1.本发明涉及口语文本生成方式,尤其涉及一种语音识别的口语文本生成方法。
背景技术:
2.随着计算机技术和网络技术的发展和广泛应用,存在着很多需要进行语音识别的情况。一般来说,语言分为口语和书面语,当前情况下的语音识别系统多对书面语进行阐述或者而且,伴随着使用人员的范围增加,逐字识别的方法显然不适用于目前的网络环境,然而目前存在识别效率低。一般来说,口语比书面语更加依赖语言环境以及更难转换为机器语言。
3.现有的文本转换方法在将书面语转换为口语时,一般是直接在书面文本上添加了口语中常见的副语言信息,转换后的口语化文本并不符合语言的表达习惯,有时在书面文本中出现了口语化的副语言信息反而会让用户感到生硬,拗口,表达不流畅等感觉,影响用户体验。
4.现有的文本转换方式对文本并没有进行系统化的学习,只是机械性地增加口语化的阐述方式。
5.对于真正口语的情况来说显得不够真实。并且进行语义转换的同时也存在一定障碍。
6.例如,一种在中国专利文献上公开的“将书面文本转换为口语文本的方法及系统”,其公告号“cn201710987858.5”,包括一种将书面文本转换为口语文本的方法及系统,通过副词等方式对书面语的语言习惯进行训练然后转换为口语文本,缺少对整体性以及语言习惯的考究,不够自然准确。
技术实现要素:
7.本发明主要解决现有的语音识别的口语文本生成方式中存在的精确度不够以及对于现有的口语文本识别能力的欠缺的补偿;提供一种具有语音语义学习能力的基于语音识别的口语文本生成方式,降低了语音识别中对于口语文本的错误识别,提高了口语文本生成的准确度以及精确度。
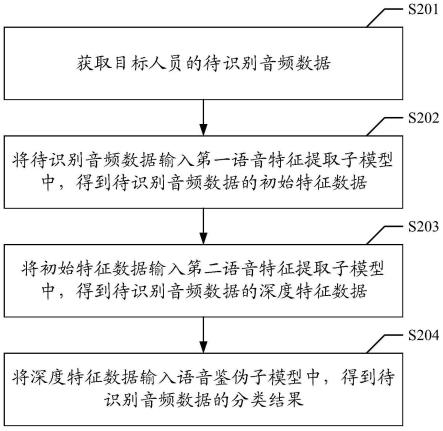
8.本发明的上述技术方案主要是通过下述技术方案得以解决的:语音识别的口语文本生成方法,包括以下步骤:步骤s1:进行端点检测获得声音信号并对声音信号进行初步去噪;步骤s2:通过语音识别引擎将去噪后的声音信号转换为机器语言;步骤s3:通过语音识别模型与分离模型对机器语言联合训练;步骤s4:进行后端识别处理;步骤s5:生成口语文本。
9.先进行去噪以及端点检测得到一条完整的语音信息,通过声音信号与机械语言的转换得到一串完整的包含声音信号的机械语言。再通过语音识别模型与分离模型的综合训
练提高机械语言转换文本的准确性以及效率。得到一段较为完整的口语文本。
10.最后通过后端识别处理得到完整的口语文本,实现语音识别的口语文本生成。
11.口语化和篇章级的语言模型处理技术,即通过借鉴语音识别处理噪声问题采用加噪训练的思想,即在书面语的基础上自动引入回读、倒装、语气词等口语“噪声”现象,从而可自动生成海量口语语料,解决口语和书面语之间的不匹配问题。收集部分口语文本和书面文本语料;使用基encoder-decoder(编码-解码)的神经网络框架建模书面语文本与口语文本之间的对应关系,从而实现了口语文本的自动生成。另外,根据语音识别的解码结果自动进行关键信息抽取,实时进行语料搜索和后处理,用解码结果和搜索到的语料形成特定语音相关的语言模型,从而进一步提高语音转录的准确率;解码器的动作是把音频的特征值抽取后,通过解码器进行声学模型的技术和语言模型的计算,给出最终的识别文字,随后解码器是对通用的标准中文构建的,识别结果中有些后处理的构建,比如语义、关键词优化等可以影响解码器的工作,自适应的过程是通过语义,关键词优化等对解码器进行二次优化,再输出最终的结果。
12.本发明通过大量的语言样本,进行训练,得到口语化的消息以及变形,涵盖了不同的方言以及不同类型的背景噪声的海量语音数据,通过先进的区分性训练进行语音建模,使语音识别器在复杂应用环境下均具有良好的效果表现。包括中文标点智能预测,文件格式智能转换,前端语音处理,端点检测。通过层层步骤对于转换完成的机械语言进行检测纠正。提高口语文本生成的速度以及准确性。中文标点智能预测能够使用超大规模的语言模型,对识别结果语句智能预测其对话语境,提供智能断句和标点符号的预测。文件格式智能转化,对结果中出现的数字、日期、时间等内容格式格式化为规整的文本。前端语音处理,即用信号处理的方法对说话人语音进行检测,降噪等预处理,以便得到最适合识别引擎处理的语音。其主要包括端点检测,噪音消除等。
13.作为优选,所述的步骤s1包括以下步骤:步骤s11:对输入的音频流进行分析,确定语音的起始和终止的位置进行语音识别。
14.步骤s12:识别截取到的音频并进行初步噪音去除。
15.端点检测是对输入的音频流进行分析,确定用户说话的起始和终止的处理过程。通过对声音强度进行检测,当声强到达一定阈值则启动。一旦检测到用户开始说话,语音开始流向识别引擎,直到检测到用户说话结束。这种方式使识别引擎在用户在说话的同时即开始进行识别处理。能够获得一串完整的语音信息,这种方式能有效切断语音信息中的无效成分。提高输入输出的效率。在实际应用中,背景噪声对于语音识别应用是一个现实的挑战,即便说话人处于安静的办公室环境,在电话语音通话过程中也难以避免会有一定的噪声,语音识别通过学习训练降噪,提升识别时的效果。
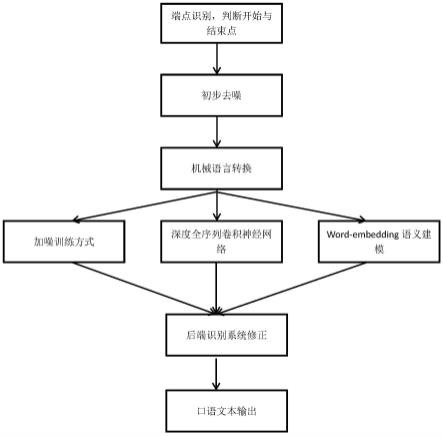
16.作为优选,所述步骤s3包括以下步骤:步骤s31:深度全序列卷积神经网络,使用大量的卷积层对整句语音进行建模。
17.步骤s32:进行word-embedding语义建模,筛选语义不顺语句。
18.步骤s33:采用加噪训练方式引入回读等口语噪音形式,构建书面语与口语文本对应关系从而加强口语文本的生成。深度全序列卷积神经网络(dfcnn),使用大量的卷积层直接对整句语音信号进行建模。在输入端dfcnn直接将语谱图作为输入,相比其他以传统语音
特征作为输入的语音识别框架相比具有天然的优势;在模型结构上,借鉴了图像识别的网络配置,每个卷积层使用小卷积核,并在多个卷积层之后再加上池化层,通过累积非常多的卷积池化层对,从而可以看到非常长的历史和未来信息,通过基于word-embedding(词嵌入) 的语义模型建模和语言模型区分性训练研究,进一步和语音识别后处理模块结合,以筛选掉识别结果中语义不通顺的语句,提升识别结果可读性。
19.作为优选,在语音识别模型与分离模型的联合训练中采用了在语音识别神经网络模型与唇语识别神经网络模型的过程中进行多模态语音识别与分离的联合训练方法。通过将音频特征输入同等频率语音帧特征向量序列,在特征提取模块的时间维度下采样四倍得到多维的语音向量,再与图像向量进行融合得到一个小的融合神经网络,通过分析完成联合训练效果。该方法能够有效分离图形以及声音信号,得到更加纯粹的声音信号,具有更加高效性。
20.作为优选,所述步骤s33中的构建书面语与口语文本对应关系为:通过在书面语上手动引入回读、倒装、语气词等口语噪声现象,生成海量的口语预料。口语预料不止用于书面语的进一步扩充与内容扩散,更加进一步将书面语与口语进行了一一的整合判断。
21.作为优选,所述步骤s4包括以下步骤:步骤s41:汇入词汇识别系统,词汇识别系统设置有不同场景下的词汇数据以及设置有声纹检测模块,进行声纹特征消除。
22.步骤s42:置信度输出,通过对返回结果进行识别来判断识别结果的准确性。
23.步骤s43:多识别技术,通过上述的置信度输出判断的结果。通过置信度结果排行输出,给以二度选择的权利。二度选择中得到的合适的结果加入口语文本生成选择。
24.步骤s44:热词识别,通过热词感应系统进行单次的检验或者校准。后端识别处理通过对说话人语音进行识别,得到最合适的结果。
25.作为优选,所述步骤s5包括以下步骤:步骤s51:进行语义解析系统的语音解析,语义解析系统包括文本解析模块,消除重复文本信息并进行分类;语义解析系统包括语义特征提取模块,根据语言中的词句重要性进行排序。
26.步骤s52:根据步骤s51的分类结果和重要性排序结果生成口语文本。
27.本发明的有益效果是:(1)相较于普通的口语文本生成方法具有高准确性。(2)更接近于人的口语叙述方式,可辨别性高。(3)具有多种口语文本的生成,可供使用者选择,选择度高。(4)进行自我学习,语义识别随使用时间稳定性和准确度均有提高。
附图说明
28.图1是实施例一的基于语音识别的口语文本生成方法的流程图。
具体实施方式
29.下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
30.实施例一:一种语音识别的口语文本生成方法,如图1所示,包括以下步骤:(1-1)进行端点识别,将声音信号的开头和结尾进行标记,获得完整的短的声音信号减少工作量。
31.(1-2)进行初步去噪处理,初步解决背景音中的不同杂音,初步简化整体工作。
32.(2-1)通过机器将声音信号转换为机械语言信号。
33.(3-1)深度全序列卷积神经网络,使用大量的卷积层对整句语音进行建模。通过输入端将与语谱图输入。并在多个卷积层后加入卷积池化层。
34.(3-2)采用word-embedding语义模型建模对于语义模型建模和语言模型进行区分性训练研究,进一步和语音识别后处理模块结合,筛选掉语义不顺部分,提升识别结果的可读性。
35.(3-3)采用加噪的方式来训练噪声问题。通过在书面语的基础上主动增加回读、倒装、语气词等模拟噪声的情况,主动生成海量的模拟口语语料,解决口语与书面语之间的不匹配的问题等。
36.(3-4)在语音识别模型与分离模型的联合训练中采用了在语音识别神经网络模型与唇语识别神经网络模型的过程中进行多模态语音识别与分离的联合训练方法。通过将音频特征输入同等频率语音帧特征向量序列,在特征提取模块的时间维度下采样四倍得到多维的语音向量,再与图像向量进行融合得到一个小的融合神经网络,再经训练解决语音信号与图像信号糅杂的问题。
37.(4-1)汇入词汇识别系统,词汇识别系统设置有不同场景下的词汇数据已经设置有声纹检测模块用以进行声纹特征消除,防止个人特征影响结果的输出。
38.(4-2)置信度输出,对于输出结果的准确性进行判断,并反馈于下一次的使用。有利于下一次的输出口语文本的准确度的研究。
39.(4-3)多识别技术,通过(4-2)的置信度输出,进行多个结果采集,并按照置信度结果排行输出,给以二度选择权利,实现手动选择口语文本的生成。
40.(4-4)进行语义的热词识别,通过热词感应系统进行单次的语句检验或者校准。
41.(5-1)进行语义解析系统的语音解析,通过对重复的文本进行无意义的消除,以及对语义特征进行提取,对口语文本进行分类和重要性排序。在文本中按照重要性提取出关键词,进行排序分类。
42.(5-2)根据步骤(5-1)的分类结果和重要性排序生成口语文本,并且返回置信度输出得到具体结果供用户选择。
43.以上所述的实施例只是本发明的一种较佳方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其他的变体以及改型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。