一种基于改进deeplabv3 网络的机械零部件图像分割算法
技术领域
1.本发明涉及深度学习和计算机视觉技术领域,具体的说是一种基于改进deeplabv3 网络的机械零部件图像分割算法。
背景技术:
2.零件的识别分割作为工业机器人智能抓取视觉任务的重要组成部分,其分割结果将对抓取任务的顺利进行产生极大的影响。在对零部件识别分割的研究中,先是使用hog算法、canny边缘检测和sobel算子等传统算法进行特征提取,但这些传统方法的零件特征识别精度主要取决于人工选择特征提取法的质量,且在多目标机械零部件图像中识别效果不佳;随着卷积神经网络算法被逐步提出,提取零部件图像区域的方法常为目标检测或语义分割,目标检测方法中常用r-cnn,ss和yolo系列等,但由于实际场景中零件种类繁多,目标检测方法难以提取目标轮廓和特定区域,但语义分割方法可以,常用方法为segnet,u-net和deeplab系列等,但在分割的过程中,由于部分零部件图像与背景相似,局部遮挡等问题,增加了分割难度。
技术实现要素:
3.针对传统deeplabv3 分割零部件图像时存在零件边缘分割模糊,不完全分割等问题,造成最终图像分割准确率低的问题,提出了一种基于改进deeplabv3 网络的机械零部件图像分割算法,减少零部件图像分割结果中边界信息模糊,提高零部件分割算法的准确度,以适应目前工业化的零部件图像分割。实验结果显示本文的算法模型能够取得不错的分割效果,对零部件图像分割具有一定的参考意义。
4.本发明为实现上述目的所采用的技术方案是:一种基于改进deeplabv3 网络的机械零部件图像分割算法,包括以下步骤:
5.步骤一:采集原始零部件图像;对零部件原始图像中出现的1个或多个零部件边界进行分割标注得到人工分割图像,将原始图像与人工分割图像共同建立零部件图像数据集;
6.步骤二:对零部件图像和人工分割图像分别进行数据增强处理扩充样本图像,再按比例随机划分为训练集、验证集和测试集;
7.步骤三:搭建改进deeplabv3 的语义分割模型,包括编码层和解码层;编码层包括mobilenetv2和通道注意力模块、自适应空间特征融合模块asff、空间金字塔池模块aspp、1
×
1卷积模块,用于将特征图尺寸缩小,提取信息进行零部件边界分割;解码层包括1
×
1卷积模块、上采样操作、非对称卷积模块,用于逐步恢复空间维度,输出同尺寸的边界分割结果图;
8.步骤四:设置网络训练参数,将训练集图片输入改进deeplabv3 的语义分割网络进行训练,利用验证集进行验证,得到优化的网络模型;
9.步骤五:利用优化的deeplabv3 语义分割模型对测试集中的零部件图像进行识别
预测,得到机械零部件分割结果图。
10.所述数据增强包括旋转、平移和添加噪声操作。
11.所述旋转包括水平翻转、垂直翻转、
±
60
°
、
±
90
°
、
±
210
°
、
±
240
°
的旋转;所述平移包括右移100像素、下移100像素;以及添加0.001,0.002,0.003的椒盐噪声;最后将增强后的数据集样本按8:1:1的比例随机划分为训练集、验证集和测试集。
12.所述mobilenetv2和通道注意力模块,将输入的样本图像进行处理,输出原图1/4大小的底层特征图、三个不同大小的特征层级图以及原图1/16大小的高层语义特征图;其中三个不同大小的特征层级图输入到asff模块后输出融合特征图至解码层;高层语义特征输入到aspp结构中,并行经过1
×
1卷积,空洞率为6,12,18的空洞卷积继续提取特征以及全局平均池化后对特征图进行融合再输出至1
×
1卷积模块,得到的高层语义特征图进入解码层;
13.所述编码层输出的底层特征图经过1
×
1卷积后与asff融合特征图进行相加操作;然后与编码层获得的高层语义特征图进行逐层2倍双线性插值上采样后的特征图进行融合操作;之后对融合后的特征图采用非对称卷积,再经过逐层2倍上采样操作后输出最终的分割预测结果图。
14.所述asff模块进行处理的步骤包括:
15.以三个不同大小的特征层级图为输入,分别记为x1,x2,x3,通过3
×
3卷积进行下采样操作将特征层级x2和x3调整与x1的大小相同;
16.对尺寸调整后的特征层级图x1,x2,x3按照融合特征公式来自适应学习各空间权重信息,得到融合特征图y
l
;所述l级融合特征公式如下:
[0017][0018]
其中,表示输出特征图y
l
的第(i,j)特征向量,表示不同的三个层级到l级的空间重要性权重,且该权重信息共享于所有通道,表示为m级调整到l级的特征映射上位置(i,j)处的特征向量。
[0019]
所述逐层2倍双线性插值上采样替换原4倍上采样用于像素的连续性,减少重要像素信息的丢失。
[0020]
所述非对称卷积模块包含3
×
3,1
×
3,3
×
1卷积,对于第j个卷积核,令f
(j)
,和分别表示3
×
3,1
×
3和3
×
1卷积核的输出结果,最终融合的结果可表示为:
[0021][0022]
式中,σj,分别对应3
×
3,1
×
3,3
×
1卷积的标准偏差值,γj,和βj,分别是3
×
3,1
×
3,3
×
1卷积的缩放系数和偏移量,bj表示偏置,公式为:
[0023]
[0024]
式中,μj,是3
×
3,1
×
3,3
×
1卷积的批量归一化的通道平均值,故即可得到以下非对称卷积融合公式:
[0025][0026]
式中,o
:,:,j
,分别表示原始含3
×
3,1
×
3和3
×
1三个分支的输出,*表示二维卷积算子,m
:,:,k
是m第k个通道上尺寸为u
×
v的特征图,表示融合后作用于第k个通道上的卷积核j,c表示通道数。
[0027]
所述网络训练参数包括:训练次数epoch设为100,初始学习率设为0.007,学习策略采用“poly”,batchsize设置为2,初始动量为0.9,使用交叉熵损失函数,同时选择随机梯度下降优化算法进行训练。
[0028]
本发明具有以下有益效果及优点:
[0029]
本文方法以mobilenetv2替换原先的骨干网络,满足了工业化场景下的实时性需求;对于骨干网络中增加的通道注意力机制,能够增强网络对目标的学习能力;对于增加的自适应空间特征融合模块,充分利用多尺度特征的特征信息,获取更多的目标信息;对于逐层上采样操作能够保证像素连续,减少重要像素信息的丢失;最后使用非对称卷积来增强3
×
3卷积的核骨架部分,提高卷积核的处理能力以及模型精度,最终本文方法能以较高的准确度分割出零部件图像。
附图说明
[0030]
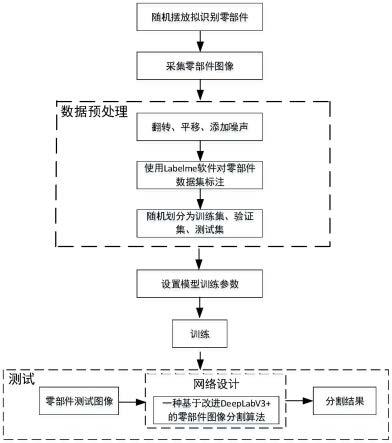
图1为本发明方法的整体流程示意图;
[0031]
图2为本发明方法中使用的通道注意力模块示意图;
[0032]
图3为本发明方法一种基于改进deeplabv3 网络的结构示意图;
[0033]
图4为本发明实施例中方法中一种基于改进deeplabv3 网络的机械零部件图像分割算法识别遮挡零件的效果示意图。
具体实施方式
[0034]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方法做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但本发明能够以很多不同于在此描述的其他方式来实施,本领域技术人员可以在不违背发明内涵的情况下做类似改进,因此本发明不受下面公开的具体实施的限制。
[0035]
除非另有定义,本文所使用的所有技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
[0036]
图1是本发明流程图。
[0037]
步骤一:数据准备
[0038]
对零部件进行随机摆放,然后使用工业相机得到原始零部件图像;使用labelme软
件对零部件原始图像中的零部件边界及部分零件中心圆轮廓进行分类标注(即按照所需要识别的零部件按照种类进行分别标注),得到人工分割图像,原始图像同人工分割图像共同建立零部件图像数据集。
[0039]
步骤二:数据增强处理
[0040]
对零部件图像和人工分割图像分别进行旋转、平移和添加噪声等数据增强处理后得到样本图像,将所有样本图像按比例随机划分为训练集、验证集和测试集;数据增强是指通过一系列随机变换对原始数据集进行扩充,从而提高数据量的方法,本系统采用一些随机的图像处理方法对原始数据集进行扩充,包括水平翻转、垂直翻转、
±
60
°
、
±
90
°
、
±
210
°
、
±
240
°
的旋转、右移100像素、下移100像素以及添加0.001,0.002,0.003的椒盐噪声,提高网络的泛化能力;最后将增强后的数据集样本按8:1:1的比例随机划分为训练集、验证集和测试集。
[0041]
步骤三:搭建分割模型
[0042]
deeplabv3 总体结构可分为编码层和解码层两部分,编码层主要作用是将特征图尺寸缩小,提取更多的信息进行准确分割,解码层则是逐步恢复空间维度,在尽可能的前提下完成同尺寸的输出。在编码层部分,以mobilenetv2替换原先的xception作为主干网络并添加通道注意力模块,增强对目标的学习能力,通道注意力结构如图2所示。输入的零部件图像首先经此主干网络后,获得原图1/4大小的底层特征、三个不同大小的特征层级图以及原图1/16大小的高层语义特征三部分,其中三个不同大小的特征层级图输入到自适应空间特征融合(adaptively spatial feature fusion,asff)模块,高层语义特征部分输入到空间金字塔池(atrous spatial pyramid pooling,aspp),在aspp结构中并行经过1
×
1卷积,空洞率为6,12,18的空洞卷积继续提取特征以及全局平均池化后对特征图进行融合,避免了信息的丢失。接着使用1
×
1卷积来减少通道数,得到的特征图进入解码层;在解码层部分,骨干网络产生的底层特征图经过1
×
1卷积后与asff融合的特征图进行相加操作,增加通道数所携带的特征信息,然后与编码层获得的高层语义特征图进行逐层2倍双线性插值上采样后的特征图进行融合操作,之后对融合后的特征图采用非对称卷积,再经过逐层2倍上采样操作,最后获得网络的预测结果,基于deeplabv3 改进的网络结构如图3所示。
[0043]
在本实施例中,以xception替换为mobilenetv2,是因为mobilenetv2网络能够解决在模型训练过程中出现的卷积神经网络庞大,硬件训练不足等问题,其核心是深度可分离卷积,包含纵向卷积和点卷积两部分,可在同等卷积核大小时,极大的减少计算量,保证了该算法在工业化场景下的实时性。
[0044]
同时在主干网络中倒置残差块的跳跃连接前引入有效通道注意力模块,该模块对τ=rw×h×c的特征图,当只考虑通道与一维卷积核k之间的相互作用时,以共享权重ωi进行通道全局平均池化后得到1
×1×
c的特征图,由于一维卷积的大小k与通道维数c存在的映射关系,故可通过c确定k的大小以及跨通道信息交互范围,对映射后的1
×1×
c特征图与初始输入特征图相乘即可得到输出,这样通过自适应确定卷积核大小k来捕获本地跨通道交互,减少模型复杂度,提高效率。
[0045]
asff模块是为了充分利用底层信息,该操作是通过增加骨干网络产生1/2,1/4,1/8大小的特征图作为输入特征层级,分别记为x1,x2,x3,输入通道数分别为32,24,16,然后通过3
×
3卷积进行下采样操作将特征层级x2和x3调整与x1的大小相同。最后将x1作为结果
输出,因为该层级相比较其他层级拥有更丰富的语义信息和空间信息;然后通过自适应融合操作来自适应学习各空间权重信息后进行融合,令表示为m级调整到l级的特征映射上位置(i,j)处的特征向量,则在相应的l级融合特征公式为:
[0046][0047]
其中,表示输出特征图y
l
的第(i,j)特征向量。表示不同的三个层级到l级的空间重要性权重,且该权重信息共享于所有通道,提高效率;
[0048]
逐层2倍双线性插值上采样替换原4倍上采样,保证了像素的连续性,减少了重要像素信息的丢失。
[0049]
非对称卷积融合模块,使用非对称卷积是为了增强3
×
3卷积的核骨架部分,增强卷积核的处理能力,提高模型的准确率,该卷积包含3
×
3,1
×
3,3
×
1卷积,对于第j个卷积核,令f
(j)
,和分别表示3
×
3,1
×
3和3
×
1卷积核的输出结果,最终卷积核融合的结果表示为:
[0050][0051]
式中,σj,分别对应3
×
3,1
×
3,3
×
1卷积的标准偏差值。γj,和βj,分别是3
×
3,1
×
3,3
×
1卷积的缩放系数和偏移量,bj表示偏置,公式为:
[0052][0053]
式中,μj,是3
×
3,1
×
3,3
×
1卷积的批量归一化的通道平均值,即可得到以下非对称卷积融合公式:
[0054][0055]
式中,o
:,:,j
,分别表示原始含3
×
3,1
×
3和3
×
1三个分支的输出,加和后作为该非对称卷积融合模块的输出,*表示二维卷积算子,m
:,:,k
是m第k个通道上尺寸为u
×
v的特征图,表示融合后作用于第k个通道上的卷积核j,c表示通道数。
[0056]
步骤四:训练语义分割模型
[0057]
设置网络训练参数,然后将步骤二中划分后的训练集图片输入到步骤三构建的改进deeplabv3 的语义分割网络进行训练。
[0058]
本实施例中,网络训练参数是训练网络的epoch设为100,初始学习率设为0.007,学习策略采用“poly”,batchsize设置为2,初始动量为0.9,使用交叉熵损失函数,同时选择随机梯度下降(stochastic gradient descent,sgd)优化算法。
[0059]
步骤五:测试
[0060]
利用所述的deeplabv3 语义分割模型对测试集中的零部件图像进行识别分割,得到网络的分割结果,如图4c)所示。其中,图4a)所示为原始图像,图4b)所示为人工标注图像,按照本方法识别的零部件边缘与人工标注图像吻合度高,表明本方法分割效果不错。
[0061]
本实施例中,采用平均交并比miou指标来评判图像分割性能,该值越高代表网络预测越准确,
[0062][0063]
式中,n表示总的类别数,即人为标注的该像素属于哪个零部件类;p
ij
表示本应该是i类但被预测为j类的像素数量;p
ii
表示预测正确的像素数量。p
ij
和p
ji
分别表示假正和假负,使用测试集进行实验结果验证,实验结果表明零部件图像的平均交并比达到了93.77%。
[0064]
以上所述,仅是本发明的较佳实施例,并非对本发明作任何限制,凡是根据本发明技术实质对以上实施例所作的任何简单修改、变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
