技术特征:
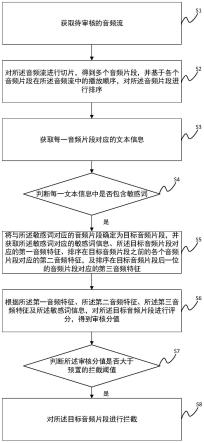
1.一种音频审核方法,其特征在于,包括:获取待审核的音频流;对所述音频流进行切片,得到多个音频片段,并基于各个音频片段在所述音频流中的播放顺序,对所述音频片段进行排序;获取每一音频片段对应的文本信息;判断每一文本信息中是否包含敏感词;若所述文本信息中包含敏感词,将与所述敏感词对应的音频片段确定为目标音频片段,并获取所述敏感词对应的敏感词信息、所述目标音频片段对应的第一音频特征、排序在目标音频片段之前的各个音频片段对应的第二音频特征,及排序在目标音频片段后一位的音频片段对应的第三音频特征;根据所述第一音频特征、所述第二音频特征、所述第三音频特征及所述敏感词信息,对所述目标音频片段进行评分,得到审核分值;判断所述审核分值是否大于预置的拦截阈值;若所述审核分值大于所述拦截阈值,则对所述目标音频片段进行拦截。2.根据权利要求1所述的方法,其特征在于,获取所述敏感词对应的敏感词信息,包括:通过预设的敏感词与类型及等级一一对应的敏感词表,确定所述敏感词对应的敏感词等级及敏感词类型。3.根据权利要求2所述的方法,其特征在于,所述文本信息中包含多个敏感词;所述通过预设的敏感词与类型及等级一一对应的敏感词表,确定所述敏感词对应的敏感词等级及敏感词类型,包括:通过所述敏感词表,确定每一敏感词对应的敏感词等级;将敏感词等级最高的敏感词,确定为目标敏感词;查询所述敏感词表,获取所述目标敏感词对应的敏感词类型,所述敏感词信息中包括所述目标敏感词对应的敏感词类型及敏感词等级。4.根据权利要求1所述的方法,其特征在于,获取所述目标音频片段对应的第一音频特征,包括:获取所述目标音频片段对应的第一情绪类型及第一短时能量值;获取排序在目标音频片段之前的各个音频片段对应的第二音频特征,包括:获取排序在目标音频片段之前的各个音频片段对应的第二短时能量值;获取排序在目标音频片段前一位的音频片段对应的第二情绪类型;获取排序在目标音频片段后一位的音频片段对应的第三音频特征,包括:获取排序在目标音频片段后一位的音频片段对应的第三短时能量值;获取排序在目标音频片段后一位的音频片段对应的第三情绪类型;根据所述第一音频特征、所述第二音频特征、所述第三音频特征及所述敏感词信息,对所述目标音频片段进行评分,得到审核分值,包括:根据所述第一情绪类型、所述第一短时能量值、所述第二短时能量值、所述第二情绪类型、所述第三短时能量值、所述第三情绪类型及所述敏感词信息,对所述目标音频片段进行评分,得到审核分值。5.根据权利要求4所述的方法,其特征在于,根据所述第一情绪类型、所述第一短时能
量值、所述第二短时能量值、所述第二情绪类型、所述第三短时能量值、所述第三情绪类型及所述敏感词信息,对所述目标音频片段进行评分,得到审核分值,包括:计算所述第二短时能量值的平均值,作为短时能量平均值;将所述第一短时能量值与所述短时能量平均值之差的平方,作为情绪波动值;确定与所述第一情绪类型的激烈程度匹配的分值,作为第一情绪分值;确定与所述第二情绪类型的激烈程度匹配的分值,作为第二情绪分值;确定与所述情绪波动值的大小程度匹配的分值,作为第三情绪分值;确定与所述第三情绪类型的激烈程度匹配的分值,作为第四情绪分值;确定与所述第一短时能量值的大小程度匹配的分值,作为第一短时能量分值;确定与排序在目标音频片段前一位的音频片段对应的第二短时能量值大小程度匹配的分值,作为第二短时能量分值;确定与所述短时能量平均值的大小程度匹配的分值,作为第三短时能量分值;确定与所述第三短时能量值的大小程度匹配的分值,作为第四短时能量分值;确定与所述敏感词信息匹配的分值,作为敏感分值;将所述第一情绪分值、所述第二情绪分值、所述第三情绪分值、所述第四情绪分值、所述第一短时能量分值、所述第二短时能量分值、第三短时能量分值、所述第四短时能量分值及所述敏感分值相加,得到审核分值。6.根据权利要求4所述的方法,其特征在于,获取所述目标音频片段对应的第一情绪类型,包括:将所述目标音频片段输入至情绪分类模型中,得到目标音频片段对应的第一情绪类型;获取排序在目标音频片段前一位的音频片段对应的第二情绪类型,包括:将排序在目标音频片段前一位的音频片段输入至情绪分类模型中,得到所述排序在目标音频片段前一位的音频片段对应的第二情绪类型;获取排序在目标音频片段后一位的音频片段对应的第三情绪类型,包括:将排序在目标音频片段后一位的音频片段输入至情绪分类模型中,得到所述排序在目标音频片段后一位的音频片段对应的第三情绪类型;其中,所述情绪分类模型,以音频为训练样本,以音频对应的情绪类型为样本标签训练得到。7.根据权利要求1所述的方法,其特征在于,所述获取每一音频片段对应的文本信息,包括:对所述每一音频片段进行编码,得到编码结果;将所述编码结果输入至声学模型中,得到所述编码结果对应的文字信息,所述声学模型,以音频为训练样本,以音频对应的文字为样本标签,训练得到;将所述文字信息输入至语言模型中,得到所述文字信息所组成的语句,所述语言模型,以文字集合为训练样本,以文字集合所组成的语句为样本标签,训练得到。8.一种音频审核装置,其特征在于,包括:音频流获取单元,用于获取待审核的音频流;音频切片单元,用于对所述音频流进行切片,得到多个音频片段,并基于各个音频片段
在所述音频流中的播放顺序,对所述音频片段进行排序;文本信息获取单元,用于获取每一音频片段对应的文本信息;敏感词判断单元,用于判断每一文本信息中是否包含敏感词;特征获取单元,用于若所述文本信息中包含敏感词,将与所述敏感词对应的音频片段确定为目标音频片段,并获取所述敏感词对应的敏感词信息、所述目标音频片段对应的第一音频特征、排序在目标音频片段之前的各个音频片段对应的第二音频特征,及排序在目标音频片段后一位的音频片段对应的第三音频特征;音频评分单元,用于根据所述第一音频特征、所述第二音频特征、所述第三音频特征及所述敏感词信息,对所述目标音频片段进行评分,得到审核分值;分值比较单元,用于将所述审核分值与拦截阈值进行比较;音频拦截单元,用于若所述审核分值大于所述风险阈值,则对所述目标音频片段进行拦截。9.一种音频审核设备,其特征在于,包括存储器和处理器;所述存储器,用于存储程序;所述处理器,用于执行所述程序,实现如权利要求1-7中任一项所述的音频审核方法的各个步骤。10.一种可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现如权利要求1-7任一项的音频审核方法的各个步骤。
技术总结
本申请公开了音频审核方法、装置、设备及可读存储介质,该方法包括:对音频流进行切片,得到多个音频片段,并对音频片段进行排序;获取每一音频片段对应的文本信息;若文本信息中包含敏感词,将与敏感词对应的音频片段确定为目标音频片段,并获取敏感词对应的敏感词信息、目标音频片段对应的第一音频特征,及排在目标音频片段前后的各个音频片段对应的第二音频特征及第三音频特征;对目标音频片段进行评分,得到审核分值;若审核分值大于拦截阈值,对目标音频片段进行拦截。可见,本申请可以提高音频审核的准确性。此外,确定审核分值时,既考虑目标音频片段,又考虑播放顺序在目标音频片段前后的音频片段,进一步提高了音频审核的准确率。准确率。准确率。
技术研发人员:吴文亮 马金龙 徐志坚 谢睿 陈光尧 邓其春 王伟喆 张政统 曾锐鸿 黎子骏
受保护的技术使用者:广州欢城文化传媒有限公司
技术研发日:2022.03.15
技术公布日:2022/6/24
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。