基于stacking多模型融合设计的空气污染物缺失值补充方法
技术领域
1.本发明涉及空气污染物应用技术领域,尤其涉及一种基于stacking多模型融合设计的空气污染物缺失值补充方法。
背景技术:
2.过去的几十年里,随着工业化和城市化的快速发展,空气污染物浓度水平的不断上升已成为全球关注的焦点。根据世界卫生组织的数据,世界上每10人中就有9人生活在被污染的空气中。常见的空气污染物包括no2,o3,pm10,pm2.5 等,它们不仅会导致环境问题,如土壤酸化,雾和霾,还会导致健康问题,如心脏病和肺部疾病。为了提前做好预防大气污染的准备,从而减轻大气污染对人体健康和经济的影响,我国已设立多个空气监测站,监测和收集空气污染数据,以便进一步研究。然而,由于收集传感器的损坏、设计不良的收集过程以及人为的错误等种种因素,各个国控站点观测到的数据总会有缺失。这些缺失的数据对后续时序数据的预测和分析带来了极大的困难。所以时序数据补缺是一个需要迫切解决的重要难题。
3.从数据缺失的性质而言,缺失数据的处理主要分为两种方案,一种是在尽量不影响研究结果的前提下将缺失记录删除,另一种就是研究如何按照采集数据的性质,规律等因素对缺失的数据进行补充。当只有极少量数据发生缺失时,可以在研究中使用删除少量缺失记录的方式来处理缺失数据。相比于删除法的大量使用限制,使用各种方式对由于不可控因素导致的采集数据缺失进行补充可以说是一种较为通用的方式。相关研究人员尝试使用均值,上一个有效记录等数据来对缺失数据进行填补,但是原始的均值填补法由于填补的数据为均值数据忽略了原始采集数据的变化趋势。
技术实现要素:
4.针对现有技术存在的精度低、分析程序复杂和时序性差的问题,本发明提供一种基于stacking多模型融合设计的空气污染物缺失值补充方法。
5.本发明提供一种基于stacking多模型融合设计的空气污染物缺失值补充方法,包括:
6.步骤1:获取各个国控站点监测的空气污染物数据和地理数据;
7.步骤2:针对每个国控站点,遍历其上的所有空气污染物数据,找到每个类型污染物的缺失值,并将缺失值所在位置处的数值补充为0;然后,再次遍历其上的所有空气污染物数据,将数值非0的数据加入至训练集中,将数值为0的数据加入预测集中;将所有国控站点的训练集和预测集分别组合在一起,记作数据集air-data;
8.步骤3:使用贝叶斯优化法hyperopt分别对极端决策树模型et、随机森林模型rf、迭代决策树模型gbdt、分布式梯度增强树模型xgboost和分布式梯度决策树模型lgbm进行参数优化,将优化后的模型分别记作hyperopt-et、 hyperopt-rf、hyperopt-gbdt、hyperopt-xgboost和hyperopt-lgbm;
9.步骤4:将hyperopt-et、hyperopt-rf、hyperopt-gbdt、hyperopt-xgboost 和hyperopt-lgbm五种模型分别作为五个基学习器,将岭回归模型作为元学习器,基于所述数据集air-data对所述基学习器和所述元学习器进行融合得到 stacking集成模型;
10.步骤5:采用所述stacking集成模型实现对空气污染物数据中的缺失值的估算。
11.进一步地,所述方法还包括:
12.若在某个国控站点上找到的缺失值的数量与其上的所有数据量的比值大于设定阈值,则认为该国控站点上的缺失值较多;
13.将缺失值较多的国控站点对应的数据从数据集air-data中进行剔除。
14.进一步地,步骤4具体包括:
15.步骤4.1:将数据集air-data中的训练集按照设定比例重新划分为训练集a 和测试集b;
16.步骤4.2:根据训练集a采用5折交叉验证方式分别对五个所述基学习器进行训练,采用训练好的五个所述基学习器分别生成五个数据集a1、a2、a3、 a4和a5;所述数据集a1、a2、a3、a4和a5的数据量均与训练集a的数据量相同;
17.步骤4.3:将所述数据集a1、a2、a3、a4和a5组合在一起作为岭回归模型的训练集,使得所述岭回归模型学习得到五个所述基学习器的输出结果与真实的空气污染物数据之间的关系,即为stacking集成模型。
18.进一步地,所述方法还包括:
19.在对五个所述基学习器采用5折交叉验证方式进行训练的过程中,将测试集 b划分为五部分,选择其中的四部分用来训练,并对剩下的一部分进行预测,并将五次预测结果进行平均得到新的测试集b1;所述测试集b1的数据量与所述测试集b的数据量相同;
20.采用所述测试集b1验证所述stacking集成模型的性能。
21.进一步地,所述空气污染物数据包括:小时no2浓度、小时pm
10
浓度、小时pm
2.5
浓度和小时o3浓度。
22.进一步地,所述地理数据包括:经度和纬度。
23.进一步地,验证所述stacking集成模型的性能时所用的指标包括:决定系数、平均绝对误差和均方根误差。
24.本发明的有益效果:
25.本发明采用hyperopt-et、hyperopt-rf、hyperopt-gbdt、 hyperopt-xgboost和hyperopt-lgbm五种模型作为基学习器,通过交叉验证训练基学习器,岭回归作为元学习器;其中,第一层的多个基学习器以原始训练集为输入,第二层的岭回归模型再以第一层的输出作为特征来训练元学习器,最终得到完整的模型,之后用于估算缺失的空气污染物浓度。stacking集成方法集成了多种学习器的估算与预测结果,克服了单个模型的缺陷,优化了线性回归的输入,提升了模型整体性能。
附图说明
26.图1为本发明实施例提供的基于stacking多模型融合设计的空气污染物缺失值补充方法的流程示意图;
27.图2为本发明实施例提供的对基学习器和元学习器进行融合得到stacking 集成
模型的示意图;
28.图3为本发明实施例提供的stacking集成模型使用测试集进行估算后,取前 300个测试样本估算结果与真实结果的对比图;
29.图4为本发明实施实例提供的同一地点的实际污染物浓度值与模型估算污染物浓度值的散点图;
30.图5为本发明实施例提供的stacking集成模型与其他模型在数据集air-data上的训练效果对比图。
具体实施方式
31.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
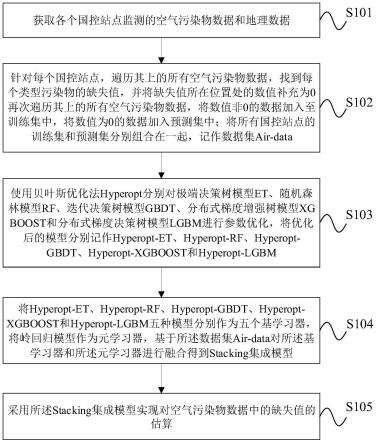
32.如图1所示,本发明实施例提供的基于stacking多模型融合设计的空气污染物缺失值补充方法,包括以下步骤:
33.s101:获取各个国控站点监测的空气污染物数据和地理数据;
34.具体地,所述空气污染物数据包括:小时no2浓度、小时pm
10
浓度、小时 pm
2.5
浓度和小时o3浓度;所述地理数据包括:经度和纬度。
35.s102:针对每个国控站点,遍历其上的所有空气污染物数据,找到每个类型污染物的缺失值,并将缺失值所在位置处的数值补充为0;然后,再次遍历其上的所有空气污染物数据,将数值非0的数据加入至训练集中,将数值为0的数据加入预测集中;将所有国控站点的训练集和预测集分别组合在一起,记作数据集 air-data;
36.具体地,国控站点监测的空气污染物数据是以csv格式存储的,为了便于数据处理,可以使用python读取csv文件,然后将该csv文件数据导入mysql 中进行整理。
37.需要说明的是,一般而言,在现实中,no2、pm
10
、pm
2.5
和o3的浓度值不会为0,所以浓度为0的数据同样当作缺失值。
38.s103:使用贝叶斯优化法hyperopt分别对极端决策树模型et、随机森林模型rf、迭代决策树模型gbdt、分布式梯度增强树模型xgboost和分布式梯度决策树模型lgbm进行参数优化,将优化后的模型分别记作hyperopt-et、 hyperopt-rf、hyperopt-gbdt、hyperopt-xgboost和hyperopt-lgbm;
39.具体地,hyperopt-et模型为基于贝叶斯算法优化的极端决策树模型、 hyperopt-rf模型为基于贝叶斯算法优化的随机森林模型;hyperopt-gbdt模型为基于贝叶斯算法优化的迭代决策树模型;hyperopt-xgboost模型为基于贝叶斯算法优化的分布式梯度增强树、hyperopt-lgbm模型为基于贝叶斯算法优化的分布式梯度决策树。
40.s104:将hyperopt-et、hyperopt-rf、hyperopt-gbdt、hyperopt-xgboost 和hyperopt-lgbm五种模型分别作为五个基学习器,将岭回归模型作为元学习器,基于所述数据集air-data对所述基学习器和所述元学习器进行融合得到 stacking集成模型;
41.作为一种可实施方式,如图2所示,本步骤包括以下子步骤:
42.s1041:将数据集air-data中的训练集按照设定比例重新划分为训练集a和测试集
b;
43.例如,将数据集air-data按4:1的比例划分为训练集和测试集,然后对数据进行归一化,消除奇异样本数据的不良影响。
44.s1042:根据训练集a采用5折交叉验证方式分别对五个所述基学习器进行训练,采用训练好的五个所述基学习器分别生成五个数据集a1、a2、a3、a4 和a5;所述数据集a1、a2、a3、a4和a5的数据量均与训练集a的数据量相同;
45.s1043:将所述数据集a1、a2、a3、a4和a5组合在一起作为岭回归模型的训练集,使得所述岭回归模型学习得到五个所述基学习器的输出结果与真实的空气污染物数据之间的关系,即为stacking集成模型。
46.s105:采用所述stacking集成模型实现对空气污染物数据中的缺失值的估算。
47.若某一国控站点上的缺失值较多,即使进行数据的补缺,对后续空气污染物的预测和分析也会产生极大的影响,因此在上述实施例的基础上,本发明实施例在步骤s102之后,还包括:对数据集air-data进行数据清理;主要包括以下内容:若在某个国控站点上找到的缺失值的数量与其上的所有数据量的比值大于设定阈值,则认为该国控站点上的缺失值较多;将缺失值较多的国控站点对应的数据从数据集air-data中进行剔除。
48.例如,对某一国控站点监测到的小时浓度值缺失数量超过总数量的10%时,可以判定为该国控站点缺失值较多。
49.本发明实施例中,采用hyperopt-et、hyperopt-rf、hyperopt-gbdt、hyperopt-xgboost和hyperopt-lgbm五种模型作为基学习器,通过交叉验证训练基学习器,岭回归作为元学习器;其中,第一层的多个基学习器以原始训练集为输入,第二层的岭回归模型再以第一层的输出作为特征来训练元学习器,最终得到完整的模型,之后用于估算缺失的空气污染物浓度。stacking集成方法集成了多种学习器的估算与预测结果,克服了单个模型的缺陷,优化了线性回归的输入,提升了模型整体性能。
50.在上述各实施例的基础上,本发明还包括:
51.在对五个所述基学习器采用5折交叉验证方式进行训练的过程中,将测试集 b划分为五部分,选择其中的四部分用来训练,并对剩下的一部分进行预测,并将五次预测结果进行平均得到新的测试集b1;所述测试集b1的数据量与所述测试集b的数据量相同;
52.采用所述测试集b1验证所述stacking集成模型的性能。
53.作为一种可实施方式,验证所述stacking集成模型的性能时所用的指标包括:决定系数、平均绝对误差和均方根误差。
54.具体地,在预测回归问题中,决定系数r2是用来衡量回归结果的好坏,也是回归拟合曲线的拟合优度。决定系数的取值在0到1之间,值越大越好,其中p为预测值,m为真实值,具体公式如下:
[0055][0056]
平均绝对误差mae是绝对误差的平均值,能够更好的反映出预测值与真实值的误差实际情况,具体公式如下:
[0057][0058]
均方根误差rmse主要衡量预测值和真实值之间的偏差,具体公式如下:
[0059][0060]
为了验证本发明所提供的方法的有效性,本发明还提供下述实验数据。
[0061]
如图3、图4和图5所示,四种污染物no2、pm
10
、pm
2.5
、o3的测试样本分别为16919、16358、16689和16900个,估算值与真实值决定系数r2分别为0.87、0.941、0.979和0.948。计算得测试集样本平均绝对误差mae分别为4.236、 8.28、4.542和7.903,均方根误差rmse为6.531、14.22、6.965和10.831。
[0062]
相比于基学习器模型,stacking集成模型表现出了更好的预测性能,并且有更高的斜率,说明低值高估和高值低估的现象相对不严重。stacking集成模型的平均绝对误差(mae)和均方根误差(rmse)要小于其他五种模型的mae和 rmse,说明利用stacking集成模型进行补缺时,其估算值与国控站点的观测值之间的误差和偏差更小,可以认为stacking集成模型的估算结果更加接近真值,回归模型表现更好的性能。
[0063]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
