技术特征:
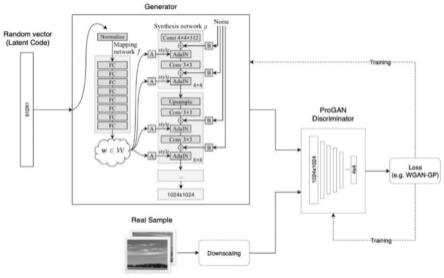
1.一种基于深度学习的脸部视频合成方法,其特征在于,该方法包括如下步骤:s1.获取脸部合成的源图片和驱动视频,保存在原始素材库中,以第一的一张脸部照片作为源图片,以第二人物进行脸部动作的视频作为驱动视频,用驱动视频中第二人物的面部动作驱动源图片中的第一人物动起来,将第一人物的脸部合成到第二人物身体上;s2.对源图片和驱动视频进行数据处理;s3.搭建stylegan2模型,并对模型进行优化;s4.对stylegan2模型进行训练;s5.将第一人物的脸部图片样本和帧图片,输入stylegan2模型进行脸部融合处理;s6.将目标脸部图片数据集合帧为视频。2.根据权利要求1所述的一种基于深度学习的脸部视频合成方法,其特征在于,步骤s1的具体方法为:s11.从图片库中获取一张包含了第一人物完整脸部的图片,这张图片上的脸部图像就为将要合成到视频中的目标脸部,定义的7种面部手势分别是:左眼睁开右眼睁开嘴巴张开、左眼睁开右眼闭上嘴巴张开、左眼睁开右眼闭上嘴巴闭上、左眼闭上右眼睁开嘴巴张开、左眼闭上右眼睁开嘴巴闭上、左眼闭上右眼闭上嘴巴张开、左眼闭上右眼闭上嘴巴闭上;s12.获取用于合成的驱动视频:从视频库中获取第二人物演讲视频,将视频截取成一段时长为1分钟的驱动视频,这个视频中将包含要使用的实际脸部外观;s13.将获取到的源图片及驱动视频进行保存,存储在原始素材库中。3.根据权利要求1所述的一种基于深度学习的脸部视频合成方法,其特征在于,步骤s2的具体方法为:s21.对源图片进行处理,调整图片尺寸,进行图像增强,具体是将源图片采用图片处理工具,按照深度学习模型的图片输入尺寸进行调整,将图片尺寸大小调整为256x256;以源图片中第一人物的脸部双眉中间点为图片中心点,对图片进行原比例缩放,当源图片的高或者宽其中一项的长度缩小到256时,则停止缩放操作;采用256x256的正方形框选住缩放后的源图片,对超出正方形范围的图片部分进行裁剪,最终得到裁剪后的第一人物的脸部图片样本;再对裁剪处理后的图片样本进行图片增强,具体是采用彩色图像的增强技术,通过先将彩色图像转换成灰度图像,然后对灰度图像进行直方图均衡化的处理,最后再将经过处理之后得到增强效果的灰度图像还原成彩色图像,并保存在样本图片文件夹中;s22.对视频进行处理,逐帧提取图片,具体是将驱动视频进行缩放裁剪至256x256的尺寸大小,将视频缩放到合适大小,将人脸放置在256x256的虚线选框中央进行裁剪,输出裁剪完成的驱动视频样本;采用opencv2进行视频逐帧提取,获取视频样本文件,获取视频总帧数,读取视频每一帧,设置每帧都获取一次,将帧转化成图片输出,设置保存帧图片的路径,将帧图片存储在保存在样本图片文件夹。4.根据权利要求1所述的一种基于深度学习的脸部视频合成方法,其特征在于,步骤s3所述的搭建stylegan2模型,并对模型进行优化,具体是在stylegan2模型中,adain被重构为weight demodulation,采用递次演进的训练方法,即先训一个小分辨率的图像,训好了
之后再逐步过渡到更高分辨率的图像,然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率;对数据分布开始跑偏的时候才使用r1 regularization,其它时候不使用,并对路径长度正则化。5.根据权利要求1所述的一种基于深度学习的脸部视频合成方法,其特征在于,步骤s4具体方法是:s41.随机生成一批潜码latents,通过生成器g得到一批假图像fake_images_out;s42.再从训练数据集中取一部分真实图像reals;s43.将真、假图像分别交给判别器d去计算得分,并计算这些得分的全局交叉熵,假图像判别为假的概率的对数与真图像判别为真的概率的对数之和的相反数,把全局交叉熵与正则化项求和作为判别器d的损失函;s44.生成器g的损失函数则只考虑它自身的交叉熵,假图像判别为真的概率的对数的相反数,再与感知路径长度正则化项求和作为生成器g的损失函数;s45.优化的过程就是通过梯度下降,使得d和g的损失函数取得最小值。6.根据权利要求1所述的一种基于深度学习的脸部视频合成方法,其特征在于,步骤s5的具体方法是:s51.从存储样本图片的文件中获取第一人物的脸部图片样本,然后再从步骤s22得到的图片文件夹中获取的首帧图片样本,首帧图片样本中包含第二人物的脸部图像;s52.采用asm算法将第一人物的脸部图片样本和首帧图片样本中的脸部进行对齐,所述asm是指主观形状模型,即通过形状模型对目标物体进行抽象,asm算法分为训练过程和搜索过程:在训练的阶段:构建各个特征点的位置约束,构建各个特征点的局部特征;在搜索的阶段:迭代到对应的特征点,首先计算眼睛或者嘴巴的位置,做尺度和旋转变化,对齐人脸;接着,在对齐后的各个点附近搜索,匹配每个局部关键点,得到初步形状;再用平均人脸修正匹配结果;迭代直到收敛;s53.将脸部对齐后第一人物的脸部图片样本与帧图像输入输入stylegan2模型中,通过脸部特征融合,将第一人物的脸部融合到帧图像中的第二人物的脸部位置,输出融合完成的目标脸部图片,将目标脸部图片进行保存。s54.按照以上步骤对步骤s22得到的图片文件夹中剩余的部分,进行批量融合处理,得到目标脸部图片数据集。7.根据权利要求1所述的一种基于深度学习的脸部视频合成方法,其特征在于,步骤s6的具体方法是:s61.从数据集中获取全部目标脸部图片,每张图片为1帧,第一帧开始一帧一帧的按顺序获取,将每帧图片作为参数传进opencv网络;s62.设置视频名称,帧率为30,视频尺寸为256x256;s63.调用write()直到遍历到最后一帧图片结束,此时输出新生成的目标脸部视频将在文件夹中输出;s64.得到最终的脸部合成视频。
技术总结
本发明提供一种基于深度学习的脸部视频合成方法,该方法包括如下步骤:S1.获取脸部合成的源图片和驱动视频,保存在原始素材库中;S2.对源图片和驱动视频进行数据处理;S3.搭建StyleGAN2模型,并对模型进行优化;S4.对StyleGAN2模型进行训练;S5.将第一人物的脸部图片样本和帧图片,输入StyleGAN2模型进行脸部融合处理;S6.将目标脸部图片数据集合帧为视频。采用本发明的方法语音识别准确率高。不仅能有效地定位目标脸部的外部轮廓形状,也可以有效地提取和定位目标脸部的内部轮廓信息,可以使目标脸部定位更加精准。可以使目标脸部定位更加精准。可以使目标脸部定位更加精准。
技术研发人员:刘奕 周建伟 舒佳根
受保护的技术使用者:苏州市职业大学
技术研发日:2022.03.11
技术公布日:2022/6/28
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。