1.本发明属于网络及信息安全技术领域,尤其涉及一种基于注意力机制的多元特征融合恶意软件检测方法。
背景技术:
2.恶意软件api序列。api是windows操作系统在动态连接库中给用户提供系统服务的接口函数,运行在用户模式下或内核模式下。其中在内核模式下运行的api就是native api,是动态连接库中的内核级系统服务的接口函数,其与用户模式下的api有很大的区别。native api调用序列能够在内核级层次上反映应用程序的特征,因此能够用来作为异常检测的数据源。动态api调用序列的提取是一个自动化的动态分析过程,它通过在真机分析环境中动态运行和监控每个pe文件得到其真实且完整的api调用序列。由于可移植执行文件对应用程序接口(application programming interface,api)的调用能够反映出文件的行为信息,因此作为基于动态特征的智能恶意代码检测方法使用的最有效的特征之一。
3.注意力机制(attention机制),attention机制最早是用于对话系统或机器翻译等任务中,主要是受人的注意力的启发,人在阅读时一般只会重点关注能够解决问题的关键信息,模型处理机制是通过合理分配注意力,对关键的部分分配较多的注意力,而对于非关键部分分配较少的注意力。attention机制能够模仿人的思维方式,其原理是在decoder阶段计算出输入序列中每个元素对于当前输出y的注意力分布概率,使得对于每个输出,可以计算唯一的对应中间语义编码c,这样模型对于不一样的输入分配了不同的权值,突出权值大的数据,弱化权值小的数据,从而改善分类效果。
4.卷积神经网络(cnn),卷积神经网络(cnn)最早应用于计算机视觉中,yoon kim首次提出textcnn。将卷积神经网络cnn应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息,从而能够更好地捕捉局部相关性。卷积层已成功地应用于序列分类和文本分类问题。cnn主要通过卷积层和池化层来学习输入的局部特征,对表征的重要信息进行提取与保留。cnn无需过多的预处理工作便能够达到预定效果,显著地减轻了对特征工程的依赖。cnn主要由输入层、卷积层、池化层和全连接层组成。对于应用于自然语言处理及序列处理领域的cnn而言,输入层为词汇的向量表示。
5.门限循环单元gru,门限循环单元是对循环神经网络的改进。gru通过引入更新门与重置门,有效地解决了rnn网络在训练过程的梯度爆炸与梯度弥散问题。相较lstm而言,gru精简了网络结构,减少了模型参数,提升了模型训练速度。在序列数据处理任务中,gru网络可以学习词语在句子中的长期依赖关系,更好地对文本进行表征建模。gru网络通过记忆单元来记忆存储句子中重要的特征信息,同时能够对不重要信息进行遗忘。
6.目前,恶意软件成为威胁计算机系统安全和网络发展的重要问题。传统检测方法必须获得恶意软件的签名之后才能对其进行检测,使得计算机感染新型恶意软件的概率增加并且为检测到恶意软件增多困难。随着机器学习被用于恶意软件检测领域,恶意软件检测技术配合使用机器学习可以在一定程度上提高泛化能力,提升恶意样本的识别率,但仍
然无法很好的兼顾序列之间的关系,未对api的参数进行合理利用,丢失了大量原始信息,且难于在其他数据集的基础上验证模型的准确性与泛化性。基于深度学习的恶意样本检测成为热点,前向神经网络兴起之后,深度学习模型卷积神经网络(cnn)和循环神经(rnn)以及它们的改进版本成为恶意样本检测的重点。但上述方法都无法很好的同时兼顾api序列间的局部特征与api序列间的依赖关系。
技术实现要素:
7.本发明提供一种基于注意力机制的多元特征融合恶意软件检测方法,旨在解决上述技术问题。
8.本发明是这样实现的,一种基于注意力机制的多元特征融合恶意软件检测方法,包括如下步骤:
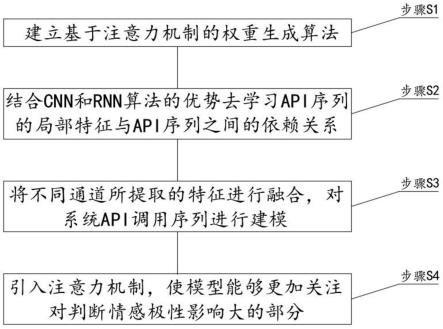
9.步骤s1:建立基于注意力机制的权重生成算法;
10.步骤s2:结合cnn和rnn算法的优势去学习api序列的局部特征与api序列之间的依赖关系;
11.步骤s3:将不同通道所提取的特征进行融合,对系统api调用序列进行建模;
12.步骤s4:引入注意力机制,使模型能够更加关注对判断情感极性影响大的部分。
13.优选的,所述步骤s1中,基于注意力机制的权重生成算法由多元特征融合层和恶意软件检测层组成,cnn和gru的特征通过多元特征融合层拼接,恶意软件检测层使用注意力机制对特征进行权重。
14.优选的,所述cnn和gru分别用于提取图像特征和语义特征。
15.优选的,所述恶意软件检测层将特征发送给softmax函数进行分类。
16.优选的,所述模型包括作为模型输入的词向量嵌入层、对序列提取特征的多通道卷积层和gru层、对提取特征进行融合的模型融合层、对不同的特征分配权重的注意力层。
17.优选的,所述多通道卷积层使用尺寸不同的卷积核,提取不同粒度的序列特征信息。
18.优选的,所述注意力层对不同的特征分配权重,把握api序列中的重要信息,最后将输出送入分类器中。
19.与现有技术相比,本发明的有益效果是:本发明的一种基于注意力机制的多元特征融合恶意软件检测方法,可以在基于系统api调用序列的恶意软件检测中取得良好的效果,大大提高了恶意程序检测的效率和准确性,在恶意程序检测领域具有广阔的应用前景,此外,可以应用在恶意软件检测领域外,还可以迁移应用于其他的序列数据分类的领域,这对于机器学习内广泛存在的分类问题具有一定的借鉴意义。
附图说明
20.图1为本发明的方法步骤示意图;
21.图2为本发明中的模型结构示意图;
22.图3为本发明中的权重生成算法的att-cnn-gru中注意力机制结构示意图;
具体实施方式
23.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
24.请参阅图1-3,本发明提供一种技术方案:一种基于注意力机制的多元特征融合恶意软件检测方法,包括如下步骤:
25.步骤s1:建立基于注意力机制的权重生成算法;
26.步骤s2:结合cnn和rnn算法的优势去学习api序列的局部特征与api序列之间的依赖关系;
27.步骤s3:将不同通道所提取的特征进行融合,对系统api调用序列进行建模;
28.步骤s4:引入注意力机制,使模型能够更加关注对判断情感极性影响大的部分。
29.如图2,在本实施方式中,模型包括词向量嵌入层、多通道卷积层、gru层、模型融合层、注意力层,该模型首先是词向量嵌入层,该层将api序列映射到任意大小的嵌入向量,作为模型的输入;嵌入向量通常可以改善复杂情况下大型神经网络的性能。接着是多通道卷积层与gru层;多通道卷积层使用尺寸不同的卷积核,提取不同粒度的序列特征信息,可以更加高效的提取api序列的局部上下文信息;gru是一种循环神经网络层可以学习嵌入向量之间的相关性。我们同时使用gru与多通道卷积层去对序列提取特征;模型融合层负责将gru和多通道卷积层提取的特征进行融合后送入注意力层,注意力层对不同的特征分配权重,可以更好的把握api序列中的重要信息,最后将输出送入分类器,得到恶意软件检测结果。
30.如图3,基于注意力机制的权重生成算法(att-cnn-gru)由多元特征融合层和恶意软件检测层组成,cnn提取的图像特征和gru提取的语义特征通过多元特征融合层进行拼接;恶意软件检测层使用注意力机制对特征进行权重,然后将其发送给softmax函数进行分类,具体过程如下:让输入长度为l的api调用序列通过词向量嵌入层,并为a
1:l
,其中ai∈rk是与句子中第一个单词相对应的k维单词向量。api调用序列可以表示为:
31.a
1:n
=a1⊕
a2⊕
...
⊕al
,
32.⊕
是连接运算符。通常,让a
i:i j
指代单词ai,a
i 1
,...,a
i j
的串联。
33.在cnn部分中,卷积运算由一个滤波器w∈r
hk
组成,该滤波器应用于h个单词的窗口以产生新的特征。例如,a
i:i h-1
可以通过生成特征ci;
34.ci=f(w*a
i:i h-1
b)
35.这里b∈r是一个偏差项,f是整流线性单位(relu),relu激活函数的形式如下:
36.f(x)=max(0,a)
37.我们的模型使用各种卷积核来形成特征图,对于n个卷积核,特征的卷积可以表示为:
38.cj=[c
1j
,c
2j
,...,c
nj
]
[0039]
在公式中,c
ij
是根据第i个卷积核卷积aj的特征。
[0040]
gru是rnn的最新变体之一,由于gru的参数少于lstm,因此在收敛时间和迭代次数方面优于lstm,因此它更适合于样本量较小的序列数据。首先,通过最后的传输状态h
t-1
和当前节点的输入api序列a
t
.获得两个门控状态。
[0041]rt
=σ(wr·
[h
t-1
,a
t
])
[0042]zt
=σ(wz·
[h
t-1
,a
t
])
[0043]
其中r
t
是复位门,z
t
是更新门。获得门控信号后,使用复位门控来获得复位数据h
t-1
*r
t
,将h
t-1
*r
t
,与输入a
t
拼接,然后通过tanh激活函数,范围为-1~1。
[0044]ht
=tanh(wh·
[h
t-1
*r
t
,a
t
])
[0045]
此处的h
t
主要包含当前输入的a
t
数据。在这个阶段,忘记和记忆的两个步骤同时进行。使用之前获得的更新门z
t
更新计算公式:
[0046]ht
=(1-z
t
)*h
t-1
z
t
*h
t
[0047]
门控信号(z
t
)的范围是0到1。门控信号越接近1,就可以记住更多的数据。越接近0,越被遗忘。
[0048]
此步骤的操作是忘记h
t-1
中的某些尺寸信息,并添加当前输入的某些尺寸信息。可以看出,遗忘的z
t
和选择项(1-z
t
)是链接的,也就是说,对于传入的维度信息,将执行选择性遗忘,并且将遗忘的z
t
的权重和权重对应于包含当前输入的h
t
的值将用于补偿(1-z
t
)以保持恒定状态。可以从每个api序列中获取相应的特征图序列。h=[h1,h2,
···
,hj]。然后,将cnn提取的特征与gru提取的特征进行拼接以获得新的特征。
[0049]
n=[h1,h2,
···
,hj,c1,c1,...cj].
[0050]
然后执行新功能图的最大池化。最大池化是一种通过最大化单词的特征表示来减少特征参数的方法。特征图的最大合并量可以表示为合并窗口内每个维度的最大特征pj∈r。
[0051]
pi=max([hi,h
i 1
,
···
,h
i l-1
,ci,c
i 1
,...c
i l-1
])
[0052]
在模型中,由于输入的单词向量是序列预处理的结果,因此单词向量之间将存在某种联系,基于注意力机制的恶意软件检测可以通过训练单词向量以提取文本中的重要特征来识别序列中的重要性级别。在att-cnn-gru模型中,通过注意力机制的作用,我们可以权衡特征,使其专注于更重要的特征。注意部分如图3所示,图中的输入是特征数据;
[0053]
p=[p1,p2,p3,...,pi]
[0054]
经过最大池化处理后的值,然后在隐藏层中引起注意,并计算每个输入a1,a2,a3,...,ai的概率分布的概率。进一步提取文本特征,突出显示文本的关键词。注意机制的计算公式如下:
[0055][0056]ei
=witanh(w
ihi
bi)
[0057]
v=∑aini[0058]
其中,ei是由babdanau等人提出的一种校验模型,ei表示第i时刻隐层状态向量hi所决定的注意力概率分布值,wi和wi表示第i时刻的权重系数矩阵,bi表示第i时刻相应的偏移量,通过上面的公式可以计算出最后包含文本信息的特征向量v。输出层的输入为上一层attention层的输出。最后利用softmax函数对输出层的输入进行相应计算,从而进行文本分类,其计算公式如下:
[0059]
y=softmax(wiv bi)
[0060]
其中:wi表示attention机制层到输出层待训练的权重系数矩阵,bi表示待训练相
对应的偏置量,y为输出的预测标签。
[0061]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。