1.本说明书实施例属于区块链技术领域,尤其涉及一种联盟链中部署链码的方法和系统。
背景技术:
2.区块链(blockchain)是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链系统中按照时间顺序将数据区块以顺序相连的方式组合成链式数据结构,并以密码学方式保证的不可篡改和不可伪造的分布式账本。由于区块链具有去中心化、信息不可篡改、自治性等特性,区块链也受到人们越来越多的重视和应用。
技术实现要素:
3.本发明的目的在于提供一种联盟链中部署链码的方法和系统,包括:
4.一种联盟链中部署链码的方法,包括:
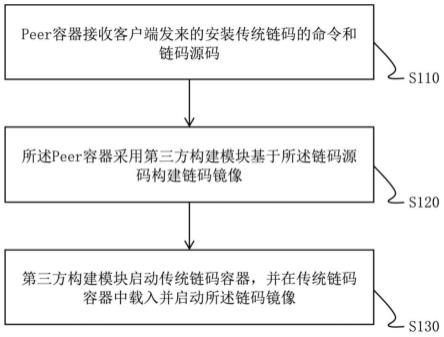
5.peer容器接收客户端发来的安装传统链码的命令和链码源码;
6.所述peer容器采用第三方构建模块基于所述链码源码构建链码镜像;
7.所述第三方构建模块启动传统链码容器,并在所述传统链码容器中载入并启动所述链码镜像。
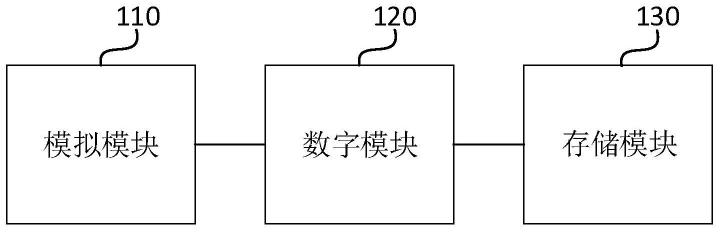
8.一种联盟链中部署链码的系统,包括:
9.peer容器,用于接收客户端发来的安装传统链码的命令和链码源码,还采用第三方构建模块基于所述链码源码构建链码镜像;
10.所述第三方构建模块,用于启动传统链码容器,并在所述传统链码容器中载入并启动所述链码镜像;
11.传统链码容器,用于运行链码。
12.上述实施例中,使得开发者在开发链码源码时还是按照传统链码的方式编写而无需做出改变,这样给链码开发者没有增加额外的开发成本。同时,通过由第三方构建模块构建链码镜像,摆脱了对docker的依赖。
附图说明
13.为了更清楚地说明本说明书实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
14.图1为本公开的一些实施例中hyperledger fabric的架构图;
15.图2为本公开的一些实施例中hyperledger fabric的交易流程示意图;
16.图3为本公开的一些实施例中hyperledger fabric的账本结构;
17.图4为本公开的一些实施例中区块和交易的结构;
18.图5为本公开的一些实施例中docker的基本原理示意图;
19.图6为本公开的一些实施例中docker的运行逻辑示意图;
20.图7为本公开的一些实施例中kubernetes的基本原理示意图;
21.图8为本公开中包含docker的通信和命令链路示意图;
22.图9为本公开中部署传统链码容器的示意图;
23.图10为本公开中部署传统链码容器的示意图;
24.图11为本公开中去除docker后的通信和命令链路示意图;
25.图12为本公开中去除docker后的部署传统链码容器的流程图;
26.图13为本公开中去除docker后的部署传统链码容器的示意图。
具体实施方式
27.为了使本技术领域的人员更好地理解本说明书中的技术方案,下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都应当属于本说明书保护的范围。
28.区块链通常可以分为三种类型:公有链(publick blockchain)、私有链(private blockchain)和联盟链(consortium blockchain)。此外,还有多种类型的结合,比如私有链 联盟链、联盟链 公有链等不同组合形式。其中去中心化程度最高的是公有链。公有链以比特币、以太坊为代表,加入公有链的参与者可以读取链上的数据记录、参与交易以及竞争新区块的记账权等。而且,各参与者(即节点)可自由加入以及退出网络,并进行相关操作。私有链则相反,该网络的写入权限由某个组织或者机构控制,数据读取权限受组织规定。简单来说,私有链可以为一个弱中心化系统,参与节点具有严格限制且少。这种类型的区块链更适合于特定机构内部使用。联盟链则是介于公有链以及私有链之间的区块链,可实现“部分去中心化”。联盟链中各个节点通常有与之相对应的实体机构或者组织;参与者通过授权加入网络并组成利益相关联盟,共同维护区块链运行。
29.hyperledger fabric是一种开源的联盟链实现。与比特币和以太坊这类公有链不同,hyperledger fabric网络中的节点一般需要经过授权认证后才能加入,从而避免了pow(proof of work,工作量证明)的资源开销,大幅提高了交易处理效率,满足企业级应用对处理性能的诉求,而且系统的运行可以不需要token(通证)的支持。
30.图1为一个典型的hyperledger fabric 1.4和2.0的架构图。通常多个组织作为一个联盟聚集在一起形成区块链网络。换句话说,组织是区块链系统的参与方。fabric中的组织在现实世界中可以是一个公司、一个企业,或者一个协会。如图1所示,包括组织1、组织2和组织3。每个组织都可以有自己对应的fabric-ca(certification authority,证书颁发)服务器。组织可以具有多个peer节点。组织的fabric-ca可以给组织内的peer节点颁发证书,颁发的证书可以用来标识节点及其所述的组织。
31.区块链网络中组织的节点称为peer。其中,peer节点上可以保存账本ledger。具体的,peer节点可以包括背书节点(endorsing peer)、记账节点(committing peer)、主节点(leader peer)和锚节点(anchor peer)。一个组织可以选择哪个节点安装链码,以实现联
盟成员共享的业务流程,而不需要在每个节点上都安装链码。一般的,背书节点上可以安装链码。背书节点上安装链码之后,经过实例化,具有协作关系的组织之间(也称为通道,channel)的其它节点才能知道链码,才可以由应用发起调用。实例化时提供的最重要的附加信息是背书策略,它描述了哪些组织必须批准交易,然后才会被接受到他们的账本上。实际上,链码中可以定义一个或多个的智能合约(smart contract)。每个智能合约在链码中有一个唯一的标识。应用可以通过智能合约的标识去访问链码容器内指定的智能合约。peer节点还可以是主节点,一个组织中一般只有一个主节点。主节点可以与排序服务通信,从而从排序服务获取最新的区块并在组织内的节点间同步。peer节点还可以是锚节点。锚节点可以代表组织与其他组织进行信息交换。一般每个组织都有一个锚节点。所有的peer节点都可以是记账节点,记账节点用于验证排序服务节点区块里的交易,维护世界状态和账本的副本。记账节点可以从orderer节点获取包含交易的区块,在对这些区块进行验证之后加入到区块链中。需要说明的是,“节点”是一个逻辑实体,不同类型的多个节点可以运行在同一个物理实体上。
32.应用(application,简写为app)可以通过内置的sdk(软件开发工具)及api(application programming interface,应用编程接口)连接到区块链节点上。app随后可以生成调用链码的交易提案,并向区块链网络提交该交易提案。如前所述,一旦在peer节点上安装了链码并完成实例化,链码内的智能合约对于相关联的通道来说就变得可用,也就是说应用就可以调用链码了。应用通过向背书策略指定的组织所属的节点发送交易提案来实现调用链码。交易提案作为智能合约的输入,背书节点上的智能合约模拟执行后生成一个经过背书的交易响应。区块链网络最终可以将这些交易排序并生成区块后提交到分布式账本上,具体的,可以由排序服务完成对交易的排序并生成区块。当这一过程完成时,app可以接收到对应的事件。
33.在一个常用于测试的简单模式中,排序服务在网络中是一个独立的节点,即由一个排序节点构成排序服务。很多时候,排序服务可以包括多个节点,并且可以配置为不同的组织中拥有不同的排序节点。
34.具体,结合图1所示的hyperledger fabric的架构,一个典型的交易的过程如下:
35.a1:应用发送交易提案(proposal)至背书节点。
36.账户登陆应用后,例如采用账户a登陆应用后,可以使用应用中的sdk生成一笔交易。sdk的作用包括将交易提案打包成合适的格式(例如grpc中使用的protocol buffer)以及根据用户的密钥对交易提案生成签名。这个生成的交易可以包含《clientid,chaincodeid,txpayload,timestamp,clientsig》等信息。其中,clientid表示登陆客户端的账户id,chaincodeid表示调用的链码的id,txpayload表示交易净荷,timestamp表示交易发起的时间戳,clientsig为客户端账户的签名。
37.应用可以按照背书策略(endorse policy)将交易发送至一个或多个背书节点。背书策略一般包括and、or、majority of等关系组织而成的节点,可以在链码中指定。and{背书节点1,背书节点2,背书节点3}可以表示需要由背书节点1,背书节点2,背书节点3均对该交易背书。or{背书节点1,背书节点2,背书节点3}可以表示由背书节点1,背书节点2,背书节点3中的任一个进行背书。majority of{背书节点1,背书节点2,背书节点3}可以表示需要由背书节点1,背书节点2,背书节点3中的至少一半以上的节点该交易背书,这里即为3个
背书节点中的至少2个。
38.如图2中所示,以and{背书节点1,背书节点2,背书节点3}作为背书策略为例,所述应用将所述交易分别发送至背书节点1,背书节点2,背书节点3。
39.a2:所述背书节点对收到的交易提案进行验证后,模拟执行所述交易并背书,并返回提案响应(proposal response)至所述应用。
40.背书节点对交易内容进行验证后,可以模拟执行所述交易中的合约。背书节点对交易的验证,可以包括用账户a的公钥对所述交易签名进行验证,该交易之前没有被提交过(重放攻击保护),交易发起者是通道上的合格发起者等。通过验证后,按照上述的例子,背书节点进一步可以模拟执行发来的交易。在模拟执行的过程中,背书节点可以调用所述交易中指明的链码(具体是指明链码中的智能合约),并输入所述交易中的所述参数,进而模拟执行。
41.交易的执行结果,一般包括产生的读集(read set,rset或rs)和/或写集(write set,wset或ws)(rs和ws可以统称为读写集,或写为rwset)。这些读写集最终可以写入peer节点本地维护的区块链账本中。读集和写集,一般会采用key-value的表达形式。此外,读写集中一般还会带入版本(version)信息,表示读写集中的操作产生时所针对的版本。
42.对交易经过模拟执行并产生读写集之后,背书节点可以对产生的读写集背书。具体的,可以是背书节点根据背书策略用自身私钥对读写集进行签名。
43.延续前述例子,以and{背书节点1,背书节点2,背书节点3}作为背书策略的情况下,所述应背书节点1,背书节点2,背书节点3分别对所述交易进行模拟执行和背书,并分别发送背书结果至所述应用。这种背书策略下,不同背书节点对同一交易的背书结果一般仅是签名不同,否则不符合所述背书策略。
44.a3:所述应用收集背书节点的返回的提案响应。
45.所述应用可以收集背书节点返回的提案响应。如图2中所示,以and{背书节点1,背书节点2,背书节点3}作为背书策略为例,所述应用可以收集背书节点1,背书节点2,背书节点3返回的提案响应。具体的,所述应用中的sdk可以用于解析返回的提案响应。具体的,sdk可以验证提案响应中背书节点的签名,并比较各背书节点返回的提案响应,判断各提案响应是否一致(正常情况下应当是仅签名不一致)以及是否按照指定的背书策略执行。
46.a4:所述应用将所述背书的交易发送至排序节点。
47.当所述应用收集到足够多背书节点返回的一致的提案响应后,例如收集齐背书节点1,背书节点2,背书节点3返回的提案响应后,所述应用可以调用sdk将所述背书的交易发送至排序节点。其中背书的交易可以包括交易提案、读/写集和背书签名在内的打包结果。
48.a5:所述排序服务对这些交易排序,并基于排序后的结果生成区块。
49.排序服务可以持续的收集背书的交易,例如包括不同应用或者同一应用发来的至少一个经过背书的交易。具体的,排序服务中的排序节点在收集一定量的背书交易后,可以对这些交易排序。具体的,例如可以是按照交易的时间戳对交易排序。排序节点进而可以将排序后的交易打包成区块。
50.a6:所述排序服务将生成的所述区块广播至主节点,并由主节点同步至所属组织内其它peer节点。
51.不同组织组成的hyperledger fabric网络中,每个组织的一个或多个peer节点中
都存在一个主节点。主节点能与排序节点通信,从而从排序节点获取最新的区块并在组织内的peer节点中同步。
52.a7:记账节点对所述区块进行验证后将所述区块追加至本地账本的区块链中,并基于所述区块更新本地账本中的世界状态。
53.所有peer节点可以是记账节点。记账节点可以在本地维护账本。所述账本可以包括区块链数据和世界状态数据,如图3所示。
54.区块链包括一系列前后链接的区块。每个区块包括了区块头、区块数据和区块元数据三部分内容。
55.区块头包含区块编号(图3中的n0、n1、n2、n3...),每个区块的区块编号都是唯一的,且一般是单调递增的。区块编号可以由排序服务在打包生成区块的过程中生成。区块头还可以包含当前区块的区块数据的哈希值(图3中的ch,current block hash),以及前一个区块头的哈希值(图3中的ph0、ph1、ph2等,ph为previous block hash的缩写,也是前一区块的区块hash)。这样,区块链中的所有区块都被按序排列,并以密码学的方式连接在一起。这种哈希和链接使区块链账本数据变得非常安全。即使某个保存区块链账本的节点被篡改了数据,通过区块的hash值,其它节点可以快速的确认被篡改的区块链账本。例如图3中的区块2,其区块头2中,包括区块号n2,当前区块的区块数据2的hash值,前一区块1的区块头1的hash值。
56.区块数据包含了一个有序的交易列表。交易列表中的每个交易代表了一个对世界状态的查询或更新操作。如前所述,区块数据可以是在排序服务打包生成区块时写入到区块数据中。如图4所示,区块数据内可以包括一系列交易。这些交易可以是按照交易的时间进行排序的。每个交易可以包括交易头,交易签名,交易提案,交易响应,交易背书。
57.·
交易头记录了关于交易的一些重要元数据,例如相关链码的名字以及版本。
58.·
交易签名包含一个由客户端应用程序创建的签名,该字段可以用于判断交易是否被篡改。
59.·
交易提案包括经编码的应用程序提供给智能合约的输入参数。智能合约运行时,这个提案提供的输入参数和当前的世界状态一起决定新的世界状态。
60.·
交易响应以读写集的形式记录下世界状态之前和之后的值。
61.·
交易响应是智能合约的输出,如果交易验证成功,那么该交易会被应用到账本上,从而更新世界状态。
62.·
交易背书是一组签名的交易响应,这些签名来自背书策略规定的相关组织,并且这些组织的数量必须满足背书策略的要求。
63.区块元数据包含区块被写入的时间,还有区块写入者的证书、公钥以及签名。随后,区块的提交者也会为每一笔交易添加一个有效或无效的标记,但由于这一信息与区块同时产生,所以它不会被包含在区块头的当前区块哈希中。
64.需要说明的是,创始块(即图3中的区块0)一般不包含任何用户交易,而只包含一些配置交易。配置交易可以用来初始化世界状态。
65.世界状态是一个数据库,其存储了一组账本状态的当前值。通过世界状态可以访问一个账本状态的当前值,而不需要遍历整个交易日志来计算当前值。
66.世界状态的一个示例,记录的是两辆车car1和car2的信息,例如分别用两个状态
来记录。
67.第一个状态的k1-v1是:
68.{key=car1,value=audi}version=0
69.第二个状态中有一个更复杂的value值:
70.{key=car2,value={model:bmw,color:red,owner:jane}}version=0
71.整体上,第二个状态是一个key-value对(简写为k-v对),其中,value2中包含的也是k-v对,且上述示例中包含了三个不同的k-v对,这里设为v2中的三个k-v对分别为k21=model:v21=bmw,k22=color:v22=red,k23=owner:v23=jane。
72.两个状态的版本都是0,这也是每个状态的起始版本。每当状态更新时版本号可以递增。状态更新时会首先检查版本号version,以确保当前状态的版本与背书时的版本一致(避免并发更新)。
73.应用程序可以调用(invoke)智能合约来最终实现对世界状态进行put和delete等操作。一个例子中,应用1按照背书策略向组织1内的背书节点1、组织2内的背书节点2和组织3内的背书节点3发起了一笔交易t8,背书策略例如是“and{背书节点1,背书节点2,背书节点3}”。类似的,应用2也按照背书策略向组织1内的背书节点1、组织2内的背书节点2和组织3内的背书节点3发起了一笔交易t9,背书策略例如也是“and{背书节点1,背书节点2,背书节点3}”。
74.t8交易例如是:
75.《clientid=应用1,
76.chaincodeid=id1,
77.txpayload=[method1(k1)],
[0078]
timestamp,
[0079]
clientsig》
[0080]
该t8交易调用编号为id1的链码,例如是调用其中的方法method1,并输入参数k1。该method1例如是读取输入的参数所对应的value,即读取车辆的品牌。
[0081]
t9交易例如是:
[0082]
《clientid=应用1,
[0083]
chaincodeid=id1,
[0084]
txpayload=[method2(k23,"paul")]
[0085]
timestamp,
[0086]
clientsig》
[0087]
该t9交易调用编号为id1的链码,例如是调用其中的方法method2,并输入参数k23。该method2例如是修改车辆所属人的名字,一般是车辆发生转让的情形。
[0088]
t8、t9两个交易由各背书节点验证、模拟执行和背书后,各背书节点分别返回提案响应所述应用1和应用2。背书节点对交易内容进行模拟执行,例如对于t8、t9分别产生读写集如下:
[0089]
t8:read《k1》version=0
[0090]
t9:write《k23,paul》version=0
[0091]
其中的version=0表示产生的操作所针对的状态版本。
[0092]
背书节点可以对产生的读写集背书后分别返回提案响应所述应用1和应用2。例如对于t8交易,背书节点1、背书节点2、背书节点3分别对所述交易进行模拟执行和背书,并分别发送背书结果至所述应用1。对于t9交易,类似的,背书节点1、背书节点2、背书节点3分别对所述交易进行模拟执行和背书,并分别发送背书结果至所述应用2。
[0093]
应用1和应用2各自分别收集齐背书节点返回的提案响应后,可以将所述背书的交易发送至排序节点。其中背书的交易可以包括交易提案、读/写集和背书签名在内的打包结果。由所述排序服务对交易t8、t9排序,例如根据交易的时间戳,t8在前t9在后,则对t8、t9排序后的结果生成区块3。后续,排序服务可以将生成的区块3广播至组织1、组织2和组织3中的各个主节点,并由主节点同步至所属组织内其它peer节点。各个记账节点对所述区块进行验证后将所述区块追加至本地账本的区块链中,并基于所述区块更新本地账本中的世界状态。这时,区块3中的交易所影响的状态例如如下:
[0094]
k1-v1:
[0095]
{key=car1,value=audi}version=1
[0096]
k2-v2:
[0097]
{key=car2,value={model:bmw,color:red,owner:paul}}version=1
[0098]
上述背书节点对交易内容进行模拟执行,包括对调用链码的交易进行模拟执行,可以采用容器技术,即前述提到的链码容器。链码容器是指链码所运行的独立于背书节点进程的容器环境(docker)中,其作用是提供链码运行的隔离沙盒环境。容器是轻量级应用代码包,它还包含程序运行所需的依赖项,例如编程语言运行时的特定版本和运行软件服务所需的库。这样,智能合约的执行可以被隔离,也就不会因为错误或恶意代码而导致背书节点进程崩溃。在实例化链代码时,背书节点使用链码填充容器映像,并调用docker管理api来部署该映像。如果容器未运行,可以启动一个新容器。一旦运行,背书节点接收的提议都将被传输到该容器中以执行。
[0099]
前述提到,链码的执行需要安装链码,即背书节点上安装链码之后,经过实例化后才可以由应用发起调用。区块链上链码的部署包括对传统链码的部署和对外部链码的部署。外部链码可以在例如区块链的外部的节点上部署与执行,以方便用户独立管理每个外部节点及其代码的运行环境。传统链码是区别于外部链码而言的,传统链码由区块链内部的节点部署与执行。
[0100]
前述提到的容器技术,属于虚拟机化技术的一种。虚拟化技术实际上包括硬件虚拟化和容器技术。虚拟机使用的是硬件虚拟化技术。虚拟机需要虚拟硬件后安装完整的操作系统,进而才能安装/运行应用。如果每次发布应用,都采用虚拟机虚拟化出一个完整的操作系统,并设置好完整的依赖环境,将是比较繁琐的工作。容器技术相对而言更加轻量。容器中可以去除操作系统,而是包含应用程序和运行应用程序所依赖的系统环境。通过容器技术,可以把应用和依赖的环境打包,该打包的内容移植到其它相同操作系统的主机上仍然能正常运行。可见容器虚拟化技术的优势在于更加轻量化、容易迁移、部署方便、资源占用少等。此外,容器能够实现标准化。主流的一种容器技术是docker,此外还有诸如rocket、rkt和kata等。
[0101]
docker的核心概念包括:镜像(image)、容器(container)、仓库(registry)。
[0102]
docker的整个运行逻辑如图5所示。docker client(客户端)将需要执行的docker
命令发送给docker运行的主机(docker host)上的docker daemon(守护进程,也称为docker engine),docker daemon将该请求分解执行。例如:
[0103]
执行docker build命令,会根据dockerfile构建一个镜像存放于本地;
[0104]
执行docker pull命令,会从远端的容器镜像仓库拉取镜像到本地;
[0105]
执行docker run命令,会将容器镜像拉取并运行成为容器实例。
[0106]
镜像构建,包括将需要进行安装的依赖和目标文件根据dockerfile进行编写,并叠加进一个已有的基础镜像,生成新的镜像。容器运行时,会在容器镜像的上层生成一个container层,这个层是将这个完整的容器镜像的副本加载并中运行。加载进内存中的这个副本对于容器来说是可以进行修改的,但是仅限于运行在内存中;对container层的任何修改都不会对底层镜像生效,当容器消亡时所做的修改也一并消亡。dockerfile是上述执行docker build命令构建docker镜像时用到的一种的配置文件,它允许通过基本的语法来定义docker镜像,其中的每一条指令可以描述一个构建镜像的步骤。例如:
[0107]
在dockerfile中常用的命令包括以下几个:
[0108]
·
from:基于什么镜像构建
[0109]
·
workdir:容器的工作目录
[0110]
·
run:执行容器构建过程中的命令
[0111]
·
cmd&entrypoint:执行容器启动后的命令
[0112]
·
add&copy:添加指定的文件到容器镜像中
[0113]
·
env:设置环境变量
[0114]
·
expose:设置容器暴露的端口
[0115]
具体的,如图6所示,docker客户端将需要创建的请求发送给docker engine,如前所述docker engine是容器化的守护进程。docker engine可以将请求发送给containerd,并由containerd调用runc。containerd用于管理容器的生命周期,通过调用runc的api来实现对容器生命周期的管理。runc直接与容器所依赖的文件(如cgroup/linux kernel等)进行交互,负责为容器配置cgroup/namespace等启动容器所需的环境,创建启动容器的相关进程。图6中多了一个containerd-shim层(也称为垫片载体,类似于适配层),该container-shim的作用是将containerd和真实的容器(里的进程)解耦,允许runc在创建/运行容器之后退出。当containerd宕机时,containerd-shim能够保持,因此可以保证容器打开的文件描述符不会被关掉(从而可以对dockerd进行升级而服务不受影响)。依靠containerd-shim来收集/报告容器的退出状态,这样就不需要containerd来监视创建的子进程。例如,一个fabric的peer节点可以最终运行于图6最左侧的容器进程中,这个容器也可以称为peer容器。
[0116]
当容器实例越来越多的时候,容器管理的复杂性陡升。这时,kubernetes(简称为k8s)就派上了用场。k8s是一个开源的容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能,能帮助对容器进行部署、发布、编排等一系列操作,可以极大的简化容器的管理运维操作。
[0117]
在kubernetes中,可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。kubernetes集群架构以及相关的核心组件如图7所
示:一个kubernetes集群一般包含1个master节点和多个node节点,一个节点可以是一台物理机或虚拟机。master是k8s的集群控制节点,每个k8s集群里由一个master来负责整个集群的管理和控制。k8s集群中的其它机器被称为node节点,node节点是k8s集群中的工作负载节点,node可以被master分配一些工作负载;当某个node宕机时,其上的工作负载会被master自动转移到其它node上去。
[0118]
每个node节点上都运行着kubelet这一关键组件。kubelet是master在node节点上的agent(代理),与master密切协作,管理本机运行容器的生命周期,负责pod对应的容器的创建、启停等任务,实现集群管理的基本功能。pod是k8s中最小的部署单元,是一组容器的集合,也是k8s进行服务编排和缩扩容的基本单位。
[0119]
node节点可以在运行期间动态增加到k8s集群中,前提是这个node节点上已经正确安装、配置和启动了包括上述kubelet在内的一些关键组件。在默认情况下,kubelet会向master注册自己,一旦node被纳入集群管理范围,kubelet就会定时向master节点汇报自身的情况,例如操作系统、docker版本、机器的cpu和内存情况,以及之前有哪些pod在运行等,这样master可以获知每个node的资源使用情况,并实现高效均衡的资源调度策略。而某个node超过指定时间不上报信息时,会被master判定为“失联”,node的状态被标记为不可用(not ready),随后master会触发“工作负载大转移”的自动流程。
[0120]
此外,node节点还具有组件kube-proxy,用于在node节点上实现pod的网络代理,实现kubernetes service与外部的通信,并可以维护网络规则和四层负载均衡工作。kubernetes service位于kube-proxy和pod之间,其定义了一个服务的访问出入口。对于内部pod、container之间的访问可以直接通过service进行。图7中的kube-proxy,service(即kubernetes service)和pod之间的关系仅作为示意。实际上,一个service可以对应多个pod,一个pod也可以对应多个services。service可以由k8s创建,service与pod的关系也可以由k8s master中指定(图中未示出)。
[0121]
使用docker作为k8s容器运行时的话,kubelet需要先要通过docker-shim去调用docker engine,再通过docker engine调用containerd。docker-shim是kubernetes的一个组件,主要目的是为了通过cri(container runtime interface,容器运行时接口)操作docker。docker在2013年就出现了,2014年kubernetes发布并默认使用docker作为容器运行时(container runtime),而docker-shim首次正式出现是在2016年。docker在创建之初并没有考虑到容器编排或者是考虑kubernetes,因此docker本身并不符合cri,即不符合容器运行时接口。因此,kubernetes在创建之初便采用docker作为它的默认容器运行时,后续代码当中包含了很多对docker相关的操作逻辑。后期,kubernetes为了能够做解耦,兼容更多的容器运行时,将操作docker相关逻辑整体独立起来组成了docker-shim。整体上,使用docker作为k8s容器运行时的架构可以如图7所示,该图中在每个node最左侧的pod中示意了kubelet与pod中的多个container命令关系,而对其它pod中的container做了省略。其中,通信和命令关系可以如图8所示,如果使用docker作为k8s的容器运行时,kubelet需要先要通过docker-shim去调用docker,再通过docker去调用containerd。
[0122]
现有的fabric的peer节点大多通过kubernetes部署。如图6左下方左侧的容器进程中显示,该容器进程实际上可以运行一个peer节点,这个容器进程也可以称为peer容器。利用容器技术运行链码,最终期望在如图6所示的中间的容器进程中运行链码。
[0123]
利用容器技术运行链码,需要在容器中生成链码程序和该连码程序执行所需的运行环境。链码程序可以是一种二进制文件,即经过编译后得到的目标文件。运行环境即上述所说程序运行所需的依赖项等。传统链码中,节点上运行容器化的链码程序,需要与之适配的运行环境。为了降低用户的负担,让用户只需关注在高级语言层面开发链码的源码,而不用关注其在不同区块链节点上运行环境的差异,区块链接收到用户开发的链码的源代码后,可以结合kubernetes和docker来编译链码源代码并执行,从而实现轻量化、容易迁移、部署方便、资源占用少等优势,并实现容器集群的自动化部署、自动扩缩容、维护等功能。
[0124]
一种hyperledger fabric中部署传统链码的过程如图9中示意。需要说明的是,这里设定在采用kubernetes和docker技术的一个container中已经部署了peer容器,这个peer容器例如是container1,其中例如运行了背书节点。
[0125]
b1:客户端发起安装链码命令至要部署的背书节点,并将创建的链码源码及背书策略打包发送至所述节点。
[0126]
这里的客户端,指创建链码源码发送该链码源码的区块链客户端。开发人员创建链码源码后,可以打包链码源码并设定背书策略,之后可以将打包的链码源码和设定的背书策略通过客户端发送至要部署链码的背书节点。要部署链码的背书节点一般包括背书策略中所包含的背书节点。背书节点如图中所示为peer容器。
[0127]
b2:背书节点采用docker创建临时容器,并在创建的临时容器中将链码源码的编译为目标文件。
[0128]
根据客户端发送的链码源码的类型,背书节点可以采用docker(这里的docker主要包括图中的docker-shim和docker engine)创建相应的临时容器。对应的临时容器中包含对应源码语言的编译环境。背书节点本地或远程的镜像仓库中包含了编译多种链码源码的编译环境镜像,并可以由docker拉取和使用。这样,背书节点接收到一种类型的源码,可以采用docker创建包含对应编译环境的临时容器。例如,对于采用go语言编辑的源码,则创建适于go语言编译环境的临时容器;对于采用java语言编辑的源码,则创建适于java语言编译环境的临时容器;对于采用node.js语言编辑的源码,则创建适于node.js语言编译环境的临时容器。
[0129]
在创建的临时容器中,可以对源码进行编译,进而生成目标文件。类似的,对于go语言编辑的源码在临时容器中编译为binary文件,对于java语言源码在临时容器中编译为jar文件,对于node.js语言源码编译为目标代码。
[0130]
具体的,创建临时容器的过程中,peer容器可以根据客户端上传的链码源码的语言来生成一个第一配置文件,这里例如为dockerfile_1,其中的内容描述了创建临时容器的步骤。peer容器可以发送docker build命令及该dockerfile_1至docker-shim,进而发送至docker engine。docker engine可以根据dockerfile_1中指定的(本地或远程的)镜像仓库拉取适合编译链码源码的编译环境镜像,并将请求发送给containerd,再由containerd调用runc。执行上述指令的结果,是由runc拉起一个基于该编译环镜镜像构建的临时容器,这个临时容器例如是container2。
[0131]
在该临时容器中,基于该编译环镜可以对所述链码源码进行编译,从而得到链码程序,也就是上面的目标文件。
[0132]
需要说明的是,该临时容器由peer容器直接通过docker-shim激活,而不需要经过
k8s。
[0133]
b3:临时容器将编译完的目标文件放至某个目录下,并通知peer容器。
[0134]
b4:peer容器接收到通知后,采用docker构建包含所述目标文件的链码镜像。
[0135]
具体的,peer容器接收到通知后,可以根据目标文件生成一个第二配置文件,这里例如为dockerfile_2,其中的内容描述了构建链码镜像的步骤,并包括执行这个链码程序的运行环境的镜像和该链码程序的存储路径。peer容器可以发送docker build命令和该dockerfile_2,通过docker-shim调用到达docker engine。docker engine可以根据dockerfile_2中指定的(本地或远程的)镜像仓库拉取适合运行链码程序的运行环境镜像,并从前述存储路径拉取所述目标代码。这样可以重新生成一个新的包含该链码程序和运行环境的镜像,存放在本地/远程的仓库中。这个新生成的链码镜像,可以由该fabric网络上的当前宿主机或其它宿主机上的容器运行,从而实现一次打包、多处执行。这里的宿主机可以是物理机或虚拟机,甚至也可以是一个容器。
[0136]
b5:peer容器接收到调用所述链码的交易后,通过docker启动链码容器并在其中基于所述链码镜像安装和实例化所述链码。
[0137]
后续,peer容器接收到调用链码的交易后,如果传统链码容器并没有启动,则peer容器可以通过docker-shim向docker engine发起docker run指令,该指令发送给containerd,进而由containerd调用runc。这样,由runc拉起一个基于该链码镜像构建的传统链码容器,这个传统链码容器例如是container3。
[0138]
进而,peer容器可以向链码容器输入所述交易中的所述参数,进行链码模拟执行该交易。
[0139]
此外,也可以b3之后,还可以如图10所示,采用下面方式:
[0140]
b5':peer容器通过docker启动链码容器并在其中基于所述链码镜像安装和实例化所述链码。
[0141]
b4中,如前所述,peer容器接收到通知后,采用docker构建包含所述目标文件的链码镜像。peer容器除了可以发送docker build命令和该dockerfile_2至docker engine,还可以发送docker run命令至docker engine。该指令通过docker-shim和docker engine发送给containerd,进而由containerd调用runc。这样,由runc拉起一个基于该链码镜像构建的传统链码容器,这个传统链码例如是container3。也就是说,一旦链码镜像构建完成,就可以拉起该链码镜像构建的传统链码容器,而不必像b5中那样等待调用所述链码的交易后由peer节点触发拉起这个传统链码容器。这样,提前拉起传统链码容器,后续peer节点接收到调用该链码的交易请求后,可以直接调用该链码进行模拟执行,而不是临时再拉起传统链码容器后再调用该链码进行模拟执行,显然这样的方式可以提高合约的执行速度。
[0142]
可见,上述过程中docker engine的主要作用在于构建镜像,并且与docker engine的通信大都需要通过docker shim进行。在采用kubernetes和docker技术的fabric 2.0(以及后续的版本)中部署传统链码的过程,都很依赖于docker,具体是很依赖于docker-shim和docker engine。此外,如前所述,使用docker作为k8s容器运行时的话,kubelet需要先要通过docker-shim去调用docker engine,再通过docker engine调用containerd。
[0143]
如前所述,docker-shim是kubernetes的一个组件,主要目的是为了通过cri操作
docker,具体是上述的docker engine。docker在创建之初并没有考虑到容器编排或者是考虑kubernetes,但kubernetes在创建之初便采用docker作为它的默认容器运行时,后续代码当中包含了很多对docker相关的操作逻辑。后期kubernetes为了能够做解耦,兼容更多的容器运行时,将操作docker相关逻辑整体独立起来组成了docker-shim。
[0144]
而containerd是容器技术标准化之后的产物,为了能够兼容oci(开放容器组织)标准,将容器运行时及其管理功能从docker daemon剥离。containerd向上可以为docker daemon提供接口,使得docker daemon可以屏蔽下面的结构变化,确保原有接口向下兼容,向下可以通过containerd-shim结合runc,使得引擎可以独立升级,避免之前docker daemon升级会导致所有容器不可用的问题。runc是一个命令行工具端,可以根据oci的标准来创建和运行容器。
[0145]
grpc是一种rpc的实现,由google公司开发,是一种高性能、开源和通用的rpc框架,面向移动和http/2设计,支持众多常见的编程语言,还提供了强大的流式调用能力,目前已经成为最主流的rpc框架之一。在服务端实现定义的服务接口,并运行一个grpc服务器来处理grpc客户端调用。而grpc客户端发起调用至grpc服务端,需要获得grpc服务端的地址和端口等信息。grpc服务端并不会主动发起向grpc客户端的连接,而需要grpc客户端主动发起向grpc服务端的连接。grpc是本技术中一种优选的实现,实际上具有类似功能的通信客户端和通信服务端在本技术中都可以实现,以下仍然以grpc为例说明。
[0146]
上述方案中,peer容器接收到所述安装传统链码的指令后,peer容器可以设置为grpc服务端。通过b5或这b5'创建传统链码容器,可以在创建传统链码容器的指令中包含peer容器自身的地址和端口,并可以置于connection.json文件中发送至传统链码容器。这样,创建的传统链码容器可以设置为grpc客户端。进而,传统链码容器被构建后,可以基于connection.json文件中grpc服务端的地址和端口向peer容器发起连接。传统链码容器通过grpc客户端发起与peer容器的连接后可以保持长连接。
[0147]
后续,peer容器接收到调用链码的交易后,可以将该交易通过保持的长连接发送至传统链码容器,从而实现对链码的调用。传统链码容器中执行调用链码的交易后,如前所述,可以将执行结果即读/写集通过保持的长连接返回至grpc服务端,即返回至peer容器。
[0148]
理论上,即使不运行docker engine,也能够直接通过containerd来管理容器,这样也就可以不需要docker-shim。
[0149]
k8s发布cri(container runtime interface),统一了容器运行时接口,凡是支持cri的容器运行时,都可以作为k8s的底层容器运行时。kubernetes在1.20版本中提到将不再在后续的版本维护docker-shim垫片,并最早将在1.23版本中开始移除该垫片。docker-shim被移除,这也因此移除了对docker作为容器运行时的支持。如前所述,containerd是从docker中分离出来的一个项目,其本身可以作为一个底层容器运行时,现在它成了kubernete容器运行时更好的选择。不仅仅是docker,还有很多云平台也支持containerd作为底层容器运行时。除了containerd,还有cri-o等可以作为底层容器运行时。
[0150]
如果使用containerd作为k8s容器运行时,containerd可以内置cri插件,从而kubelet可以直接调用containerd,如图11所示。显然的,kubelet通过cri直接调用containerd,可以缩短通信链路,从而可以提高性能,而且取出docker后资源占用也会变小(docker不是一个纯粹的容器运行时,具有大量其它功能,因此它的存在更耗资源)。
[0151]
一种hyperledger fabric中部署链码的过程可以如图12中所示。这里仍然设定在采用kubernetes和docker技术的一个container中已经部署了peer容器,这个peer容器例如是container1,其中例如运行了背书节点。并包括如下:
[0152]
s110:peer容器接收客户端发来的安装传统链码的命令和链码源码。
[0153]
客户端可以与图9中的b1过程类似,发起安装链码命令至要部署的背书节点,并将创建的链码源码及背书策略打包发送至所述节点。开发人员创建链码源码后,可以打包链码源码并设定背书策略,之后可以将打包的链码源码和设定的背书策略通过客户端发送至要部署链码的背书节点。要部署链码的背书节点一般包括背书策略中所包含的背书节点。
[0154]
如图1及对应文字所述,fabric可以包括多个组织,每个组织可以有多个peer。如前所述,这里可以设定在采用kubernetes和containerd技术的一个container中已经部署了peer节点,可以称为peer容器。peer容器可以内置cckeeper模块,或者该cckeeper模块位于peer容器之外。
[0155]
s120:所述peer容器采用第三方构建模块基于所述链码源码构建链码镜像。
[0156]
peer容器接收客户端发来的安装传统链码的命令和链码源码后,可以将该安装传统链码的命令和链码源码发送至内置或外置的cckeeper模块,这个cckeeper即第三方构建模块。cckeeper模块接收到客户端发来的链码源码,可以生成一个第三配置文件(dockerfile),这里设为dockerfile_3。dockerfile_3里可以包括对创建镜像构建容器的描述。
[0157]
构建链码镜像,如前所述,包括编译得到链码程序和将编译得到链码程序加入到一个运行环境中生成镜像。
[0158]
所述peer容器可以发送创建镜像构建容器的任务至k8s的master,具体可以由该cckeeper发送。这样,参考图7,master可以向一个node中的kubelet发起任务。kubelet收到该任务后,通过cri插件发送创建container的命令至containerd,进而containerd调用runc,从而可以创建一个镜像构建容器,例如是container4。
[0159]
另一方面cckeeper模块生成dockerfile_3后,可以发送dockerfile_3至imgbuilder(容器镜像构建工具),进而imgbuilder可以根据dockerfile_3中的内容拉取一个编译环境镜像,这个镜像中的内容适于编译所述链码源码。imgbuilder例如可以包括kaniko容器镜像工具,该工具是谷歌开源的一个容器镜像构建工具,具备了imgbuilder模块要求的功能。imgbuilder可在创建的镜像构建容器中执行镜像构建任务。在该镜像构建容器中,imgbuilder基于该编译环镜可以对所述链码源码进行编译,从而得到链码程序,也就是上面的目标文件。
[0160]
imgbuilder可以将生成的链码程序存储于一个路径下,并通知cckeeper。可以是通过peer容器通知cckeeper,也可以是直接通知cckeeper,图13中仅示出了一种,即前者的实现方式。
[0161]
cckeeper模块接收到通知后,可以根据目标文件生成一个第四配置文件,这里例如为dockerfile_4,其中的内容描述了构建链码镜像的步骤,并包括执行这个链码程序的运行环境的镜像和该链码程序的存储路径。cckeeper可以发送构建链码镜像指令至imgbuilder。imgbuilder可以根据dockerfile_4中指定的(本地或远程的)镜像仓库拉取适合运行链码程序的运行环境镜像,并从前述存储路径拉取所述目标代码。这样可以重新生
成一个新的包含该链码程序和运行环境的镜像,并存放在本地/远程的镜像仓库中。这个新生成的链码镜像,可以由该fabric网络上的当前宿主机或其它宿主机上的容器运行,从而实现一次打包、多处执行。这里的宿主机可以是物理机或虚拟机,甚至也可以是一个容器。
[0162]
s130:第三方构建模块启动传统链码容器,并在传统链码容器中载入并启动所述链码镜像。
[0163]
这里,可以是在cckeeper构建链码完成后即启动链码容器,也可以是peer容器在接收到调用链码的交易请求后触发cckeeper启动链码容器。
[0164]
前者例如是peer容器通过cckeeper启动链码容器并在其中基于所述链码镜像安装和实例化所述链码。具体的,imgbuilder构建链码镜像完毕后,可以发送一个通知至cckeeper。cckeeper接收到通知后,可以拉起一个基于该链码镜像构建的传统链码容器,这个传统链码容器例如是container5。也就是说,一旦链码镜像构建完成,就可以拉起该链码镜像构建的传统链码容器。这样,提前拉起传统链码容器,后续peer节点接收到调用该链码的交易请求后,可以直接调用该链码进行模拟执行,而不是临时再拉起传统链码容器后再调用该链码进行模拟执行,显然这样的方式可以提高合约的执行速度。
[0165]
后者例如是peer容器接收到调用所述链码的交易后,通过cckeeper启动链码容器并在其中基于所述链码镜像安装和实例化所述链码。具体的,imgbuilder构建链码镜像完毕后,可以发送一个通知至cckeeper,从而cckeeper可以获得链码镜像的存储路径。peer容器接收到调用链码的交易后,如果传统链码容器并没有启动,则peer容器可以调用cckeeper,由cckeeper拉起一个基于该链码镜像构建的传统链码容器,这个传统链码容器例如是container5。
[0166]
进而,peer容器可以向链码容器输入所述交易中的所述参数,进行链码模拟执行该交易。
[0167]
peer容器可以设置为grpc服务端。s120或者s130中,所述peer容器采用第三方构建模块基于所述链码源码构建链码镜像,或peer容器在接收到调用链码的交易请求后触发cckeeper启动链码容器中,peer容器可以将自身的ip地址、端口等信息发送至cckeeper。进而,cckeeper创建传统链码容器时,可以发送一个connection.json文件,该文件中可以包括上述peer容器的ip地址、端口等信息。传统链码容器启动后,通过connection.json可以知道当前grpc服务端的ip地址和端口等信息。进而,传统链码容器可以设置自身为grpc的客户端。传统链码容器进而可以通过grpc客户端发起与peer容器的连接,并可以保持长连接。进而,peer容器在接收到调用链码的交易请求后,可以通过保持的长连接向传统链码容器发起调用,输入所述交易中的所述参数,进行链码模拟执行该交易。传统链码容器中执行调用链码的交易后,也可以将执行结果即读/写集通过保持的长连接返回至grpc服务端,即返回至peer容器。
[0168]
通过上述过程,使得开发者在开发链码源码时还是按照传统链码的方式编写而无需做出改变,这样给链码开发者没有增加额外的开发成本。同时,通过由第三方构建模块构建链码镜像,摆脱了对docker的依赖。
[0169]
以下以一个hyperledger fabric中的具体例子来说明联盟链中部署链码的过程,可以如图13中所示,包括:
[0170]
c1:客户端发送安装传统链码的命令和链码源码至peer容器,peer容器发送该连
码源码至cckeeper。
[0171]
如前所述,这里可以设定在采用kubernetes和containerd技术的一个container中已经部署了peer节点,可以称为peer容器。用户创建链码源码后,可以通过客户端将安装传统链码的命令和该链码源码发消息至相连的peer容器。
[0172]
peer容器可以将客户端发来的安装传统链码的命令和链码源码发送至cckeeper。
[0173]
cckeeper可以根据链码源码生成一个第三配置文件(dockerfile),这里设为dockerfile_3。dockerfile_3里可以包括对创建镜像构建容器的描述。
[0174]
cckeeper模块可以内置于peer容器,或者该cckeeper模块可以设置于peer容器之外。以下以后者为例进行说明,cckeeper模块内置于peer容器的情形与此类似。
[0175]
c2:cckeeper采用创建镜像构建容器,并在其中将链码源码编译为目标文件。
[0176]
具体的,cckeeper可以发送创建镜像构建容器的任务至k8s的master。这样,参考图7,master可以向一个node中的kubelet发起任务。kubelet收到该任务后,通过cri插件发送创建container的命令至containerd,进而containerd调用runc,从而可以创建一个镜像构建容器,例如是container4。
[0177]
另一方面cckeeper生成dockerfile_3后,可以发送dockerfile_3至imgbuilder,进而imgbuilder可以根据dockerfile_3中的内容拉取一个编译环境镜像,这个镜像中的内容适于编译所述链码源码。imgbuilder例如可以包括kaniko容器镜像工具,该工具是谷歌开源的一个容器镜像构建工具,具备了imgbuilder模块要求的功能。imgbuilder可在创建的镜像构建容器中执行镜像构建任务。在该镜像构建容器中,imgbuilder基于该编译环镜可以对所述链码源码进行编译,从而得到链码程序,也就是上面的目标文件。imgbuilder可以将生成的链码程序存储于一个路径下,并通知cckeeper。
[0178]
上述过程中,kubelet可以通过cri与containerd通信,进而发送构建镜像的相关命令至containerd。这样,在取消docker-shim和docker-engine后,在保持构建镜像链路畅通的情况下精简了链路,如前所述提高性能并降低了资源占用。
[0179]
c3:镜像构建容器将编译完的目标文件放至某个目录下,并通知peer容器/cckeeper。
[0180]
c4:cckeeper采用imgbuilder构建包含所述目标文件的链码镜像,并存储于镜像仓库中。
[0181]
cckeeper可以接收到c3中的通知。之后,cckeeper可以根据目标文件生成一个第四配置文件,这里例如为dockerfile_4,其中的内容描述了构建链码镜像的步骤,并包括执行这个链码程序的运行环境的镜像和该链码程序的存储路径。cckeeper可以发送构建链码镜像指令至imgbuilder。imgbuilder可以根据dockerfile_4中指定的(本地或远程的)镜像仓库拉取适合运行链码程序的运行环境镜像,并从前述存储路径拉取所述目标代码。这样可以重新生成一个新的包含该链码程序和运行环境的镜像,并存放在本地/远程的镜像仓库中。这个新生成的链码镜像,可以由该fabric网络上的当前宿主机或其它宿主机上的容器运行,从而实现一次打包、多处执行。这里的宿主机可以是物理机或虚拟机,甚至也可以是一个容器。
[0182]
imgbuilder完成链码镜像的构建后,可以发送通知至cckeeper,cckeeper可以通知peer容器。
[0183]
c5:cckeeper创建传统链码容器,并在所述传统链码容器中载入并启动所述链码镜像。
[0184]
peer容器可以设置为grpc服务端。
[0185]
cckeeper可以采用符合cri的容器运行时创建链码容器。具体的,cckeeper可以发送创建链码容器的命令至master,master将该命令通知至node中的kubelet,kubelet进一步可以采用包含cri插件的containerd创建container。在这一过程中,cckeeper可以通过connection.json文件发送所述peer容器的ip地址、端口等信息至传统链码容器。
[0186]
传统链码容器启动后,可以运行所述链码镜像。通过一系列指令,可以从所述镜像仓库中拉取构建的链码镜像并在pod的一个container中运行,从而生成链码容器。通过connection.json可以知道当前grpc服务端的ip地址和端口等信息。进而,传统链码容器可以设置自身为grpc的客户端。传统链码容器进而可以通过grpc客户端发起与peer容器的连接,并可以保持长连接。进而,peer容器在接收到调用链码的交易请求后,可以通过保持的长连接向传统链码容器发起调用,输入所述交易中的所述参数,进行链码模拟执行该交易。传统链码容器中执行调用链码的交易后,也可以将执行结果即读/写集通过保持的长连接返回至grpc服务端,即返回至peer容器。
[0187]
通过上述过程,使得开发者在开发链码源码时还是按照传统链码的方式编写而无需做出改变,这样给链码开发者没有增加额外的开发成本。同时,通过由第三方构建模块构建链码镜像,摆脱了对docker的依赖。
[0188]
以下介绍本技术一种hyperledger fabric中部署链码的系统实施例,包括:
[0189]
peer容器,用于接收客户端发来的安装传统链码的命令和链码源码,还采用第三方构建模块基于所述链码源码构建链码镜像;
[0190]
所述第三方构建模块,用于启动传统链码容器,并在所述传统链码容器中载入并启动所述链码镜像;
[0191]
传统链码容器,用于运行链码。
[0192]
其中,所述peer容器采用第三方构建模块基于所述链码源码构建链码镜像,其中,第三方构建模块调用容器镜像构建工具基于所述链码源码及适配的运行环境构建链码镜像。
[0193]
其中,所述第三方构建模块调用容器镜像构建工具基于所述链码源码及适配的运行环境构建链码镜像,包括:
[0194]
第三方构建模块调用容器镜像构建工具,所述将客户端发来的链码源码编译得到链码程序;
[0195]
第三方构建模块调用容器镜像构建工具,将所述链码程序加入到适配的运行环境中并生成链码镜像。
[0196]
其中,所述第三方构建模块调用容器镜像构建工具,所述将客户端发来的链码源码编译得到链码程序,包括:
[0197]
第三方构建模块基于所述链码源码生成第三配置文件并发送至容器镜像构建工具,并创建镜像构建容器;
[0198]
所述容器镜像构建工具根据第三配置文件拉取编译环境镜像,并在所述镜像构建容器中执行镜像构建任务,得到编译后的链码程序。
[0199]
其中,所述第三方构建模块调用容器镜像构建工具,将所述链码程序加入到适配的运行环境中并生成链码镜像,包括:
[0200]
第三方构建模块基于生成的链码程序生成第四配置文件;
[0201]
所述第三方构建模块调用容器镜像构建工具并将该第四配置文件发送至所述容器镜像构建工具;
[0202]
所述容器镜像构建工具根据第四配置文件拉取运行环境镜像,并生成包含所述链码程序和运行环境的链码镜像。
[0203]
其中,所述第三方构建模块启动传统链码容器,并在所述传统链码容器中载入并启动所述链码镜像,包括:
[0204]
第三方构建模块构建链码完成后即启动链码容器,并在所述传统链码容器中载入并启动所述链码镜像;或,
[0205]
peer容器在接收到调用链码的交易请求后触发第三方构建模块启动链码容器,并在所述传统链码容器中载入并启动所述链码镜像。
[0206]
其中,所述peer容器设置为grpc服务端,所述启动后的传统链码容器设置为grpc客户端,且peer容器与传统链码容器之间保持长连接。
[0207]
其中,第三方构建模块设置于所述peer容器内或peer容器外。
[0208]
在20世纪90年代,对于一个技术的改进可以很明显地区分是硬件上的改进(例如,对二极管、晶体管、开关等电路结构的改进)还是软件上的改进(对于方法流程的改进)。然而,随着技术的发展,当今的很多方法流程的改进已经可以视为硬件电路结构的直接改进。设计人员几乎都通过将改进的方法流程编程到硬件电路中来得到相应的硬件电路结构。因此,不能说一个方法流程的改进就不能用硬件实体模块来实现。例如,可编程逻辑器件(programmable logic device,pld)(例如现场可编程门阵列(field programmable gate array,fpga))就是这样一种集成电路,其逻辑功能由用户对器件编程来确定。由设计人员自行编程来把一个数字系统“集成”在一片pld上,而不需要请芯片制造厂商来设计和制作专用的集成电路芯片。而且,如今,取代手工地制作集成电路芯片,这种编程也多半改用“逻辑编译器(logic compiler)”软件来实现,它与程序开发撰写时所用的软件编译器相类似,而要编译之前的原始代码也得用特定的编程语言来撰写,此称之为硬件描述语言(hardware description language,hdl),而hdl也并非仅有一种,而是有许多种,如abel(advanced boolean expression language)、ahdl(altera hardware description language)、confluence、cupl(cornell university programming language)、hdcal、jhdl(java hardware description language)、lava、lola、myhdl、palasm、rhdl(ruby hardware description language)等,目前最普遍使用的是vhdl(very-high-speed integrated circuit hardware description language)与verilog。本领域技术人员也应该清楚,只需要将方法流程用上述几种硬件描述语言稍作逻辑编程并编程到集成电路中,就可以很容易得到实现该逻辑方法流程的硬件电路。
[0209]
控制器可以按任何适当的方式实现,例如,控制器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(application specific integrated circuit,asic)、可编程逻辑控制器和嵌入微控制器的形式,控制器的例子包括但不限于以下微控制
器:arc 625d、atmel at91sam、microchip pic18f26k20以及silicone labs c8051f320,存储器控制器还可以被实现为存储器的控制逻辑的一部分。本领域技术人员也知道,除了以纯计算机可读程序代码方式实现控制器以外,完全可以通过将方法步骤进行逻辑编程来使得控制器以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入微控制器等的形式来实现相同功能。因此这种控制器可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构。或者甚至,可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0210]
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为服务器系统。当然,本技术不排除随着未来计算机技术的发展,实现上述实施例功能的计算机例如可以为个人计算机、膝上型计算机、车载人机交互设备、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。
[0211]
虽然本说明书一个或多个实施例提供了如实施例或流程图所述的方法操作步骤,但基于常规或者无创造性的手段可以包括更多或者更少的操作步骤。实施例中列举的步骤顺序仅仅为众多步骤执行顺序中的一种方式,不代表唯一的执行顺序。在实际中的装置或终端产品执行时,可以按照实施例或者附图所示的方法顺序执行或者并行执行(例如并行处理器或者多线程处理的环境,甚至为分布式数据处理环境)。术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、产品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、产品或者设备所固有的要素。在没有更多限制的情况下,并不排除在包括所述要素的过程、方法、产品或者设备中还存在另外的相同或等同要素。例如若使用到第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
[0212]
为了描述的方便,描述以上装置时以功能分为各种模块分别描述。当然,在实施本说明书一个或多个时可以把各模块的功能在同一个或多个软件和/或硬件中实现,也可以将实现同一功能的模块由多个子模块或子单元的组合实现等。以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0213]
本发明是参照根据本发明实施例的方法、装置(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0214]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或
多个方框中指定的功能。
[0215]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0216]
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
[0217]
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
[0218]
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储、石墨烯存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
[0219]
本领域技术人员应明白,本说明书一个或多个实施例可提供为方法、系统或计算机程序产品。因此,本说明书一个或多个实施例可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本说明书一个或多个实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0220]
本说明书一个或多个实施例可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本本说明书一个或多个实施例,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
[0221]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本说明书的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特
征进行结合和组合。
[0222]
以上所述仅为本说明书一个或多个实施例的实施例而已,并不用于限制本本说明书一个或多个实施例。对于本领域技术人员来说,本说明书一个或多个实施例可以有各种更改和变化。凡在本说明书的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。