1.本公开涉及被设计为执行浮点运算的集成电路。更具体地,本公开涉及将灵活的舍入点用于浮点尾数。
背景技术:
2.本节旨在向读者介绍可能与本公开的各个方面相关的本领域的各个方面,这些方面在下面描述和/或要求保护。该论述被认为有助于为读者提供背景信息以促进更好地理解本公开的各个方面。因此,应当理解,这些陈述应据此进行阅读,而不是作为对现有技术的承认。
3.人工智能(ai)正成为日益流行的应用领域。ai应用的浮点运算的舍入电路实现方式已成为专用标准产品(assp)设计和中央处理单元(cpu)设计二者的架构瓶颈。
4.ai以浮点格式使用许多不同数量(例如,8、16和32)的位用于存储和计算。然而,当计算内积时,至少一些格式可以使用通用格式。例如,内积的累加可以使用ieee float32来执行以保持高精度,而不管在神经网络的输入和/或输出中使用的精度级别。ai(尤其是深度学习)构建了多层拓扑,数据通过它进行传播。由于每个运算的输入都是以较低精度格式之一(例如,float16)提供的,因此在内积完成之后将累加器结果向下转换为对应的目标精度。使用这种精度级别,使得可以将舍入的累加器结果正确地馈送到ai实现方式的下一层(例如,神经网络)。
附图说明
5.通过阅读以下详细描述并参考附图,可以更好地理解本公开的各个方面,在附图中:
6.图1是根据实施例的用于实现浮点乘法器舍入的系统的框图;
7.图2是根据实施例的可以实现乘法器的集成电路设备的框图;
8.图3是根据实施例的用于执行具有舍入的浮点乘法的浮点乘法器的框图;
9.图4是根据实施例的作为图3的浮点乘法器的另一实施例的浮点乘法器的框图;
10.图5是根据实施例的混合整数和浮点乘法器的框图;
11.图6是根据实施例的浮点乘法器的框图;
12.图7是示出根据实施例的可用于图6的浮点乘法器中的brent-kung传播网络的延迟分布(profile)的曲线图;
13.图8是根据实施例的执行浮点舍入运算以执行多个连续舍入点的系统的框图;
14.图9是根据实施例的为多个非连续舍入点实现浮点运算的系统的框图;以及
15.图10是根据实施例的其中可以实现一个或多个浮点乘法器舍入电路的数据处理系统的框图。
具体实施方式
16.下面将描述一个或多个具体实施例。为了提供这些实施例的简明描述,在说明书中并未描述实际实现方式的所有特征。可以理解,在任何此类实际实现方式的开发中,就像在任何工程或设计项目中一样,必须做出许多特定于实现方式的决策来实现开发者的特定目标,例如遵守系统相关和业务相关的约束,这可能因实现方式而异。此外,可以理解,这样的开发工作可能是复杂和耗时的,但是对于受益于本公开的普通技术人员来说,这仍然是设计、制造和制造的例行工作。
17.当介绍本公开的各种实施例的要素时,冠词“一(a)”、“一个(an)”和“该(the)”旨在表示存在一个或多个要素。术语“包括”和“具有”旨在包含性的且表示除了所列元素之外可能还有其它元素。此外,应当理解,对本公开的“一些实施例”、“实施例”、“一个实施例”或“一实施例”的引用并不旨在被解释为排除存在也包含所引用特征的附加实施例。此外,短语a“基于”b旨在表示a至少部分地基于b。此外,术语“或”旨在包含性的(例如,逻辑或)而不是排他性的(例如,逻辑异或)。换句话说,短语a“或”b旨在表示a、b、或者a和b二者。
18.如下文进一步详细讨论的,本公开的实施例一般涉及用于在利用多于一个浮点精度级别的系统中舍入和/或计算一个或多个尾数舍入位置的逻辑电路。这种计算可以使用多个加法器,但加法器的尺寸和/或成本可能很昂贵。相比之下,使用现代设计工具,进位传播加法器(cpa)可用于实现执行加法和舍入的组合加法器。然而,利用cpa和组合加法器的电路可能会变得非常复杂,以实现多个可选择的舍入位置。如本文所讨论的,结合并行前缀传播电路,舍入电路可以使得尾数中的舍入起始点能够被自由控制。自由控制尾数中的舍入起始点可能会导致计算延迟更少,因为并行传播电路可以在设置的舍入点(例如,在更高有效位)处开始计算,而不是执行整个舍入计算。
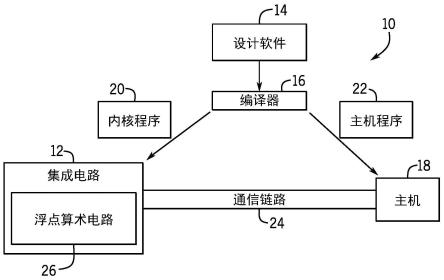
19.考虑到上述情况,图1示出了可以实现浮点乘法器舍入的系统10的框图。设计者可能希望在集成电路设备12(例如,现场可编程门阵列(fpga))上的各个舍入位置处实现涉及多个舍入操作的功能。设计者可以指定要实现的高级程序,例如opencl程序,这可以使设计者能够更高效且容易地提供编程指令以配置集成电路设备12的可编程逻辑单元集合,而不要求对低级硬件描述语言(例如,verilog或vhdl)的特定知识。例如,因为opencl与其它高级编程语言(如c )非常相似,因此为了在集成电路设备12中实现新功能,熟悉此类编程语言的可编程逻辑设计者的学习曲线可能比可能必须学习不熟悉的低级硬件描述语言的设计者要短。
20.设计者可以使用设计软件14来实现他们的高级设计。设计软件14可以使用编译器16来将高级程序转换成低级描述。设计软件14还可用于优化和/或提高设计效率。编译器16可以向主机18和集成电路设备12提供代表高级程序的机器可读指令。主机18可以接收可由内核程序20实现的主机程序(host program)22。为了实现主机程序22,主机18可以经由通信链路24将来自主机程序22的指令传送到集成电路设备12,这可以是例如直接存储器访问(dma)通信或外围组件互连快速(pcie)通信。在一些实施例中,内核程序20和主机18可以在集成电路设备12上实现浮点算术电路26的配置。浮点算术电路26可以包括电路和/或其它逻辑元件,并且可以被配置为例如实现浮点算术逻辑和/或机器学习操作。
21.现在转向集成电路设备12的更详细讨论,图2示出了集成电路设备12的框图,该集成电路设备12可以是可编程逻辑器件,例如fpga。此外,应当理解,集成电路设备12可以是
任何其它合适类型的可编程逻辑器件(例如,专用集成电路和/或专用标准产品)。如图所示,集成电路设备12可以具有输入/输出电路42,以用于驱动信号离开设备以及用于经由输入/输出引脚44从其它设备接收信号。互连资源46(例如,全局和局部垂直和水平导线和总线)可以用于在集成电路设备12上路由信号。另外,互连资源46可以包括固定互连(导线)和可编程互连(即,相应固定互连之间的可编程连接)。可编程逻辑48可以包括组合和顺序逻辑电路。例如,可编程逻辑48可以包括查找表、寄存器和复用器。在各种实施例中,可编程逻辑48可以被配置为执行定制逻辑功能。与互连资源相关联的可编程互连可以被认为是可编程逻辑48的一部分。可编程逻辑48可以包括不同层的可编程性的多种不同类型的可编程逻辑48。例如,可编程逻辑48可以包括各种数学逻辑单元,例如算术逻辑单元(alu)或可配置逻辑块(clb),其可被配置为执行各种数学函数(例如,浮点乘法计算)。集成电路(例如,集成电路设备12)可以在可编程逻辑48内包含可编程元件50。例如,设计者(例如,客户)可以对可编程逻辑48进行编程(例如,配置)以执行一个或多个期望功能(例如,执行浮点运算)。
22.各种机制可用于可在可编程逻辑48中使用的硬化电路(hardened circuit)中实现浮点乘法运算。图3示出了用于执行具有舍入的浮点乘法的浮点乘法器100的框图。该实施例可以使用进位传播加法器(cpa)102和舍入cpa 108。浮点舍入的某些实施例包括复合加法器,其中,cpa 102和舍入cpa 108可以由同时计算a b和a b 1的单个结构代替。在一些实施例中,也可以计算a b 2。这可能导致比两个单独的加法运算更高效的结构。
23.可以使用用于整数乘法的某些方法来形成浮点乘法器100的尾数乘法。浮点乘法器可以包括:产生多个部分乘积的部分乘积生成器,以冗余形式将各种部分乘积相加到一起并具有两个输出向量的n-2压缩器,以及将两个向量相加到一起的cpa。
24.此外,图3示出了浮点乘法器100中的浮点乘法和舍入的各个步骤。浮点乘法器100接受精度为p的两个尾数。这些尾数具有隐含的前导1,因此乘法器的结果实际上是2p 2位宽。因此,输入的值为1.x和1.y。因此,乘积将在两个可能的范围内:从1.0到和从2.0到可以对输出进行归一化以确保结果在1.0到的范围内。这种归一化可以通过检视一个或多个最高有效位的值并使用归一化复用器104右移多个(例如,1个)位来实现。换句话说,归一化复用器104可用于归一化数字到正确的位置(同时也会导致数字指数的对应变化)。乘法器输出的较低位与归一化条件相组合可以定义舍入位的值。然后可以在舍入cpa 108中将舍入位添加到尾数。如果输出的归一化值为则可以溢出到2.0。在这种情况下,指数的值可以增加1。如可以从图3看到的,这种学究式的浮点乘法器舍入方法会导致更长的关键路径(critical path)。在关键路径中,首先将“和”和“进位”位输入到第一cpa 102。然后,来自cpa 102的输出被输出到归一化复用器104和舍入电路106。来自归一化复用器104和舍入电路106的输出然后被输出到舍入cpa 108。舍入cpa 108输出尾数值,并且任何进位将被输出到组件110。浮点乘法器100将生成正确的结果,但可能不是用于专用集成电路(asic)中的最有效选择。浮点乘法器100可能不适合asic(因为cpa占用了集成电路设备12上的大量空间),可能很昂贵,并且可能比替代实现方式效率低。在某些asic浮点乘法器架构中,舍入电路106可以与舍入cpa 108组合。
25.图4示出了作为图3中描述的浮点乘法器100的替代实施例的浮点乘法器120的框图。主要地,可以用并行前缀传播电路122代替图3中的舍入cpa 108。并行前缀传播电路122
是这样一种结构,其中每个输出可以是其位置之前的输入的按位与。然后,输入的与运算(anding)的输出随后可以与舍入位进行与运算。并行前缀传播电路122可以与任何合适的前缀拓扑(例如,brent-kung、ladner-fischer或其它合适的前缀拓扑)并行高效地实现。并行前缀传播电路122的输出然后可以与归一化复用器104的输出位进行异或。并行前缀传播电路122的最高有效位输出将指示溢出。用并行前缀传播电路122代替舍入cpa 108的优点在于,并行前缀传播电路122的尺寸和简单性使得它节省空间并减少浮点乘法器120中的延时。
26.允许对现有技术进行所公开的改进的一个技术方面是合成工具和设计软件的改进,例如图1中描述的那些。在先前,电路设计者必须指定组合浮点舍入或cpa电路的逐门实现。电子设计自动化(eda)工具已经改进到存在已发布的算术拓扑库的点,并且eda工具可以快速评估大量方法,包括压缩器对cpa架构的影响。因此,在行为上指定cpa的情况下构建浮点乘法器可以产生比使用浮点乘法器100和120实现的电路更小的电路尺寸。构建图4的舍入实现方式的附加元件(即,并行前缀传播电路122)的成本小于图3中所示的显式(explicitly)定义的对应物(即,舍入cpa 108)。
27.图5示出了具有并行前缀加法器154的混合整数和浮点乘法器150的简化框图。首先,电路152计算向量x(i)、生成向量g(i)和传播向量p(i)的部分乘积。两个输入向量a(i)和b(i)可以是:(1)按位异或,其得到向量x(i),(2)按位与,其得到生成向量g(i),以及(3)按位或,其得到传播向量p(i)。然后可以将生成向量g(i)和传播向量p(i)输入到并行前缀加法器154中,该并行前缀加法器154输出进位向量c(i)。向量x(i)和c(i)然后可以被输入到异或门160中以产生结果向量r(i)。可以使用多种前缀拓扑(例如,brent-kung或ladner-fischer网络)来实现并行前缀加法器154。
28.混合整数和浮点乘法器150可能比所示的更复杂,并且可能导致集成电路设备12上的空间消耗和延时的增加。回想图3,浮点尾数在cpa 102的上部,并且舍入cpa 108仅用于舍入确定。因此,图5中的向量拆分成两半,并且每一半可以经由并行前缀加法器154a和154b相加在一起。由于混合整数和浮点乘法器150可以重新用于整数乘法,所以可以使用整个输出。因此,可以添加并行前缀加法器154c以可选地组合并行前缀加法器154a和154b的输出。结果,尾数的范围可能从2.0到为了适应这个范围,可以使用半加器层162在尾数位置的最低有效位中插入附加空间。这种附加空间的插入使得混合整数和浮点乘法器150能够在位置0或位置1处注入舍入。
29.在诸如图5所示的混合整数和浮点乘法器150之类的系统中可能难以实现添加附加的舍入位置。为了添加附加的舍入位置,混合整数和浮点乘法器150可以利用:添加附加的并行前缀加法器154并重新格式化(reformat)它们在混合整数和浮点乘法器150中的位置,以潜在地增加混合整数和浮点乘法器150的复杂度。相比之下,图6描述了可用于比图5的混合整数和浮点乘法器150更高效地添加附加的舍入位置的浮点乘法器200。例如,浮点乘法器200可以省略半加器层162,同时在多个位置处提供舍入点。
30.如前所述,图3中所示的cpa 102和舍入cpa 108可以由单个结构代替,该结构可能比其中单独执行多个加法运算的结构更高效。图6示出了浮点乘法器200的实施例的简化框图,其中,浮点乘法器200表示可以高效地实现多个加法运算同时保持运算分离的结构。这可能导致更易于维护和验证的更简单的设计代码库(design code base)。
31.可以使用eda工具显式定义或在行为上指定图6中的cpa电路202。cpa电路202驱动处理电路206、舍入电路213和传播网络208。处理电路206使用来自cpa电路202的输出和/或其它控制信号来生成舍入位207。舍入电路213包括舍入复用器210,其被配置为在舍入位置处将舍入位207或来自cpa电路202的对应位输出到传播网络208。浮点乘法器200中还可以包括一个或多个或门212,以将传播网络208中舍入位置右侧的一位或多位(例如,传播位)驱动为逻辑值(例如,高)。强制舍入位置右侧的一位或多位为高可以导致浮点乘法器200表现得好像传播网络208中的计算开始于注入舍入处一样。换句话说,将这些位驱动为高可以将浮点乘法器200(例如,归一化复用器204)的一些部分移出关键路径。
32.在浮点乘法器200中,传播网络208的最高有效位输出驱动归一化复用器204和指数调整二者,随后是异常处理。在异常处理完成之前,不能使用尾数值。异常处理可能发生在浮点乘法器200外部但在集成电路设备12内(例如,通过可编程逻辑48内的指定功能),和/或可以在浮点乘法器200中使用为简单起见从图中省略的电路进行处理。归一化复用器204出现在异或218之后。异或218可以将来自传播网络208的进位值应用到然后由归一化复用器204复用的值。
33.传播网络208可以由诸如eda工具之类的设计软件在行为上指定。显式定义的电路可能很大而且很复杂。这可能导致电路更容易出现错误(bug),在集成电路设备12上消耗更多空间,以及增加延时和功耗。相反,行为上指定电路可能会导致更容易验证的简化电路。
34.图7示出了延迟分布图220,其示出了为什么图6的归一化复用器204不再处于关键路径中。换句话说,归一化复用器204不再依赖于传播网络208的最慢输出位。在图4中,浮点乘法器120可以操作,使得并行前缀传播电路122在并行前缀传播电路122可以开始处理之前依赖于接收归一化复用器104的结果,由此增加浮点乘法器120中的延时。然而,在图6中,最高有效位输出可以比来自传播网络208的至少一些位更快地变得可用。如前所述,图6示出了传播网络208的最高有效位输出驱动归一化复用器204和异常处理之后的指数调整二者。
35.在某些传播网络(例如,brent-kung网络)中,中间位比最高有效位花费更长的时间来计算。这些类型的网络的延迟分布在图7中示出。图7示出延迟分布图220。延迟分布图220包括x轴222,其表示左侧的较大位索引和右侧的较低位索引。延迟分布图220包括y轴224,其中增加的深度代表增加的延迟。图7还示出了传播网络208的一部分226和传播网络208的另一部分228。从部分226在x轴222和y轴224上的定位可以看出,该部分226处的位比代表传播网络208的中间位的部分228处的位经历更少的延迟。由于传播网络208的最高有效位驱动归一化复用器204,并且传播网络208的中间位通常具有最大延迟,因此可以看出归一化复用器204在关键路径之外。
36.图8示出了具有多个舍入点的系统250的框图。系统250包括独热编码器(one-hot encoder)252、一元编码器254、一组复用器256、一组或门258以及传播网络208。独热编码器252、一元编码器254、一组复用器256以及一组或门258共同形成舍入电路260。舍入电路260可以是图6中描述的舍入电路213的替代实施例。在舍入电路260中,当一组复用器256选择某个位置作为舍入位置(例如,位置2)时,独热编码器252的输出将所选择的位位置设置为1并且所有其它位置设置为0。例如,在位位置2处舍入的4位舍入电路中,独热编码器252将输出“0100”。对于一元编码器254,如果选择位置作为舍入位置(例如,位置2),则一元编码器
254将为舍入位置处的位和舍入位置左侧的所有位输出0。一元编码器254还为舍入位置右侧的所有位输出1。这些1使舍入位置右侧的所有或门258为位位置右侧的位输出1。例如,在位置2处具有舍入位置的4位舍入电路中,一元编码器254输出为“0011”。作为另一示例,如果舍入电路260是将位6作为所选舍入位置的10位位置(9:0)舍入电路,则独热编码器252的输出将是“0001000000”,并且一元编码器254的输出将是“0000111111”。然后输出将被或门258注入到在对应位置处的传播网络208中(例如,传播向量p(i))。
37.使用舍入电路260而不是舍入电路213使得归一化复用器204能够在传播网络208之前实现。将归一化复用器204移动到传播网络208的输出端使集成电路设备12能够复用两个相邻位置之间的舍入位(例如,舍入位207)。
38.图9是具有多个不连续舍入位置的系统270的框图。图9示出了具有独热编码器252、一元编码器254、一组复用器256、一组或门258和传播网络208的系统270。独热编码器252、一元编码器254、一组复用器256和一组或门258共同形成舍入电路272。虽然图9中的系统包含特定尺寸的舍入电路272,但舍入电路272内的一个或多个位可能不连接到一组复用器256中的复用器,并且因此可能不可用作舍入位置。例如,如果系统270具有8位舍入电路272(7:0),则只有四位可以耦合到一组复用器256中的复用器,并因此可用作舍入位(例如,位7、6、3和0可能是可用作舍入位置的仅有的位)。换句话说,系统使得能够使用不连续的不同舍入位置。例如,如果位6被选作舍入位置,则一元编码器254将触发位6右侧的所有或门258,导致位6右侧的位(例如,5:0)被设置为1。在这种情况下,传播网络208可以就像舍入计算在位6处开始一样进行操作。虽然该示例描述了具有4个可用舍入位置的8位舍入电路272,但应当注意,其它实施例可以包括任意尺寸的舍入电路272,具有任意数量的可用舍入位置。例如,复用器256可以位于神经网络中不同格式的尾数中经常使用的某些位位置处。例如,位位置可以设置为2、4、8、16、32或任何其它合适的位置(例如,使用2^n导出的任何数字)。
39.图3-9中所示的实施例可以在多个集成电路设备上实现,例如图2中描述的集成电路设备12。图2中的集成电路设备12可以是asic或fpga。集成电路设备12可以是数据处理系统(例如,图10所示的数据处理系统300)或者可以是其组件。数据处理系统300可以包括主机处理器302、存储器和/或存储电路304以及网络接口306。数据处理系统300可以包括更多或更少的组件(例如,电子显示器、用户界面结构或asic)。主机处理器302可以包括任何合适的处理器,例如处理器或精简指令处理器(例如,精简指令集计算机(risc)或高级risc机器(arm)处理器),其可以管理数据处理系统300的数据处理请求(例如,以执行机器学习、视频处理、语音识别、图像识别、数据压缩、数据库搜索排名、生物信息学、网络安全模式识别、空间导航等)。存储器和/或存储电路304可以包括随机存取存储器(ram)、只读存储器(rom)、一个或多个硬盘驱动器、闪存等。存储器和/或存储电路304可以保存要由数据处理系统300处理的数据。在一些情况下,存储器和/或存储电路304还可以存储用于对集成电路设备12进行编程的配置程序(比特流)。网络接口306可以允许数据处理系统300与其它电子设备通信。数据处理系统300可以包括若干不同的封装或者可以包含在单个封装衬底上的单个封装内。
40.在一个示例中,数据处理系统300可以是处理各种不同请求的数据中心的一部分。例如,数据处理系统300可以经由网络接口306接收数据处理请求以执行机器学习、视频处
理、语音识别、图像识别、数据压缩、数据库搜索排名、生物信息学、网络安全模式识别、空间导航或其它一些专门的任务。主机处理器302可以使集成电路设备12的可编程逻辑结构用适合于实现所请求任务的乘法器进行编程。例如,主机处理器302可以指示存储在存储器和/或存储电路304上的配置数据(比特流)被编程到集成电路设备12的可编程逻辑结构中。配置数据(比特流)可以表示使用一个或多个浮点乘法器或其它浮点算术运算的电路设计集,其可以根据本文描述的技术映射到可编程逻辑并在其中打包到一起。通过高效地映射和打包浮点乘法器,可以在集成电路设备12上减少用于执行所请求任务的面积、延时和/或路由资源。
41.虽然本公开中阐述的实施例可易于进行各种修改和替代形式,但具体实施例已经通过示例在附图中示出并且已经在本文中进行了详细描述。然而,可以理解的是,本公开并不旨在限于所公开的特定形式。本公开将涵盖落入由以下所附权利要求限定的本公开的精神和范围内的所有修改、等同和替代。
42.本文提出和要求保护的技术被引用并应用于实际性质的实物和具体示例,其明显改进了当前技术领域,并且因此不是抽象的、无形的或纯理论的。此外,如果附于本说明书的任何权利要求包含被指定为“用于[执行][功能]
…
的单元”或“用于[执行][功能]
…
的步骤”的一个或多个元素,则旨在此类元素应根据35usc 112(f)进行解释。然而,对于包含以任何其它方式指定的元素的任何权利要求,并不旨在将这些元素根据35u.s.c.112(f)进行解释。
[0043]
本公开的示例性实施例
[0044]
以下编号的条款定义了本公开的某些示例性实施例。
[0045]
示例性实施例1、一种系统,包括:
[0046]
算术电路,其生成浮点尾数并且包括:
[0047]
基于多个输入位来计算浮点尾数的传播网络;以及
[0048]
舍入浮点尾数的舍入电路,其中该舍入电路包括:
[0049]
用于浮点尾数的舍入位置处的复用器,其选择性地输入多个输入位中的第一输入位或舍入位;以及
[0050]
将多个输入位中的第二输入位与舍入位进行或运算(or)的或门,其中第二输入位是比第一输入位低的有效位。
[0051]
示例性实施例2、示例性实施例1的系统,其中,算术电路包括乘法器电路,该乘法器电路包括:
[0052]
接收第一浮点数的第一输入;以及
[0053]
接收第二浮点数的第二输入,其中算术电路至少部分地基于第一和第二浮点数的乘法来生成浮点尾数。
[0054]
示例性实施例3、示例性实施例2的系统,其中,乘法器电路包括加法器,该加法器将一个或多个值加在一起以至少部分地基于第一和第二浮点数来生成多个输入位。
[0055]
示例性实施例4、示例性实施例1的系统,包括输出复用器,其从传播网络接收浮点尾数并将浮点尾数归一化。
[0056]
示例性实施例5、示例性实施例1的系统,其中,多个输入位至少部分地基于对在多个异或门处接收到的值的异或(xor)运算。
[0057]
示例性实施例6、示例性实施例5的系统,其中,多个输入位包括:
[0058]
根据在多个与门处接收到的值生成的生成位;以及
[0059]
根据在多个或门处接收到的值生成的传播位。
[0060]
示例性实施例7、示例性实施例1的系统,其中,传播网络包括并行前缀传播电路。
[0061]
示例性实施例8、示例性实施例1的系统,其中,舍入电路包括:
[0062]
用于浮点尾数的附加舍入位置处的多个附加复用器,其选择性地输入多个输入位中的相应输入位或多个附加舍入位中的相应舍入位;以及
[0063]
将多个输入位中的相应输入位与舍入位进行或运算的多个附加或门,其中多个附加复用器中的每一个对应于多个附加或门中的一个或多个或门以及附加舍入位置的相应附加舍入位置,其中对应的一个或多个或门与比多个附加复用器中的相应附加复用器低的有效位相关联。
[0064]
示例性实施例9、示例性实施例8的系统,其中,多个附加复用器对应于多个输入位的非连续位。
[0065]
示例性实施例10、示例性实施例9的系统,其中,多个附加或门的数量大于多个附加复用器的数量。
[0066]
示例性实施例11、一种方法,包括:
[0067]
接收两个值;
[0068]
基于两个值的相应位对来生成输入位;
[0069]
确定组合两个值的结果的舍入位;
[0070]
将至少一些输入位传输到传播网络;
[0071]
在传播网络中,至少部分地基于至少一些输入位生成输出;
[0072]
使用舍入复用器,选择性地传输输入位中的第一输入位或在传播网络的第一位置处的舍入位;
[0073]
将输入位中的第二输入位与传播网络的第二位置处的舍入位一起传输到或门,其中所述第一位置包括舍入位置并且所述第二位置处于输入位的较低有效值处;以及
[0074]
至少部分地基于舍入复用器的输出和或门的输出来舍入输出。
[0075]
示例性实施例12、示例性实施例11的方法,其中,生成输入位包括:对相应的位对进行异或运算,对相应的位对进行与运算,以及对相应的位对进行或运算。
[0076]
示例性实施例13、示例性实施例12的方法,其中,第二输入位是对相应的位对进行或运算的结果。
[0077]
示例性实施例14、示例性实施例12的方法,其中,输出包括进位位。
[0078]
示例性实施例15、示例性实施例14的方法,其中,将进位位与相应的位对的异或的相应输出进行异或以生成结果位。
[0079]
示例性实施例16、示例性实施例11的方法,包括在输出复用器中归一化结果位。
[0080]
示例性实施例17、示例性实施例16的方法,其中,输出复用器中的归一化至少部分地基于来自传播网络的溢出。
[0081]
示例性实施例18、示例性实施例17的方法,其中,溢出基于传播网络的最高有效位。
[0082]
示例性实施例19、一种系统,包括:
[0083]
生成浮点尾数的算术电路,包括:
[0084]
基于多个输入位来计算浮点尾数的传播网络;以及
[0085]
将浮点尾数舍入到多个舍入位置之一的舍入电路,其中所述舍入位置对应于:
[0086]
用于浮点尾数的相应舍入位置处的相应复用器,其选择性地输入多个输入位中的第一输入位或舍入位;以及
[0087]
将多个输入位中的第二输入位与舍入位进行或运算的或门,其中第二输入位是比第一输入位低的有效位。
[0088]
示例性实施例20、示例性实施例19的系统,其中,多个舍入位置包括多个输入位的非连续位。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。