1.本发明主要涉及到医疗信息化技术领域,特指一种中文电子病历中症状的标准化表型自动获取方法。
背景技术:
2.疾病辅助诊断软件利用计算机分析处理医学检测数据,能够提高医生诊断疾病的效率,在医疗领域发展迅速。疾病辅助诊断软件通常需要输入患者的症状,尤其是症状的标准化表型(hpo,human phenotype ontology),以方便计算机进行分析处理。然而,在实际应用中,用户常常只能提供患者的中文病历,如何从患者病历中自动化地提取症状的标准化表型,是提高疾病辅助诊断系统使用效率的一个关键环节。
3.一份详尽的临床病历通常包含病患病史特点、身体状况、检查结果、诊断结论、用药建议以及治疗方式等信息,其中患者当前的身体状态(症状),是医生进行临床诊断的重要依据,也是疾病辅助诊断软件的重要输入,因此高效准确的从临床病历中提取出症状信息意义重大。中文临床病历的特点有:(1)篇幅较长;(2)不同地区、机构的病历组织结构各异,表达方式也不尽相同;(3)充斥着大量的否定用语;(4)症状表述各异。病历描述中患者的症状,是医生进行临床诊断的重要依据,也是计算机进行疾病辅助诊断的关键,通常为了提高辅助诊断的效率,软件的输入是标准化的疾病表型。中文病历的特点使得软件的使用者很难通过人工的方法从病历中获取准确的标准表型,导致表型的输入很不准确,这大大影响了疾病辅助诊断类软件的诊断效率。
4.中文病历的上述特点导致人工从病历中提取症状较为困难,特别的,由于临床病历中大量否定域的存在(例:无呕吐、头晕),人工提取时需要对这些否定域进行剔除,费时费力。此外,如果要将提取结果(症状)用于其他分析软件,则还需将提取结果转化为标准的表型术语(hpo),要求医务人员对标准表型术语有充分的理解。
技术实现要素:
5.本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种原理简单、智能化程度高、精确性好、实用性强的中文电子病历中症状的标准化表型自动获取方法。
6.为解决上述技术问题,本发明采用以下技术方案:
7.一种中文电子病历中症状的标准化表型自动获取方法,其包括:
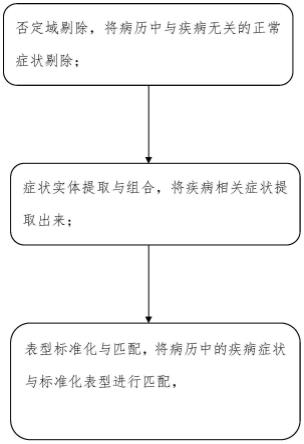
8.否定域剔除,将病历中与疾病无关的正常症状剔除;
9.症状实体提取与组合,将疾病相关症状提取出来;
10.表型标准化与匹配,将病历中的疾病症状与标准化表型进行匹配,确定哪些标准化表型与患者症状相关,获得的标准化表型作为医疗辅助诊断系统中患者表型的输入。
11.作为本发明的进一步改进:在进行症状类实体提取过程中,将临床病历中的症状类实体分为修饰实体mod、症状的部位实体body以及症状的表征实体sym三个细分种类,一
个完整的症状类实体由症状的表征实体加上修饰实体mod、症状的部位实体body组成。
12.作为本发明的进一步改进:在进行症状类实体提取过程中,使用词嵌入方法将临床病历文本向量化为输入特征,利用训练好的神经网络模型,对输入特征的类型判断,并将识别结果输出,实现症状类实体的自动提取。
13.作为本发明的进一步改进:所述症状类实体提取过程的流程包括:
14.步骤s10:模型选择;采用双向长短时记忆网络-条件随机场模型结构;
15.步骤s20:语料标注;采用bio标注法作为语料的标注方法,其中b代表目标实体的起始字符;i代表目标实体词中的字符,包含实体词末尾位置;o代表不在目标实体中的字符;
16.步骤s30:训练;按照预设比例将标注文本分为训练集、测试集和验证集;以句为单位对标注文本进行划分,标注文本送入模型训练前需经过向量化,将文字与标注转化为计算机能够识别的字符代号,完成向量化,而后进行模型训练。
17.作为本发明的进一步改进:所述实体组合的流程包括:
18.步骤s100:实体组合;根据中文表述方法及语料标注特点进行实体组合,临床病历以句为单位经过实体提取后,得到实体的组合序列,按照规则对实体重组后得到最终的症状实体;
19.步骤s200:将症状实体转化为标准语句。
20.作为本发明的进一步改进:进行实体组合时,一个症状词有且只有一个sym实体,并包括有若干mod、body实体,词序不受限制。
21.作为本发明的进一步改进:进行实体组合时,语言的表述是连续的。
22.作为本发明的进一步改进:所述表型标准化的过程中,将病历中每个分句中的各症状类实体与每个标准化表型对应的症状类实体进行匹配,再获取综合匹配度。
23.作为本发明的进一步改进:所述匹配的流程包括:
24.(1)将各实体词转化为词向量的形式;
25.(2)对于每个病历分句,将病历分句中各症状类实体和标准化表型相同类型的实体词进行匹配,获得每种实体的匹配度,令病历分句中的症状为r,标准化表型为h,则实体间匹配采用余弦距离:
26.match(r,h,sym)=embed(symr)
·
embed(sym h)
27.match(r,h,body)=embed(bodyr)
·
embed(bodyh)
28.match(r,h,mod)=embed(modr)
·
embed(modh)
29.对于症状实体有多个实体词的情况,则先选出匹配最高的一对实体词,再选出匹配度次高的一对实体词,原来已经匹配过的实体词不再参与匹配,依次类推,最后该实体匹配度取多个实体词匹配度之和与1中较小的那个值:
[0030][0031]
若病历分句的症状r或标准化表型h中有一个或两者均无相应的症状实体,则实体的匹配度为一个很小的负值δ,缺省取δ=-0.00001;
[0032]
(3)获得综合匹配度:
[0033]
match(r,h)=γ1*match(r,h,sym) γ2*match(r,h,mod) γ3*match(r,h,mod)
其中:γ1、γ2、γ3均为大于0小于1的权重系数,且满足:γ1 γ2 γ3=1;
[0034]
(4)对于病历中的每个症状,输出与其最匹配的k个标准化hpo作为输出,供用户选择。
[0035]
与现有技术相比,本发明的优点就在于:
[0036]
1、本发明的中文电子病历中症状的标准化表型自动获取方法,原理简单、智能化程度高、精确性好、实用性强;本发明基于规则和人工智能的方法,实现了临床病例中症状类实体的提取及标准化工作。相比于传统的人工方法,本发明的方法提高了临床病历信息提取的效率,一定程度上提高了准确率,通过更换预测模型与相应的规则,可以实现不同类型的实体提取,有广泛的应用意义。
[0037]
2、本发明的中文电子病历中症状的标准化表型自动获取方法,采用一种组合方法,分阶段的使用否定域正则、神经网络模型、实体组合与字符匹配算法对临床病历分别进行否定域剔除、症状类实体(类型、部位、症状)提取、实体组合并对应到标准术语集等操作,最终实现了高效、准确、自动化的从临床病历中提取有效实体,并给出其对应的标准术语对象,提出去的标准术语可直接用于其他医疗分析流程。
[0038]
3、本发明的中文电子病历中症状的标准化表型自动获取方法,为一种基于bilstm-crf深度神经网络和多实体综合匹配相结合的方法,自动化地从中文临床病历中获得患者疾病症状的标准化表型,相比传统的人工方法,用本方法获取标准化表型不仅速度快,而且准确度高,大大提高了疾病辅助诊断类系统的使用效率。
附图说明
[0039]
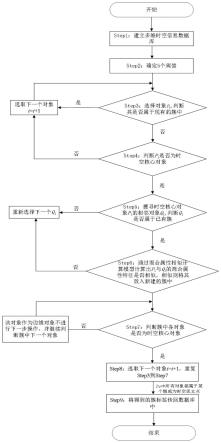
图1是本发明方法的流程示意图。
[0040]
图2是本发明方法在一个具体应用实例中的流程示意图。
具体实施方式
[0041]
以下将结合说明书附图和具体实施例对本发明做进一步详细说明。
[0042]
如图1和图2所示,本发明的中文电子病历中症状的标准化表型自动获取方法,包括:
[0043]
否定域剔除,将病历中与疾病无关的正常症状剔除;
[0044]
症状实体提取与组合,将疾病相关症状提取出来;
[0045]
表型标准化与匹配,将病历中的疾病症状与标准化表型进行匹配,确定哪些标准化表型与患者症状相关,获得的标准化表型作为医疗辅助诊断系统中患者表型的输入。
[0046]
在具体应用实例中,在进行否定域剔除过程中,否定域是指临床病历中存在的与患者疾病症状无关的词语或语句,否定域在病历中大量存在,这些描述属于正常描述,不是疾病状态的异常描述。
[0047]
在具体实例中,如下所示,该病历中下划线的部分均为否定域。
[0048]“患儿,男,6岁8月龄,因“2月内反复晕厥3次”就诊。每次晕厥发作于运动后出现,发作前无特殊不适,发作时伴有面色苍白、四肢发绀、小便失禁,持续1-2分钟自行好转,无高热、抽搐,无大汗、视物模糊,无步态不稳等,无特殊用药史,发病以来,精神、食纳、二便、体重无明显变化。出生史、个人史、既往史:无特殊。家族史:无晕厥、猝死、严重心脑血管疾
病史。查体:一般情况可,神清,皮肤未见明显皮疹,全身淋巴结无肿大,咽充血,双侧扁桃体i度肿大,无脓性分泌物,双肺呼吸音清晰,未闻及干湿啰音,心率66次/分,律齐,未闻及杂音,腹部无明显异常,神经系统检查无明显异常。”[0049]
采用本发明的否定域判定之后,剔除否定域后的上述病历的结果如下所示:
[0050]“[患儿,][男,][6岁8月龄,][因“2月内反复晕厥3次”就诊。][每次晕厥发作于运动后出现,][发作时伴有面色苍白、四肢发绀、小便失禁,][持续1-2分钟自行好转,][查体:咽充血,][双侧扁桃体i度肿大。]”[0051]
其中每个中括号内的内容表示一个病历分句。后续的症状实体提取与组合是对每个分句进行处理。
[0052]
在具体应用实例中,在进行症状类实体提取过程中,本发明将临床病历中的症状类实体分为修饰实体(mod)、部位(body)以及症状的表征实体(sym)三个细分种类,一个完整的症状类实体由表证词加上其他类型组成。
[0053]
在一个实例中如下所示:
[0054]
消化道(body)穿孔(sym)急性(mod)肠(body)梗阻(sym),消化道和肠为症状部位词(body),穿孔和梗阻为表征词(sym),急性则为症状修饰词(mod)。
[0055]
在具体应用实例中,采用深度神经网络的方法,即在进行症状类实体提取过程中,是使用词嵌入方法将临床病历文本向量化为输入特征,利用训练好的神经网络模型,实现对输入特征的类型判断,并将识别结果输出,从而实现症状类实体的自动提取。
[0056]
在具体应用实例中,症状类实体提取过程的详细流程包括:
[0057]
步骤s10:模型选择;
[0058]
实体提取属于分类任务,为了更好的理解输入文本,强化上下文关系,本发明采用bilstm-crf(双向长短时记忆网络-条件随机场)模型结构,bilstm除了正向运算外还添加了反向运算,从而能够更好的理解上下文关系,强化模型预测能力。
[0059]
步骤s20:语料标注;
[0060]
本发明采用bio标注法作为语料的标注方法,其中b(begin)代表目标实体的起始字符;i(inside)代表目标实体词中的字符,包含实体词末尾位置;o(out)代表不在目标实体中的字符。
[0061]
结合下表为例:
[0062]
表语料标注示例
[0063]
患有急性肠梗阻oob-modi-modb-bodyb-symi-sym
[0064]
步骤s30:训练;
[0065]
按照一定预设比例(例如7:2:1的比例)将标注文本分为训练集、测试集和验证集。以句为单位对标注文本进行划分,标注文本送入模型训练前需经过向量化,将文字与标注转化为计算机能够识别的字符代号,完成向量化,而后进行模型训练。
[0066]
例如,本发明在一个具体实践任务中,基于1200份临床病历、12000个标准表型,人工标记、人工审核形成了23万余行语料。
[0067]
采用本发明方法中的上述模型对三类实体(mod、body、sym)的识别精准率如下表所示:
[0068]
表 模型识别效果
[0069]
entity typeprecision/%recall/%fb1/%mod37.6643.9440.56body95.294.4994.84symptom92.3893.6393
[0070]
在具体应用实例中,所述实体组合与标准化的详细流程包括:
[0071]
步骤s100:实体组合;
[0072]
根据一般中文表述方法及语料标注特点,本发明总结出如下症状词组成特点:
[0073]
a)一个症状词有且只有一个sym实体,可以有若干mod、body实体,词序不受限制。
[0074]
b)语言的表述是连续的。
[0075]
为此,本发明总结了如下实体重组合规则,参见下表:
[0076]
表 实体重组规则
[0077]
原始序列重组序列说明mod body symmod body sym不变sym body modmod body sym改变实体顺序sym bodybody sym改变实体顺序sym modmod sym改变实体顺序mod bodybody sym将mod改为sym,并放后面body modbody sym将mod改为symmod body1 body2 symmod body1,body2 sym拆分为两个症状mod sym1 body sym2mod sym1,body sym2拆分为两个症状body1 mod body2 symmod body2 sym删除多余的body词body1 body2 ... bodyn symbody1 body2 ... bodyn sym不变
[0078]
由上可知,临床病历以句为单位经过实体提取后,得到三类实体的组合序列(mod、body、sym),按照上述规则对实体重组后得到最终的症状实体。
[0079]
如下表示例:
[0080]
表 实体重组示例
[0081][0082]
步骤s200:标准化;
[0083]
对症状实体进行标准化,首先是为了减轻由于中文的多义性所带来的理解差异。其次,将症状实体转化为标准术语也利于临床病历实体提取结果在不同工具、流程间的传播。
[0084]
在具体应用实例中,本发明将病历中的症状与标准化表型进行匹配,在匹配之前,先使用症状实体识别,将标准化表型中的实体识别出来,并使用实体重组规则,将所有标准化表型也按照该规则进行重组。
[0085]
在匹配过程中,本发明将病历中每个分句中的各症状类实体与每个标准化表型对应的症状类实体进行匹配,再获取综合匹配度。
[0086]
匹配过程如下:
[0087]
(1)将各实体词转化为词向量的形式;
[0088]
(2)对于每个病历分句,将病历分句中各症状类实体和标准化表型相同类型的实体词进行匹配,获得每种实体的匹配度,令病历分句中的症状为r,标准化表型为h,则实体间匹配采用余弦距离:
[0089]
match(r,h,sym)=embed(symr)
·
embed(symh)
[0090]
match(r,h,body)=embed(bodyr)
·
embed(bodyh)
[0091]
match(r,h,mod)=embed(modr)
·
embed(modh)
[0092]
对于某类症状实体有多个实体词的情况,则先选出匹配最高的一对实体词,再选出匹配度次高的一对实体词,原来已经匹配过的实体词不再参与匹配,依次类推,最后该实体匹配度取多个实体词匹配度之和与1中较小的那个值,如下所示。
[0093][0094]
若病历分句的症状r或标准化表型h中有一个或两者均无相应的症状实体,则实体的匹配度为一个很小的负值δ,缺省取δ=-0.00001;
[0095]
(3)获得综合匹配度:
[0096]
match(r,h)=γ1*match(r,h,sym) γ2*match(r,h,mod) γ3*match(r,h,mod)
[0097]
其中:γ1、γ2、γ3均为大于0小于1的权重系数,且满足:γ1 γ2 γ3=1。在本发明的方法中,默认γ1取0.6,γ2取0.3,γ3取0.1。
[0098]
(4)对于病历中的每个症状,输出与其最匹配的k个标准化hpo作为输出,供用户选择。对于无需用户手动选择hpo的系统,k值设为1。
[0099]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。