技术特征:
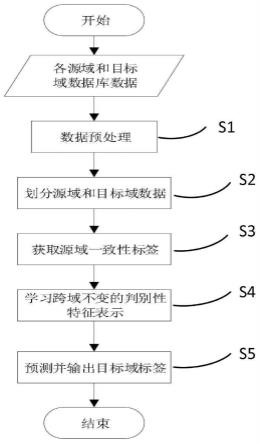
1.一种多源跨域表情识别方法,其特征在于,包括以下步骤:对图像数据进行人脸检测和关键点检测,并进行预处理;将预处理后的图像数据划分为源域数据和目标域数据;获取源域数据一致性标签,包括基于源域数据原有的标签学习一个标注模型,用于自动对源域数据进行重新标注;利用基于类别原型的度量学习方法学习跨域不变的特征表示,具体步骤包括:以源域数据和目标域数据为输入,利用表情识别模型,以第二交叉熵损失函数为目标函数,采用随机梯度下降算法学习源域数据和目标域数据的特征表示,并在每一次迭代中得到预测标签;将表情识别模型输出的目标域数据的预测标签作为目标域伪标签;根据源域数据一致性标签和特征表示,设计基于类别原型的第一损失函数,用于提高源域特征表示判别性,迭代过程中对源域数据的类别原型进行更新;基于目标域特征表示和目标域伪标签,设计基于类别原型的第二损失函数,用于提高目标域特征表示的判别性,迭代过程中对目标域数据的类别原型进行更新;基于源域数据和目标域数据的类别原型,设计源域-目标域特征表示差异性损失函数,用于减小特征表示的差异性;对表情识别模型进行训练,包括:将第二交叉熵损失函数、基于类别原型的第一损失函数、基于类别原型的第二损失函数、源域-目标域特征表示差异性损失函数相加得到整体损失函数,将整体损失函数用于表情识别模型训练,利用随机梯度下降算法进行迭代,直至达到最大迭代次数或表情识别模型收敛;将目标域数据输入训练好的表情识别模型中,得到目标域数据的最佳预测标签。2.根据权利要求1所述的多源跨域表情识别方法,其特征在于,所述对图像数据进行预处理,包括对人脸图像进行旋转校正并进行尺寸归一化。3.根据权利要求1所述的多源跨域表情识别方法,其特征在于,将预处理后的图像数据划分为源域数据和目标域数据,具体包括:在n个数据库中选择k个数据库作为源域数据库,其中k小于n,未被选择的数据库在每次训练过程中选择其中一个作为目标域数据库。4.根据权利要求1所述的多源跨域表情识别方法,其特征在于,获取源域数据一致性标签,具体步骤包括初始化训练阶段和重标签阶段:初始化训练阶段,包括:利用多个源域数据库,使用第一交叉熵损失函数训练标注模型,标注模型输出每个源域样本的预测分数和类别,用于对不同的源域数据库进行一致化标注;基于标注模型输出每个源域样本的预测分数的信息熵,设计得分差异损失函数,利用得分差异损失函数对每个源域样本各类别的得分进行约束;重标签阶段,包括:将预测类别和原始标签进行比较,当预测类别与原标签类别不同,且预测类别分数比原标签类别得分高出一个阈值时,将对应的源域样本的标签重新标记为预测标签;利用得分差异损失函数重复重标签阶段至标注模型收敛,将所有源域数据输入到标注模型,获得每个源域数据库的新标签。5.根据权利要求4所述的多源跨域表情识别方法,其特征在于,在进入重标签阶段前,
重复初始化训练阶段到指定的迭代次数。6.一种多源跨域表情识别装置,其特征在于,所述装置包括:预处理单元,用于对图像数据进行人脸检测和关键点检测,并进行预处理;图像数据划分单元,用于将预处理后的图像数据划分为源域数据和目标域数据;获取源域数据一致性标签单元,用于基于源域数据原有的标签学习一个标注模型,用于自动对源域数据进行重新标注;学习跨域不变的特征表示单元,用于利用基于类别原型的度量学习方法学习跨域不变的特征表示,具体步骤包括:以源域数据和目标域数据为输入,利用表情识别模型,以第二交叉熵损失函数为目标函数,采用随机梯度下降算法学习源域数据和目标域数据的特征表示,并在每一次迭代中得到预测标签;将表情识别模型输出的目标域数据的预测标签作为目标域伪标签;根据源域数据一致性标签和特征表示,设计基于类别原型的第一损失函数,用于提高源域特征表示判别性,迭代过程中对源域数据的类别原型进行更新;基于目标域特征表示和目标域伪标签,设计基于类别原型的第二损失函数,用于提高目标域特征表示的判别性,迭代过程中对目标域数据的类别原型进行更新;基于源域数据和目标域数据的类别原型,设计源域-目标域特征表示差异性损失函数,用于减小特征表示的差异性;表情识别模型训练单元,用于对表情识别模型进行训练,包括:将第二交叉熵损失函数、基于类别原型的第一损失函数、基于类别原型的第二损失函数、源域-目标域特征表示差异性损失函数相加得到整体损失函数,将整体损失函数用于表情识别模型训练,利用随机梯度下降算法进行迭代,直至达到最大迭代次数或表情识别模型收敛;获取最佳预测标签单元,用于将目标域数据输入训练好的表情识别模型中,得到目标域数据的最佳预测标签。7.根据权利要求6所述的多源跨域表情识别装置,其特征在于,所述获取源域数据一致性标签单元包括初始化训练模块和重标签模块,初始化训练模块用于:利用多个源域数据库,使用第一交叉熵损失函数训练标注模型,标注模型输出每个源域样本的预测分数和类别,用于对不同的源域数据库进行一致化标注;基于标注模型输出每个源域样本的预测分数的信息熵,设计得分差异损失函数,利用得分差异损失函数对每个源域样本各类别的得分进行约束;重标签模块用于:将预测类别和原始标签进行比较,当预测类别与原标签类别不同,且预测类别分数比原标签类别得分高出一个阈值时,将对应的源域样本的标签重新标记为预测标签;利用得分差异损失函数重复重标签阶段至标注模型收敛,将所有源域数据输入到标注模型,获得每个源域数据库的新标签。8.一种多源跨域表情识别装置,其特征在于,包括:处理器;以及存储器,其中,所述存储器中存储有计算机可执行程序,当由所述处理器执行所述计算机可执行程序时,执行权利要求1-5中任一项所述的多源跨域表情识别方法。9.一种计算机可读介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理
器执行时实现如权利要求1-5中任一项所述的多源跨域表情识别方法。
技术总结
本发明公开了一种多源跨域表情识别方法、装置及存储介质,方法包括:将预处理后的图像数据划分为源域数据和目标域数据;获取源域数据一致性标签,包括基于源域数据原有的标签学习一个标注模型,用于自动对源域数据进行重新标注;利用基于类别原型的度量学习方法学习跨域不变的特征表示,用于提高源域和目标域特征表示判别性,以及减小特征表示的差异性;对表情识别模型进行训练;将目标域数据输入训练好的表情识别模型中,得到目标域数据的最佳预测标签。本发明可从多个源域数据学习语义知识并将其迁移到目标域数据,提升跨域表情识别方法的泛化性能。的泛化性能。的泛化性能。
技术研发人员:卢光明 李英建 张正 罗子娟 李亚桐 张伟彬 陈东鹏
受保护的技术使用者:哈尔滨工业大学(深圳)
技术研发日:2022.02.15
技术公布日:2022/6/10
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。