加权情绪值,st-1代表着周日的加权情绪值。
[0044]
在本实施例中,对新闻文本数据集进行处理的预设规则为:根据预设新闻的分类准则对新闻文本数据集进行判断,并根据判断结果对新闻文本数据集进行分析,得到各类新闻情绪数量指标。对新闻文本数据集进行处理,包括将新闻文本数据集进行分类,分为融资类新闻、财务类新闻和高管类新闻。具体的新闻文本分类准则如表一所示。
[0045]
表一
[0046][0047]
s300.将处理后的股票历史数据与技术指标数据集、投资者情绪指数和新闻情绪数量指标指数作为输入,输入到at-lstm模型,对股票趋势进行预测。
[0048]
在本实施例中,at-lstm模型由lstm层、dropout层、自注意力层以及全连接层组成;输入t天的目标股票特征数据,先经过lstm层顺序提取t天股票数据的时间序列特征,其中lstm的层数n通过实验调参确定;每层后面加入dropout层,通过随机删除一些神经元,防止模型过拟合;自注意力层进行序列间潜在关系的学习,通过对输入的滞后交易日数据之间的比较计算注意力分布概率,捕获数据之间的联系,突出输入中重要交易日特征数据的影响作用,自注意力机制可以进行并行运算,加快运算速度,最后添加全连接层输出预测值。
[0049]
本实施例公开的一种基于多特征指标的股票趋势预测方法,包括:获取股票历史数据与技术指标数据集、股吧评论数据集和新闻文本数据集;分别按不同预设规则对股票历史数据与技术指标数据集、股吧评论数据集和新闻文本数据集进行处理,分别得到处理后的股票历史数据与技术指标数据集、投资者情绪指数和新闻情绪数量指标指数;将处理后的股票历史数据与技术指标数据集、投资者情绪指数和新闻情绪数量指标指数作为输入,输入到at-lstm模型,对股票趋势进行预测。本发明针对股票趋势预测难题,通过skep情感分析技术,提出了加权情绪指数的构建方法,并制定了新闻分类的准则,提升了现阶段股票趋势预测的准确率。
[0050]
应该明白,公开的过程中的步骤的特定顺序或层次是示例性方法的实例。基于设计偏好,应该理解,过程中的步骤的特定顺序或层次可以在不脱离本公开的保护范围的情况下得到重新安排。所附的方法权利要求以示例性的顺序给出了各种步骤的要素,并且不是要限于所述的特定顺序或层次。
[0051]
在上述的详细描述中,各种特征一起组合在单个的实施方案中,以简化本公开。不应该将这种公开方法解释为反映了这样的意图,即,所要求保护的主题的实施方案需要清楚地在每个权利要求中所陈述的特征更多的特征。相反,如所附的权利要求书所反映的那样,本发明处于比所公开的单个实施方案的全部特征少的状态。因此,所附的权利要求书特
此清楚地被并入详细描述中,其中每项权利要求独自作为本发明单独的优选实施方案。
[0052]
本领域技术人员还应当理解,结合本文的实施例描述的各种说明性的逻辑框、模块、电路和算法步骤均可以实现成电子硬件、计算机软件或其组合。为了清楚地说明硬件和软件之间的可交换性,上面对各种说明性的部件、框、模块、电路和步骤均围绕其功能进行了一般地描述。至于这种功能是实现成硬件还是实现成软件,取决于特定的应用和对整个系统所施加的设计约束条件。熟练的技术人员可以针对每个特定应用,以变通的方式实现所描述的功能,但是,这种实现决策不应解释为背离本公开的保护范围。
[0053]
结合本文的实施例所描述的方法或者算法的步骤可直接体现为硬件、由处理器执行的软件模块或其组合。软件模块可以位于ram存储器、闪存、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、移动磁盘、cd-rom或者本领域熟知的任何其它形式的存储介质中。一种示例性的存储介质连接至处理器,从而使处理器能够从该存储介质读取信息,且可向该存储介质写入信息。当然,存储介质也可以是处理器的组成部分。处理器和存储介质可以位于asic中。该asic可以位于用户终端中。当然,处理器和存储介质也可以作为分立组件存在于用户终端中。
[0054]
对于软件实现,本技术中描述的技术可用执行本技术所述功能的模块(例如,过程、函数等)来实现。这些软件代码可以存储在存储器单元并由处理器执行。存储器单元可以实现在处理器内,也可以实现在处理器外,在后一种情况下,它经由各种手段以通信方式耦合到处理器,这些都是本领域中所公知的。
[0055]
上文的描述包括一个或多个实施例的举例。当然,为了描述上述实施例而描述部件或方法的所有可能的结合是不可能的,但是本领域普通技术人员应该认识到,各个实施例可以做进一步的组合和排列。因此,本文中描述的实施例旨在涵盖落入所附权利要求书的保护范围内的所有这样的改变、修改和变型。此外,就说明书或权利要求书中使用的术语“包含”,该词的涵盖方式类似于术语“包括”,就如同“包括,”在权利要求中用作衔接词所解释的那样。此外,使用在权利要求书的说明书中的任何一个术语“或者”是要表示“非排它性的或者”。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
