具有错误时并行解压缩的经压缩的高速缓存存储器
背景
1.技术领域
1.本公开总体上关于处理器技术、高速缓存技术和压缩技术。
2.
背景技术:
2.zcache(z高速缓存)是捕捉并压缩被驱逐的干净的页高速缓存页的驱动器。当干净的页被回收时,zcache压缩/存储随机存取存储器(ram)中的被驱逐的页的内容。当文件系统读取文件页时,zcache检查它是否具有副本,并且如果有,则解压缩/返回该数据。否则,数据照常从文件系统/盘被读取。zcache捕捉并压缩ram中的交换(swap)页。当页需要被换出时,zcache压缩/存储ram中的交换页的内容。当页需要被换入时,如果前交换位被置位,则zcache解压缩/返回该数据。否则,数据照常从交换盘被读取。
3.zswap(z交换)是linux内核特征,其提供用于被交换的页的经压缩的写回高速缓存,作为虚拟存储器压缩的形式。与当存储器页要被换出时将它们移动到交换设备不同,zswap执行其压缩,并且随后将它们存储到被动态地分配在系统ram中的存储器池中。此后,向实际的交换设备的写回被延迟或甚至完全被避免,产生对需要交换的linux系统的显著减少的输入/输出(i/o)。权衡是对用于执行压缩的附加的中央处理单元(cpu)周期的需求。
4.zram是用于在ram中创建经压缩的块设备的linux内核模块,换言之,ram盘,但具有运行中(on-the-fly)盘压缩。利用zram创建的块设备随后可被用于交换或被用作通用ram盘。zram的两个最常见的用途是用于临时文件(/tmp)的存储以及被用作交换设备。
附图说明
5.以示例方式以及非限制方式在附图的各图中图示本发明的各实施例,在附图中:
6.图1a至图1b是根据一些实施例的页错误的时序的示例比较的说明性示图;
7.图2是根据实施例的集成电路的示例的框图;
8.图3a至图3b是根据实施例的方法的示例的流程图;
9.图4是根据实施例的装置的示例的框图;
10.图5是根据实施例的工作描述符的示例的说明性示图;
11.图6a至图6b是根据一些实施例的页错误的时序的另一示例比较的说明性示图;
12.图7a至图7b是根据一些实施例的存储器页和经压缩的数据的示例的说明性示图;
13.图8是根据实施例的集成电路的另一示例的框图;
14.图9a至图9d是根据实施例的方法的另一示例的流程图;
15.图10是根据实施例的装置的另一示例的框图;
16.图11a至图11b是根据实施例的工作描述符的对的示例的说明性示图;
17.图12a至图12b是根据实施例的数据结构和工作描述符的对的示例的说明性示图;
18.图13a是图示根据本发明的实施例的示例性有序流水线和示例性的寄存器重命名
的乱序发布/执行流水线两者的框图。
19.图13b是图示根据本发明的实施例的要包括在处理器中的有序架构核的示例性实施例和示例性的寄存器重命名的乱序发布/执行架构核两者的框图;
20.图14a-图14b图示更具体的示例性有序核架构的框图,该核将是芯片中的若干逻辑块之一(包括相同类型和/或不同类型的其他核);
21.图15是根据本发明的实施例的可具有多于一个的核、可具有集成存储器控制器、并且可具有集成图形器件的处理器的框图;
22.图16-图19是示例性计算机架构的框图;以及
23.图20是根据本发明的实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。
具体实施方式
24.本文中讨论的实施例以各种方式提供用于利用经压缩的高速缓存的技术和机制。本文中描述的技术可以在一个或多个电子设备中实现。可以利用本文中描述的技术的电子设备的非限制性示例包括任何种类的移动设备和/或固定式设备,诸如,相机、蜂窝电话、计算机终端、台式计算机、电子阅读器、传真机、自动服务机、膝上型计算机、上网本计算机、笔记本计算机、互联网设备、支付终端、个人数字助理、媒体播放器和/或记录器、服务器(例如,刀片服务器、机架安装服务器、其组合等)、机顶盒、智能电话、平板个人计算机、超移动个人计算机、有线电话、上述各项的组合,等等。更一般地,本文中描述的技术可在各种电子设备中的任何电子设备中被采用,各种电子设备包括可操作用于控制或利用高速缓存的集成电路系统。
25.在下列描述中,讨论了众多细节,以提供对本公开的实施例的更透彻的解释。然而,对本领域的技术人员将显而易见的是,可以在没有这些特定细节的情况下实施本公开的实施例。在其他实例中,以框图形式,而不是详细地示出公知的结构和设备,以避免使本公开的实施例变得模糊。
26.注意,在实施例的对应附图中,利用线来表示信号。一些线可以较粗以指示更多数量的成份信号路径,和/或在一个或多个末端处具有箭头以指示信息流的方向。此类指示不旨在是限制性的。相反,线结合一个或多个示例性实施例使用,以促进对电路或逻辑单元的更容易的理解。如由设计需要或偏好所规定,任何所表示的信号都可实际包括可在任一方向上行进的一个或多个信号,并可利用任何合适类型的信号方案来实现。
27.贯穿说明书以及在权利要求书中,术语“连接的”意指所连接的物体之间的诸如电气、机械、或磁性连接之类的无需任何中介设备的直接连接。术语“耦合的”意指直接的或间接的连接,诸如所连接的物体之间的直接的电气、机械、或磁性连接或者通过一个或多个无源或有源中介设备的间接连接。术语“电路”或“模块”可以指布置成用于彼此合作以提供期望功能的一个或多个无源和/或有源组件。术语“信号”可指至少一个电流信号、电压信号、磁信号、或数据/时钟信号。“一(a/an)”和“该”的含义包括复数引用。“在
……
中”的含义包括“在
……
中”和“在
……
上”。
28.术语“设备”一般可以指根据使用那个术语的上下文的装置。例如,设备可以指层或结构的堆叠、单个结构或层、具有有源和/或无源元件的各种结构的连接,等等。一般而
言,设备是三维结构,具有沿x-y-z笛卡尔坐标系的x-y方向的平面以及沿z方向的高度。设备的平面也可以是包括该设备的装置的平面。
29.术语“缩放”一般指将设计(示意图和布局)从一种工艺技术转换为另一种工艺技术,并随后在布局区域中被减小。术语“缩放”一般还指在同一技术节点内缩小布局和设备的尺寸。术语“缩放”还可指信号频率相对于另一参数(例如,功率供给水平)的调整(例如,减速或加速——即,分别为缩小或放大)。
30.术语“基本上”、“接近”、“近似”、“附近”以及“大约”一般指处于目标值的 /-10%内。例如,除非在其使用的明确的上下文中以其他方式指定,否则术语“基本上相等”、“大约相等”和“近似相等”意指在如此描述的物体之间仅存在偶然变化。在本领域中,此类变化典型地不大于预定的目标值的 /-10%。
31.应当理解,如此使用的术语在适当情况下是可互换的,例如使得本文中所描述的本发明的实施例能够以不同于本文中所图示或以其他方式描述的那些取向的其他取向来操作。
32.除非另外指定,否则使用序数形容词“第一”、“第二”、“第三”等来描述公共对象仅仅指示类似对象的不同实例被提及,并且不旨在暗示如此描述的对象必须在时间上、空间上、排名上、或以任何其他方式处于给定序列中。
33.在说明书和权利要求书中的术语“左”、“右”、“前”、“后”、“顶”、“底”、“在
……
上方”、“在
……
下方”等(如果有)用于描述性目的,并且不一定用于描述永久的相对位置。例如,如本文中所使用的术语“在
……
上方”、“在
……
下方”、“前侧”、“后侧”、“顶”、“底”,“在
……
上方”、“在
……
下方”和“在
……
上”是指一个组件、结构或材料相对于设备中其他所引用的组件、结构或材料的相对位置,其中此类物理关系是显著的。本文仅出于描述性目的采用这些术语,并且这些术语主要在设备z轴的上下文内,因此这些术语可以相对于设备的取向。因此,如果设备相对于所提供的图的上下文上下颠倒地取向,则在本文中所提供的图中的上下文中在第二材料“上方”的第一材料也可以在该第二材料“下方”。在材料的上下文中,设置在另一材料上方或下方的一种材料可直接接触,或者可具有一种或多种中介材料。此外,设置在两种材料之间的一种材料可直接与这两个层接触,或者可具有一个或多个中介层。相比之下,在第二材料“上”的第一材料与该第二材料直接接触。在组件组装件的上下文中进行类似的区分。
34.可在设备的z轴、x轴或y轴的上下文中采用术语“在
……
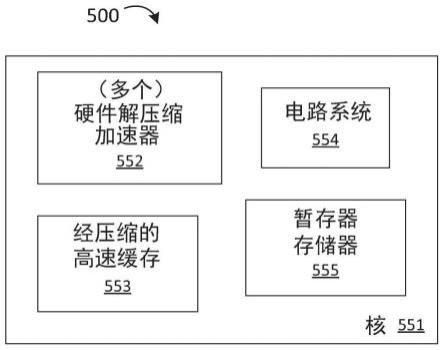
之间”。在两种其他材料之间的材料可以与那两种材料中的一种或两种接触,或者该材料可通过一种或多种中介材料来与其他那两种材料两者分开。因此,在两种其他材料“之间”的材料可以与其他那两种材料中的任一种接触,或者该材料可通过中介材料耦合至其他那两种材料。在两个其他设备之间的设备可直接连接至那两个设备中的一个或两个,或者该设备可通过一个或多个中介设备与其他那两个设备两者分开。
35.如贯穿说明书以及在权利要求书中所使用,由术语
“……
中的至少一个”或
“……
中的一个或多个”联接的项列表可意指所列举的项的任何组合。例如,短语“a、b或c中的至少一个”可意指a;b;c;a和b;a和c;b和c;或a、b和c。应指出,附图的具有与任何其他附图的要素相同的附图标记(或名称)的那些要素能以与所描述的方式类似的任何方式操作或起作用,但不被限于此。
36.此外,本公开中讨论的组合逻辑和时序逻辑的各种元件可涉及物理结构(诸如,and门、or门或xor门),或涉及实现作为所讨论的逻辑的布尔等效的逻辑结构的器件的合成的或以其他方式优化的集合。
37.一些实施例提供用于错误时解压缩和/或错误时并行解压缩的技术。一些计算系统可将轻量型经压缩的高速缓存(lcc)用于交换页(例如,诸如zswap)。lcc可取得处于被换出的过程中的页,并且尝试将它们压缩到动态分配的基于ram的存储器池中,这基本上以cpu周期换取潜在降低的交换i/o。如果从经压缩的高速缓存的读取比从交换设备的读取快,则该权衡可产生显著的性能改善。
38.一些基于经压缩的高速缓存的页交换技术可利用压缩算法的软件实现。涉及执行基于软件的压缩的等待时间会限制此类软件无法太激进地执行向lcc的页交换,因为对于对那个页的后续访问的解压缩等待时间和对工作负载的相关联的性能影响将是不可接受的。一些cpu/处理器可包括用于支持向经压缩的高速缓存的更激进的交换的硬件压缩/解压缩电路系统。例如,一些处理器可包括硬件解压缩加速器(hda)。
39.参考图1a,示例时序图示出对于页错误,在各处理步骤中花费了多少时间。x轴图示出用于执行每个处理步骤的微秒数。如图所示,页错误在工作负载访问被交换的页时在时刻0开始,此刻,微代码(ucode)开始将页错误异常递送到软件。操作系统(os)页错误处置程序(handler)随后接下来执行,并且在os页错误处置程序发现该页已被交换到经压缩的高速缓存之后,该os页错误处置程序发布入列(enq)事务,该enq事务具有用于hda的解压缩工作描述符(例如,大约1.1微秒)。enq事务可与从存储器位置取得描述符并将其写入加速器设备(例如,诸如hda、硬件解压缩引擎等)中的队列的指令的集合对应。在该示例中,用于通过芯片上系统(soc)结构将enq事务从核递送到hda的等待时间是下一条形(标记为soc)。hda执行解压缩,并用信号通知完成。完成信号必须经过soc结构并到达核,在那个时刻,正在等待完成的os软件执行处理的其余部分,并且调用中断返回(iret)指令以返回至生成该页错误的工作负载。示图中的最后的条形是iret指令的等待时间。在该示例中,页错误的所有处理花费约3.8毫秒。
40.一些实施例可提供用于通过允许串行化操作中的一些被重叠而进一步减少页错误处理的等待时间的技术。有利地,凭借减少的等待时间,软件可在将页交换到经压缩的高速缓存时更激进。更多页被压缩提供进一步的优势,体现在软件具有可用于主机附加工作负载的更多存储器(例如,这对于服务器运营商、云服务提供商等产生成本节省,因为它们现在可支持更多密集的紧缩工作负载,而不导致对工作负载的附加性能损失)。计算系统(例如,服务器)的总持有成本可显著地降低,因为存储器可能是系统中的较昂贵的组件中的一个。
41.错误时解压缩示例
42.参考图1b,一些实施例可提供使软件将经压缩的页被存储在存储器中之处的地址提供给递送页错误异常的微代码的技术。该微代码随后可以向hda生成enq事务。如图1b中所示,凭借在hda中发生的解压缩,一些实施例使对页错误异常的微代码递送与os页错误处置中的大多数重叠。有利地,一些实施例通过使解压缩与其他操作重叠来提供页错误处理的等待时间的减小,以允许软件在将存储器交换到经压缩的高速缓存时更激进,而不引发对工作负载的附加的性能开销。在所图示的示例中,重叠允许页错误处置等待时间减少约
28%,从而允许更激进地将页交换到经压缩的高速缓存。
43.参考图2,集成电路200的实施例可包括核221、耦合至核221的硬件解压缩加速器222、耦合至核221的经压缩的高速缓存223、以及电路系统224,该电路系统224耦合至核221,并且通信地耦合至硬件解压缩加速器222和经压缩的高速缓存223。电路系统224可配置成用于:存储去往解压缩工作描述符的第一地址(例如,第一地址指向解压缩工作描述符);响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存中之处的第二地址;以及将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器。在一些实施例中,集成电路200进一步包括暂存器存储器225,该暂存器存储器225耦合至核221,并通信地耦合至电路系统224。例如,电路系统224可配置成用于将解压缩工作描述符的第一地址存储在暂存器存储器225中,并且解压缩工作描述符可包括与要解压缩的下一页对应的第二地址。例如,暂存器存储器225可包括型号专用寄存器(msr),该msr包括指示与该msr相关联的逻辑处理器的字段。
44.在一些实施例中,电路系统224可进一步配置成用于:加载与出错的页的虚拟地址对应的页表条目;确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器222生成入列事务。电路系统224还可配置成用于:如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成;如果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成;和/或原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。本领域技术人员将理解,电路系统224可包括适当地配置的逻辑电路、状态机等。附加地或替代地,电路系统224中的一些或全部可利用适当的微代码指令来实现,这些微代码指令当由处理器执行时使该处理器执行电路系统224的各种功能。
45.硬件解压缩加速器222、经压缩的高速缓存223、电路系统224和/或暂存器存储器225的实施例可被并入处理器中,该处理器包括例如:核990(图13b)、核1102a-n(图15、图19)、处理器1210(图16)、协处理器1245(图16)、处理器1370(图17-图18)、处理器/协处理器1380(图17-图18)、协处理器1338(图17-图18)、协处理器1520(图19)、和/或处理器1614、1616(图20)。
46.参考图3a至图3b,方法300的实施例可包括:在框331处,存储去往解压缩工作描述符的第一地址;在框332处,响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页存储在经压缩的高速缓存中之处的第二地址;以及在框333处,将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器。例如,方法300可包括:在框334处,将解压缩工作描述符的第一地址存储在暂存器存储器中,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。在一些实施例中,在框335处,暂存器存储器可包括msr,该msr包括指示与该msr相关联的逻辑处理器的字段。
47.方法300的一些实施例可进一步包括:在框336处,加载与出错的页的虚拟地址对应的页表条目;在框337处,确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则在框338处,利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器生成入列事务。方法300还可包括:在框339处,如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成;在框340处,如
果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成;和/或在框341处,原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。
48.参考图4,装置400的实施例可包括硬件解压缩加速器442、经压缩的高速缓存443、通信地耦合至硬件解压缩加速器442和经压缩的高速缓存443的处理器444、以及通信地耦合至处理器444的存储器445。存储器445可存储微代码指令,这些微代码指令当由处理器444执行时使处理器444:存储去往解压缩工作描述符的第一地址;响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存443中之处的第二地址;以及将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器442。装置400的一些实施例可进一步包括暂存器存储器446,该暂存器存储器446通信地耦合至处理器444,用于存储解压缩工作描述符的第一地址,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。例如,暂存器存储器446可包括msr,该msr包括指示与该msr相关联的逻辑处理器的字段。
49.在一些实施例中,存储器445可存储进一步的指令,这些指令当由处理器444执行时使处理器444:加载与出错的页的虚拟地址对应的页表条目;确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器442生成入列事务。存储器445还可存储进一步的指令,这些指令当由处理器444执行时使处理器444:如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成;如果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成;和/或原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。
50.硬件解压缩加速器442、经压缩的高速缓存443、存储器445和/或暂存器存储器446的实施例可与处理器集成,该处理器包括例如:核990(图13b)、核1102a-n(图15、图19)、处理器1210(图16)、协处理器1245(图16)、处理器1370(图17-图18)、处理器/协处理器1380(图17-图18)、协处理器1338(图17-图18)、协处理器1520(图19)、和/或处理器1614、1616(图20)。
51.一些实施例利用msr,该msr保存将针对需要解压缩的下一页被排队的解压缩工作描述符的64b对齐的线性地址。在一些实施例中,msr名义上可被引用为“ia32_decomp_descriptor_ptr”。在一些实施例中,msr是线程范围的msr。解压缩工作描述符可具有以下格式:
52.软件利用在发生在用户级别应用(例如,环3)中的下一个页错误时对其的解压缩应当被完成的存储器的页的物理地址对解压缩描述符进行编程。当软件将页交换到经压缩的高速缓存时,软件如下所述地更新与被交换的页对应的页表条目(pte):1.通过清除存在位将页标记为不存在。2.使用hda压缩页,并将该页存储在经压缩的交换高速缓存中。3.将经压缩的交换高速缓存中的、经压缩的页存储在的位置的地址存储在被标记为不存在的pte中。该地址可以是虚拟地址或物理地址。如果虚拟地址被配置,则期望软件配置iommu中的pasid以从虚拟转换为物理。如果配置宾客物理地址,则期望软件配置pasid以从宾客物理转换为物理。类似地,如果未针对pasid启用直接存储器访问(dma)转换,则该地址可以是物理地址。4.设置pte中的位(本文中被称为“错误时解压缩”位)(例如,错误时解压缩位将由硬件解释),以指示如果对该经压缩的页的访问发生,则硬件应当触发对该页的解压缩。5.os随后执行iret以返回环3,从而继续执行工作负载。
53.当iret发生以从os内核级别(环0)转变到用户应用级别(环3)时,微代码将该描述符的两个四字高速缓存到内部暂存器寄存器中(例如,ia32_decomp_descriptor_ptr可保存内部暂存器寄存器的地址)。
54.当硬件用信号向微代码通知页错误时,微代码继续加载与出错的虚拟地址对应的页表条目,并且如果“错误时解压缩位”为0或“解压缩被排队”位为1(下文描述),则微代码跳过这些步骤中的其余步骤并继续正常地递送页错误。如果具有要解压缩的页的地址的解压缩描述符在最后的iret时不是有效的,则微代码跳过这些步骤中的其余步骤并继续正常
地递送页错误。
55.如果“错误时解压缩位”为1,并且“解压缩被排队”位为0,并且具有要解压缩的页的地址的解压缩描述符是有效的,则微代码随后使用锁定式读取-修改-写入操作原子性地设置pte中的“解压缩被排队”位。原子性操作强制使得如果对该地址的页错误同时从两个逻辑处理器发生,则仅一个逻辑处理器提交解压缩(即,赢得竞争且能够设置“解压缩被排队”标志的线程)。微代码随后利用作为如从pte读取的经压缩的页地址的源以及作为在最后的iret时从解压缩描述符读取的页地址的目标来生成enq事务。
56.图5示出工作描述符内容的说明性示例,其可由微代码使用enq事务排队到hda。微代码使用由ia32_decomp_descriptor_ptr指向的解压缩工作描述符的内容来填充目的地地址、pasid、操作标志和解压缩标志。微代码将源传递尺寸填充为如由软件所指定的最大源缓冲器尺寸——如果要压缩的实际源缓冲器小于那个尺寸,则iax将更早地停止处理。最大目的地尺寸被填充为四(4)千字节(kb)。
57.微代码随后继续进行页错误递送流的其余部分,包括例如:在idt中发现软件页错误处置程序地址;在栈上使出错指令指针和栈指针入栈;以及在栈上使错误代码入栈。微代码还在栈上使错误代码中的位入栈以指示该逻辑处理器是否已将enq提交到hda。微代码随后继续取出软件页错误处置程序的指令。
58.在os页错误处置程序利用其预处理被完成后,os页错误处置程序读取错误pte。如果“解压缩被排队”位被设置,则os页错误处置程序随后通过检查其栈上的错误代码中的该位来检查该逻辑处理器上的微代码是否是使解压缩排队的微代码。如果解压缩未被该逻辑处理器排队,则存在竞争,并且存在也处置对于同一地址的页错误的另一逻辑处理器。在这种情况下,软件等待逻辑处理器上的页错误处置程序,其中,enq被排队以完成页错误。注意,类似的竞争可在软件页错误处置程序执行enq的情况下发生,并且为了避免使来自多个逻辑处理器的enq排队以发起解压缩,当软件执行解压缩排队时,软件可原子性地设置“解压缩被排队”。
59.如果解压缩由该逻辑处理器排队,则os页错误处置程序读取使用另一逐逻辑处理器msr排队的enq事务的状态(本文中被称为“ia32_decomp_enq_status”),以确定由微代码提交的enq是否被接受到hda工作队列中。如果hda工作队列是忙碌的,则enq可能已被hda拒绝。如果状态显示enq被接受,则软件在hda上等待,以利用解压缩状态写入完成记录。如果由微代码发布的enq未被hda接受,则在此刻,软件再次生成enq以将解压缩工作提交到hda。
60.在解压缩被完成后,os分配新页以用作用于下一页错误时的解压缩的目标页,并且将该新页的地址存储在解压缩工作描述符中。os随后调用iret以继续执行出错的工作负载。
61.错误时并行解压缩示例
62.如图1b中所示,一些实施例提供用于通过允许这些串行化操作中的一些被重叠而减少页错误处理的等待时间的技术。参考图6a,示例说明性示图示出解压缩的等待时间未被完全隐藏在os前(os-pre)之下。附加地或替代地,一些实施例也可提供用于经由并行解压缩来提供改善的或最优的等待时间的技术。一些处理器可包括多个hda或具有对多个hda的访问权。例如,解压缩引擎可包括两个或更多个解压缩核。参考图6b,示例说明性示图示出一些实施例如何可以利用错误时并行解压缩以进一步减少等待时间。
63.参考图7a至图7b,示例存储器页可存储四(4)kb的未经压缩的数据。一些实施例可将4kb页视为两个各自都为2kb的块或切片(例如,切片0和切片1)。根据一些实施例,微代码可配置成用于将4kb页压缩为两个块zlice0(z切片0)和zslice1(z切片1),并且将经压缩的块存储在(例如,经压缩的池中的)物理地址a处。图7b示出存储在经压缩的存储器池中的物理地址a处的经压缩的数据。虽然结合乘二(x2)配置描述了并行解压缩的各种示例,但是能以自然方式将实施例扩展到更高程度的并行性。
64.参考图8,集成电路500可包括核551、耦合至核551的一个或多个硬件解压缩加速器552、耦合至核551的经压缩的高速缓存553、以及电路系统554,该电路系统554耦合至核551,并且通信地耦合至硬件解压缩加速器552和经压缩的高速缓存553。电路系统554可配置成用于:响应于页错误的指示来加载页表条目;确定页表条目是否指示页将在错误时被解压缩,并且如果确定是,则基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及利用第一解压缩工作描述符的第一地址向(多个)硬件解压缩加速器552生成第一入列事务,并利用第二解压缩工作描述符的第二地址向(多个)硬件解压缩加速器552生成第二入列事务。
65.在一些实施例中,电路系统554可进一步配置成用于:通过页表条目确定第一地址;以及将第二地址设置为第一解压缩工作描述符之后的连续地址。电路系统554还可配置成用于:将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该指定的页地址加具有页尺寸的块的预定长度。
66.在一些实施例中,集成电路500可进一步包括暂存器存储器555,该暂存器存储器555耦合至核551,并通信地耦合至电路系统554。电路系统554可配置成用于:将第一解压缩工作描述符和第二解压缩工作描述符存储在暂存器存储器555中;将第一地址设置为暂存器存储器555中的第一解压缩工作描述符的地址;以及将第二地址设置为暂存器存储器555的、在第一解压缩工作描述符之后的连续地址。在一些实施例中,电路系统554还可配置成用于:从页表条目中指示的存储器位置读取第一源地址和数据长度;将第二源地址设置为第一源地址加数据长度;将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。例如,经压缩的高速缓存553可按页布置,其中每个页具有两个或更多个块。第一解压缩工作描述符可与经压缩的高速缓存553的页的两个或更多个块中的第一块对应,并且第二解压缩工作描述符可与经压缩的高速缓存553的页的两个或更多个块中的第二块对应。
67.在一些实施例中,电路系统554可进一步配置成用于:将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该目的地页地址加第一块的尺寸。本领域技术人员将理解,电路系统554可包括适当地配置的逻辑电路、状态机等。附加地或替代地,电路系统554中的一些或全部可利用适当的微代码指令来实现,这些微代码指令当由处理器执行时使该处理器执行电路系统554的各种功能。
68.硬件解压缩加速器552、经压缩的高速缓存553、电路系统554和/或暂存器存储器555的实施例可被并入处理器中,该处理器包括例如:核990(图13b)、核1102a-n(图15、图19)、处理器1210(图16)、协处理器1245(图16)、处理器1370(图17-图18)、处理器/协处理器
1380(图17-图18)、协处理器1338(图17-图18)、协处理器1520(图19)、和/或处理器1614、1616(图20)。
69.参考图9a至图9d,方法600的实施例可包括:在框661处,响应于页错误的指示来加载页表条目;在框662处,确定页表条目是否指示页将在错误时被解压缩;以及如果确定是,则在框663处,基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及在框664处,利用第一解压缩工作描述符的第一地址向硬件解压缩加速器生成第一入列事务,并利用第二解压缩工作描述符的第二地址向硬件解压缩加速器生成第二入列事务。
70.方法600的一些实施例可进一步包括:在框665处,通过页表条目确定第一地址;以及在框666处,将第二地址设置为第一解压缩工作描述符之后的连续地址。例如,方法600可进一步包括:在框667处,将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及在框668处,将第二解压缩工作描述符中的第二目的地地址字段设置为该指定的页地址加具有页尺寸的块的预定长度。
71.方法600的一些实施例可进一步包括:在框669处,将第一解压缩工作描述符和第二解压缩工作描述符存储在暂存器存储器中;在框670处,将第一地址设置为第一解压缩工作描述符在暂存器存储器中的地址;以及在框671处,将第二地址设置为暂存器存储器的、在第一解压缩工作描述符之后的连续地址。例如,方法600还可包括:在框672处,从页表条目中指示的存储器位置读取第一源地址和数据长度:在框673处,将第二源地址设置为第一源地址加数据长度;在框674处,将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及在框675处,将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。
72.在一些实施例中,在框676处,经压缩的高速缓存可按页来布置,其中每个页具有两个或更多个块。例如,在框677处,第一解压缩工作描述符可与经压缩的高速缓存的页的两个或更多个块中的第一块对应,并且第二解压缩工作描述符可与经压缩的高速缓存的页的两个或更多个块中的第二块对应。方法600的一些实施例随后可进一步包括:在框678处,将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及在框679处,将第二解压缩工作描述符中的第二目的地地址字段设置为该目的地页地址加第一块的尺寸。
73.参考图10,装置700的实施例可包括一个或多个硬件解压缩加速器772、经压缩的高速缓存773、通信地耦合至(多个)硬件解压缩加速器772和经压缩的高速缓存773的一个或多个处理器774、以及通信地耦合至(多个)处理器774的存储器775。存储器775可存储微代码指令,这些微代码指令当由(多个)处理器774执行时使(多个)处理器774:响应于页错误的指示来加载页表条目;确定页表条目是否指示页将在错误时被解压缩,并且如果确定是,则基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及利用第一解压缩工作描述符的第一地址向(多个)硬件解压缩加速器772生成第一入列事务,并利用第二解压缩工作描述符的第二地址向(多个)硬件解压缩加速器772生成第二入列事务。
74.在一些实施例中,存储器775可存储进一步的微代码指令,这些微代码指令当由(多个)处理器774执行时使(多个)处理器774:通过页表条目确定第一地址;以及将第二地
址设置为第一解压缩工作描述符之后的连续地址。例如,存储器775可存储进一步的微代码指令,这些微代码指令当由(多个)处理器774执行时使(多个)处理器774:将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为指定的页地址条目加具有页尺寸的块的预定长度。
75.在一些实施例中,装置700可进一步包括暂存器存储器776,该暂存器存储器776通信地耦合至(多个)处理器774,用于存储第一解压缩工作描述符和第二解压缩工作描述符,并且存储器775可存储进一步的微代码指令,这些微代码指令当由(多个)处理器774执行时使(多个)处理器774:将第一地址设置为第一解压缩工作描述符在暂存器存储器776中的地址;以及将第二地址设置为暂存器存储器776的、在第一解压缩工作描述符之后的连续地址。存储器775还可存储微代码指令,这些微代码指令当由(多个)处理器774执行时使(多个)处理器774:从页表条目中指示的存储器位置读取第一源地址和数据长度;将第二源地址设置为第一源地址加数据长度;将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。例如,经压缩的高速缓存773可按页布置,其中每个页具有两个或更多个块。在一些实施例中,第一解压缩工作描述符可与经压缩的高速缓存773的页的两个或更多个块中的第一块对应,并且第二解压缩工作描述符可与经压缩的高速缓存773的页的两个或更多个块中的第二块对应。在一些实施例中,存储器775可存储进一步的微代码指令,这些微代码指令当由(多个)处理器774执行时使(多个)处理器774:将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该目的地页地址加第一块的尺寸。
76.硬件解压缩加速器772、经压缩的高速缓存773、存储器775和/或暂存器存储器776的实施例可与处理器集成,该处理器包括例如:核990(图13b)、核1102a-n(图15、图19)、处理器1210(图16)、协处理器1245(图16)、处理器1370(图17-图18)、处理器/协处理器1380(图17-图18)、协处理器1338(图17-图18)、协处理器1520(图19)、和/或处理器1614、1616(图20)。
77.参考图11a至图11b,os随后可创建用于x2解压缩的描述符的对,并将它们连续地存储在地址d处(例如,在lcc元数据区域中)。第一描述符具有设置为地址a的源1地址字段、设置为名义待定(tbd)值的目的地地址字段、设置为tbd的完成地址记录字段、以及设置为两(2)kb(例如,2048)的最大目的地尺寸字段。第二描述符具有设置为a加切片0的长度(例如,len(切片0)与第一块的经压缩的尺寸对应)的源1地址字段、设置为tbd 2048的目的地地址字段、设置为tbd的完成地址记录字段、以及设置为两(2)kb的最大目的地尺寸字段。os随后将地址d存储在pte中(例如,而不是上文结合错误时解压缩示例描述的地址a),这启用并行解压缩。在未命中时,微代码读取d,用这两个描述符字段中的核的指定的页地址来替换tbd。并且随后以d和d 64作为描述符的地址来提交两个enq事务。有利地,一些实施例可提供并行解压缩以进一步减少等待时间。一些实施例可将整个解压缩操作隐藏于os前计算时间之下。
78.对于该示例,参考图11b,微代码页错误处置程序从pte读取d,并且如下所述来填充tbd字段。对于第一描述符,微代码将目的地地址字段集设置为目的地页地址,并且将完
成地址记录字段集设置为核cplrec0值。对于第二描述符,微代码将目的地地址字段集设置为目的地页地址加2048,并且将完成地址记录字段集设置为核cplrec1值。在第一描述符和第二描述符用适当的值被更新后,微代码以d和d 64作为描述符的地址来提交两个enq事务。可能需要工作的分离,因为一些字段是页和数据专用的(并且例如在压缩时期间由os填充),而其他字段是核/线程专用的,其仅能够在错误发生时由微代码动态地处置。
79.参考图12a至图12b,数据结构和描述符的另一实施例可提供针对并行压缩的附加的压缩益处。如上文结合图11a至图11b所描述,一些实施例提供从微代码和性能的角度看简单且高效的、用于错误时并行解压缩的技术,但是向每个经压缩的页添加128b开销(例如,2x 64b描述符)。一些实施例提供增加压缩率的、用于错误时并行解压缩的替代技术。
80.根据一些实施例,每个核被提供有暂存器存储器中的描述符的对。与将描述符的对存储在地址d处不同,os可仅存储图12a中示出的数据结构,其包括地址a和zslice0的长度。地址d被存储在pte中。注意,不需要zslice1的长度(len(zslice1)),因为输出尺寸已知为2048。有利地,利用该实施例,开销为约10字节,这与将两个描述符存储在地址d处相比具有每页低约10倍的开销。
81.在未命中时,微代码从pte读取地址d,并且在暂存器存储器中连续地在地址sp处创建两个描述符。这些字段如上文结合图11b所描述地被填入。所有其他字段是微代码在其将这两个描述符填写到暂存器存储器中时能够执行的简单计算。页错误处置程序流程是类似的,但是具有用于被微代码填充的更多字段。在暂存器存储器中的第一描述符和第二描述符用适当的值被更新后,微代码以sp和sp 64作为描述符的地址来提交两个enq事务。
82.本领域技术人员将领会,各种设备可受益于前述实施例。以下示例性核架构、处理器和计算机架构是可受益性地并入本文中描述的技术的实施例的设备的非限制性示例。
83.示例性核架构、处理器和计算机架构
84.处理器核能以不同方式、出于不同的目的、在不同的处理器中实现。例如,此类核的实现可以包括:1)旨在用于通用计算的通用有序核;2)旨在用于通用计算的高性能通用乱序核;3)旨在主要用于图形和/或科学(吞吐量)计算的专用核。不同处理器的实现可包括:1)cpu,其包括旨在用于通用计算的一个或多个通用有序核和/或旨在用于通用计算的一个或多个通用乱序核;以及2)协处理器,其包括旨在主要用于图形和/或科学(吞吐量)的一个或多个专用核。此类不同的处理器导致不同的计算机系统架构,这些计算机系统架构可包括:1)在与cpu分开的芯片上的协处理器;2)在与cpu相同的封装中但在分开的管芯上的协处理器;3)与cpu在相同管芯上的协处理器(在该情况下,此类协处理器有时被称为专用逻辑或被称为专用核,该专用逻辑诸如,集成图形和/或科学(吞吐量)逻辑);以及4)芯片上系统,其可以将所描述的cpu(有时被称为(多个)应用核或(多个)应用处理器)、以上描述的协处理器和附加功能包括在同一管芯上。接着描述示例性核架构,随后描述示例性处理器和计算机架构。
85.示例性核架构
86.有序和乱序核框图
87.图13a是图示根据本发明的各实施例的示例性有序流水线和示例性的寄存器重命名的乱序发布/执行流水线的框图。图13b是示出根据本发明的各实施例的要包括在处理器中的有序架构核的示例性实施例和示例性的寄存器重命名的乱序发布/执行架构核的框
图。图13a-图13b中的实线框图示有序流水线和有序核,而虚线框的任选增加图示寄存器重命名的、乱序发布/执行流水线和核。考虑到有序方面是乱序方面的子集,将描述乱序方面。
88.在图13a中,处理器流水线900包括取出级902、长度解码级904、解码级906、分配级908、重命名级910、调度(也被称为分派或发布)级912、寄存器读取/存储器读取级914、执行级916、写回/存储器写入级918、异常处置级922和提交级924。
89.图13b示出处理器核990,该处理器核990包括前端单元930,该前端单元930耦合到执行引擎单元950,并且前端单元930和执行引擎单元950两者都耦合到存储器单元970。核990可以是精简指令集计算(risc)核、复杂指令集计算(cisc)核、超长指令字(vliw)核、或混合或替代的核类型。作为又一选项,核990可以是专用核,诸如例如,网络或通信核、压缩引擎、协处理器核、通用计算图形处理单元(gpgpu)核、图形核,等等。
90.前端单元930包括分支预测单元932,该分支预测单元932耦合到指令高速缓存单元934,该指令高速缓存单元934耦合到指令转换后备缓冲器(tlb)936,该指令转换后备缓冲器936耦合到指令取出单元938,该指令取出单元938耦合到解码单元940。解码单元940(或解码器)可对指令解码,并且生成从原始指令解码出的、或以其他方式反映原始指令的、或从原始指令导出的一个或多个微操作、微代码进入点、微指令、其他指令、或其他控制信号作为输出。解码单元940可使用各种不同的机制来实现。合适机制的示例包括但不限于,查找表、硬件实现、可编程逻辑阵列(pla)、微代码只读存储器(rom)等。在一个实施例中,核990包括存储用于某些宏指令的微代码的微代码rom或其他介质(例如,在解码单元940中,或以其他方式在前端单元930内)。解码单元940耦合到执行引擎单元950中的重命名/分配器单元952。
91.执行引擎单元950包括重命名/分配器单元952,该重命名/分配器单元952耦合到引退单元954和一个或多个调度器单元的集合956。(多个)调度器单元956表示任何数量的不同调度器,包括预留站、中央指令窗等。(多个)调度器单元956耦合到(多个)物理寄存器堆单元958。(多个)物理寄存器堆单元958中的每一个物理寄存器堆单元表示一个或多个物理寄存器堆,其中不同的物理寄存器堆存储一种或多种不同的数据类型,诸如,标量整数、标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点,状态(例如,作为要执行的下一条指令的地址的指令指针)等等。在一个实施例中,(多个)物理寄存器堆单元958包括向量寄存器单元、写掩码寄存器单元和标量寄存器单元。这些寄存器单元可以提供架构向量寄存器、向量掩码寄存器和通用寄存器。(多个)物理寄存器堆单元958由引退单元954重叠,以图示可实现寄存器重命名和乱序执行的各种方式(例如,使用(多个)重排序缓冲器和(多个)引退寄存器堆;使用(多个)未来文件、(多个)历史缓冲器、(多个)引退寄存器堆;使用寄存器映射和寄存器池,等等)。引退单元954和(多个)物理寄存器堆单元958耦合到(多个)执行集群960。(多个)执行集群960包括一个或多个执行单元的集合962以及一个或多个存储器访问单元的集合964。执行单元962可执行各种操作(例如,移位、加法、减法、乘法)并可对各种数据类型(例如,标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点)执行。尽管一些实施例可以包括专用于特定功能或功能集合的多个执行单元,但是其他实施例可包括仅一个执行单元或全都执行所有功能的多个执行单元。(多个)调度器单元956、(多个)物理寄存器堆单元958和(多个)执行集群960示出为可能有多个,因为某些实施例为某些类型的数据/操作创建分开的流水线(例如,标量整数流水线、标量浮点/紧缩整数/紧缩浮点/向量整数/向量
浮点流水线,和/或各自具有其自身的调度器单元、(多个)物理寄存器堆单元和/或执行集群的存储器访问流水线——并且在分开的存储器访问流水线的情况下,实现其中仅该流水线的执行集群具有(多个)存储器访问单元964的某些实施例)。还应当理解,在使用分开的流水线的情况下,这些流水线中的一个或多个可以是乱序发布/执行,并且其余流水线可以是有序的。
92.存储器访问单元的集合964耦合到存储器单元970,该存储器单元970包括数据tlb单元972,该数据tlb单元972耦合到数据高速缓存单元974,该数据高速缓存单元974耦合到第二级(l2)高速缓存单元976。在一个示例性实施例中,存储器访问单元964可包括加载单元、存储地址单元和存储数据单元,其中的每一个均耦合到存储器单元970中的数据tlb单元972。指令高速缓存单元934还耦合到存储器单元970中的第二级(l2)高速缓存单元976。l2高速缓存单元976耦合到一个或多个其他级别的高速缓存,并最终耦合到主存储器。
93.作为示例,示例性寄存器重命名的乱序发布/执行核架构可如下所述地实现流水线900:1)指令取出938执行取出级902和长度解码级904;2)解码单元940执行解码级906;3)重命名/分配器单元952执行分配级908和重命名级910;4)(多个)调度器单元956执行调度级912;5)(多个)物理寄存器堆单元958和存储器单元970执行寄存器读取/存储器读取级914;执行集群960执行执行级916;6)存储器单元970和(多个)物理寄存器堆单元958执行写回/存储器写入级918;7)各单元可牵涉到异常处置级922;以及8)引退单元954和(多个)物理寄存器堆单元958执行提交级924。
94.核990可支持一个或多个指令集(例如,x86指令集(具有已与较新版本一起添加的一些扩展);加利福尼亚州桑尼维尔市的mips技术公司的mips指令集;加利福尼亚州桑尼维尔市的arm控股公司的arm指令集(具有诸如neon的任选的附加扩展)),其中包括本文中描述的(多条)指令。在一个实施例中,核990包括用于支持紧缩数据指令集扩展(例如,avx1、avx2)的逻辑,由此允许使用紧缩数据来执行由许多多媒体应用使用的操作。
95.应当理解,核可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,各种方式包括时分多线程化、同时多线程化(其中单个物理核为物理核正在同时多线程化的线程中的每一个线程提供逻辑核)、或其组合(例如,时分取出和解码以及此后的诸如英特尔超线程化技术中的同时多线程化)。
96.尽管在乱序执行的上下文中描述了寄存器重命名,但应当理解,可以在有序架构中使用寄存器重命名。尽管所图示的处理器的实施例还包括分开的指令和数据高速缓存单元934/974以及共享的l2高速缓存单元976,但是替代实施例可以具有用于指令和数据两者的单个内部高速缓存,诸如例如,第一级(l1)内部高速缓存或多个级别的内部高速缓存。在一些实施例中,该系统可包括内部高速缓存和在核和/或处理器外部的外部高速缓存的组合。或者,所有高速缓存都可以在核和/或处理器的外部。
97.具体的示例性有序核架构
98.图14a-图14b图示更具体的示例性有序核架构的框图,该核将是芯片中的若干逻辑块(包括相同类型和/或不同类型的其他核)中的一个逻辑块。取决于应用,逻辑块通过高带宽互连网络(例如,环形网络)与一些固定的功能逻辑、存储器i/o接口和其他必要的i/o逻辑进行通信。
99.图14a是根据本发明的实施例的单个处理器核以及它至管芯上互连网络1002的连
接及其第二级(l2)高速缓存的本地子集1004的框图。在一个实施例中,指令解码器1000支持具有紧缩数据指令集扩展的x86指令集。l1高速缓存1006允许对进入标量和向量单元中的、对高速缓存存储器的低等待时间访问。尽管在一个实施例中(为了简化设计),标量单元1008和向量单元1010使用分开的寄存器集合(分别为标量寄存器1012和向量寄存器1014),并且在这些寄存器之间传输的数据被写入到存储器,并随后从第一级(l1)高速缓存1006读回,但是本发明的替代实施例可以使用不同的方法(例如,使用单个寄存器集合或包括允许数据在这两个寄存器堆之间传输而无需被写入和读回的通信路径)。
100.l2高速缓存的本地子集1004是全局l2高速缓存的一部分,该全局l2高速缓存被划分成多个分开的本地子集,每个处理器核一个本地子集。每个处理器核具有到其自身的l2高速缓存的本地子集1004的直接访问路径。由处理器核读取的数据被存储在其l2高速缓存子集1004中,并且可以与其他处理器核访问其自身的本地l2高速缓存子集并行地被快速访问。由处理器核写入的数据被存储在其自身的l2高速缓存子集1004中,并在必要的情况下从其他子集转储清除。环形网络确保共享数据的一致性。环形网络是双向的,以允许诸如处理器核、l2高速缓存和其他逻辑块之类的代理在芯片内彼此通信。每个环形数据路径为每个方向1012位宽。
101.图14b是根据本发明的实施例的图14a中的处理器核的一部分的展开图。图14b包括l1高速缓存1006的l1数据高速缓存1006a部分,以及关于向量单元1010和向量寄存器1014的更多细节。具体地,向量单元1010是16宽向量处理单元(vpu)(见16宽alu 1028),该单元执行整数、单精度浮点以及双精度浮点指令中的一个或多个。该vpu通过混合单元1020支持对寄存器输入的混合,通过数值转换单元1022a-b支持数值转换,并且通过复制单元1024支持对存储器输入的复制。写掩码寄存器1026允许掩蔽所得的向量写入。
102.图15是根据本发明的实施例的可具有多于一个的核、可具有集成存储器控制器、以及可具有集成图形器件的处理器1100的框图。图15中的实线框图示具有单个核1102a、系统代理1110、一个或多个总线控制器单元的集合1116的处理器1100,而虚线框的任选增加图示具有多个核1102a-n、系统代理单元1110中的一个或多个集成存储器控制器单元的集合1114以及专用逻辑1108的替代处理器1100。
103.因此,处理器1100的不同实现可包括:1)cpu,其中专用逻辑1108是集成图形和/或科学(吞吐量)逻辑(其可包括一个或多个核),并且核1102a-n是一个或多个通用核(例如,通用有序核、通用乱序核、这两者的组合);2)协处理器,其中核1102a-n是旨在主要用于图形和/或科学(吞吐量)的大量专用核;以及3)协处理器,其中核1102a-n是大量通用有序核。因此,处理器1100可以是通用处理器、协处理器或专用处理器,诸如例如,网络或通信处理器、压缩引擎、图形处理器、gpgpu(通用图形处理单元)、高吞吐量的集成众核(mic)协处理器(包括30个或更多核)、嵌入式处理器,等等。该处理器可以被实现在一个或多个芯片上。处理器1100可以是一个或多个基板的一部分,和/或可使用多种工艺技术(诸如例如,bicmos、cmos、或nmos)中的任何技术被实现在一个或多个基板上。
104.存储器层次结构包括核1102a-n内的一个或多个级别的相应的高速缓存1104a-n、一个或多个共享高速缓存单元的集合1106、以及耦合到集成存储器控制器单元的集合1114的外部存储器(未示出)。共享高速缓存单元的集合1106可包括一个或多个中间级别的高速缓存,诸如,第二级(l2)、第三级(l3)、第四级(l4)或其他级别的高速缓存、末级高速缓存
(llc)和/或以上各项的组合。虽然在一个实施例中,基于环的互连单元1112将集成图形逻辑1108、共享高速缓存单元的集合1106以及系统代理单元1110/(多个)集成存储器控制器单元1114互连,但是替代实施例可使用任何数量的公知技术来互连此类单元。在一个实施例中,在一个或多个高速缓存单元1106与核1102a-n之间维持一致性。
105.在一些实施例中,一个或多个核1102a-n能够实现多线程化。系统代理1110包括协调和操作核1102a-n的那些部件。系统代理单元1110可包括例如功率控制单元(pcu)和显示单元。pcu可以是对核1102a-n以及集成图形逻辑1108的功率状态进行调节所需的逻辑和部件,或可包括这些逻辑和部件。显示单元用于驱动一个或多个外部连接的显示器。
106.核1102a-n在架构指令集方面可以是同构的或异构的;即,核1102a-n中的两个或更多个核可能能够执行相同的指令集,而其他核可能能够执行该指令集的仅仅子集或不同的指令集。
107.示例性计算机架构
108.图16-图19是示例性计算机架构的框图。本领域中已知的对膝上型设备、台式机、手持pc、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般地,能够包含如本文中所公开的处理器和/或其他执行逻辑的各种各样的系统或电子设备一般都是合适的。
109.现在参考图16,所示出的是根据本发明一个实施例的系统1200的框图。系统1200可以包括一个或多个处理器1210、1215,这些处理器耦合到控制器中枢1220。在一个实施例中,控制器中枢1220包括图形存储器控制器中枢(gmch)1290和输入/输出中枢(ioh)1250(其可以在分开的芯片上);gmch 1290包括存储器和图形控制器,存储器1240和协处理器1245耦合到该存储器和图形控制器;ioh 1250将输入/输出(i/o)设备1260耦合到gmch1290。或者,存储器和图形控制器中的一个或这两者被集成在(如本文中所描述的)处理器内,存储器1240和协处理器1245直接耦合到处理器1210,并且控制器中枢1220与ioh 1250处于单个芯片中。
110.附加的处理器1215的任选性在图16中通过虚线来表示。每一处理器1210、1215可包括本文中描述的处理核中的一个或多个,并且可以是处理器1100的某一版本。
111.存储器1240可以是例如动态随机存取存储器(dram)、相变存储器(pcm)或这两者的组合。对于至少一个实施例,控制器中枢1220经由诸如前端总线(fsb)之类的多分支总线、诸如快速路径互连(qpi)之类的点对点接口、或者类似的连接1295来与(多个)处理器1210、1215进行通信。
112.在一个实施例中,协处理器1245是专用处理器,诸如例如,高吞吐量mic处理器、网络或通信处理器、压缩引擎、图形处理器、gpgpu、嵌入式处理器,等等。在一个实施例中,控制器中枢1220可以包括集成图形加速器。
113.在物理资源1210、1215之间可以存在包括架构、微架构、热、功耗特性等一系列品质度量方面的各种差异。
114.在一个实施例中,处理器1210执行控制一般类型的数据处理操作的指令。嵌入在这些指令内的可以是协处理器指令。处理器1210将这些协处理器指令识别为具有应当由附
连的协处理器1245执行的类型。因此,处理器1210在协处理器总线或者其他互连上将这些协处理器指令(或者表示协处理器指令的控制信号)发布到协处理器1245。(多个)协处理器1245接受并执行所接收的协处理器指令。
115.现在参见图17,所示出的是根据本发明的实施例的第一更具体的示例性系统1300的框图。如图17中所示,多处理器系统1300是点对点互连系统,并且包括经由点对点互连1350耦合的第一处理器1370和第二处理器1380。处理器1370和1380中的每一个都可以是处理器1100的某一版本。在本发明的一个实施例中,处理器1370和1380分别是处理器1210和1215,而协处理器1338是协处理器1245。在另一实施例中,处理器1370和1380分别是处理器1210和协处理器1245。
116.处理器1370和1380示出为分别包括集成存储器控制器(imc)单元1372和1382。处理器1370还包括作为其总线控制器单元的一部分的点对点(p-p)接口1376和1378;类似地,第二处理器1380包括p-p接口1386和1388。处理器1370、1380可以经由使用点对点(p-p)接口电路1378、1388的p-p接口1350来交换信息。如图17中所示,imc 1372和1382将处理器耦合到相应的存储器,即存储器1332和存储器1334,这些存储器可以是本地附连到相应处理器的主存储器的部分。
117.处理器1370、1380可各自经由使用点对点接口电路1376、1394、1386、1398的各个p-p接口1352、1354来与芯片组1390交换信息。芯片组1390可以任选地经由高性能接口1339和接口1392来与协处理器1338交换信息。在一个实施例中,协处理器1338是专用处理器,诸如例如,高吞吐量mic处理器、网络或通信处理器、压缩引擎、图形处理器、gpgpu、嵌入式处理器,等等。
118.共享高速缓存(未示出)可被包括在任一处理器中,或在这两个处理器的外部但经由p-p互连与这些处理器连接,使得如果处理器被置于低功率模式,则任一个或这两个处理器的本地高速缓存信息可被存储在共享高速缓存中。
119.芯片组1390可以经由接口1396耦合到第一总线1316。在一个实施例中,第一总线1316可以是外围部件互连(pci)总线或诸如pci快速总线或另一第三代i/o互连总线之类的总线,但是本发明的范围不限于此。
120.如图17中所示,各种i/o设备1314可连同总线桥1318一起耦合到第一总线1316,该总线桥1318将第一总线1316耦合到第二总线1320。在一个实施例中,诸如协处理器、高吞吐量mic处理器、gpgpu、加速器(诸如例如,图形加速器或数字信号处理(dsp)单元)、现场可编程门阵列或任何其他处理器的一个或多个附加处理器1315耦合到第一总线1316。在一个实施例中,第二总线1320可以是低引脚数(lpc)总线。在一个实施例中,各种设备可耦合到第二总线1320,这些设备包括例如键盘和/或鼠标1322、通信设备1327以及存储单元1328,该存储单元1328诸如可包括指令/代码和数据1330的盘驱动器或者其他大容量存储设备。此外,音频i/o 1324可以被耦合到第二总线1320。注意,其他架构是可能的。例如,代替图17的点对点架构,系统可以实现多分支总线或其他此类架构。
121.现在参考图18,示出的是根据本发明的实施例的第二更具体的示例性系统1400的框图。图17和图18中的类似元件使用类似的附图标记,并且从图18中省略了图17的某些方面以避免混淆图18的其他方面。
122.图18图示处理器1370、1380可分别包括集成存储器和i/o控制逻辑(“cl”)1472和
1482。因此,cl 1472、1482包括集成存储器控制器单元,并包括i/o控制逻辑。图18图示不仅存储器1332、1334耦合到cl 1472、1482,而且i/o设备1414也耦合到控制逻辑1472、1482。传统i/o设备1415被耦合到芯片组1390。
123.现在参考图19,示出的是根据本发明的实施例的soc 1500的框图。图15中的类似要素使用类似的附图标记。另外,虚线框是更先进的soc上的任选的特征。在图19中,(多个)互连单元1502被耦合到:应用处理器1510,其包括一个或多个核的集合1102a-n以及(多个)共享高速缓存单元1106;系统代理单元1110;(多个)总线控制器单元1116;(多个)集成存储器控制器单元1114;一个或多个协处理器的集合1520,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(sram)单元1530;直接存储器访问(dma)单元1532;以及用于耦合到一个或多个外部显示器的显示单元1540。在一个实施例中,(多个)协处理器1520包括专用处理器,诸如例如,网络或通信处理器、压缩引擎、gpgpu、高吞吐量mic处理器、或嵌入式处理器,等等。
124.本文公开的机制的各实施例可以被实现在硬件、软件、固件或此类实现方式的组合中。本发明的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
125.可将程序代码(诸如,图17中图示的代码1330)应用于输入指令,以执行本文中描述的功能并生成输出信息。可以按已知方式将输出信息应用于一个或多个输出设备。为了本技术的目的,处理系统包括具有处理器的任何系统,该处理器诸如例如,数字信号处理器(dsp)、微控制器、专用集成电路(asic)或微处理器。
126.程序代码可以用高级的面向过程的编程语言或面向对象的编程语言来实现,以便与处理系统通信。如果需要,也可用汇编语言或机器语言来实现程序代码。事实上,本文中描述的机制不限于任何特定的编程语言的范围。在任何情况下,该语言可以是编译语言或解释语言。
127.至少一个实施例的一个或多个方面可以由存储在机器可读介质上的表示性指令来实现,该指令表示处理器中的各种逻辑,该指令在被机器读取时使得该机器制造用于执行本文中所述的技术的逻辑。被称为“ip核”的此类表示可以被存储在有形的机器可读介质上,并可被供应给各个客户或生产设施以加载到实际制造该逻辑或处理器的制造机器中。
128.此类机器可读存储介质可以包括但不限于通过机器或设备制造或形成的制品的非暂态、有形布置,其包括存储介质,诸如硬盘;任何其他类型的盘,包括软盘、光盘、紧致盘只读存储器(cd-rom)、可重写紧致盘(cd-rw)以及磁光盘;半导体器件,诸如,只读存储器(rom)、诸如动态随机存取存储器(dram)和静态随机存取存储器(sram)的随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、闪存、电可擦除可编程只读存储器(eeprom);相变存储器(pcm);磁卡或光卡;或适于存储电子指令的任何其他类型的介质。
129.因此,本发明的实施例还包括非暂态的有形机器可读介质,该介质包含指令或包含设计数据,诸如硬件描述语言(hdl),它定义本文中描述的结构、电路、装置、处理器和/或系统特征。这些实施例也被称为程序产品。
130.仿真(包括二进制变换、代码变形等)
131.在一些情况下,指令转换器可用于将指令从源指令集转换至目标指令集。例如,指
令转换器可以将指令变换(例如,使用静态二进制变换、包括动态编译的动态二进制变换)、变形、仿真或以其他方式转换成要由核处理的一条或多条其他指令。指令转换器可以用软件、硬件、固件、或其组合来实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上且部分在处理器外。
132.图20是根据本发明的实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。在所图示的实施例中,指令转换器是软件指令转换器,但替代地,该指令转换器可以用软件、固件、硬件或其各种组合来实现。图20示出可使用x86编译器1604来编译高级语言1602形式的程序,以生成可由具有至少一个x86指令集核的处理器1616原生执行的x86二进制代码1606。具有至少一个x86指令集核的处理器1616表示通过兼容地执行或以其他方式处理以下各项来执行与具有至少一个x86指令集核的英特尔处理器基本相同的功能的任何处理器:1)英特尔x86指令集核的指令集的实质部分,或2)目标为在具有至少一个x86指令集核的英特尔处理器上运行以便取得与具有至少一个x86指令集核的英特尔处理器基本相同的结果的应用或其他软件的目标代码版本。x86编译器1604表示可操作用于生成x86二进制代码1606(例如,目标代码)的编译器,该二进制代码可通过或不通过附加的链接处理在具有至少一个x86指令集核的处理器1616上执行。类似地,图20示出可以使用替代的指令集编译器1608来编译高级语言1602形式的程序,以生成可以由不具有至少一个x86指令集核的处理器1614(例如,具有执行加利福尼亚州桑尼维尔市的mips技术公司的mips指令集、和/或执行加利福尼亚州桑尼维尔市的arm控股公司的arm指令集的核的处理器)原生执行的替代的指令集二进制代码1610。指令转换器1612用于将x86二进制代码1606转换成可以由不具有x86指令集核的处理器1614原生执行的代码。该转换后的代码不大可能与替代的指令集二进制代码1610相同,因为能够这样做的指令转换器难以制造;然而,转换后的代码将完成一般操作,并且由来自替代指令集的指令构成。因此,指令转换器1612通过仿真、模拟或任何其他过程来表示允许不具有x86指令集处理器或核的处理器或其他电子设备执行x86二进制代码1606的软件、固件、硬件或其组合。
133.本文中描述了用于指令级架构操作码参数化的技术和架构。在上文描述中,出于解释的目的,阐述了众多具体细节以提供对某些实施例的透彻理解。然而,对本领域技术人员而言将显而易见的是,某些实施例可在无需这些具体细节的情况下实施。在其他实例中,以框图形式示出结构和设备以避免使描述含糊。
134.附加注解与示例
135.示例1包括一种集成电路,其包括:核、耦合至核的硬件解压缩加速器、耦合至核的经压缩的高速缓存、以及耦合至核并通信地耦合至硬件解压缩加速器和经压缩的高速缓存的电路系统,该电路系统用于:存储去往解压缩工作描述符的第一地址;响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存中之处的第二地址;以及将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器。
136.示例2包括示例1的集成电路,进一步包括耦合至核并通信地耦合至电路系统的暂存器存储器,其中,电路系统进一步用于将解压缩工作描述符的第一地址存储在暂存器存储器中,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。
137.示例3包括示例2的集成电路,其中,暂存器存储器包括型号专用寄存器,该型号专用寄存器包括指示与该型号专用寄存器相关联的逻辑处理器的字段。
138.示例4包括示例2至3中的任一项的集成电路,其中,电路系统进一步用于:加载与出错的页的虚拟地址对应的页表条目;确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器生成入列事务。
139.示例5包括示例4的集成电路,其中,电路系统进一步用于:如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成。
140.示例6包括示例4至5中的任一项的集成电路,其中,电路系统进一步用于:如果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成。
141.示例7包括示例4至6中的任一项的集成电路,其中,电路系统进一步用于:原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。
142.示例8包括一种方法,包括:存储去往解压缩工作描述符的第一地址;响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存中之处的第二地址;以及将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器。
143.示例9包括示例8的方法,进一步包括:将解压缩工作描述符的第一地址存储在暂存器存储器中,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。
144.示例10包括示例9的方法,其中,暂存器存储器包括型号专用寄存器,该型号专用寄存器包括指示与该型号专用寄存器相关联的逻辑处理器的字段。
145.示例11包括示例9至10中的任一项的方法,进一步包括:加载与出错的页的虚拟地址对应的页表条目;确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器生成入列事务。
146.示例12包括示例11的方法,进一步包括:如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成。
147.示例13包括示例11至12中的任一项的方法,进一步包括:如果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成。
148.示例14包括示例11至13中的任一项的方法,进一步包括:原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。
149.示例15包括一种装置,其包括:硬件解压缩加速器、经压缩的高速缓存、通信地耦合至硬件解压缩加速器和经压缩的高速缓存的处理器、以及通信地耦合至处理器的存储器,其中,存储器存储微代码指令,这些微代码指令当被处理器执行时使该处理器:存储去往解压缩工作描述符的第一地址;响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存中之处的第二地址;以及将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器。
150.示例16包括示例15的装置,进一步包括:暂存器存储器,通信地耦合至处理器,用于存储解压缩工作描述符的第一地址,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。
151.示例17包括示例16的装置,其中,暂存器存储器包括型号专用寄存器,该型号专用寄存器包括指示与该型号专用寄存器相关联的逻辑处理器的字段。
152.示例18包括示例16至17中的任一项的装置,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:加载与出错的页的虚拟地址对应的页表条目;确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器生成入列事务。
153.示例19包括示例18的装置,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成。
154.示例20包括示例18至19中的任一项的装置,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:如果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成。
155.示例21包括示例18至20中的任一项的装置,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。
156.示例22包括一种集成电路,其包括:核、耦合至核的硬件解压缩加速器、耦合至核的经压缩的高速缓存、耦合至核并通信地耦合至硬件解压缩加速器和经压缩的高速缓存的处理器、以及耦合至核并通信地耦合至处理器的存储器,其中,存储器存储微代码指令,这些微代码指令当被处理器执行时使该处理器:存储去往解压缩工作描述符的第一地址;响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存中之处的第二地址;以及将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器。
157.示例23包括示例22的集成电路,进一步包括:暂存器存储器,耦合至核并通信地耦合至处理器,用于存储解压缩工作描述符的第一地址,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。
158.示例24包括示例23的集成电路,其中,暂存器存储器包括型号专用寄存器,该型号专用寄存器包括指示与该型号专用寄存器相关联的逻辑处理器的字段。
159.示例25包括示例23至24中的任一项的集成电路,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:加载与出错的页的虚拟地址对应的页表条目;确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器生成入列事务。
160.示例26包括示例25的集成电路,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成。
161.示例27包括示例25至26中的任一项的集成电路,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:如果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成。
162.示例28包括示例25至27中的任一项的集成电路,其中,存储器存储进一步的指令,这些指令当由处理器执行时使该处理器:原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。
163.示例29包括一种解压缩设备,包括:用于存储去往解压缩工作描述符的第一地址的装置;用于响应于页错误的指示而从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存中之处的第二地址的装置;以及用于将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器的装置。
164.示例30包括示例29的设备,进一步包括:用于将解压缩工作描述符的第一地址存储在暂存器存储器中的装置,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。
165.示例31包括示例30的设备,其中,暂存器存储器包括型号专用寄存器,该型号专用寄存器包括指示与该型号专用寄存器相关联的逻辑处理器的字段。
166.示例32包括示例30至31中的任一项的设备,进一步包括:用于加载与出错的页的虚拟地址对应的页表条目的装置;用于确定该页表条目是否指示该页将在错误时被解压缩的装置;以及用于如果确定是则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器生成入列事务的装置。
167.示例33包括示例32的设备,进一步包括:用于如果页表条目指示另一解压缩操作被排队则跳过入列事务的生成的装置。
168.示例34包括示例32至33中的任一项的设备,进一步包括:用于如果具有经压缩的页的地址的解压缩工作描述符被确定为无效则跳过入列事务的生成的装置。
169.示例35包括示例32至34中的任一项的设备,进一步包括:用于原子性地设置页表条目中的字段以指示与页错误相关联的逻辑处理器已使解压缩操作排队的装置。
170.示例36包括至少一种非暂态机器可读介质,包括多条指令,这些指令响应于在计算设备上被执行而使计算设备:存储去往解压缩工作描述符的第一地址;响应于页错误的指示,从第一地址处的解压缩工作描述符检取经压缩的页被存储在经压缩的高速缓存中之处的第二地址;以及将对第二地址处的经压缩的页解压缩的指令发送到硬件解压缩加速器。
171.示例37包括示例36的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:将解压缩工作描述符的第一地址存储在暂存器存储器中,其中,解压缩工作描述符包括与要解压缩的下一页对应的第二地址。
172.示例38包括示例37的至少一种非暂态机器可读介质,其中,暂存器存储器包括型号专用寄存器,该型号专用寄存器包括指示与该型号专用寄存器相关联的逻辑处理器的字段。
173.示例39包括示例37至38中的任一项的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:加载与出错的页的虚拟地址对应的页表条目;确定该页表条目是否指示该页将在错误时被解压缩;并且如果确定是,则利用来自页表条目的经压缩的页地址作为源以及从解压缩工作描述符检取的第二地址作为目标来向硬件解压缩加速器生成入列事务。
174.示例40包括示例39的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:如果页表条目指示另一解压缩操作被排队,则跳过入列事务的生成。
175.示例41包括示例39至40中的任一项的至少一种非暂态机器可读介质,包括多条进
一步的指令,这些指令响应于在计算设备上被执行而使计算设备:如果具有经压缩的页的地址的解压缩工作描述符被确定为无效,则跳过入列事务的生成。
176.示例42包括示例39至41中的任一项的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:原子性地设置页表条目中的字段,以指示与页错误相关联的逻辑处理器已使解压缩操作排队。
177.示例43包括一种集成电路,其包括:核、耦合至核的硬件解压缩加速器、耦合至核的经压缩的高速缓存、以及耦合至核并通信地耦合至硬件解压缩加速器和经压缩的高速缓存的电路系统,该电路系统用于:响应于页错误的指示而加载页表条目;确定页表条目是否指示页将在错误时被解压缩,并且如果确定是,则基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及利用第一解压缩工作描述符的第一地址向硬件解压缩加速器生成第一入列事务,并利用第二解压缩工作描述符的第二地址向硬件解压缩加速器生成第二入列事务。
178.示例44包括示例43的集成电路,其中,电路系统进一步用于:通过页表条目确定第一地址;以及将第二地址设置为第一解压缩工作描述符之后的连续地址。
179.示例45包括示例44的集成电路,其中,电路系统进一步用于:将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该指定的页地址加具有页尺寸的块的预定长度。
180.示例46包括示例43至45中的任一项的集成电路,进一步包括:暂存器存储器,耦合至核并通信地耦合至电路系统,其中,电路系统进一步用于:将第一解压缩工作描述符和第二解压缩工作描述符存储在暂存器存储器中;将第一地址设置为第一解压缩工作描述符在暂存器存储器中的地址;以及将第二地址设置为暂存器存储器的、在第一解压缩工作描述符之后的连续地址。
181.示例47包括示例46的集成电路,其中,电路系统进一步用于:从页表条目中指示的存储器位置读取第一源地址和数据长度;将第二源地址设置为第一源地址加数据长度;将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。
182.示例48包括示例47的集成电路,其中,经压缩的高速缓存按页来布置,其中每一页具有两个或更多个块。
183.示例49包括示例48的集成电路,其中,第一解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第一块对应,并且其中,第二解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第二块对应。
184.示例50包括示例49的集成电路,其中,电路系统进一步用于:将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该目的地页地址加第一块的尺寸。
185.示例51包括一种方法,其包括:响应于页错误的指示来加载页表条目;确定页表条目是否指示页将在错误时被解压缩,并且如果确定是,则基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及利用第一解压缩工作描述符的第一地址向硬件解压缩加速器生成第一入列事务,并利用第二解压缩
工作描述符的第二地址向硬件解压缩加速器生成第二入列事务。
186.示例52包括示例51的方法,进一步包括:通过页表条目确定第一地址;以及将第二地址设置为第一解压缩工作描述符之后的连续地址。
187.示例53包括示例52的方法,进一步包括:将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该指定的页地址加具有页尺寸的块的预定长度。
188.示例54包括示例51至53中的任一项的方法,进一步包括:将第一解压缩工作描述符和第二解压缩工作描述符存储在暂存器存储器中;将第一地址设置为第一解压缩工作描述符在暂存器存储器中的地址;以及将第二地址设置为暂存器存储器的、在第一解压缩工作描述符之后的连续地址。
189.示例55包括示例54的方法,进一步包括:从页表条目中指示的存储器位置读取第一源地址和数据长度;将第二源地址设置为第一源地址加数据长度;将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。
190.示例56包括示例55的方法,其中,经压缩的高速缓存按页来布置,其中每一页具有两个或更多个块。
191.示例57包括示例56的方法,其中,第一解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第一块对应,并且其中,第二解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第二块对应。
192.示例58包括示例57的方法,进一步包括:将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该目的地页地址加第一块的尺寸。
193.示例59包括一种装置,其包括:硬件解压缩加速器、经压缩的高速缓存、通信地耦合至硬件解压缩加速器和经压缩的高速缓存的处理器、以及通信地耦合至处理器的存储器,其中,存储器存储微代码指令,这些微代码指令当由处理器执行时使该处理器:响应于页错误的指示而加载页表条目;确定页表条目是否指示页将在错误时被解压缩,并且如果确定是,则基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及利用第一解压缩工作描述符的第一地址向硬件解压缩加速器生成第一入列事务,并利用第二解压缩工作描述符的第二地址向硬件解压缩加速器生成第二入列事务。
194.示例60包括示例59的装置,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:通过页表条目确定第一地址;以及将第二地址设置为第一解压缩工作描述符之后的连续地址。
195.示例61包括示例60的装置,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为指定的页地址加具有页尺寸的块的预定长度。
196.示例62包括示例59至61中的任一项的装置,进一步包括暂存器存储器,该暂存器存储器通信地耦合至处理器,用于存储第一解压缩工作描述符和第二解压缩工作描述符,
并且其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:将第一地址设置为第一解压缩工作描述符在暂存器存储器中的地址;以及将第二地址设置为暂存器存储器的、在第一解压缩工作描述符之后的连续地址。
197.示例63包括示例62的装置,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:从页表条目中指示的存储器位置读取第一源地址和数据长度;将第二源地址设置为第一源地址加数据长度;将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。
198.示例64包括示例63的装置,其中,经压缩的高速缓存按页来布置,其中每一页具有两个或更多个块。
199.示例65包括示例64的装置,其中,第一解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第一块对应,并且其中,第二解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第二块对应。
200.示例66包括示例65的装置,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该目的地页地址加第一块的尺寸。
201.示例67包括一种集成电路,其包括:核、耦合至核的硬件解压缩加速器、耦合至核的经压缩的高速缓存、耦合至核并通信地耦合至硬件解压缩加速器和经压缩的高速缓存的处理器、以及耦合至核并通信地耦合至处理器的存储器,其中,该存储器存储微代码指令,这些微代码指令当由处理器执行时使该处理器:响应于页错误的指示而加载页表条目;确定页表条目是否指示页将在错误时被解压缩,并且如果确定是,则基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及利用第一解压缩工作描述符的第一地址向硬件解压缩加速器生成第一入列事务,并利用第二解压缩工作描述符的第二地址向硬件解压缩加速器生成第二入列事务。
202.示例68包括示例67的集成电路,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:通过页表条目确定第一地址;以及将第二地址设置为第一解压缩工作描述符之后的连续地址。
203.示例69包括示例68的集成电路,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为指定的页地址加具有页尺寸的块的预定长度。
204.示例70包括示例67至69中的任一项的集成电路,进一步包括暂存器存储器,该暂存器存储器通信地耦合至处理器,用于存储第一解压缩工作描述符和第二解压缩工作描述符,并且其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:将第一地址设置为第一解压缩工作描述符在暂存器存储器中的地址;以及将第二地址设置为暂存器存储器的、在第一解压缩工作描述符之后的连续地址。
205.示例71包括示例70的集成电路,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:从页表条目中指示的存储器位置读取第一源地址和
数据长度;将第二源地址设置为第一源地址加数据长度;将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。
206.示例72包括示例71的集成电路,其中,经压缩的高速缓存按页来布置,其中每一页具有两个或更多个块。
207.示例73包括示例72的集成电路,其中,第一解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第一块对应,并且其中,第二解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第二块对应。
208.示例74包括示例73的集成电路,其中,存储器存储进一步的微代码指令,这些微代码指令当由处理器执行时使该处理器:将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为该目的地页地址加第一块的尺寸。
209.示例75包括一种解压缩设备,其包括:用于响应于页错误的指示来加载页表条目的装置;用于确定页表条目是否指示页将在错误时被解压缩的装置,以及如果确定是,则用于基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符的装置;以及用于利用第一解压缩工作描述符的第一地址向硬件解压缩加速器生成第一入列事务并利用第二解压缩工作描述符的第二地址向硬件解压缩加速器生成第二入列事务的装置。
210.示例76包括示例75的设备,进一步包括:用于通过页表条目确定第一地址的装置;以及用于将第二地址设置为第一解压缩工作描述符之后的连续地址的装置。
211.示例77包括示例76的设备,进一步包括:用于将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址的装置;以及用于将第二解压缩工作描述符中的第二目的地地址字段设置为该指定的页地址加具有页尺寸的块的预定长度的装置。
212.示例78包括示例75至77中的任一项的设备,进一步包括:用于将第一解压缩工作描述符和第二解压缩工作描述符存储在暂存器存储器中的装置;用于将第一地址设置为第一解压缩工作描述符在暂存器存储器中的地址的装置;以及用于将第二地址设置为暂存器存储器的、在第一解压缩工作描述符之后的连续地址的装置。
213.示例79包括示例78的设备,进一步包括:用于从页表条目中指示的存储器位置读取第一源地址和数据长度的装置;用于将第二源地址设置为第一源地址加数据长度的装置;用于将第一解压缩工作描述符中的第一源地址字段设置为第一源地址的装置;以及用于将第二解压缩工作描述符中的第二源地址字段设置为第二源地址的装置。
214.示例80包括示例79的设备,其中,经压缩的高速缓存按页来布置,其中每一页具有两个或更多个块。
215.示例81包括示例80的设备,其中,第一解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第一块对应,并且其中,第二解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第二块对应。
216.示例82包括示例81的设备,进一步包括:用于将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址的装置;以及用于将第二解压缩工作描述符中的第二
目的地地址字段设置为该目的地页地址加第一块的尺寸的装置。
217.示例83包括至少一种非暂态机器可读介质,包括多条指令,这些指令响应于在计算设备上被执行而使计算设备:响应于页错误的指示来加载页表条目;确定页表条目是否指示页将在错误时被解压缩,并且如果确定是,则基于来自页表条目的信息修改第一地址处的第一解压缩工作描述符和第二地址处的第二解压缩工作描述符;以及利用第一解压缩工作描述符的第一地址向硬件解压缩加速器生成第一入列事务,并利用第二解压缩工作描述符的第二地址向硬件解压缩加速器生成第二入列事务。
218.示例84包括示例83的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:通过页表条目确定第一地址;以及将第二地址设置为第一解压缩工作描述符之后的连续地址。
219.示例85包括示例84的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:将第一解压缩工作描述符中的第一目的地地址字段设置为与逻辑核相关联的指定的页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为指定的页地址加具有页尺寸的块的预定长度。
220.示例86包括示例83至85中的任一项的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:将第一解压缩工作描述符和第二解压缩工作描述符存储在暂存器存储器中;将第一地址设置为第一解压缩工作描述符在暂存器存储器中的地址;以及将第二地址设置为暂存器存储器的、在第一解压缩工作描述符之后的连续地址。
221.示例87包括示例86的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:从页表条目中指示的存储器位置读取第一源地址和数据长度;将第二源地址设置为第一源地址加数据长度;将第一解压缩工作描述符中的第一源地址字段设置为第一源地址;以及将第二解压缩工作描述符中的第二源地址字段设置为第二源地址。
222.示例88包括示例87的至少一种非暂态机器可读介质,其中,经压缩的高速缓存按页来布置,其中每一页具有两个或更多个块。
223.示例89包括示例88的至少一种非暂态机器可读介质,其中,第一解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第一块对应,并且其中,第二解压缩工作描述符与经压缩的高速缓存的页的两个或更多个块中的第二块对应。
224.示例90包括示例89的至少一种非暂态机器可读介质,包括多条进一步的指令,这些指令响应于在计算设备上被执行而使计算设备:将第一解压缩工作描述符中的第一目的地地址字段设置为目的地页地址;以及将第二解压缩工作描述符中的第二目的地地址字段设置为目的地页地址加第一块的尺寸。
225.在说明书中对“一个实施例”或“实施例”的引用意味着结合该实施例描述的特定特征、结构或特性被包括在本发明的至少一个实施例中。在本说明书中的不同位置处出现短语“在一个实施例中”不一定全都指同一个实施例。
226.本文中的详细描述的一些部分在对计算机存储器内数据位的操作的算法和符号表示方面来呈现。这些算法描述和表示是由计算领域的普通技术人员使用以向本领域其他技术人员最有效地传递其工作的实质的手段。算法在此一般被理解为导致所需结果的自洽
的步骤序列。这些步骤是需要对物理量进行物理操纵的那些步骤。通常但非必须,这些量采用能够被存储、传输、组合、比较、以及以其他方式操纵的电信号或磁信号的形式。主要出于常见用途的考虑,将这些信号称为位、值、元素、符号、字符、项、数字等已被证明有时是方便的。
227.然而,应当记住,所有这些和类似的术语用于与适当的物理量关联,并且仅仅是应用于这些量的方便的标记。除非以其他方式明确指明,否则如从本文的讨论中显而易见的,可以理解,贯穿说明书,利用诸如“处理”或“计算”或“运算”或“确定”或“显示”等术语的讨论,指的是计算机系统或类似电子计算设备的动作和进程,该计算机系统或类似电子计算设备操纵在该计算机系统的寄存器和存储器内表示为物理(电子)量的数据并将其转换成在该计算机系统存储器或寄存器或其他此类信息存储、传输或显示设备内类似地表示为物理量的其他数据。
228.某些实施例还涉及用于执行本文中操作的装置。该装置可专门构造来用于所需目的,或其可包括通用计算机,该通用计算机由存储在该计算机内的计算机程序有选择地激活或重新配置。此类计算机程序可以存储在计算机可读存储介质中,该计算机可读存储介质诸如但不限于任何类型的盘,包括软盘、光盘、cd-rom、磁光盘、只读存储器(rom)、诸如动态随机存取存储器(ram)(dram)的ram、eprom、eeprom、磁卡或光卡、或适用于存储电子指令且耦合至计算机系统总线的任何类型的介质。
229.本文中呈现的算法和显示并非固有地与任何特定计算机或其他装置相关。可以将各种通用系统与根据本文中的教导的程序一起使用,或可以证明构造更专门的装置来执行所要求的方法步骤是方便的。各种这些系统的所需结构将从本文中的描述呈现。此外,某些实施例不是参考任何特定编程语言来描述的。将会理解,可以使用各种编程语言来实现本文所描述的此类实施例的教导。
230.除了本文所描述的内容,可对所公开的实施例及其实现方式作出各种修改而不背离其范围。因此,本文中的说明和示例应当被解释成说明性的,而非限制性的。本发明的范围应当仅通过参照所附权利要求书来界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。