1.本技术涉及音频数据处理技术领域,尤其涉及一种音频数据处理方法和装置、语音交互方法、设备和芯片、音箱、电子设备及存储介质。
背景技术:
2.随着社会的发展,人们之间的通信也变得越来越频繁,特别是基于语音技术的通信,已经从过去仅通过电话网络进行通话而演变为通过更多的各种样式的工具或方式来进行语音通信,例如人们现在已经在从过去的电脑手机等工具向多元化和小型化,尤其是可穿戴式设备的方向发展,但是人们进行通话的环境也变得越来越复杂,相应地在人们进行通话时也施加了更多的影响,例如,设备回声,非目标人物说话的语音、外界噪声干扰等等,这些都直接导致了用户所使用的设备的拾音组件拾取的通话人的语音的原始音是带回声、带噪、低信噪比的语音信号。因此,人们对于在通信过程中采集和传递的音频提出了更高的要求,尤其是在音频质量方面需要更清晰的音频效果。例如,现有技术中已经使用了各种语音识别算法来从上述这样的带有回声、带有噪声或者低信噪比的语音信号中识别出语音,因此,在通话或者甚至人机交互的场景带来了很大的困扰。
3.因此,需要一种能够对原始音频信号中的语音信号进行增强的技术。
技术实现要素:
4.本技术实施例提供一种音频数据处理方法和装置、语音交互方法、设备和芯片、音箱、电子设备及存储介质,以解决现有技术中从混合音频信号中分离音频信号的缺陷。
5.为达到上述目的,本技术实施例提供了一种音频数据处理方法,包括:
6.获取麦克风信号和参考信号,其中,所述麦克风信号为一个或多个麦克风接收到的音频信号,所述参考信号为一个或多个由扬声器播放的音频信号;
7.根据空间传递函数和回声路径数据,对当前麦克风信号和历史麦克风信号以及当前的参考信号进行处理,以分离一个或多个音频源发出的源信号。
8.本技术实施例还提供了一种语音交互方法,包括:
9.接收当前麦克风信号和参考信号,其中,所述当前麦克风信号为多个麦克风当前接收到的音频信号,所述参考信号包括一个或多个由扬声器播放的音频信号,并且所述当前麦克风信号中至少包含有语音信号;
10.使用空间传递函数和回声路径数据将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式;
11.计算所述麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据所述相关性确定所述当前麦克风信号中的语音信号;
12.根据所确定的语音信号执行对应的处理。
13.本技术实施例还提供了一种语音交互设备,包括:一个或多个麦克风、扬声器以及
处理器,
14.其中,所述一个或多个麦克风用于接收当前麦克风信号,其中所述当前麦克风信号中至少包含有语音信号;
15.所述扬声器用于播放音频信号;
16.所述处理器用于使用所述扬声器播放的音频信号作为参考信号,并使用空间传递函数和回声路径数据将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,以计算所述麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据所述相关性确定所述当前麦克风信号中的语音信号,以根据所确定的语音信号执行对应的处理。
17.本技术实施例还提供了一种音箱,包括:一个或多个麦克风、扬声器以及处理器,
18.其中,所述一个或多个麦克风用于接收当前麦克风信号,其中所述当前麦克风信号中至少包含有语音信号;
19.所述扬声器用于播放音频信号;
20.所述处理器用于使用所述扬声器播放的音频信号作为参考信号,并使用空间传递函数和回声路径数据将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,以计算所述麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据所述相关性确定所述当前麦克风信号中的语音信号,以根据所确定的语音信号执行对应的播放处理。
21.本技术实施例还提供了一种语音交互芯片,包括:
22.麦克风信号接收模块,用于从麦克风接收当前麦克风信号,其中所述当前麦克风信号中至少包含有语音信号;
23.播放模块,用于将音频信号发送给扬声器;
24.处理模块,用于使用播放模块发送的音频信号作为参考信号,并使用空间传递函数和回声路径数据将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,以计算所述麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据所述相关性确定所述当前麦克风信号中的语音信号,以根据所确定的语音信号生成对应的处理指令。
25.本技术实施例还提供了一种音频数据处理装置,包括:
26.获取模块,用于获取麦克风信号和参考信号,其中,所述麦克风信号为一个或多个麦克风接收到的音频信号,所述参考信号为一个或多个由扬声器播放的音频信号;
27.处理模块,用于根据空间传递函数和回声路径数据,对当前麦克风信号和历史麦克风信号以及当前的参考信号进行处理,以分离一个或多个音频源发出的源信号。
28.本技术实施例还提供了一种电子设备,包括:
29.存储器,用于存储程序;
30.处理器,用于运行所述存储器中存储的所述程序,所述程序运行时执行本技术实施例提供的音频数据处理方法或语音交互方法。
31.本技术实施例还提供了一种计算机可读存储介质,其上存储有可被处理器执行的计算机程序,其中,该程序被处理器执行时实现如本技术实施例提供的音频数据处理方法或语音交互方法。
32.本技术实施例还提供了一种计算机程序产品,包括计算机程序或指令,其中,当所述计算机程序或指令被处理器执行时,致使所述处理器实现如本技术实施例提供的音频数据处理方法或语音交互方法。
33.本技术实施例提供的音频数据处理方法和装置、语音交互方法、设备和芯片、音箱、电子设备及存储介质,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
34.上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
附图说明
35.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本技术的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
36.图1a为本技术实施例提供的音频数据处理方案的应用场景示意图;
37.图1b为本技术实施例提供的音频数据处理方法的应用架构的示意图;
38.图2为本技术提供的音频数据处理方法一个实施例的流程图;
39.图3为本技术提供的语音交互方法一个实施例的流程图;
40.图4为本技术提供的音频数据处理装置实施例的结构示意图;
41.图5为本技术提供的语音交互设备实施例的结构示意图;
42.图6为本技术实施例提供的音箱实施例的结构示意图;
43.图7为本技术实施例提供的语音交互芯片的示意图;
44.图8为本技术提供的电子设备实施例的结构示意图。
具体实施方式
45.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
46.实施例一
47.本技术实施例提供的方案可应用于任何具有音频数据处理能力的计算系统,例如通信服务器等等。图1a为本技术实施例提供的音频数据处理方案的应用场景示意图,图1a所示的场景仅仅是本技术的技术方案可以应用的场景的示例之一。
48.随着社会的发展,人们使用语音的场景也越来越多,不仅人们之间的通信变得越来越频繁,特别是基于语音技术的通信,已经从过去仅通过电话网络进行通话而演变为通过更多的各种样式的工具或方式来进行语音通信,并且人们现在使用音频的工具也从过去
的电脑手机等工具向多元化和小型化,尤其是可穿戴式设备的方向发展,但是人们进行通话等使用语音的环境也变得越来越复杂,相应地在人们在使用语音时也施加了更多的影响,例如,设备回声,非目标人物说话的语音、外界噪声干扰等等,这些都直接导致了用户所使用的设备的拾音组件拾取的通话人的语音的原始音是带回声、带噪、低信噪比的语音信号,这样的原始音不仅影响与目标说话人的通话对象之间的通话,而且还在例如人机交互的使用场景中影响识别效果,进而影响用户想要控制的对象的执行。因此,人们对于在在各种环境下采集和传递的音频提出了更高的要求,尤其是在音频质量方面需要更清晰的音频效果。
49.为此,现有技术中提出了使用各种算法来对音频信号进行音频增强处理,即,对非目标人物的说话的语音以及其他环境噪声等进行抑制。并且也提出了针对混杂了多种音频信号的上述原始语音中的各种音频进行针对性处理的处理方法和模块/装置。
50.例如,为了能够从通信设备采集到的混有回声、噪声等的原始音识别出目标说话人的语音,已经开始使用了各种算法来使用某个单一算法针对特定类型的环境噪声问题进行处理,例如,使用回声消除方案来进行回声消除,使用去混响方案来去除混入的噪声等,以及使用盲源分离方案来识别不同来源的音频数据。并且随着人们对于语音识别的要求的提高,现有技术中的使用单一算法的方案无法解决原始语音中存在的全部问题。因此,现有技术中已经提出了以子模块级联方式对原始语音进行处理的方案,例如,“回声消除
→
去混响
→
盲源分离”方案或“波束形成
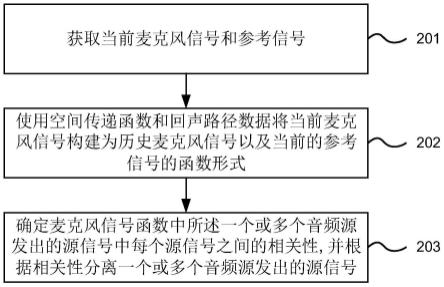
→
回声消除
→
去混响”,这样的现有技术的方案虽然能够对原始语音中存在的多种问题进行级联式的求解并且由于使用子模块级联的形式也使得能够在使用中非常灵活,但是其缺陷在于级联的各个子模块之间都是彼此独立地工作的,并且每个子模块使用自己的目标函数和优化方法,因此,在使用过程中,虽然每个子模块都是最终达到自己的极值化状态,但是实际上,局部极值并非是整体极值,即,每个子模块自己的算法必然都没有考虑其它算法处理时的情况,即,无法实现协作以实现整体极值。
51.因此,本技术提出了一种能够在统一的框架下对音频数据进行多种处理的方案,如图1a中所示,图1a是根据本技术的音频数据处理方法的应用场景的示意图。在图1a中所示的场景中,当目标说话人在观看电视时,想要通过语音来对电视进行控制,例如切换频道的操作。因此,目标说话人可以在观看位置朝向电视发出“下一台”的语音指令,即图1a中所示的直达声。在该情况下,目标说话人所发出的直达声在到达电视的过程中,在与目标说话人处于同一空间中,即处于同一房间中存在着其他音源以及各种环境声音。例如,如图1中所示,在目标说话人的旁边还存在着与目标说话人一起观看电视的家人作为干扰说话人,在目标说话人发出语音指令的过程中,该干扰说话人也可能同时例如进行说话或者发出其他声响,从而电视的拾音设备在该过程中也会接收到干扰说话人发出的干扰音频。
52.此外,目标说话人发出的语音经由房间的墙壁的反射而形成反射声,并且也会传播到电视附近,从而电视的拾音设备在接收目标说话人的语音过程中也会同时接收到该反射声。此外,房间中还存在着一些会发出声音的设备,例如,图1a中所示的场景中,在目标说话人的身后还放置着打印机,该打印机如果处于打印过程中,则还会发出嗡嗡的打印噪声,并且该打印噪声也会直接或经由反射而传播到电视。此外,电视在播放电视节目过程中也会通过扬声器发出音频,并且电视的拾音设备也会接收到扬声器发出的声音的声学回波。因此,在目标说话人发出语音指令之后,电视的拾音设备接收到的原始音频中会包含有上
述所有音频中的至少几种。因此,在识别时需要从该原始音频中去除各种噪声,或者识别出来自干扰说话人和发出声音的设备发出的声音,以使得目标说话人的声音更加清楚,即,对目标说话人的语音进行增强处理,使得电视的处理设备能够准确地识别出目标说话人的指令。
53.因此,在现有技术中,通常是使用多个模块的组合,即级联来实现对于原始音频中的不同类型的处理。例如,现有技术中提出了采用“回声消除
→
去混响
→
盲源分离”这三个模块的级联来分别对如图1a中所示的电视的拾音设备接收到的原始音频依次进行处理,即先应用回声消除模块来从原始音频中消除扬声器发出的声音经由墙壁等反射而由拾音设备接收到的回波,之后再应用去混响模块来将由于目标说话人发出的语音经由墙壁反射而受到的反射声,之后再通过盲源分离模块来确定经过了前两个模块处理之后的音频中包含的不同音频来源,并且进行对应的音频分离。在该过程中,由于每个子模块都是独立地进行处理。
54.因此,不可避免的是,先进行处理的子模块对原始音频进行的处理会对后面进行处理的子模块的处理带来影响。例如,去混响模块是对音源发出的音频经过反射形成反射声进行处理,但是经过这样处理之后的音频中包含的各音源发出的音频也可能被减弱,从而在最终由盲源分离模块进行盲源分离时就会可能由于某个或一些音源发出的音频的强度被减弱太多而不能够再盲源分离模块中被正确地识别并分离出来,从而被最终识别为目标说话人发出的音频,因此使得电视对根据说话人的语音指令的识别效果得到了劣化。
55.为此,在本技术实施例中,在对如图1a中所示的场景中由例如电视的拾音设备接收到的原始音频进行处理时,可以仅通过根据麦克风信号和麦克风信号的历史信号进行处理,就能够一次实现回声消除和去混响以及盲源分离这三个处理,从而最终获得音频源发出的源信号。具体地,可以先获取一个或多个麦克风接收到的音频信号作为麦克风信号以及由音频播放装置播放的原始声音作为参考信号,因此,根据本技术实施例中,在麦克风信号的历史信息中包含了源信号和参考信号的历史信息,因此在本技术实施例中,可以在获取了麦克风信号和参考信号之后,根据空间传递函数和回声路径数据,就可以对当前接收到的麦克风信号和历史麦克风信号以及当前的参考信号进行处理,从而实现对原始音频的三种处理,进而获得音频源发出的源信号。
56.图1b示出了本技术实施例提供的音频数据处理方法的应用架构的示意图,如图1b中所示,由麦克风接收的外部音频信号,即麦克风信号和发送到播放器进行播放的音频信号,即参考信号可以通过使用空间传递函数和回声路径数据来构建为函数形式,从而通过例如处理器的处理模块部分来确定函数形式的麦克风信号函数中所包含的一个或多个音频源发出的源信号中各个源信号之间的相关性,从而就能够根据所确定的相关性从麦克风信号中分离处各个源信号。
57.因此,根据本技术实施例的音频数据处理方案,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
58.上述实施例是对本技术实施例的技术原理和示例性的应用框架的说明,下面通过
多个实施例来进一步对本技术实施例具体技术方案进行详细描述。
59.实施例二
60.图2为本技术提供的音频数据处理方法一个实施例的流程图,该方法的执行主体可以为具有音频数据处理能力的各种终端或服务器设备,也可以为集成在这些设备上的装置或芯片。如图2所示,该音频数据处理方法包括如下步骤:
61.s201,获取当前麦克风信号和参考信号。
62.人们在通信或使用智能设备进行人机交互的时候,可以通过所使用的通信设备或智能设备来采集或拾取目标说话人发出的语音。具体地,在本技术实施例中,可以通过例如麦克风的拾取设备来采集用户的语音信号。但是实际上,用户通常发出语音的环境非常复杂。例如,图1a中所示的是用户常见起居室中的场景,用户在观看电视的过程中向电视发出语音指令,从而作为控制对象的电视机可以通过其麦克风来接收该语音指令,但是由于用户所处的环境中还存在着多个音源和多种干扰因素,例如,在目标说话人的旁边还存在着与目标说话人一起观看电视的家人作为干扰说话人,在目标说话人发出语音指令的过程中,该干扰说话人也可能同时例如进行说话或者发出其他声响,从而电视的拾音设备在该过程中也会接收到干扰说话人发出的干扰音频。
63.此外,目标说话人发出的语音经由房间的墙壁的反射而形成反射声,并且也会传播到电视附近,从而电视的拾音设备在接收目标说话人的语音过程中也会同时接收到该反射声。此外,房间中还存在着一些会发出声音的设备,例如,图1a中所示的场景中,在目标说话人的身后还放置着打印机,该打印机如果处于打印过程中,则还会发出嗡嗡的打印噪声,并且该打印噪声也会直接或经由反射而传播到电视。
64.此外,电视在播放电视节目过程中也会通过扬声器发出音频,并且电视的拾音设备也会接收到扬声器发出的声音的声学回波。因此,在目标说话人发出语音指令之后,在步骤s201中可以接收到包含有上述所有音频中的至少几种的当前麦克风信号,特别地,在电视机中可以设置多个麦克风,来从不同位置和角度接收音频信号,以增强接收的音频信号的强度。此外,在本技术实施例中还需要接收参考信号以便于对麦克风信号中包含的多种音频进行分离处理。例如,参考信号可以是一个或多个由扬声器播放的音频信号,具体地,在本技术实施例中,例如,参考信号可以是传输到电视机的扬声器以便于扬声器播放给用户的电视节目的音频数据,并且该音频数据在被扬声器播放出来之后,可能会再被扬声器作为环境声音而与目标说话人的语音指令一起被接收到,从而该参考信号就可以用于分离接收到的麦克风信号中的该环境声音。
65.s202,使用空间传递函数和回声路径数据将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
66.在步骤s201中获取到了当前麦克风信号和参考信号之后,在本技术实施例中,可以进一步接收历史麦克风信号,特别是,历史麦克风信号已经包含有来自音频源的原信号和参考信号的历史信息,即,如上所述,在步骤s201中接收到的麦克风信号是各种音频源发送的音频信号并且还接收到了参考信号,因此在步骤s202中可以根据空间传递函数和回声路径数据来通过例如建模以将步骤s201中接收到的当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
67.例如,在本技术实施例中,步骤s201中接收到的当前麦克风信号可以为:
[0068][0069]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0070]
因此在本技术实施例中,可以在获取了麦克风信号和参考信号之后,根据空间传递函数和回声路径数据,就可以将当前接收到的麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,例如下面的公式:
[0071][0072]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0073]
s203,确定麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据相关性分离一个或多个音频源发出的源信号。
[0074]
由于步骤s202中获得的当前麦克风信号函数中包含了各种音频源的音频信号,并且由于源信号通常是彼此独立的并且遵循非高斯分布,因此在步骤s203中,可以对于步骤s202中生成的当前麦克风信号函数中的各个源信号计算之间的相关性,例如,非高斯性的相关性,并且根据该相关性能,例如取相关性最大的极值部分来作为两个信号的分离点,因此就可以将当前麦克风信号中包含的混在一起的多个音频源的源信号进行分离。
[0075]
例如,在本技术实施例中,步骤s201中接收到的麦克风信号可以为:
[0076][0077]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0078]
具体地,例如,如上述公式(1)中所示,历史麦克风信号可以是对当前时刻之前的所有时刻的历史麦克风信号的加权和。即,当l=1时,为当前时刻前一时刻的麦克风历史数据,并且随着l的增加,x(τ-l)可以表示在时间上更早时刻的麦克风历史数据,并且c
l
可以为加权系数,从而通过对各个时刻的历史麦克风信号的加权求和,能够获得更准确的历史麦克风数据。
[0079]
此外,在本技术实施例中,由于例如混响信号随着时间而衰减,因此,可以将上述公式(1)近似为下面的公式(2):
[0080][0081]
其中,l为进行音频处理所使用的滤波器建模的数据块的数目,即将加权求和计算的上限修改为l,并且显而易见的是,l越大则该公式越接近上述公式(1),并且当l为无穷大时该公式(2)可以变回到公式(1)。但是通过使用公式(2)的近似,可以将公式(1)中的加权求和变为有限数量的加权求和计算,能够大大降低了计算量。
[0082]
特别地,在本技术实施例中,通过将公式(2)改写为下面所示的公式(3)的矩阵与向量相乘的形式就可以使用iva(独立向量分析)的方法进行求解。
[0083]
即,
[0084][0085]
特别地,由于对于去混响和回声消除来说,并不存在排列歧义性的影响,所以在本技术实施例中可以使用ica(独立成分分析)的非线性加权方法从而在对上述公式(3)进行求解的过程中,可以使用ica的非线性加权方法来进行计算。即,可以引入分离矩阵q来进行求解,从而公式(3)变为下面的公式(4):
[0086][0087]
此外,在本技术实施例中,还可以进一步按照分频段的方法来计算非线性加权,即,使用下述公式(5)来计算分离矩阵q,
[0088][0089]
例如,在本技术实施例中,可以先对q
draec
进行迭代来实现去混响和消除回声,之后再对q
bss
进行迭代来实现盲源分离。因此,通过该方式,可以提高计算效率。
[0090]
特别地,在本技术实施例中,当使用滤波器g作为去混响和回声消除部分的滤波器时,上述公式(5)中的q
draec
与滤波器g的关系可以如下面的公式(6)所示:
[0091][0092]
在对滤波器g进行初始化之后,可以根据下面的公式(7)来计算去混响之后的近端语音y,该近端语音y可以表示麦克风接收到的用户发出的语音音频,
[0093][0094]
之后可以根据下面的公式(8)来计算上述非线性加权系数β,
[0095]
β(τ)=(1-α)(‖y(τ)‖2 δ)
(γ-2)/2
ꢀꢀ
(8)
[0096]
因此,可以根据下面的公式(9)来更新在步骤s301中接收到的麦克风信号与参考信号之间的互相关矩阵,其中h可以表示共轭转置,
[0097][0098]
并且根据下面的公式(10)来更新参考信号的相关矩阵,
[0099][0100]
继而根据下面的公式(11)来更新滤波器g,
[0101][0102]
因此,通过上述迭代过程,可以获得盲源分离后的目标说话人,即用户发出的语音
信号,可以构建为下面的公式(12):
[0103]
z(τ)=d(τ-1)y(τ)
ꢀꢀ
(12)
[0104]
其中,d为分离矩阵,并且可以使用各种方式来对该分离矩阵进行更新。
[0105]
因此,根据本技术实施例的音频数据处理方案,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
[0106]
实施例三
[0107]
图3为本技术提供的语音交互方法一个实施例的流程图,该方法的执行主体可以为具有语音交互能力的各种终端或服务器设备,也可以为集成在这些设备上的装置或芯片。如图3所示,该语音交互方法包括如下步骤:
[0108]
s301,获取当前麦克风信号和参考信号。
[0109]
在本技术实施例中,可以通过例如麦克风的拾取设备来采集用户的语音信号。但是实际上,用户通常发出语音的环境非常复杂。例如,图1a中所示的是用户常见起居室中的场景,用户在观看电视的过程中向电视发出语音指令,从而作为控制对象的电视机可以通过其麦克风来接收该语音指令,但是由于用户所处的环境中还存在着多个音源和多种干扰因素。因此,在目标说话人发出语音指令之后,在步骤s301中可以接收到包含有上述所有音频中的至少几种的当前麦克风信号,特别地,在电视机中可以设置多个麦克风,来从不同位置和角度接收音频信号,以增强接收的音频信号的强度。此外,在本技术实施例中还需要接收参考信号以便于对麦克风信号中包含的多种音频进行分离处理。例如,参考信号可以是一个或多个由扬声器播放的音频信号,具体地,在本技术实施例中,例如,参考信号可以是传输到电视机的扬声器以便于扬声器播放给用户的电视节目的音频数据,并且该音频数据在被扬声器播放出来之后,可能会再被扬声器作为环境声音而与目标说话人的语音指令一起被接收到,从而该参考信号就可以用于识别接收到的麦克风信号中的语音信号。
[0110]
s302,使用空间传递函数和回声路径数据将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
[0111]
在步骤s301中获取到了当前麦克风信号和参考信号之后,在本技术实施例中,可以进一步接收历史麦克风信号,特别是,历史麦克风信号已经包含有来自音频源的源信号和参考信号的历史信息,即,如上所述,在步骤s301中接收到的麦克风信号是各种音频源发送的音频信号并且还接收到了参考信号,因此在步骤s302中可以根据空间传递函数和回声路径数据来通过例如建模以将步骤s301中接收到的当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
[0112]
例如,在本技术实施例中,步骤s301中接收到的当前麦克风信号可以为:
[0113][0114]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0115]
因此在本技术实施例中,可以在获取了麦克风信号和参考信号之后,根据空间传递函数和回声路径数据,就可以将当前接收到的麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,例如下面的公式:
[0116][0117]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0118]
s303,确定麦克风信号函数中一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据相关性分离一个或多个音频源发出的源信号。
[0119]
由于步骤s302中获得的当前麦克风信号函数中包含了各种音频源的音频信号,并且由于源信号通常是彼此独立的并且遵循非高斯分布,因此在步骤s303中,可以对于步骤s302中生成的当前麦克风信号函数中的各个源信号计算之间的相关性,例如,非高斯性的相关性,并且根据该相关性能,例如取相关性最大的极值部分来作为两个信号的分离点,因此就可以将当前麦克风信号中包含的混在一起的多个音频源的源信号进行分离,例如可以获得用户所发出的语音指令的语音音频信号。
[0120]
s304,根据所确定的与语音信号执行对应的处理。
[0121]
因此,根据本技术实施例,在步骤s303中从麦克风接收到的混合了多个音频源的源信号的混合信号中识别或分离出用户所发出的语音信号的音频信号,因此在步骤s304中就可以根据所确定的语音信号来执行对应的交互处理。例如,用户在观看电视节目的过程中,可以发出“提高音量”这样的语音指令,该语音指令被混合在电视播放的节目音频、用户所处的房间的房间噪声等各种音频中被电视机的麦克风所采集到,因此通过步骤s302和s303的处理就可以从该混合音频中识别或分离出用户发出的语音信号,并且因此在步骤s304中就可以执行与该语音信号对应的处理,即提高电视扬声器播放的音量。
[0122]
因此,根据本技术实施例的语音交互方案,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
[0123]
实施例四
[0124]
图4为本技术提供的音频数据处理装置实施例的结构示意图,可用于执行如图2所示的方法步骤。如图4所示,该音频数据处理装置可以包括:获取模块41、计算模块42和执行模块43。
[0125]
获取模块41可以用于获取当前麦克风信号和参考信号。
[0126]
人们在通信或使用智能设备进行人机交互的时候,可以通过所使用的通信设备或智能设备来采集或拾取目标说话人发出的语音。具体地,在本技术实施例中,可以通过例如麦克风的获取模块41来采集用户的语音信号。在目标说话人发出语音指令之后,获取模块41可以接收到包含有多种音频的麦克风信号,特别地,在电视机中可以设置多个麦克风,来
从不同位置和角度接收音频信号,以增强接收的音频信号的强度。此外,在本技术实施例中还需要接收参考信号以便于对麦克风信号中包含的多种音频进行分离处理。例如,参考信号可以是一个或多个由扬声器播放的音频信号,具体地,在本技术实施例中,例如,参考信号可以是传输到电视机的扬声器以便于扬声器播放给用户的电视节目的音频数据,并且该音频数据在被扬声器播放出来之后,可能会再被扬声器作为环境声音而与目标说话人的语音指令一起被接收到,从而该参考信号就可以用于分离接收到的麦克风信号中的该环境声音。
[0127]
计算模块42可以用于使用空间传递函数和回声路径数据将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
[0128]
在获取模块41获取到了当前麦克风信号和参考信号之后,在本技术实施例中,可以进一步接收历史麦克风信号,特别是,历史麦克风信号已经包含有来自音频源的原信号和参考信号的历史信息,即,如上所述,获取模块41接收到的麦克风信号是各种音频源发送的音频信号并且还接收到了参考信号,因此计算模块42可以根据空间传递函数和回声路径数据来通过例如建模以将获取模块41接收到的当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
[0129]
例如,在本技术实施例中,获取模块41接收到的当前麦克风信号可以为:
[0130][0131]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0132]
因此在本技术实施例中,可以在获取了麦克风信号和参考信号之后,根据空间传递函数和回声路径数据,就可以将当前接收到的麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,例如下面的公式:
[0133][0134]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0135]
计算模块42可以进一步用于确定麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据相关性分离一个或多个音频源发出的源信号。
[0136]
由于获取模块41获得的当前麦克风信号函数中包含了各种音频源的音频信号,并且由于源信号通常是彼此独立的并且遵循非高斯分布,因此计算模块42就可以对于生成的当前麦克风信号函数中的各个源信号计算之间的相关性,例如,非高斯性的相关性,并且根据该相关性能,例如取相关性最大的极值部分来作为两个信号的分离点,因此就可以将当前麦克风信号中包含的混在一起的多个音频源的源信号进行分离。
[0137]
例如,在本技术实施例中,获取模块41接收到的麦克风信号可以为:
[0138][0139]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0140]
具体地,例如,如上述公式(1)中所示,历史麦克风信号可以是对当前时刻之前的所有时刻的历史麦克风信号的加权和。即,当l=1时,为当前时刻前一时刻的麦克风历史数据,并且随着l的增加,x(τ-l)可以表示在时间上更早时刻的麦克风历史数据,并且c
l
可以为加权系数,从而通过对各个时刻的历史麦克风信号的加权求和,能够获得更准确的历史麦克风数据。
[0141]
此外,在本技术实施例中,由于例如混响信号随着时间而衰减,因此,可以将上述公式(1)近似为下面的公式(2):
[0142][0143]
其中,l为进行音频处理所使用的滤波器建模的数据块的数目,即将加权求和计算的上限修改为l,并且显而易见的是,l越大则该公式越接近上述公式(1),并且当l为无穷大时该公式(2)可以变回到公式(1)。但是通过使用公式(2)的近似,可以将公式(1)中的加权求和变为有限数量的加权求和计算,能够大大降低了计算量。
[0144]
特别地,在本技术实施例中,通过将公式(2)改写为下面所示的公式(3)的矩阵与向量相乘的形式就可以使用iva(独立向量分析)的方法进行求解。
[0145]
即,
[0146][0147]
特别地,由于对于去混响和回声消除来说,并不存在排列歧义性的影响,所以在本技术实施例中可以使用ica(独立成分分析)的非线性加权方法从而在对上述公式(3)进行求解的过程中,可以使用ica的非线性加权方法来进行计算。即,可以引入分离矩阵q来进行求解,从而公式(3)变为下面的公式(4):
[0148][0149]
此外,在本技术实施例中,还可以进一步按照分频段的方法来计算非线性加权,即,使用下述公式(5)来计算分离矩阵q,
[0150][0151]
例如,在本技术实施例中,可以先对q
draec
进行迭代来实现去混响和消除回声,之后再对q
bss
进行迭代来实现盲源分离。因此,通过该方式,可以提高计算效率。
[0152]
特别地,在本技术实施例中,当使用滤波器g作为去混响和回声消除部分的滤波器时,上述公式(5)中的q
draec
与滤波器g的关系可以如下面的公式(6)所示:
[0153][0154]
在对滤波器g进行初始化之后,可以根据下面的公式(7)来计算去混响之后的近端语音y,该近端语音y可以表示麦克风接收到的用户发出的语音音频,
[0155][0156]
之后可以根据下面的公式(8)来计算上述非线性加权系数β,
[0157]
β(τ)=(1-α)(‖y(τ)‖2 δ)
(γ-2)/2
ꢀꢀ
(8)
[0158]
因此,可以根据下面的公式(9)来更新在步骤s301中接收到的麦克风信号与参考信号之间的互相关矩阵,其中h可以表示共轭转置,
[0159][0160]
并且根据下面的公式(10)来更新参考信号的相关矩阵,
[0161][0162]
继而根据下面的公式(11)来更新滤波器g,
[0163][0164]
因此,通过上述迭代过程,可以获得盲源分离后的目标说话人,即用户发出的语音信号,可以构建为下面的公式(12):
[0165]
z(τ)=d(τ-1)y(τ)
ꢀꢀ
(12)
[0166]
其中,d为分离矩阵,并且可以使用各种方式来对该分离矩阵进行更新。
[0167]
因此,根据本技术实施例的音频数据处理方案,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
[0168]
实施例五
[0169]
图5为本技术提供的语音交互设备实施例的结构示意图,可用于执行如图3所示的方法步骤。如图5所示,该语音交互设备可以包括:一个或多个麦克风51、扬声器52和处理器53。
[0170]
人们在通信或使用智能设备时通常需要进行人机交互,并且因此这样的通信设备或智能设备可以是本技术实施例所提供的语音交互设备,因此可以通过所使用的这样的语音交互设备被来采集或拾取目标说话人发出的语音并进而根据识别出的语音来进行相应的操作。
[0171]
例如,在本技术实施例中,可以通过麦克风51来采集用户的语音信号。由于通常用户在例如房间的环境中使用语音交互设备,因此在目标说话人发出语音指令之后,麦克风51会接收到包含有多种音频的麦克风信号,把并且这样的麦克风信号除了包含有用户发出的语音信号之外还会包含各种环境噪声以及其他音源发出的声音。因此,在本技术实施例中,可以设置一个或多个麦克风51,来从不同位置和角度接收音频信号,以增强接收的音频
信号的强度。此外,在本技术实施例中还需要接收参考信号以便于对麦克风信号中包含的多种音频进行识别处理。例如,本技术的语音交互设备由于不仅需要接收用户的语音指令,更重要的是,其通常需要为用户播放用户所需要的各种音频。因此,本技术的语音交互设备中的扬声器52可以播放各种音频信号,并且从而处理器53可以使用这些发送到扬声器52进行播放的音频信号作为参考信号。这样的音频数据在被扬声器52播放出来之后,可能会再被麦克风51作为环境声音而与目标说话人的语音指令一起被接收到,从而该参考信号就可以用于分离接收到的麦克风信号中的该环境声音。
[0172]
因此,处理器53可以使用扬声器52播放的音频信号作为参考信号,并使用空间传递函数和回声路径数据将麦克风51接收到的当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,以计算所述麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据所述相关性确定所述当前麦克风信号中的语音信号,以根据所确定的语音信号执行对应的处理。
[0173]
例如,麦克风51接收到的历史麦克风信号已经包含有来自音频源的原信号和参考信号的历史信息,即,如上所述,麦克风51接收到的麦克风信号是各种音频源发送的音频信号,因此处理器53可以根据空间传递函数和回声路径数据来通过例如建模以将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
[0174]
例如,在本技术实施例中,麦克风51接收到的当前麦克风信号可以为:
[0175][0176]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0177]
因此在本技术实施例中,可以在获取了麦克风信号和参考信号之后,根据空间传递函数和回声路径数据,就可以将当前接收到的麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,例如下面的公式:
[0178][0179]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0180]
处理器53可以进一步用于确定麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据相关性分离一个或多个音频源发出的源信号。
[0181]
由于麦克风51获得的当前麦克风信号函数中包含了各种音频源的音频信号,并且由于源信号通常是彼此独立的并且遵循非高斯分布,因此处理器53就可以对于生成的当前麦克风信号函数中的各个源信号计算之间的相关性,例如,非高斯性的相关性,并且根据该相关性能,例如取相关性最大的极值部分来作为两个信号的分离点,因此就可以将当前麦克风信号中包含的混在一起的多个音频源的源信号进行分离。从而就能够根据计算出的相关性来确定当前麦克风信号中的语音信号,因此就可以根据所确定的语音信号来执行对应
的交互处理。
[0182]
例如,用户在观看电视节目的过程中,可以发出“提高音量”这样的语音指令,该语音指令被混合在电视播放的节目音频、用户所处的房间的房间噪声等各种音频中被电视机的麦克风所采集到,因此处理器53就可以从该混合音频中识别或分离出用户发出的语音信号,并且因此就可以执行与该语音信号对应的处理,即提高扬声器52播放的音量。
[0183]
因此,根据本技术实施例的语音交互方案,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
[0184]
实施例六
[0185]
图6为本技术提供的音箱实施例的结构示意图,可用于执行如图3所示的方法步骤。如图6所示,该音箱可以包括:一个或多个麦克风61、扬声器62和处理器63。
[0186]
现有的音箱已经不仅仅是为用户播放指定的音频文件,用户更多地需要音箱也能够听懂用户的指令,与用户进行交互,例如,用户无需使用接触音箱或使用遥控器来控制音箱,而是在收听音箱的播放过程中仅通过发出语音指令来控制音箱的操作,甚至在音箱通过网络连接接入到互联网的情况下,用户可以通过语音来与音箱进行例如问答等的语音交互。但是由于用户通常在例如房间的环境中使用音箱,或者往往在音箱播放音频的情况下与音箱进行交互,因此可以通过麦克风61来采集包含有用户的语音信号的各种音频信号。特别地,在本技术实施例中,可以设置一个或多个麦克风61,来从不同位置和角度接收音频信号,以增强接收的音频信号的强度。此外,在本技术实施例中还需要接收参考信号以便于对麦克风信号中包含的多种音频进行识别处理。例如,本技术的音箱由于不仅需要接收用户的语音指令,更重要的是,其通常需要为用户播放用户所需要的各种音频。因此,本技术的音箱中的扬声器62可以播放各种音频信号,并且从而处理器63可以使用这些发送到扬声器62进行播放的音频信号作为参考信号。这样的音频数据在被扬声器62播放出来之后,可能会再被麦克风61作为环境声音而与目标说话人的语音指令一起被接收到,从而该参考信号就可以用于分离接收到的麦克风信号中的该环境声音。
[0187]
因此,处理器63可以使用扬声器62播放的音频信号作为参考信号,并使用空间传递函数和回声路径数据将麦克风61接收到的当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,以计算所述麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据所述相关性确定所述当前麦克风信号中的语音信号,以根据所确定的语音信号执行对应的处理。
[0188]
例如,麦克风61接收到的历史麦克风信号已经包含有来自音频源的原信号和参考信号的历史信息,即,如上所述,麦克风61接收到的麦克风信号是各种音频源发送的音频信号,因此处理器63可以根据空间传递函数和回声路径数据来通过例如建模以将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
[0189]
例如,在本技术实施例中,麦克风61接收到的当前麦克风信号可以为:
[0190]
[0191]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0192]
因此在本技术实施例中,可以在获取了麦克风信号和参考信号之后,根据空间传递函数和回声路径数据,就可以将当前接收到的麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,例如下面的公式:
[0193][0194]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0195]
处理器63可以进一步用于确定麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据相关性分离一个或多个音频源发出的源信号。
[0196]
由于麦克风61获得的当前麦克风信号函数中包含了各种音频源的音频信号,并且由于源信号通常是彼此独立的并且遵循非高斯分布,因此处理器63就可以对于生成的当前麦克风信号函数中的各个源信号计算之间的相关性,例如,非高斯性的相关性,并且根据该相关性能,例如取相关性最大的极值部分来作为两个信号的分离点,因此就可以将当前麦克风信号中包含的混在一起的多个音频源的源信号进行分离。从而就能够根据计算出的相关性来确定当前麦克风信号中的语音信号,因此就可以根据所确定的语音信号来执行对应的交互处理。
[0197]
例如,用户在使用音箱的过程中,可以发出“提高音量”这样的语音指令,该语音指令被混合在音箱播放的节目音频、用户所处的房间的房间噪声等各种音频中被音箱的麦克风所采集到,因此处理器63就可以从该混合音频中识别或分离出用户发出的语音信号,并且因此就可以执行与该语音信号对应的处理,即提高扬声器62播放的音量。
[0198]
因此,根据本技术实施例的音箱,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
[0199]
实施例七
[0200]
图7为本技术提供的语音交互芯片实施例的结构示意图,可用于执行如图3所示的方法步骤。如图7所示,该语音交互芯片可以包括:麦克风信号接收模块71、播放模块72和处理模块73。
[0201]
人们在通信或使用智能设备时通常需要进行人机交互,并且因此这样的通信设备或智能设备可以使用本技术实施例所提供的语音交互芯片来实现语音交互功能,因此可以通过安装有本技术实施例的语音交互芯片来采集或拾取目标说话人发出的语音并进而根据识别出的语音来生成对应的处理指令,从而通信设备或智能设备可以进行相应的操作。
[0202]
例如,在本技术实施例中,可以通过麦克风信号接收模块71来接收由例如智能设
备的麦克风采集的用户的语音信号。由于通常用户在例如房间的环境中使用智能设备,因此在目标说话人发出语音指令之后,麦克风会接收到包含有多种音频的麦克风信号,把并且这样的麦克风信号除了包含有用户发出的语音信号之外还会包含各种环境噪声以及其他音源发出的声音。因此,在本技术实施例中,可以通过语音交互芯片中的麦克风信号接收模块71来接收麦克风接收到的音频信号。
[0203]
在本技术实施例中还需要接收参考信号以便于对麦克风信号中包含的多种音频进行识别处理。例如,智能设备由于不仅需要接收用户的语音指令,更重要的是,其通常需要为用户播放用户所需要的各种音频。因此,本技术的语音交互芯片中的播放模块72可以将音频信号发送给扬声器,以播放各种音频,并且处理模块73可以使用这些发送到扬声器进行播放的音频信号作为参考信号。这样的音频数据在被扬声器播放出来之后,可能会再被麦克风作为环境声音而与目标说话人的语音指令一起被接收到并发送给麦克风信号接收模块71,从而处理模块73就可以使用该参考信号分离接收到的麦克风信号中的该环境声音。
[0204]
因此,处理模块73可以使用发送给扬声器播放的音频信号作为参考信号,并使用空间传递函数和回声路径数据将麦克风信号接收模块71接收到的当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,以计算所述麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据所述相关性确定所述当前麦克风信号中的语音信号,以根据所确定的语音信号执行对应的处理。
[0205]
例如,麦克风信号接收模块71接收到的历史麦克风信号已经包含有来自音频源的原信号和参考信号的历史信息,即,如上所述,麦克风信号接收模块71接收到的麦克风信号是各种音频源发送的音频信号,因此处理模块73可以根据空间传递函数和回声路径数据来通过例如建模以将当前麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式。
[0206]
例如,在本技术实施例中,麦克风信号接收模块71接收到的当前麦克风信号可以为:
[0207][0208]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0209]
因此在本技术实施例中,可以在获取了麦克风信号和参考信号之后,根据空间传递函数和回声路径数据,就可以将当前接收到的麦克风信号构建为历史麦克风信号以及当前的参考信号的函数形式,例如下面的公式:
[0210][0211]
其中,s=[s1,
…
,sn]
t
为源信号,r=[r1,
…
,rr]
t
为参考信号,x=[x1,
…
,xm]
t
为麦克风信号,m、n、r为麦克风数、声源数、参考数。a和b分别为根据空间传递函数对房间进行的建模以及回声路径函数。
[0212]
处理模块73可以进一步用于确定麦克风信号函数中所述一个或多个音频源发出的源信号中每个源信号之间的相关性,并根据相关性分离一个或多个音频源发出的源信号。
[0213]
由于麦克风信号接收模块71获得的当前麦克风信号函数中包含了各种音频源的音频信号,并且由于源信号通常是彼此独立的并且遵循非高斯分布,因此处理模块73就可以对于生成的当前麦克风信号函数中的各个源信号计算之间的相关性,例如,非高斯性的相关性,并且根据该相关性能,例如取相关性最大的极值部分来作为两个信号的分离点,因此就可以将当前麦克风信号中包含的混在一起的多个音频源的源信号进行分离。从而就能够根据计算出的相关性来确定当前麦克风信号中的语音信号,因此就可以根据所确定的语音信号来执行对应的交互处理。
[0214]
例如,用户在使用智能设备播放音视频的过程中,可以发出“提高音量”这样的语音指令,该语音指令被混合在该智能设备所播放的节目音频、用户所处的房间的房间噪声等各种音频中被麦克风所采集到并发送给语音交互芯片的麦克风信号接收模块71,因此处理模块73就可以从该混合音频中识别或分离出用户发出的语音信号,并且因此就可以生成与该语音信号对应的处理指令并发送给智能设备的扬声器,从而能够提高扬声器播放的音量。
[0215]
因此,根据本技术实施例的语音交互方案,能够通过获取麦克风信号和参考信号并且在历史麦克风信号中包含源信号和参考信号的历史信息,从而能够直接使用盲源分离的计算框架来对原始音频进行回声消除、去混响以及盲源分离这三种处理,消除了现有技术中需要使用不同的模块/框架来分别进行上述处理带来的优化冲突的问题,从而可以进一步提高音频处理优化的效果。
[0216]
实施例八
[0217]
以上描述了音频数据处理装置的内部功能和结构,该装置可实现为一种电子设备。图8为本技术提供的电子设备实施例的结构示意图。如图8所示,该电子设备包括存储器81和处理器82。
[0218]
存储器81,用于存储程序。除上述程序之外,存储器81还可被配置为存储其它各种数据以支持在电子设备上的操作。这些数据的示例包括用于在电子设备上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。
[0219]
存储器81可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(sram),电可擦除可编程只读存储器(eeprom),可擦除可编程只读存储器(eprom),可编程只读存储器(prom),只读存储器(rom),磁存储器,快闪存储器,磁盘或光盘。
[0220]
处理器82,不仅仅局限于中央处理器(cpu),还可能为图形处理器(gpu)、现场可编辑门阵列(fpga)、嵌入式神经网络处理器(npu)或人工智能(ai)芯片等处理芯片。处理器82,与存储器81耦合,执行存储器81所存储的程序,该程序运行时执行上述实施例二的音频数据处理方法和实施例三的语音交互方法。
[0221]
进一步,如图8所示,电子设备还可以包括:通信组件83、电源组件84、音频组件85、显示器86等其它组件。图8中仅示意性给出部分组件,并不意味着电子设备只包括图8所示组件。
[0222]
通信组件83被配置为便于电子设备和其他设备之间有线或无线方式的通信。电子设备可以接入基于通信标准的无线网络,如wifi,3g、4g或5g,或它们的组合。在一个示例性实施例中,通信组件83经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信组件83还包括近场通信(nfc)模块,以促进短程通信。例如,在nfc模块可基于射频识别(rfid)技术,红外数据协会(irda)技术,超宽带(uwb)技术,蓝牙(bt)技术和其他技术来实现。
[0223]
电源组件84,为电子设备的各种组件提供电力。电源组件84可以包括电源管理系统,一个或多个电源,及其他与为电子设备生成、管理和分配电力相关联的组件。
[0224]
音频组件85被配置为输出和/或输入音频信号。例如,音频组件85包括一个麦克风(mic),当电子设备处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器81或经由通信组件83发送。在一些实施例中,音频组件85还包括一个扬声器,用于输出音频信号。
[0225]
显示器86包括屏幕,其屏幕可以包括液晶显示器(lcd)和触摸面板(tp)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。
[0226]
此外,本技术实施例还提供了一种计算机程序产品,包括计算机程序或指令,当所述计算机程序或指令被处理器执行时,致使所述处理器实现前述的音频数据处理方法或语音交互方法的程序指令。在本技术实施例中,计算机程序产品可以根据实际需要以各种形式来实施,例如,可以制作为用于智能设备的应用程序(app)或小程序等形式。
[0227]
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0228]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。