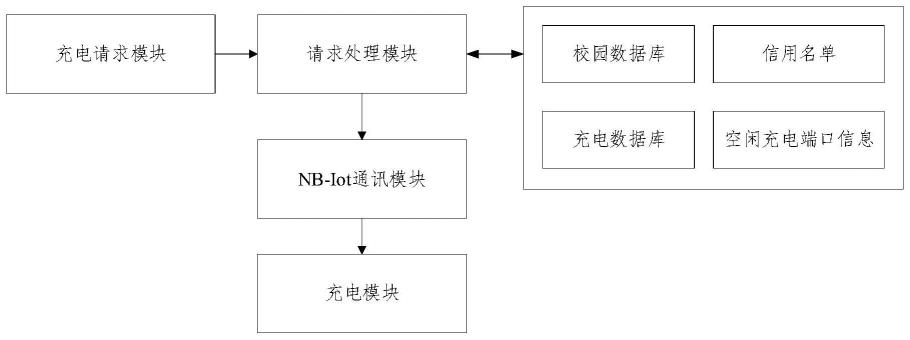
1.本发明涉及人工智能语音识别领域,具体涉及一种基于深度学习的脸部视频合成方法。
背景技术:
2.人脸合成由于其应用与技术价值,是机器视觉领域的热点之一,人脸合成领域具有很高的活跃度,且伴随着近年来深度学习技术的突破性进展,这一类技术也经历着飞速的发展,在隐私保护、影视动画、娱乐商用等各个领域得到了广泛的应用。
3.逼真的人脸合成技术可以以较低的成本实现翻拍或补拍视频片段,或者配音等工作。还有一些视频借助这类技术合成老年或年轻版本的演员,节省了拍摄成本。当视频中需要呈现高危险性的特技镜头时,通过这类技术合成高质量的面部图像,不仅能够保证任务的人身安全,还避免了使用昂贵的特效带来的额外成本。
4.目前各类脸部视频合成的方式大多采用人工进行图像处理,通过对图片和视频中的人脸进行替换和修图,获得合成图像和视频。这种方式需要投入大量的人力物力,处理速度也很慢,无法更上现今短视频行业的发展。因此,采用基于深度学习的人工智能的处理方法,能极大减少图片和视频的处理难度,提高脸部合成视频的处理效率。
技术实现要素:
5.针对现有技术的不足,本发明提供了一种基于深度学习的脸部视频合成方法,采用改进的stylegan2模型,生成的图像质量明显更好。采用asm算法,不仅能有效地定位目标脸部的外部轮廓形状,也可以有效地提取和定位目标脸部的内部轮廓信息,可以使目标脸部定位更加精准。
6.为实现以上目的,本发明通过以下技术方案予以实现:
7.一种基于深度学习的脸部视频合成方法,该方法包括如下步骤:
8.s1.获取脸部合成的源图片和驱动视频,保存在原始素材库中,以第一的一张脸部照片作为源图片,以第二人物进行脸部动作的视频作为驱动视频,用驱动视频中第二人物的面部动作驱动源图片中的第一人物动起来,将第一人物的脸部合成到第二人物身体上;
9.s2.对源图片和驱动视频进行数据处理;
10.s3.搭建stylegan2模型,并对模型进行优化;
11.s4.对stylegan2模型进行训练;
12.s5.将第一人物的脸部图片样本和帧图片,输入stylegan2模型进行脸部融合处理;
13.s6.将目标脸部图片数据集合帧为视频。
14.进一步地,步骤s1的具体方法为:
15.s11.从图片库中获取一张包含了第一人物完整脸部的图片,这张图片上的脸部图像就为将要合成到视频中的目标脸部,定义的7种面部手势分别是:左眼睁开右眼睁开嘴巴
张开、左眼睁开右眼闭上嘴巴张开、左眼睁开右眼闭上嘴巴闭上、左眼闭上右眼睁开嘴巴张开、左眼闭上右眼睁开嘴巴闭上、左眼闭上右眼闭上嘴巴张开、左眼闭上右眼闭上嘴巴闭上;
16.s12.获取用于合成的驱动视频:从视频库中获取第二人物演讲视频,将视频截取成一段时长为1分钟的驱动视频,这个视频中将包含要使用的实际脸部外观;
17.s13.将获取到的源图片及驱动视频进行保存,存储在原始素材库中。
18.进一步地,步骤s2的具体方法为:
19.s21.对源图片进行处理,调整图片尺寸,进行图像增强,具体是将源图片采用图片处理工具,按照深度学习模型的图片输入尺寸进行调整,将图片尺寸大小调整为256x256;以源图片中第一人物的脸部双眉中间点为图片中心点,对图片进行原比例缩放,当源图片的高或者宽其中一项的长度缩小到256时,则停止缩放操作;采用256x256的正方形框选住缩放后的源图片,对超出正方形范围的图片部分进行裁剪,最终得到裁剪后的第一人物的脸部图片样本;
20.再对裁剪处理后的图片样本进行图片增强,具体是采用彩色图像的增强技术,通过先将彩色图像转换成灰度图像,然后对灰度图像进行直方图均衡化的处理,最后再将经过处理之后得到增强效果的灰度图像还原成彩色图像,并保存在样本图片文件夹中;
21.s22.对视频进行处理,逐帧提取图片,具体是将驱动视频进行缩放裁剪至256x256的尺寸大小,将视频缩放到合适大小,将人脸放置在256x256的虚线选框中央进行裁剪,输出裁剪完成的驱动视频样本;
22.采用opencv2进行视频逐帧提取,获取视频样本文件,获取视频总帧数,读取视频每一帧,设置每帧都获取一次,将帧转化成图片输出,设置保存帧图片的路径,将帧图片存储在保存在样本图片文件夹。
23.进一步地,步骤s3所述的搭建stylegan2模型,并对模型进行优化,具体是在stylegan2模型中,adain被重构为weight demodulation,采用递次演进的训练方法,即先训一个小分辨率的图像,训好了之后再逐步过渡到更高分辨率的图像,然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率;对数据分布开始跑偏的时候才使用r1regularization,其它时候不使用,并对路径长度正则化。
24.进一步地,步骤s4具体方法是:
25.s41.随机生成一批潜码latents,通过生成器g得到一批假图像fake_images_out;
26.s42.再从训练数据集中取一部分真实图像reals;
27.s43.将真、假图像分别交给判别器d去计算得分,并计算这些得分的全局交叉熵,假图像判别为假的概率的对数与真图像判别为真的概率的对数之和的相反数,把全局交叉熵与正则化项求和作为判别器d的损失函;
28.s44.生成器g的损失函数则只考虑它自身的交叉熵,假图像判别为真的概率的对数的相反数,再与感知路径长度正则化项求和作为生成器g的损失函数;
29.s45.优化的过程就是通过梯度下降,使得d和g的损失函数取得最小值。
30.进一步地,步骤s5的具体方法是:
31.s51.从存储样本图片的文件中获取第一人物的脸部图片样本,然后再从步骤s22得到的图片文件夹中获取的首帧图片样本,首帧图片样本中包含第二人物的脸部图像;
32.s52.采用asm算法将第一人物的脸部图片样本和首帧图片样本中的脸部进行对齐,所述asm是指主观形状模型,即通过形状模型对目标物体进行抽象,asm算法分为训练过程和搜索过程:
33.在训练的阶段:构建各个特征点的位置约束,构建各个特征点的局部特征;
34.在搜索的阶段:迭代到对应的特征点,首先计算眼睛或者嘴巴的位置,做尺度和旋转变化,对齐人脸;接着,在对齐后的各个点附近搜索,匹配每个局部关键点,得到初步形状;再用平均人脸修正匹配结果;迭代直到收敛;
35.s53.将脸部对齐后第一人物的脸部图片样本与帧图像输入输入stylegan2模型中,通过脸部特征融合,将第一人物的脸部融合到帧图像中的第二人物的脸部位置,输出融合完成的目标脸部图片,将目标脸部图片进行保存。
36.s54.按照以上步骤对步骤s22得到的图片文件夹中剩余的部分,进行批量融合处理,得到目标脸部图片数据集。
37.进一步地,步骤s6的具体方法是:
38.s61.从数据集中获取全部目标脸部图片,每张图片为1帧,第一帧开始一帧一帧的按顺序获取,将每帧图片作为参数传进opencv网络;
39.s62.设置视频名称,帧率为30,视频尺寸为256x256;
40.s63.调用write()直到遍历到最后一帧图片结束,此时输出新生成的目标脸部视频将在文件夹中输出;
41.s64.得到最终的脸部合成视频。
42.有益效果:
43.1.本发明采用改进的stylegan2模型,生成的图像质量明显更好(fid分数更高、artifacts减少);提出替代progressive growing的新方法,牙齿、眼睛等细节更完美;更平滑的插值(额外的正则化);训练速度更快。
44.2.本发明采用asm算法,不仅能有效地定位目标脸部的外部轮廓形状,也可以有效地提取和定位目标脸部的内部轮廓信息。最大的优点是能产生一个可变的模型实例,通过改变形状参数得到在一定范围内变化的统计模型实例。模型中的形状参数在一定范围内的变化,可以使目标脸部定位更加精准。在脸部对齐中起到关键左右,将双眼、鼻尖、双嘴角(共五点)校准至同一位置,为人脸合成的预处理环节。
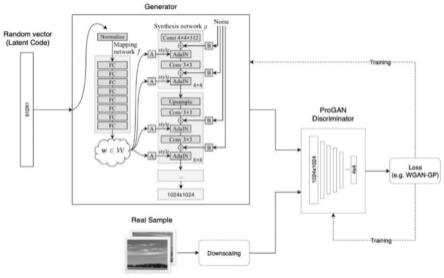
45.3.本发明通过直方图均衡化实现了图片样本的增强,提高了脸部图像的清晰度和亮度。
附图说明
46.图1为stylegan网络结构;
47.图2为stylegan2新的网络结构;
48.图3为asm算法脸部关键特征点。
具体实施方式
49.本实施例的基于深度学习的脸部视频合成方法,该方法包括如下步骤:
50.步骤s1,获取脸部合成的源图片和驱动视频,保存在原始素材库中。
51.以第一的一张脸部照片作为源图片,以第二人物进行脸部动作的视频作为驱动视频,用驱动视频中第二人物的面部动作驱动源图片中的第一人物动起来,将第一人物的脸部合成到第二人物身体上。
52.s11.获取脸部合成的目标源图片
53.从图片库中获取一张包含了第一人物完整脸部的图片,这张图片上的脸部图像就为将要合成到视频中的目标脸部。这张图片上的脸部图像要清晰可见,包含想要从中获取一些面部手势的脸部。在正常情况下,人的左眼和右眼分别有两种状态睁开和闭上。嘴巴也有两种状态:张开嘴和闭上嘴巴。按照排列和组合原理,我们能定义的面部手势共有2
×2×
2=8种。这8种状态分别是:左眼睁开右眼睁开嘴巴张开、左眼睁开右眼睁开嘴巴闭上、左眼睁开右眼闭上嘴巴张开、左眼睁开右眼闭上嘴巴闭上、左眼闭上右眼睁开嘴巴张开、左眼闭上右眼睁开嘴巴闭上、左眼闭上右眼闭上嘴巴张开、左眼闭上右眼闭上嘴巴闭上。然而在正常情况下,我们的脸部状态是左边的眼睛和右边的眼睛都睁开,嘴巴处于闭合状态,同时遵守手势设计原则的可靠性,因此我们将这种情况去除掉。因为我们能够定义并且识别的面部手势共有7种。
54.s12.获取用于合成的驱动视频
55.从视频库中获取第二人物演讲视频,将视频截取成一段时长为1分钟的驱动视频,这个视频中将包含要使用的实际脸部外观。
56.s13.将获取到的源图片及驱动视频进行保存
57.将从图片库及视频库中获取到的第一人物源图片及第二人物驱动视频进行保存,存储在原始素材库中。
58.步骤s2,对源图片和驱动视频进行数据处理。
59.s21.对源图片进行处理,调整图片尺寸,进行图像增强
60.将源图片采用图片处理工具,按照深度学习模型的图片输入尺寸进行调整,将图片尺寸大小调整为256x256。以源图片中第一人物的脸部双眉中间点为图片中心点,对图片进行原比例缩放,当源图片的高或者宽其中一项的长度缩小到256时,则停止缩放操作。采用256x256的正方形框选住缩放后的源图片,对超出正方形范围的图片部分进行裁剪,最终得到裁剪后的第一人物的脸部图片样本。
61.对裁剪处理后的图片样本进行图片增强。采用彩色图像的增强技术,通过先将彩色图像转换成灰度图像,然后对灰度图像进行直方图均衡化的处理,最后再将经过处理之后得到增强效果的灰度图像还原成彩色图像,并保存在样本图片文件夹中。
62.将直方图均衡用到hsi色彩空间的i分量上,直方图对亮度分量进行均衡。是图像在亮度上得到增强。在饱和度和色向上保持不变。原理就是利用hsi色彩空间的特点,i分量代表图像亮度。处理后不会改变图像色相。
63.将图片样本从rgb转换到hsi;分离hsi空间,i分量形成一个单独的灰度图像;对灰度图像进行直方图均衡;用均衡后的数据取代原i分量数据;hsi转换回rgb,均衡化后分量图像还原输出图片样本。通过直方图均衡化实现了图片样本的增强,提高了脸部图像的清晰度和亮度。
64.s22.对视频进行处理,逐帧提取图片。
65.将驱动视频进行缩放裁剪至(256x256)的尺寸大小,将视频缩放到合适大小,将人
脸放置在(256x256)的虚线选框中央进行裁剪,输出裁剪完成的驱动视频样本。
66.采用opencv2进行视频逐帧提取,获取视频样本文件,获取视频总帧数。视频的帧数一般都是30帧/秒,视频样本文件的时长为1分钟,则视频总帧数为30x60帧,即1800帧。读取视频每一帧,设置每帧都获取一次,将帧转化成图片输出,设置保存帧图片的路径,将帧图片存储在保存在样本图片文件夹,得到1800张帧图片,帧图片中包含第二人物脸部图像。
67.步骤s3,搭建stylegan2模型,并对模型进行优化。
68.stylegan首先使用mapping network将输入向量编码为中间变量w进行特征解缠,然后中间变量传给生成网络得到18个控制变量,使得该控制变量的不同元素能够控制不同的视觉特征。视觉特征可以简单分为三种:(1)粗糙的——分辨率不超过82,影响姿势、一般发型、面部形状等;(2)中等的——分辨率为162至322,影响更精细的面部特征、发型、眼睛的睁开或是闭合等;(3)高质的——分辨率为642到10242,影响颜色(眼睛、头发和皮肤)和微观特征;它在诸多不同数据集上的结果都比较稳定,只是生成的图像有时会出现水滴状的伪影。
69.针对水滴状的伪影这个缺陷,stylegan2重点修复artifacts问题,并进一步提高了生成图像的质量,如图2所示,图2中:(a)为stylegan原版,(b)为stylegan拆分adain模块:实例归一化和style调制,(c)为去掉对均值的操作(归一化和调制),修改添加噪声【b】的位置。(d)为从对特征图的修改,改为对卷积权重的修改。归一化改为demodulation。
70.如图2中(a)显示的是原始的stylegan合成网络,其中a表示从w学习的仿射变换,产生样式向量,而b表示噪声广播操作。如图2中(b)是如图2中(a)的细节描述,将adain操作分为了两个部分,分别是归一化部分和调制部分,以此将特征图扩展为完整细节。原始stylegan在样式块内添加了偏置和噪音,使它们的相对影响与当前样式大小成反比。如果将添加偏置和噪音的操作移到风格块外,可以得到更多可预测的结果,并且不再需要均值仅仅计算标准偏差就够了,这样的设计架构如图2中(c)所示。
71.stylegan2的主要改进:
72.生成的图像质量明显更好(fid分数更高、artifacts减少;提出替代progressive growing的新方法,牙齿、眼睛等细节更完美;改善了style-mixing;更平滑的插值(额外的正则化);训练速度更快。
73.改进详述:
74.1.weight demodulation
75.在stylegan2中,adain被重构为weight demodulation,如图2中网络结构所示
76.adain层的含义:同bn层类似,其目的是对网络中间层的输出结果进行scale和shift,以增加网络的学习效果,避免梯度消失。相对于bn是学习当前batch数据的mean和variance,instance norm则是采用了单张图片。adain则是使用learnable的scale和shift参数去对齐特征图中的不同位置。
77.weight demodulation的处理流程如下:
78.(1)如图2里面的(c)所示,conv 3x3后面的mod std被用于对卷积层的权重进行scaling(缩放),这里的iii表示第iii个特征图。
79.w
′
ijk
=si×wijk
80.(2)接着对卷积层的权重进行demod
[0081][0082]
那么,得到新的卷积层权重为:
[0083][0084]
加一个小的∈是为了避免分母为0,保证数值稳定性。尽管这种方式与instance norm并非在数学上完全等价,但是weight demodulation同其它normalization方法一样,使得输出特征图有着standard的unit和deviation。
[0085]
此外,将scaling参数挪为卷积层的权重使得计算路径可以更好的并行化。
[0086]
2.progressive growth(递次演进)
[0087]
progressive growing指的是:先训一个小分辨率的图像,训好了之后再逐步过渡到更高分辨率的图像。然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率。
[0088]
stylegan2开始寻求其它的设计以便于让网络更深,并有着更好的训练稳定性。stylegan2采用了类似resnet的残差连接结构(residual block),stylegan2设计了一个新的架构来利用图像生成的多个尺度信息,他们通过一个resnet风格的跳跃连接在低分辨率的特征映射到最终生成的图像。
[0089]
3.lazy regularization(正则化)
[0090]
stylegan1对ffhq数据集使用了r1正则化。实验结果表明,在评估计算代价的时候,regularization是可以忽略的。实际上,即使每隔16个mini-batch使用regularization的方式,模型效果依旧很不错,因此,在stylegan2中,我们可以使用lazy regularization的策略,即对数据分布开始跑偏的时候才使用r1 regularization,其它时候不使用。
[0091]
4.路径长度正则化
[0092]
路径长度正则化的意义是使得latent space的插值变得更加smooth和线性。
[0093]
无论w或图像空间方向如何,这些渐变应具有接近等长度,即小位移产生相同大小的变化。表示从潜在空间到图像空间的映射是良好的。路径长度正则化不但提高了图片的生成质量,而且使得生成器更平滑,生成的图片反转回latent code更容易了。
[0094]
步骤s4,对stylegan2模型进行训练
[0095]
stylegan2本质上是通过假图像生成器generator与真图像判别器discrimnator之间的对抗,最终使判别器无法判别真假(对于由假图像和真图像共同组成的数据集,判别器给出正确标签的概率为50%)。其过程表现为两个神经网络的权重和偏置不断调整,使得对于生成器生成的假图像,判别器判别为假的概率最小,即:生成器神经网络的运算矩阵所表达的特征期望平均值(度量标准包括:fid、ppl、lpips等)逼近真实图像样本的平均值,且特征期望方差为最小;同时判别器对真假图像的混合数据集能给出正确标签(即:判定真图像为真,假图像为假)的概率最大。
[0096]
过程大致是这样的:
[0097]
s41.随机生成一批(minibatch_size)潜码latents,通过生成器g得到一批假图像fake_images_out;
[0098]
s42.再从训练数据集中取一部分(minibatch)真实图像reals;
[0099]
s43.将真、假图像分别交给判别器d去计算得分(即:判定为真的概率,分别为real_scores_out和fake_scores_out),并计算这些得分的全局交叉熵(-log(1-sigmoid(fake_scores_out))-log(sigmoid(real_scores_out)))——假图像判别为假的概率的对数与真图像判别为真的概率的对数之和的相反数,把全局交叉熵与正则化项求和作为判别器d的损失函数;
[0100]
s44.同时,生成器g的损失函数则只考虑它自身的交叉熵(-log(sigmoid(fake_scores_out)))——假图像判别为真的概率的对数的相反数,再与ppl(感知路径长度)正则化项求和作为生成器g的损失函数;
[0101]
s45.优化的过程就是通过梯度下降,使得d和g的损失函数取得最小值。
[0102]
步骤s5,将第一人物的脸部图片样本和帧图片,输入stylegan2模型进行脸部融合处理。
[0103]
s51.获取第一人物的脸部图片样本和帧图片
[0104]
从存储样本图片的文件中获取第一人物的脸部图片样本,然后再从1800张帧图片中获取的首帧图片样本。首帧图片样本中包含第二人物的脸部图像。
[0105]
s52.采用asm算法将第一人物的脸部图片样本和首帧图片样本中的脸部进行对齐。
[0106]
asm(active shape model)是指主观形状模型,即通过形状模型对目标物体进行抽象。asm是一种基于点分布模型(point distribution model,pdm)的算法。在pdm中,外形相似的物体,例如人脸的几何形状可以通过若干关键特征点(landmarks)的坐标依次串联形成一个形状向量来表示。基于asm的人脸通常通过标定好的68个关键特征点来进行描述,asm算法分为训练过程和搜索过程。
[0107]
在训练的阶段:主要是构建各个特征点的位置约束,构建各个特征点的局部特征
[0108]
在搜索的阶段:主要是迭代到对应的特征点。计算眼睛(或者嘴巴)的位置,做简单的尺度和旋转变化,对齐人脸;接着,在对齐后的各个点附近搜索,匹配每个局部关键点(常采用马氏距离),得到初步形状;再用平均人脸(形状模型)修正匹配结果;迭代直到收敛。
[0109]
如图3所示,图中白色的点就是上面所说的关键特征点,标记出来关键特征点的目的是在人脸检测的基础上,进一步能够确定人力各个脸部特征的具体位置的。
[0110]
(3)将脸部对齐后的图片样本输入stylegan2模型进行脸部融合处理,得到融合图像。
[0111]
将脸部对齐后第一人物的脸部图片样本与帧图像输入输入stylegan2模型中,通过脸部特征融合,将第一人物的脸部融合到帧图像中的第二人物的脸部位置,输出融合完成的目标脸部图片,将目标脸部图片进行保存。
[0112]
(4)按照以上步骤对1800张帧图片中剩余的部分,进行批量融合处理,得到目标脸部图片数据集。
[0113]
步骤s6,将目标脸部图片数据集合帧为视频。
[0114]
从数据集中获取1800张目标脸部图片,通过opencv合帧为视频输出。
[0115]
每张图片为1帧,第一帧开始一帧一帧的按顺序获取,将每帧图片作为参数传进网络。
[0116]
设置视频名称,帧率为30,视频尺寸为256x256
[0117]
调用write()直到遍历到最后一帧图片结束,此时输出新生成的目标脸部视频将在文件夹中输出。
[0118]
(4)得到最终的脸部合成视频。
[0119]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。