cp-ebus弹性模式视频的处理方法、装置、设备与介质
技术领域
1.本发明涉及医疗图像分析领域,尤其涉及一种cp-ebus弹性模式视频的处理方法、装置、设备与介质。
背景技术:
2.cp-ebus是一种微创的胸内病变诊断技术,该技术利用装有活检针、超声装置和内窥镜的探头精确地由气管或支气管进入准备活检的淋巴结或病变附近观察病变,并利用活检针取得目标淋巴结或者病变的组织或细胞成分,通过对取出标本的病理分析可以对病人的疾病进行准确的诊断。然而由于活检取得的标本量较少,单纯病理诊断有20%的假阴性。在取得病变标本的过程中,超声装置可以获取不同模态下的淋巴结或者病变的超声影像,现有研究表明,超声影像中的弹性模式(即e模式)对于淋巴结良恶性的诊断有着重要的价值。依据超声影像的诊断结果,可以帮助操作医生在活检过程中挑选合适的淋巴结或病变进行穿刺,同时当穿刺结果阴性时也可以作为活检诊断的一个补充,弥补病理诊断的缺陷。
3.现有的对cp-ebus影像e模式的诊断方法分为半定量或者定量方法,其中半定量方法主要依赖于医生对弹性图像颜色分布的观察,例如,观察弹性e模式影像中的淋巴结的颜色分布,如果偏蓝色,即淋巴结偏硬,则对于淋巴结诊断倾向于恶性,如果偏绿色,即淋巴结偏软,则对于淋巴结诊断倾向于良性。另一类定量的方法,通常是以影像的某些统计特征作为指标,设定一定的阈值,超过或者低于该阈值则认为该淋巴结属于恶性或良性。以上现有的方法,都依赖于医生从弹性超声视频中选择出代表性图片,该代表性图片往往需要医生观察整个视频,并且高度依赖于医生的经验,专家医生所选出来的代表性图片要好于初学者。
4.可见,现有技术中,cp-ebus弹性模式视频的处理方法的处理结果的优劣取决于医生的经验,难以得到保障。
技术实现要素:
5.本发明提供一种cp-ebus弹性模式视频的处理方法、装置、设备与介质,以解决的问题。
6.根据本发明的第一方面,提供了一种cp-ebus弹性模式视频的处理方法,包括:
7.获取待处理视频的有效帧;所述待处理视频源自目标对象的e模式超声影像;
8.将所述有效帧转化为归一化的颜色直方图,并将所述颜色直方图输入经训练的第一神经网络,获取所述第一神经网络输出的所述有效帧的单帧特征表示信息;所述第一神经网络采用了具有可学习参数的一层或多层全连接层;
9.基于有效帧的单帧特征表示信息,在有效帧中选出代表性图片,并基于所述代表性图片,确定对应于所述待处理视频的视频特征表示信息;
10.基于所述视频特征表示信息,确定对应于所述待处理视频的当前分类结果,所述当前分类结果表征了所述目标对象倾向于良性还是恶性。
11.可选的,获取待处理视频的有效帧,包括:
12.获取所述待处理视频;
13.在所述待处理视频的所有视频帧中,基于所述视频帧的成像质量,确定所述有效帧。
14.可选的,基于所述视频帧的成像质量,确定所述有效帧,包括:
15.确定任一第z个视频帧中的扫描框区域;其中,z为大于或与等于1的整数;
16.计算所述第z个视频帧的扫描框区域内像素点的至少一种像素参数的统计值,所述至少一种像素参数包括饱和度和/或相对明暗度;
17.针对所述第z个视频帧,通过比较所述至少一种像素参数的统计值与预设的选择阈值,确定所述任一视频帧是否为所述有效帧;
18.若所述第z个视频帧为有效帧,则确定所述第z个视频帧之后或附近的m个视频帧非有效帧,其中,m为大于或等于1的整数。
19.可选的,基于有效帧的单帧特征表示信息,在有效帧中选出代表性图片,并确定对应于所述待处理视频的视频特征表示信息,包括:
20.基于每个有效帧的单帧特征表示信息,利用可微分稀疏图注意力机制,计算该有效帧的重要性评估信息;所述重要性评估信息被用于表征出对应有效帧在所述待处理视频或所有有效帧中的重要程度;其中的k为大于或等于1的整数;
21.基于所述重要性评估信息,选取重要性最高的k个有效帧作为代表性图片;
22.对所述代表性图片的重要性评估信息进行加权求和,得到加权特征表示信息;
23.将所述加权特征表示信息输入经训练的第二神经网络,获取所述第二神经网络输出的所述视频特征表示信息,所述第二神经网络采用了具有可学习参数的一层或多层全连接层。
24.可选的,基于每个有效帧的单帧特征表示信息,利用可微分稀疏图注意力机制,计算该有效帧的重要性评估信息,包括:
25.针对任意第y个有效帧,通过预先确定的第一可学习参数矩阵,将所述第y个有效帧的单帧特征表示信息映射为指定维度的嵌入特征表示信息;其中的y为大于或等于1的整数;
26.通过预先确定的第二可学习参数矩阵,将所述单帧特征表示信息映射为特定维度的关系特征表示信息;
27.基于所述关系特征表示信息与所述嵌入特征信息,构建一全连接图,所述全连接图中的每个结点对应一个有效帧,每个结点的结点特征表示信息为对应有效帧的嵌入特征表示信息,表征结点间关系的邻接矩阵是根据对应结点的关系特征表示信息确定;
28.基于预先确定的第三可学习参数矩阵与所述全连接图,确定一更新特征表示信息;
29.基于预先确定的第四可学习参数矩阵与所述更新特征表示信息,计算各个有效帧的稠密重要性分数,并基于所述稠密重要性分数,确定所述有效帧的重要性分数作为所述重要性评估信息。
30.可选的,基于预先确定的第三可学习参数矩阵与所述全连接图,确定一更新特征表示信息,包括:
31.根据所述全连接图的邻接矩阵a和结点特征xe传递信息,获得axe;
32.基于所述第三可学习参数矩阵对axe进行图卷积,并通过非线性函数σ激活,得到对应的输出结果;
33.将所述输出结果输入至一层或者多层全连接层,并对该全连接层的输出进行第一次层归一化,将第一次层归一化的结果与跃层连接传递的axe相加,再进行第二次层归一化,得到所述更新特征表示信息。
34.可选的,所采用的可学习参数是基于训练视频集,以及针对所述训练视频集中的视频而标定的指定分类结果而得到的,其中的指定分类结果表征了对应视频的指定对象是良性还是恶性。
35.根据本发明的第二方面,提供了一种cp-ebus弹性模式视频的处理装置,包括:
36.获取模块,用于获取待处理视频的有效帧;所述待处理视频源自目标对象的e模式超声影像;
37.单帧特征确定模块,用于将所述有效帧转化为归一化的颜色直方图,并将所述颜色直方图输入经训练的第一神经网络,获取所述第一神经网络输出的所述有效帧的单帧特征表示信息;所述第一神经网络采用了具有可学习参数的一层或多层全连接层;
38.视频特征确定模块,用于基于有效帧的单帧特征表示信息,在有效帧中选出代表性图片,并基于所述代表性图片,确定对应于所述待处理视频的视频特征表示信息;
39.分类模块,用于基于所述视频特征表示信息,确定对应于所述待处理视频的当前分类结果,所述当前分类结果表征了所述目标对象倾向于良性还是恶性。
40.根据本发明的第三方面,提供了一种电子设备,包括处理器与存储器,
41.所述存储器,用于存储代码;
42.所述处理器,用于执行所述存储器中的代码用以实现第一方面及其可选方案涉及的方法。
43.根据本发明的第四方面,提供了一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面及其可选方案涉及的方法。
44.本发明提供的cp-ebus弹性模式视频的处理方法、装置、设备与介质中,实现了目标对象良性还是恶性的自动判断,该过程中,可无需医生介入,进而,可以替代现有的医生进行自动选图和自动诊断,保障了处理结果的稳定性,避免医生经验的不同而带来的难以保障的问题。进一步方案中,通过神经网络(例如使用全连接层的神经网络),可有助于提高选图与诊断的准确性,在部分方案中,经充分训练之后,可有助于使得:选图和诊断结果与医学专家相比并无显著差异,并且拥有良好的可扩展性。
附图说明
45.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
46.图1是本发明一实施例中cp-ebus弹性模式视频的处理方法的流程示意图;
47.图2是本发明一实施例中步骤s11的流程示意图;
48.图3是本发明一实施例中步骤s112的流程示意图;
49.图4是本发明一实施例中步骤s13的流程示意图;
50.图5是本发明一实施例中步骤s131的流程示意图;
51.图6是本发明一实施例中cp-ebus弹性模式视频的处理装置的程序模块示意图;
52.图7是本发明一实施例中电子设备的构造示意图。
具体实施方式
53.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
54.本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
55.下面以具体地实施例对本发明的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
56.本发明实施例提供的cp-ebus弹性模式视频的处理方法,可应用于任意具备数据处理能力的设备,例如计算机、服务器、平板电脑、移动终端、医疗设备等等。
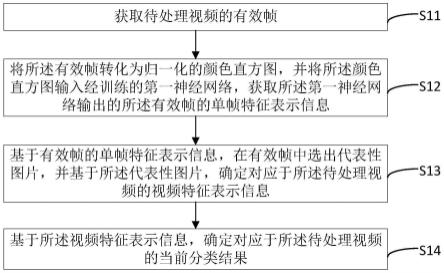
57.本发明实施例中,请参考图1,cp-ebus弹性模式视频的处理方法,包括:
58.s11:获取待处理视频的有效帧;
59.所述待处理视频源自目标对象的e模式超声影像;其中的目标对象可例如为淋巴结或包含淋巴结的生理部位;其中的待处理视频可以是e模式超声影像本身,也可以是在此基础上处理后得到的视频;
60.s12:将所述有效帧转化为归一化的颜色直方图,并将所述颜色直方图输入经训练的第一神经网络,获取所述第一神经网络输出的所述有效帧的单帧特征表示信息;
61.所述第一神经网络采用了具有可学习参数的一层或多层全连接层;
62.其中的单帧特征表示信息,可理解为对对应有效帧内像素的特征进行表示的任意信息,具体的,可以是对有效帧内像素的颜色的特征进行表示的任意信息;
63.s13:基于有效帧的单帧特征表示信息,在有效帧中选出代表性图片,并基于所述代表性图片,确定对应于所述待处理视频的视频特征表示信息;
64.其中的代表性图片,可理解为用于代表待处理视频中视频帧的图片;
65.其中的有效帧,可理解为待处理视频的视频帧中非冗余的且具有一定图像质量的图片;
66.其中的视频特征表示信息,可理解为对待处理视频(或其中有效帧,亦或其中代表性图片)的特征进行表示的任意信息;
67.s14:基于所述视频特征表示信息,确定对应于所述待处理视频的当前分类结果;
68.所述当前分类结果表征了所述目标对象倾向于良性还是恶性,也可理解为目标对象为良性还是恶性的识别结果。
69.以上方案中,实现了目标对象良性还是恶性的自动判断,该过程中,可无需医生介入,进而,可以替代现有的医生进行自动选图和自动诊断,保障了处理结果的稳定性,避免医生经验的不同而带来的难以保障的问题。
70.其中一种实施方式中,请参考图2,步骤s11,可以包括:
71.s111:获取所述待处理视频;
72.s112:在所述待处理视频的所有视频帧中,基于所述视频帧的成像质量,确定所述有效帧。
73.其中的成像质量,可基于视频帧中像素的任意像素参数而评价,具体可基于视频帧的所有像素的像素参数而评价,也可仅基于视频帧的部分像素的像素参数而评价,还可区分于不同像素而采用不同的像素参数和/或评价方式,同时,所确定的有效帧具体为成像质量较佳的部分视频帧。
74.具体的,在步骤s112中,可针对待处理视频,依据视频帧的成像质量,筛选出有效帧,过滤冗余信息。
75.一种举例中,请参考图3,步骤s112可以包括:
76.s1121:确定任一第z个视频帧中的扫描框区域;
77.其中,z为大于或与等于1的整数;
78.s1122:计算所述第z个视频帧的扫描框区域内像素点的至少一种像素参数的统计值,
79.所述至少一种像素参数包括饱和度和/或相对明暗度;部分举例中,可同时采用饱和度与相对明暗度,其他举例中,至少一种像素参数也可包括色度、亮度、对比度等;
80.s1123:针对所述第z个视频帧,通过比较所述至少一种像素参数的统计值与预设的选择阈值,确定所述任一视频帧是否为所述有效帧;
81.s1124:若所述第z个视频帧为有效帧,则确定所述第z个视频帧之后或附近的m个视频帧非有效帧,其中,m为大于或等于1的整数。
82.步骤s1121的一种具体的举例中,可对弹性视频帧中的扫描框区域进行定位,从而可以裁剪掉帧中的无关部分(例如扫描框区域之外的部分,也可不限于此);
83.步骤s1122、s1123、s1124的一种具体的举例中,可对扫描框内图像,根据有颜色像素点的饱和度和相对明暗度对该帧的成像质量进行评估,具体而言,可以对于待处理视频中的每一帧,根据图像质量评估判断该帧的质量,若质量合格则将该帧视作有效帧,并跳过接下来的m帧(该m个视频帧可理解为一种非有效帧,也可理解为冗余帧),m为预设的超参数。由于视频中的相邻帧具有相似性,该策略可以在尽量减少遗漏重要信息的情况下,降低有效帧的数量,避免过高的复杂度。可见,本发明具体方案既筛除了质量较差的视频帧,还将冗余的视频帧排除。
84.再进一步的举例中,可以根据所述视频帧中的饱和度,确定所述视频帧中的有颜色像素点与无颜色像素点,计算有颜色像素点的覆盖比例,以及有颜色像素点的明暗度均值与无颜色像素点的明暗度均值的比值。若当前帧的两项计算结果(即所述覆盖比例与所
述比值)均高于对应的选择阈值,则将该帧作为有效帧保留,否则作为冗余帧去除。
85.其中一种实施方式中,步骤s12的具体举例可例如:
86.输入的有效帧(w和h是有效帧的宽度和高度,c为3对应rgb三个通道的分量值,每个通道均为8比特,取值范围为0-255的整数),在每个通道上,以区间大小l生成直方图,统计值位于各个区间内的像素点数量,共计28/l区间(其中的l通常为2的幂,取值范围在1-256的区间范围内),则所有三个通道共有2
24
/l3个区间。对于每个有效帧所有2
24
/l3个区间,进行归一化,去除均值并除去标准差,得到归一化颜色直方图,例如这里l=32。
87.针对于其中的归一化,可例如:对一个d=2
24
/l3维向量v归一化,即对v的每一项vk进行操作vk=(v
k-mean(v))/std(v),mean(v)是所述d维向量的d个维度的分量的均值,std(v)是所述d维向量的d个维度的分量的标准差。
88.然后,可将所得到的各个有效帧的归一化颜色直方图通过具有可学习参数的一层或多层全连接层(例如一种经训练的神经网络),进行变换得到n个有效帧的l维特征表示(即l维的特征表示信息),x的行向量x1,x2,
…
,xn对应每个有效帧的l维特征表示,即行向量中的x1,x2,
…
,xn分别为一个特征表示信息。例如可将所得到的各个有效帧的归一化颜色直方图通过具有可学习参数的三层全连接层,输出维度分别为512,256和128,进行变换得到n个有效帧的l=128维特征表示
89.其中一种实施方式中,请参考图4,步骤s13可以包括:
90.s131:基于每个有效帧的单帧特征表示信息,利用可微分稀疏图注意力机制,计算该有效帧的重要性评估信息;
91.所述重要性评估信息被用于表征出对应有效帧在所述待处理视频或所有有效帧中的重要程度;部分举例中,重要性评估信息可采用十进制、二进制等任意进制的数值、字符,例如,重要性评估信息可例如重要性分数来表征,其他部分举例中,也可以采用评级结果或文字等任意形式来表征;
92.s132:基于所述重要性评估信息,选取重要性最高的k个有效帧作为代表性图片;
93.其中的k为大于或等于1的整数;其可以是固定的数值,可以是随有效帧数量而变化(例如与有效帧数量呈正比)的任意数值;
94.s133:对所述代表性图片的重要性评估信息进行加权求和,得到加权特征表示信息;
95.其中的加权特征信息,可理解为对重要性评估信息进行加权求和后直接或间接得到的信息;
96.s134:将所述加权特征表示信息输入经训练的第二神经网络,获取所述第二神经网络输出的所述视频特征表示信息;
97.所述第二神经网络采用了具有可学习参数的一层或多层全连接层。
98.进一步举例中,请参考图5,步骤s131可以包括:
99.s1311:针对任意第y个有效帧,通过预先确定的第一可学习参数矩阵,将所述第y个有效帧的单帧特征表示信息映射为指定维度的嵌入特征表示信息;
100.其中的y为大于或等于1的整数;
101.其中的嵌入特征表示信息可理解为利用指定维度的信息而对有效帧的特征进行描述的任意信息;
102.s1312:通过预先确定的第二可学习参数矩阵,将所述单帧特征表示信息映射为特定维度的关系特征表示信息;
103.该特定维度可以与所述指定维度相同,也可以不同;
104.关系特征表示信息可理解为为利用指定维度的信息而对有效帧之间的关系特征进行描述,从而可应用于后续步骤的全连接图的任意信息;
105.s1313:基于所述关系特征表示信息与所述嵌入特征信息,构建一全连接图;
106.所述全连接图中的每个结点对应一个有效帧,每个结点的结点特征表示信息为对应有效帧的嵌入特征表示信息,表征结点间关系的邻接矩阵是根据对应结点的关系特征表示信息确定;
107.s1314:基于预先确定的第三可学习参数矩阵与所述全连接图,确定一更新特征表示信息;
108.s1315:基于预先确定的第四可学习参数矩阵与所述更新特征表示信息,计算各个有效帧的稠密重要性分数,并基于所述稠密重要性分数,确定所述有效帧的重要性分数作为所述重要性评估信息。
109.步骤s1311的一种举例中,可以通过可学习参数矩阵(即第一可学习参数矩阵),其中l=128,l
′
=64,将有效帧的特征表示x(即单帧特征表示信息)映射到l
′
维嵌入特征表示xe(即嵌入特征表示信息),即xe=xwe。
110.步骤s1312的一种举例中,可以通过可学习参数矩阵(即第二可学习参数矩阵),其中l=128,l
′
=64,将有效帧的特征表示x(即单帧特征表示信息)映射到l
′
维关系特征表示xr(即关系特征表示信息),即xr=xwr。
111.步骤s1313的一种举例中,根据关系特征表示xr(即关系特征表示信息)和嵌入特征表示xe(即嵌入特征表示信息)构造全连接图,其中,每个结点对应一个有效帧,每个结点的结点特征即为对应有效帧的嵌入特征表示信息,邻接矩阵a根据关系特征表示xr基于如下函数构建:
[0112][0113]
这里,softmax函数按行作用于矩阵对于输入的行向量x=[x1,
…
,xn],输出向量的第i个元素为
[0114]
步骤s1314的一种举例中,可以包括:
[0115]
s13141:根据所述全连接图的邻接矩阵a和结点特征xe传递信息,获得axe;
[0116]
s13142:基于所述第三可学习参数矩阵对axe进行图卷积,并通过非线性函数σ激活,得到对应的输出结果;
[0117]
s13143:将所述输出结果输入至一层或者多层全连接层,并对该全连接层的输出
进行第一次层归一化,将第一次层归一化的结果与跃层连接传递的axe相加,再进行第二次层归一化,得到所述更新特征表示信息。
[0118]
可见,以上过程可描述为:根据所构建的全连接图基于可学习参数矩阵(即第三可学习参数矩阵)进行图卷积传递信息和更新各个结点的特征,并通过非线性函数激活、具有可学习参数的全连接层和层归一化获得更新特征表示(即更新特征表示信息)。具体的操作如下:
[0119]
s13141与s13142的中举例中,可根据所述图的邻接矩阵a和结点特征xe传递信息,获得axe通过跃层连接,基于可学习参数矩阵(即第三可学习参数矩阵)对axe进行图卷积,其中lg=128,并通过relu函数(一种纠正线性单元,也可采用其他函数实现)激活,输出这里relu(x)=max(0,x)。
[0120]
将输出的通过具有可学习参数的全连接层,其中l1=256,并通过relu函数激活,并将激活输出再通过具有可学习参数的全连接层,其中l2=128。
[0121]
然后,s13143的具体举例中,可对全连接层的输出进行层归一化(即第一次层归一化),同s13141、s13142跃层连接传递的axe相加,再进行层归一化(即第二次层归一化),获得更新特征表示(即更新特征表示信息);
[0122]
其中,按照上述步骤可以得到:
[0123]
这里ln代表层归一化;
[0124]
之后,步骤s1315的具体举例中,可基于可学习参数向量(即第四可学习参数矩阵)根据计算各有效帧的稠密重要性分数对所述稠密重要性分数进行软阈值操作,获得重要性分数s作为重要性评估信息。以上过程的具体操作为:
[0125]
s13151:基于可学习参数向量限据计算各个有效帧的稠密重要性分数这里这里是双曲正切函数。
[0126]
s13152:对s13151得到的所述稠密重要性分数降序排序,得到找到满足的最大整数l,计算软阈值
[0127]
s13153:基于软阈值从稠密重要性分数计算重要性分数,s13153:基于软阈值从稠密重要性分数计算重要性分数,当大于0时si取值为否则si值为0。
[0128]
以上步骤s133与s134中,可将k个代表性图片的重要性分数作为权重组合对应的特征表示,得到加权特征表示信息,然后将加权特征表示信息通过具有可学习参数的一层或多层全连接层(即第二神经网络),得到聚合特征表示(即视频特征表示信息)。在此基础上,步骤s14中,可基于所述聚合特征表示(视频特征表示信息)进行分类,得到良恶性诊断(即当前分类结果);例如,可预先设置各视频特征表示信息与良性的对应关系,各视频特征表示信息与恶性的对应关系,然后基于该对应关系确定当前分类结果,再例如,也可利用分类器(亦或神经网络等)等对聚合特征表示(视频特征表示信息)进行分类,得到良恶性诊断的结果(即当前分类结果),从而实现步骤s14的过程,该分类器也可与其他各种可学习参数等一同训练确定。
[0129]
以上各实施例、举例中所采用的可学习参数是基于训练视频集,以及针对所述训练视频集中的视频而标定的指定分类结果而得到的,其中的指定分类结果表征了对应视频的指定对象是良性还是恶性。
[0130]
为了验证本发明上述方案的效果,在真实的cp-ebus数据集上进行了实验,并且和现有的深度学习方法以及人类专家使用的方法进行了性能比较。实验中模型在727个弹性视频通过分层五折交叉验证的方式进行训练和评估。具体地,727个弹性视频被平均成五折,在分割数据时,每折中良恶性比例基本一致。对每一折进行评估时,将其余四折中的三折作为训练数据,另外一折作为验证数据用以选择模型。最后我们计算不同模型在五折交叉验证中的结果的平均值进行对比。同时,为了验证模型选图的效果,由三位专家对模型在弹性视频上选出的图片用定量和半定量方法进行诊断。另外三名专家在弹性视频上直接进行选图和诊断,将不同模型的诊断性能以及基于模型和专家选图的临床方法诊断性能作为结果记录下来。
[0131]
实验结果如下:
[0132][0133]
表1:本发明具体方案和一般视频识别方法的性能对比。acc:准确率,sen:敏感度,spe:特异度,ppv:阳性预测值,npv:阴性预测值。此外,括号内的数值是配对t检验获得的p值。
[0134][0135]
表2:自动选图和三名专家组成的专家组分别选取的三幅代表性图片的定性五分法诊断结果。acc:准确率,sen:敏感度,spe:特异度,ppv:阳性预测值,npv:阴性预测值。
[0136][0137]
表3:自动选图与专家选图四种定量指标的差异性
[0138]
表1比较了本发明具体方案和现有自然视频识别方法的诊断性能。这里lstm和gru表示直接采用递归神经网络lstm和gru融合帧特征。可以看出,在各个指标下本文所述方法均远远优于现有深度学习模型。同时,我们使用配对t检验(paired t-test)对本文所述方法的和其他模型结果的显著性进行了统计分析,结果表明我们的方法与现有模型的结果在大多数情况下具有显著差异,验证了本文所述方法在基于cp-ebus视频的淋巴结良恶性诊断中的优越性。表2和表3分别比较了使用定性和定量方法对模型选图和专家选图进行诊断的结果比较。结果表明,利用本文所述方法所选的图进行诊断具有更好和更稳定的性能表现,远远优于复杂、耗时的专家选图,进一步突出了本文所述方法的优越性。
[0139]
与现有技术相比,本发明具体方案具有以下优点:
[0140]
首先实现了ebus弹性模式视频的自动化选图和诊断,选图和诊断结果相较于人类专家无显著差异。
[0141]
能够快速完成自动选图和诊断,适用于ebus弹性模式视频的实时分析。
[0142]
相较于现有技术而言易于推广,可以高效部署在cp-ebus设备上。
[0143]
请参考图7,提供了一种电子设备30,包括:
[0144]
处理器31;以及,
[0145]
存储器32,用于存储所述处理器的可执行指令;
[0146]
其中,所述处理器31配置为经由执行所述可执行指令来执行以上所涉及的方法。
[0147]
处理器31能够通过总线33与存储器32通讯。
[0148]
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现以上所涉及的方法。
[0149]
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0150]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。