1.本技术涉及自然语言处理技术领域,尤其涉及一种文本处理方法、装置、存储介质及设备。
背景技术:
2.随着计算机算力的井喷式发展,深度学习在人工智能中的应用也日益增多,越来越多的工程项目由传统的手工特征被更替为深度学习模型,如文本处理等。
3.智能问答是人工智能领域里的一项重要应用,相较于传统的人工客服系统来说,智能问答系统具有高效率、低成本等诸多优势,目前越来越多的企业使用智能问答系统为用户提供对话服务,如百度大脑un i t3.0解读之对话式文档问答等,能够基于阅读理解问答技术达到文档自动问答的目的。但是目前在实现智能问答之前还是需要预先由人工来梳理相关领域文档的问答对,才能够基于人工梳理的问答对结果进行智能问答,而通过人工来梳理问答对的过程,主观性强、难以量化,不仅梳理效率低,而且还需要花费大量的人力资源,导致文本的处理效果较差,智能问答的效率也不高。
技术实现要素:
4.本技术实施例的主要目的在于提供一种文本处理方法、装置、存储介质及设备,能够提高文本的处理效果和实现智能问答的效率。
5.本技术实施例提供了一种文本处理方法,包括:
6.获取待回答的目标问题文本;
7.将所述目标问题文本输入至预先构建的智能问答模型,预测得到所述目标问题文本对应的答案文本;
8.其中,所述智能问答模型是根据利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的;所述扩展问题是根据无监督语料和所述问答对中的问题挖掘得到的。
9.一种可能的实现方式中,所述问答对的挖掘过程如下:
10.获取无监督文档;
11.将所述无监督文档中的标题文本输入预训练语言模型,得到所述标题文本所属的预设问题标签分类和所述标题文本中每个文字被选为问题的分类结果;
12.利用预设问题模板,根据所述标题文本所属的预设问题标签分类和所述标题文本中每个文字被选为问题的分类结果,生成问答对中的问题;
13.利用机器阅读理解mrc模型和所述问答对中的问题在所述无监督文档中的段落内容,自动挖掘出所述问答对中的问题对应的答案。
14.一种可能的实现方式中,所述利用机器阅读理解mrc模型和所述问答对中的问题在所述无监督文档中的段落内容,自动挖掘出所述问答对中的问题对应的答案,包括:
15.利用机器阅读理解mrc模型,从所述问答对中的问题在所述无监督文档中的段落内容中,自动挖掘出所述问答对中的问题对应的所有答案,并从所有答案中选择最高置信
度对应的答案作为所述问题对应的最终答案。
16.一种可能的实现方式中,所述扩展问题的挖掘过程如下:
17.获取无监督语料;
18.计算所述问答对中的问题与无监督语料中的每个候选问题之间的相似度;
19.选择满足预设条件的相似度对应的候选问题作为所述问答对中的问题对应的扩展问题答案。
20.一种可能的实现方式中,所述预设条件包括相似度大于预设阈值。
21.一种可能的实现方式中,所述智能问答模型的构建方式如下:
22.获取样本问题文本;所述样本问题文本包括通过无监督文档自动挖掘出的样本问答对中的问题、以及根据所述样本问答对中的问题自动挖掘出的样本扩展问题;
23.利用所述样本问题文本及其对应的答案文本,对预先构建的初始智能问答模型进行训练,得到所述智能问答模型。
24.一种可能的实现方式中,所述方法还包括:
25.获取验证问题文本;
26.将所述验证问题文本输入所述智能问答模型,获得所述验证问题文本对应的回答结果;
27.当所述验证问题文本对应的回答结果与所述验证问题文本对应的答案标记结果不一致时,将所述验证问题文本重新作为所述样本问题文本,对所述智能问答模型进行更新。
28.本技术实施例还提供了一种文本处理装置,包括:
29.第一获取单元,用于获取待回答的目标问题文本;
30.预测单元,用于将所述目标问题文本输入至预先构建的智能问答模型,预测得到所述目标问题文本对应的答案文本;
31.其中,所述智能问答模型是根据利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的;所述扩展问题是根据无监督语料和所述问答对中的问题挖掘得到的。
32.一种可能的实现方式中,所述装置还包括:
33.第二获取单元,用于获取无监督文档;
34.输入单元,用于将所述无监督文档中的标题文本输入预训练语言模型,得到所述标题文本所属的预设问题标签分类和所述标题文本中每个文字被选为问题的分类结果;
35.生成单元,用于利用预设问题模板,根据所述标题文本所属的预设问题标签分类和所述标题文本中每个文字被选为问题的分类结果,生成问答对中的问题;
36.挖掘单元,用于利用机器阅读理解mrc模型和所述问答对中的问题在所述无监督文档中的段落内容,自动挖掘出所述问答对中的问题对应的答案。
37.一种可能的实现方式中,所述挖掘单元具体用于:
38.利用机器阅读理解mrc模型,从所述问答对中的问题在所述无监督文档中的段落内容中,自动挖掘出所述问答对中的问题对应的所有答案,并从所有答案中选择最高置信度对应的答案作为所述问题对应的最终答案。
39.一种可能的实现方式中,所述装置还包括:
40.第三获取单元,用于获取无监督语料;
41.计算单元,用于计算所述问答对中的问题与无监督语料中的每个候选问题之间的相似度;
42.选择单元,用于选择满足预设条件的相似度对应的候选问题作为所述问答对中的问题对应的扩展问题答案。
43.一种可能的实现方式中,所述预设条件包括相似度大于预设阈值。
44.一种可能的实现方式中,所述装置还包括:
45.第四获取单元,用于获取样本问题文本;所述样本问题文本包括通过无监督文档自动挖掘出的样本问答对中的问题、以及根据所述样本问答对中的问题自动挖掘出的样本扩展问题;
46.训练单元,用于利用所述样本问题文本及其对应的答案文本,对预先构建的初始智能问答模型进行训练,得到所述智能问答模型。
47.一种可能的实现方式中,所述装置还包括:
48.第五获取单元,用于获取验证问题文本;
49.获得单元,用于将所述验证问题文本输入所述智能问答模型,获得所述验证问题文本对应的回答结果;
50.更新单元,用于当所述验证问题文本对应的回答结果与所述验证问题文本对应的答案标记结果不一致时,将所述验证问题文本重新作为所述样本问题文本,对所述智能问答模型进行更新。
51.本技术实施例还提供了一种文本处理设备,包括:处理器、存储器、系统总线;
52.所述处理器以及所述存储器通过所述系统总线相连;
53.所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述文本处理方法中的任意一种实现方式。
54.本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述文本处理方法中的任意一种实现方式。
55.本技术实施例还提供了一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行上述文本处理方法中的任意一种实现方式。
56.本技术实施例提供的一种文本处理方法、装置、存储介质及设备,首先获取待回答的目标问题文本;然后将目标问题文本输入至预先构建的智能问答模型,预测得到目标问题文本对应的答案文本;其中,智能问答模型是根据利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的;扩展问题是根据无监督语料和问答对中的问题挖掘得到的。可见,由于本技术实施例是利用预先构建的智能问答模型对目标问题文本进行智能回答,有效提高了智能问答效率,且该智能问答模型是利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的,不再需要人工来梳理问答对,消除了人工梳理的主观性带来的影响,进而能够提高文本的处理效果和实现智能问答的效率。
附图说明
57.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本技术
的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
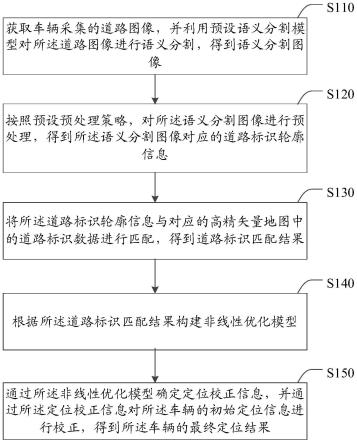
58.图1为本技术实施例提供的一种文本处理方法的流程示意图;
59.图2为本技术实施例提供的问答对的挖掘过程的示意图;
60.图3为本技术实施例提供的文本处理整体过程的示意图;
61.图4为本技术实施例提供的一种文本处理装置的组成示意图。
具体实施方式
62.目前,用户经常碰到很多复杂的规章制度或规则条款。比如:最新的房产摇号政策的具体实施标准是什么?银行最新推出的一款理财产品的办理指南、价格收费标准是什么?商业保险理赔需要什么材料,工作几年可以排队办理等?这些情况下,客服/接线人员需要各种查询确定或者检索规章制度文件或说明,才能回复并解决用户的疑问,回答效率较低。
63.由此,为提高回答效率,越来越多的企业使用智能问答系统为用户提供对话服务,如百度大脑unit3.0解读之对话式文档问答等,能够基于阅读理解问答技术达到文档自动问答的目的。但是目前在实现智能问答之前还是需要预先由人工来梳理相关领域文档的问答对,才能够基于人工梳理的问答对结果进行智能问答,而通过人工来梳理问答对的过程,主观性强、难以量化,不仅梳理效率低,而且还需要花费大量的人力资源,导致文本的处理效果较差,智能问答的效率也不高。
64.因此,如何提高文本的处理效果和实现智能问答的效率是目前亟待解决的技术问题。
65.为解决上述缺陷,本技术提供了一种文本处理方法,首先获取待回答的目标问题文本;然后将目标问题文本输入至预先构建的智能问答模型,预测得到目标问题文本对应的答案文本;其中,智能问答模型是根据利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的;扩展问题是根据无监督语料和问答对中的问题挖掘得到的。可见,由于本技术实施例是利用预先构建的智能问答模型对目标问题文本进行智能回答,有效提高了智能问答效率,且该智能问答模型是利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的,不再需要人工来梳理问答对,消除了人工梳理的主观性带来的影响,进而能够提高文本的处理效果和实现智能问答的效率。
66.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
67.第一实施例
68.参见图1,为本实施例提供的一种文本处理方法的流程示意图,该方法包括以下步骤:
69.s101:获取待回答的目标问题文本。
70.在本实施例中,将采用本实施例实现文本处理的任一问题文本定义为目标问题文本。并且,本实施例不限制目标问题文本的语种类型,比如,目标问题文本可以是中文文本、或英文文本等;本实施例也不限制目标问题文本的来源,比如,目标问题文本可以是来自于
from transformer)模型等;预设问题标签分类可根据实际情况进行设定,本技术实施例对此不进行限定,比如可以将预设问题标签分类利用如图2中cls1、cls2、cls3、cls4
…
来表示,通常情况下,可以将预设问题标签分类定义为5w1h体系,即why、what、where、who、when、how。
82.步骤a3:利用预设问题模板,根据标题文本所属的预设问题标签分类和标题文本中每个文字被选为问题的分类结果,生成问答对中的问题。
83.通过步骤a2得到标题文本所属的预设问题标签分类和标题文本中每个文字被选为问题的分类结果后,进一步可以利用预设问题模板,根据标题文本所属的预设问题标签分类和标题文本中每个文字被选为问题的分类结果,生成问答对中的问题,如图2所示的q1、q2
…
qn等,用以执行后续步骤a4。
84.其中,预设问题模板的具体内容可根据实际情况进行设定,本技术实施例对此不进行限定,通常需要提前梳理好,其主要目的是为了规范最终的问答对中的问题,即协助模型进行训练以提高生成问答对中的问题的顺滑度,使其更像一个正常人描述的问题。预设问题模板的示例如下表1所示:
[0085][0086]
表1
[0087]
需要说明的是,表1中每个问题类型下的问题模板数量可以有多个,用以提升生成问题结果的鲁棒性和多样性。
[0088]
步骤a4:利用机器阅读理解mrc模型和问答对中的问题在所述无监督文档中的段落内容,自动挖掘出问答对中的问题对应的答案。
[0089]
通过步骤a3生成问答对中的问题(如图2所示的q1、q2
…
qn等)后,进一步可以利用机器阅读理解(machine reading comprehension,简称mrc)模型,对问题在无监督文档中的段落内容(如图2所示的p1、p2
…
pm等)进行处理,根据处理结果自动挖掘出问答对中的问题对应的答案,进而可以利用问题及其对应的答案构成问答对。
[0090]
具体来讲,一种可选的实现方式是,在获取到问答对中的问题后,可以利用预训练mrc模型,从问答对中的问题在无监督文档中的段落内容中,自动挖掘出问题对应的所有答案,其中,利用mrc模型进行答案挖掘的具体实现过程与现有方法一致,在此不再赘述。然
后,可以从所有答案中选择最高置信度对应的答案,作为问题对应的最终答案,即最大化段落内容中的每个文字被预测成答案开始或者结束位置的置信度的均值,以使得挖掘到的答案的置信度最高。
[0091]
在本技术实施例的另一种可选的实现方式中,为提高智能问答模型的预测准确率,在利用无监督文档自动挖掘出的问答对后,还可以利用无监督语料,对问答对中的问题进行处理,并根据处理结果自动挖掘出扩展问题,用以丰富训练语料来训练智能问答模型,其中,扩展问题的挖掘过程具体可以包括下述步骤b1-b3:
[0092]
步骤b1:获取无监督语料。
[0093]
在本实现方式中,为了构建智能问答模型,丰富训练语料,不仅需要利用无监督文档自动挖掘出的问答对,还需要对问答对中的问题进行扩展,在扩展过程中,首先需要获取相应领域中的无监督语料,即需要获取相应领域中的自然文本数据,用以通过执行后续步骤b2-b3从中挖掘出问答对中的问题对应的扩展问题。
[0094]
步骤b2:计算问答对中的问题与无监督语料中的每个候选问题之间的相似度。
[0095]
通过步骤b1获取到无监督语料后,进一步可以利用现有或未来出现的相似度计算方法,计算出问答对中的问题与无监督语料中的每个候选问题之间的相似度,用以执行后续步骤b3。
[0096]
步骤b3:选择满足预设条件的相似度对应的候选问题作为问答对中的问题对应的扩展问题答案。
[0097]
通过步骤b2计算出问答对中的问题与无监督语料中的每个候选问题之间的相似度后,进一步可以从中选择出满足预设条件的相似度对应的候选问题作为问答对中的问题对应的扩展问题答案。
[0098]
其中,预设条件的具体内容可根据实际情况进行设定,本技术实施例对此不进行限定,比如可以预设条件的具体内容设定为相似度大于预设阈值,即,可以选择大于预设阈值的相似度对应的候选问题作为问答对中的问题对应的扩展问题答案。而且其中的预设阈值的具体取值也可根据实际情况进行设定,比如可以设定为0.8等。
[0099]
具体来讲,扩展问题的挖掘过程的实现代码可以如下示例:
[0100]
for candidate in相应领域内无监督的自然文本数据:
[0101]
if compute_similarity(question,candidate)》limit_score:
[0102]
candidate_list.append(candidate)
[0103]
其中,compute_similarity函数表示计算相似度的算法,可以使用各类现有或未来出现的相似度计算方法;limit_score表示阈值得分,取值在0~1之间,得分越高,表示问答对中的问题(question)和候选(candidate)问题越相似,进而表明候选(candidate)问题作为问答对中的问题(question)的扩展问的可能性越高。最终可以为每个问答对中的问题(question)挖掘出其对应的扩展问题,当扩展问题较多时,还可以将其组成扩展问题列表(candidate_list)。
[0104]
在此基础上,通过上述步骤a1-a4自动挖掘出的问答对(question-answer)和通过上述步骤b1-b3自动挖掘出的对于每个question对应的扩展问题(或扩展问题列表(candidate_list))后,可以将这些数据作为训练数据,对初始智能问答模型(如科大讯飞自研的问答机器人等)进行自动训练,以生成回答效果跟家的智能问答模型,实现自动实时
问答。
[0105]
接下来,本实施例将对智能问答模型的构建过程进行介绍,其中,一种可选的实现方式是,智能问答模型的构建过程具体可以包括:首先获取样本问题文本;其中,样本问题文本包括通过无监督文档自动挖掘出的样本问答对中的问题、以及根据样本问答对中的问题自动挖掘出的样本扩展问题,然后利用样本问题文本及其对应的答案文本,对预先构建的初始智能问答模型进行训练,得到智能问答模型。
[0106]
具体来讲,在本实现方式中,为了构建智能问答模型,需要预先进行大量的准备工作,首先,需要收集大量的无监督文档,并通过执行上述步骤a1-a4从中挖掘出大量问题文本数据,作为样本问题文本,再通过执行上述步骤b1-b3自动挖掘出样本问题文本中问题对应的扩展问题,作为样本扩展问题,用以与样本问题文本共同构成模型训练数据。例如,可以预先通过网络渠道,收集新闻通知文本、教科书文本等无监督文档数据,在从中确定出样本问题文本及对应的样本扩展问题,构成模型训练数据,并记录这些样本问题文本对应的答案文本结果。接着,可以根据这些样本问题文本、样本扩展问题、及答案文本结果,对初始智能问答模型进行训练,进而生成智能问答模型。
[0107]
需要说明的是,可以将初始智能问答模型选为sentence-bert网络结构等。
[0108]
在进行模型训练时,可以依次从训练数据中提取一份样本问题文本作为模型输入,并将模型输出的预测的答案结果与已记录的样本问题文本对应的答案文本结果进行比较,并根据二者的差异对模型参数进行更新。这样,进行多轮模型训练,直至满足预设的条件(如训练次数达到预设次数或优化函数的取值基本不变等),则停止模型参数的更新,完成智能问答模型的训练,生成一个训练好的智能问答模型。
[0109]
在此基础上,在根据样本问题文本训练生成智能问答模型后,进一步的,还可以利用验证问题文本对生成的智能问答模型进行验证。具体验证过程可以包括下述步骤(1)-(3):
[0110]
步骤(1):获取验证问题文本。
[0111]
在本实施例中,为了实现对智能问答模型进行验证,首先需要获取验证问题文本,如可以通过网络渠道收集100个新闻文本,并通过执行上述步骤a1-a4从中挖掘出大量问题文本数据,作为验证问题文本,其中,验证问题文本指的是可以用来进行智能问答模型验证的问题文本信息,在获取到这些验证问题文本及每个验证问题文本对应的答案标记结果后,可继续执行后续步骤(2)。
[0112]
步骤(2):将验证问题文本输入智能问答模型,获得验证问题文本对应的回答结果。
[0113]
通过步骤(1)获取到验证问题文本后,进一步的,可以将验证问题文本输入智能问答模型,预测得到验证问题文本对应的回答结果,用以执行后续步骤(3)。
[0114]
步骤(3):当验证问题文本对应的回答结果与验证问题文本对应的答案标记结果不一致时,将验证问题文本重新作为样本问题文本,对智能问答模型进行更新。
[0115]
通过步骤(2)获得验证问题文本对应的回答结果后,若验证问题文本对应的回答结果与验证问题文本对应的真实答案标记结果(如人工标记的答案文本结果)不一致,则可以将验证问题文本重新作为样本问题文本,对智能问答模型进行参数更新。
[0116]
通过上述实施例,可以利用验证问题文本对智能问答模型进行有效验证,当预测
出的验证问题文本对应的回答结果与验证问题文本对应的真实答案标记结果不一致时,可以及时调整更新智能问答模型,进而有助于提高智能问答模型的预测精度和准确性。
[0117]
这样,通过上述步骤s101-s102即可利用预先构建的智能问答模型,准确预测出目标问题文本对应的答案文本。为便于理解本技术提供的文本处理方法,接下来,本技术将通过举例的形式对本技术中的文本文本处理的整体过程进行介绍。
[0118]
举例说明:如图3所示,在对目标问题文本进行处理之前,首先可以通过执行上述步骤a1-a4,从“关于房产摇号的通知”这一无监督文档中自动挖掘出问答对“q1:房产摇号,使用对象;q1':房产牙好的使用对象有哪些;a1:刚需,在本地无房产
…
。qm:房产摇号,相关材料;qm’:房产摇号需要准备什么;am:刚需人才:
…
;非刚需普通住户:...”等。然后,再通过执行上述步骤b1-b3自动挖掘出扩展问题“1:谁可以进行摇号
…
。n:这次摇号买房是针对哪些人”等,从而可以利用这些数据作为训练数据,训练得到智能问答模型。
[0119]
在此基础上,如图3所示,在将目标问题文本“房产摇号适用对象是什么?”输入至智能问答模型后,可以预测得到该目标问题文本对应的答案文本为“刚需,在本地无房产”。
[0120]
综上,本实施例提供的一种文本处理方法,首先获取待回答的目标问题文本;然后将目标问题文本输入至预先构建的智能问答模型,预测得到目标问题文本对应的答案文本;其中,智能问答模型是根据利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的;扩展问题是根据无监督语料和问答对中的问题挖掘得到的。可见,由于本技术实施例是利用预先构建的智能问答模型对目标问题文本进行智能回答,有效提高了智能问答效率,且该智能问答模型是利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的,不再需要人工来梳理问答对,消除了人工梳理的主观性带来的影响,进而能够提高文本的处理效果和实现智能问答的效率。
[0121]
第二实施例
[0122]
本实施例将对一种文本处理装置进行介绍,相关内容请参见上述方法实施例。
[0123]
参见图4,为本实施例提供的一种文本处理装置的组成示意图,该装置400包括:
[0124]
第一获取单元401,用于获取待回答的目标问题文本;
[0125]
预测单元402,用于将所述目标问题文本输入至预先构建的智能问答模型,预测得到所述目标问题文本对应的答案文本;
[0126]
其中,所述智能问答模型是根据利用无监督文档自动挖掘出的问答对、以及扩展问题训练得到的;所述扩展问题是根据无监督语料和所述问答对中的问题挖掘得到的。
[0127]
在本实施例的一种实现方式中,所述装置还包括:
[0128]
第二获取单元,用于获取无监督文档;
[0129]
输入单元,用于将所述无监督文档中的标题文本输入预训练语言模型,得到所述标题文本所属的预设问题标签分类和所述标题文本中每个文字被选为问题的分类结果;
[0130]
生成单元,用于利用预设问题模板,根据所述标题文本所属的预设问题标签分类和所述标题文本中每个文字被选为问题的分类结果,生成问答对中的问题;
[0131]
挖掘单元,用于利用机器阅读理解mrc模型和所述问答对中的问题在所述无监督文档中的段落内容,自动挖掘出所述问答对中的问题对应的答案。
[0132]
在本实施例的一种实现方式中,所述挖掘单元具体用于:
[0133]
利用机器阅读理解mrc模型,从所述问答对中的问题在所述无监督文档中的段落
内容中,自动挖掘出所述问答对中的问题对应的所有答案,并从所有答案中选择最高置信度对应的答案作为所述问题对应的最终答案。
[0134]
在本实施例的一种实现方式中,所述装置还包括:
[0135]
第三获取单元,用于获取无监督语料;
[0136]
计算单元,用于计算所述问答对中的问题与无监督语料中的每个候选问题之间的相似度;
[0137]
选择单元,用于选择满足预设条件的相似度对应的候选问题作为所述问答对中的问题对应的扩展问题答案。
[0138]
在本实施例的一种实现方式中,所述预设条件包括相似度大于预设阈值。
[0139]
在本实施例的一种实现方式中,所述装置还包括:
[0140]
第四获取单元,用于获取样本问题文本;所述样本问题文本包括通过无监督文档自动挖掘出的样本问答对中的问题、以及根据所述样本问答对中的问题自动挖掘出的样本扩展问题;
[0141]
训练单元,用于利用所述样本问题文本及其对应的答案文本,对预先构建的初始智能问答模型进行训练,得到所述智能问答模型。
[0142]
在本实施例的一种实现方式中,所述装置还包括:
[0143]
第五获取单元,用于获取验证问题文本;
[0144]
获得单元,用于将所述验证问题文本输入所述智能问答模型,获得所述验证问题文本对应的回答结果;
[0145]
更新单元,用于当所述验证问题文本对应的回答结果与所述验证问题文本对应的答案标记结果不一致时,将所述验证问题文本重新作为所述样本问题文本,对所述智能问答模型进行更新。
[0146]
进一步地,本技术实施例还提供了一种文本处理设备,包括:处理器、存储器、系统总线;
[0147]
所述处理器以及所述存储器通过所述系统总线相连;
[0148]
所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述文本处理方法的任一种实现方法。
[0149]
进一步地,本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述文本处理方法的任一种实现方法。
[0150]
进一步地,本技术实施例还提供了一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行上述文本处理方法的任一种实现方法。
[0151]
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到上述实施例方法中的全部或部分步骤可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者诸如媒体网关等网络通信设备,等等)执行本技术各个实施例或者实施例的某些部分所述的方法。
[0152]
需要说明的是,本说明书中各个实施例采用递进的方式描述,每个实施例重点说
明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0153]
还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0154]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。