一种基于国产cpu和操作系统环境的语音识别登陆方法
技术领域
1.本发明公开一种方法,涉及语音登录技术领域,具体地说是一种基于国产cpu和操作系统环境的语音识别登陆方法。
背景技术:
2.随着国内信息技术和社会经济的发展,国产化技术也在快速发展,在国产cpu和操作系统环境中,提高了对各类电脑和应用登陆认证的安全性要求。长时间使用同一套单一的用户账号和密码登录方式,安全性极低,存在泄露数据的风险,但如果密码设计复杂且频繁变更,使用起来就比较麻烦,也容易忘记密码,非常不方便。
3.随着指纹识别、语音识别、人脸识别等安全认证技术的出现和快速发展,在国产环境下,还没有集成语音识别在内的安全认证登陆方式。
技术实现要素:
4.本发明针对现有技术的问题,提供一种基于国产cpu和操作系统环境的语音识别登陆方法,可以兼容基于多种国产cpu的麒麟、uos、深度、普华等操作系统,具有良好的通用性、灵活性和可移植性。
5.本发明提出的具体方案是:
6.一种基于国产cpu和操作系统环境的语音识别登陆方法,通过外设语音识别进行操作系统端的安全登陆和浏览器的安全登陆,
7.所述操作系统端的安全登陆:获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则进行安全认证登录,进入对应的操作系统;
8.所述浏览器的安全登陆:利用语音识别浏览器插件获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则通过单点登录进入对应的web应用系统。
9.进一步,所述的方法中分别针对操作系统端的安全登陆和浏览器的安全登陆,所述根据语音数据提取语音特征之前,包括:
10.对所述语音数据进行端点检测、预加重、分帧及加窗的预处理。
11.进一步,所述的方法中分别针对操作系统端的安全登陆和浏览器的安全登陆,所述根据语音数据提取语音特征,包括:
12.提取所述语音数据的语音特征参数,所述语音特征参数包括梅尔频率倒谱系数。
13.进一步,所述的方法中分别针对操作系统端的安全登陆和浏览器的安全登陆,所述根据语音特征构建语音识别模型,包括:
14.根据所述语音特征训练获得语音识别的高斯混合隐马尔可夫模型。
15.进一步,所述的方法中分别针对操作系统端的安全登陆和浏览器的安全登陆,所述利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,包括:
16.通过动态时间规整算法获得待识别的语音特征与所述语音特征之间的相似性距离度量,选取距离度量的门限值,比对所述相似性距离度量与门限值,若所述相似性距离度量不大于门限值,则校验通过,否则校验不通过。
17.本发明还提供一种基于国产cpu和操作系统环境的语音识别登陆装置,为外设语音识别装置,针对操作系统端的安全登陆,包括操作系统端模型构建模块、操作系统端校验模块和操作系统端登录模块,针对浏览器的安全登陆,包括浏览器端模型构建模块、浏览器端校验模块和浏览器端登录模块,
18.针对操作系统端的安全登陆,操作系统端模型构建模块获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,操作系统端校验模块利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则操作系统端登录模块进行安全认证登录,进入对应的操作系统;
19.针对浏览器的安全登陆,浏览器端模型构建模块利用语音识别浏览器插件获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,浏览器端校验模块利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则浏览器端登录模块通过单点登录进入对应的web应用系统。
20.进一步,所述的装置中针对操作系统端的安全登陆,所述操作系统端模型构建模块根据语音数据提取语音特征之前,包括:
21.对所述语音数据进行端点检测、预加重、分帧及加窗的预处理;
22.针对浏览器的安全登陆,所述浏览器端模型构建模块根据语音数据提取语音特征之前,包括:
23.对所述语音数据进行端点检测、预加重、分帧及加窗的预处理。
24.进一步,所述的装置中针对操作系统端的安全登陆,所述操作系统端模型构建模块根据语音数据提取语音特征,包括:
25.提取所述语音数据的语音特征参数,所述语音特征参数包括梅尔频率倒谱系数;
26.针对浏览器的安全登陆,所述浏览器端模型构建模块根据语音数据提取语音特征,包括:
27.提取所述语音数据的语音特征参数,所述语音特征参数包括梅尔频率倒谱系数。
28.进一步,所述的装置中针对操作系统端的安全登陆,所述操作系统端模型构建模块所述根据语音特征构建语音识别模型,包括:
29.根据所述语音特征训练获得语音识别的高斯混合隐马尔可夫模型;
30.针对浏览器的安全登陆,所述浏览器端模型构建模块根据语音特征构建语音识别模型,包括:
31.根据所述语音特征训练获得语音识别的高斯混合隐马尔可夫模型。
32.进一步,所述的装置中针对操作系统端的安全登陆,所述操作系统端校验模块利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结
果校验待识别的语音,包括:
33.通过动态时间规整算法获得待识别的语音特征与所述语音特征之间的相似性距离度量,选取距离度量的门限值,比对所述相似性距离度量与门限值,若所述相似性距离度量不大于门限值,则校验通过,否则校验不通过;
34.针对浏览器的安全登陆,所述浏览器端校验模块利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,包括:
35.通过动态时间规整算法获得待识别的语音特征与所述语音特征之间的相似性距离度量,选取距离度量的门限值,比对所述相似性距离度量与门限值,若所述相似性距离度量不大于门限值,则校验通过,否则校验不通过。
36.本发明的有益之处是:
37.本发明提供一种基于国产cpu和操作系统环境的语音识别登陆方法,为国产环境各种电脑和应用的登录提供安全认证,保证了用户电脑数据和各种应用数据的安全性,充分考虑了全国产环境下,不同操作系统、浏览器的兼容性,可以实现将语音数据作为唯一的标识数据,通过语音识别外设直接进行安全认证登录,方便快捷。
附图说明
38.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
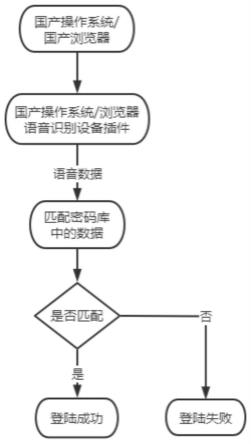
39.图1是本发明方法语音数据验证登陆流程示意图。
40.图2是本发明方法语音存储流程示意图。
41.图3是本发明方法语音识别原理示意图。
具体实施方式
42.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
43.本发明一种基于国产cpu和操作系统环境的语音识别登陆方法,通过外设语音识别进行操作系统端的安全登陆和浏览器的安全登陆,
44.所述操作系统端的安全登陆:获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则进行安全认证登录,进入对应的操作系统;
45.所述浏览器的安全登陆:利用语音识别浏览器插件获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则通过单点登录进入对应的web应用系统。
46.本发明方法利用国产化语音识别设备作为外设,进行用户登录的方法。本方法将用户语音数据作为用户登录的唯一标识,自动匹配已经授权的登录语音信息,基本实现登
录的高效性和安全性。
47.本发明方法可以兼容基于多种国产cpu的麒麟、uos、深度、普华等操作系统,具有良好的通用性、灵活性和可移植性。
48.具体应用中,在本发明方法的一些实施例中,语音识别登陆分为操作系统端的安全登陆和浏览器安全登陆两种模式,语音识别首先对输入的原始语音信号进行预处理,包括端点检测、预加重、分帧、加窗等处理过程,实现语音特征的提取功能,在训练过程中,对所提取出来的说话人语音特征进行学习训练,建立模型,或者对系统中已有模型进行适应性修改。在识别过程中,要根据模型对输入语音的特征参数进行模式匹配计算,从而实现识别判断,得出识别结果。
49.针对操作系统端的安全登陆模式,调用语音识别外设接口获取语音数据。
50.其中语音录入时利用录音设备录取目标人物的某一段语音数据,进行语音数据预处理,首先通过端点检测获取有用语音数据的始点和终点,再对录入的语音信号进行预加重,将语音通过滤波器:h(z)=1-az-1
,a为预加重系数,0.9《a《1.0,目的是为了增加语音的高频分辨率,为进行快速傅里叶变换输入平稳信号,进行语音数据分帧,将一段语音数据截取成若干片段的短语音,使帧与帧过渡平滑,保持连续。取出语音信号后,先进行加窗操作再进行快速傅里叶变换,而加窗是与窗函数相乘,使信号在中间向两边逐渐变为0,常用的有汉明窗,通过frames*=np.hamming(frame_length)添加,改善因截断效应造成的频谱泄露。
51.预处理后的语音数据进行特征提取,其中提取的语音特征参数包括梅尔频率倒谱系数,梅尔频率倒谱系数是基于人的听觉特点利用人听觉的临界带效应,在mel标度频率域提取出来的倒谱特征参数。提取过程为:语音数据乘上汉明窗后,每帧还必须再通过快速傅里叶变换得到在频谱上的分布,对分帧加窗后的每帧信号进行快速傅里叶变换得到各帧的频谱,并对语音信号的频谱取模平方得到语音信号的功率谱,包含快速傅里叶变换的库有librosa、torch、scipy,将一般的频率标度转化为梅尔频率标度,映射关系是mel(f)=2959*lg(1 f/700),再配置三角带通滤波器并计算三角形滤波器对信号幅度谱滤波后的输出,最后对滤波器输出作对数操作,再进一步做离散余弦变换,得到梅尔频率倒谱系数。
52.可以利用stilm语言模型工具箱构建模型,开始训练前,先对梅尔频率倒谱系数特征进行倒谱均值、方差规整,首先训练单音素模型,对模型做对齐后训练三音素模型,再经过线性判别分析将拼接后的输入特征降维到40维,然后采用基于特征的最大似然线性回归进行特征归一化变换,最后采用基于高斯混合模型的说话人自适应训练得到tri3模型,采用的高斯混合元数为4000,经过训练后得到语音识别的高斯混合隐马尔可夫模型。
53.进行语音数据校验时,通过动态时间规整算法获得待识别的语音特征与所述语音特征之间的相似性距离度量,选取距离度量的门限值,比对所述相似性距离度量与门限值,若所述相似性距离度量不大于门限值,则校验通过,否则校验不通过,其中采用动态时间规整算法进行匹配计算的具体实现过程中,首先申请两个n*m的矩阵d和d,分别为累积距离和帧匹配距离矩阵,n和m分别为待校验样本和训练样本的帧数;然后计算两个样本的帧匹配距离矩阵d,为每个格点(i,j)都计算其三个可能的前续格点的累积距离d1、d2和d3,最后利用最小值函数找到三个前续格点的累积距离的最小值作为累积距离,与当前帧的匹配距离d(i,j)相加,作为当前格点的累积距离,计算过程一直达到格点(n,m),并将d(n,m)输出,作
为匹配的距离度量,d(n,m)即为最佳路径所对应的匹配距离度量。对于所录语音中说话人进行确认时,将d(n,m)与预先设定好的门限值s相比较,如果d(n,m)≤s,则可判定该说话人得到确认,校验通过,否则被拒绝,校验不通过。而对于说话人辨认,则计算待测样本与所有训练样本之间的匹配距离{d1,d2,
…dk
},找出其中最小值所对应的说话人样本,即为所求说话人。
54.语音数据校验通过后,调用原操作系统登录接口,进行安全认证登录,进入对应的操作系统。
55.针对浏览器安全登录模式,调用语音识别外设进行单点登录,首先语音识别外设利用对应的语音识别浏览器插件获取语音数据,利用浏览器插件通过语音识别外设接口获取用户语音数据,再调用各web应用系统密码存储接口,存储对应的语音数据,
56.语音数据的预处理及构建语音识别模型的流程和操作系统端的语音数据处理雷同,在此不再赘述。
57.进行语音数据校验时,web应用先调用语音识别对应的浏览器插件,获取语音数据,当获取到待测语音数据后,此处语音数据校验流程和操作系统端的语音数据校验流程雷同,在此不再赘述。
58.用户语音数据校验通过后,获取web应用系统中对应的用户数据,然后调用web应用系统安全认证接口,通过单点登录进入对应的web应用系统。
59.利用本发明方法当用户通过语音识别设备进行安全认证登录时,需要再次使用语音识别外设,输入语音数据,然后将语音数据和操作系统或web应用系统中的语音数据进行校验,判断是否有权限登录电脑或者web应用系统。利用本发明方法调用语音识别外设,并且获取语音数据的内容,直接将语音数据传到操作系统或web应用系统中去,避免了用户输错密码或者密码混乱导致的无法登录的问题,提高了办公效率,降低了用户被锁定的风险。
60.本发明还提供一种基于国产cpu和操作系统环境的语音识别登陆装置,为外设语音识别装置,针对操作系统端的安全登陆,包括操作系统端模型构建模块、操作系统端校验模块和操作系统端登录模块,针对浏览器的安全登陆,包括浏览器端模型构建模块、浏览器端校验模块和浏览器端登录模块,
61.针对操作系统端的安全登陆,操作系统端模型构建模块获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,操作系统端校验模块利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则操作系统端登录模块进行安全认证登录,进入对应的操作系统;
62.针对浏览器的安全登陆,浏览器端模型构建模块利用语音识别浏览器插件获取语音数据,根据语音数据提取语音特征,根据语音特征构建语音识别模型,浏览器端校验模块利用语音识别模型通过动态时间规整算法将待识别的语音特征进行相似性匹配,根据匹配结果校验待识别的语音,校验通过则浏览器端登录模块通过单点登录进入对应的web应用系统。
63.上述装置内的各模块之间的信息交互、执行过程等内容,由于与本发明方法实施例基于同一构思,具体内容可参见本发明方法实施例中的叙述,此处不再赘述。
64.同样地,本发明为国产环境各种电脑和应用的登录提供安全认证,保证了用户电脑数据和各种应用数据的安全性,充分考虑了全国产环境下,不同操作系统、浏览器的兼容
性,可以实现将语音数据作为唯一的标识数据,通过语音识别外设直接进行安全认证登录,方便快捷。
65.需要说明的是,上述各流程和各装置中不是所有的步骤和模块都是必须的,可以根据实际的需要忽略某些步骤或模块。各步骤的执行顺序不是固定的,可以根据需要进行调整。上述各实施例中描述的系统结构可以是物理结构,也可以是逻辑结构,即,有些模块可能由同一物理实体实现,或者,有些模块可能分由多个物理实体实现,或者,可以由多个独立设备中的某些部件共同实现。
66.以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
