一种基于双经验池dqn的交通信号灯控制方法
技术领域
1.本发明属于交通信号灯控制技术领域,具体涉及一种基于双经验池深度q学习的交通信号灯控制方法。
背景技术:
2.采用基于深度q学习算法(dqn)进行交通信号灯的调控已有大量的研究。该方法无需带标签的测试数据,而是通过建立经验池来构建训练数据,在算法开始阶段得到的策略较差,随着经验池的不断更新和训练的继续进行,得到的策略逐渐得到优化,越来越好。因此,如何使算法快速收敛,即策略快速优化,是影响方法整体执行效果的重要因素。
技术实现要素:
3.发明目的:本发明提供一种基于双经验池dqn的交通信号灯控制方法,该方法能够使算法快速收敛,获得的交通信号灯控制策略快速优化。
4.技术方案:本发明采用如下技术方案:
5.一种基于双经验池dqn的交通信号灯控制方法,包括步骤:
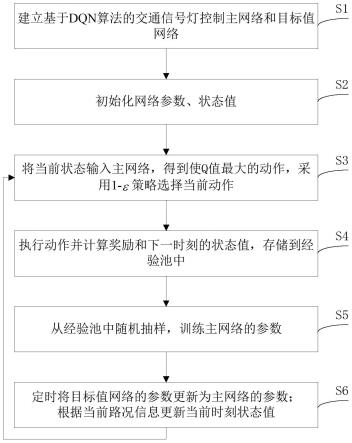
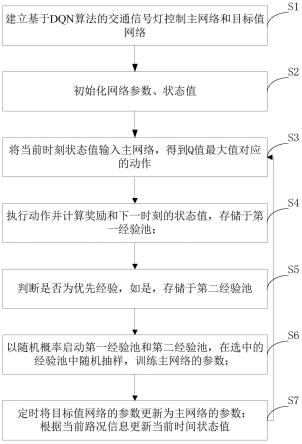
6.s1、建立基于dqn算法的交通信号灯控制主网络和目标值网络;所述交通信号灯控制主网络和目标值网络的结构相同,输入为状态值,输出为在输入状态值下执行各种动作的q值最大值,以及该q值最大值所对应的动作;所述主网络和目标值网络的状态空间为交通路口各车道上车辆的数量构成的向量,动作空间为对交通路口当前所有交通信号灯相位的调控操作构成的向量,奖励函数为交通路口所有进车道上车辆数量与出车道上车辆数量之差;
7.s2、对主网络的参数θ进行随机初始化,将目标值网络的参数θ
′
初始化为θ,初始化时间步t=0,采集交通路口的路况信息,建立初始状态值s
t
,初始化
8.s3、将s
t
输入主网络中,选择使q(s
t
,a;θ)取最大值的动作a
t
作为当前时间对交通信号灯的调控操作,即:a
t
=argmaxaq(s
t
,a;θ),其中q(s
t
,a;θ)表示主网络在参数θ下根据状态s
t
动作a输出的q值;
9.s4、执行动作a
t
并计算奖励r
t
和状态s
t 1
;将(s
t
,a
t
,r
t
,s
t 1
)存储到第一经验池中;
10.s5、当t>0时计算当前历史经验平均奖励如果将(s
t
,a
t
,r
t
,s
t 1
)存储到第二经验池中;
11.s6、在(p1,p2)区间内生成随机数p,以1-p作为概率选择第一经验池,以p作为概率选择第二经验池,在选中的经验池中随机抽样b个记录,通过最小化损失函数训练主网络的参数θ;p1,p2为预设的区间下限和上限,0<p1<p2<1;
12.所述损失函数为:
13.其中(si,ai,ri,s
i 1
)为在选中的经验池中随机抽样的记录,γ为折扣因子,maxa′q′
(s
i 1
,a
′
,θ
′
)表示目标值网络在输入状态s
i 1
时输出的最大的q值,maxaq(si,a,θ)表示主网
络在输入状态si时输出的最大的q值;
14.s7、令t加一,如果mod(t,c)为0,将目标值网络的参数θ
′
更新为主网络的参数θ;mod为取余运算,c为预设的参数更新时间步;根据当前路况信息更新s
t
,跳转至步骤s3继续执行。
15.进一步地,所述步骤s6采用梯度下降法最小化损失函数得到主网络的参数。
16.进一步地,当交通路口为十字路口,所述主网络和目标值网络的状态空间中的状态值为[n1,m1,n2,m2,n3,m3,n4,m4],其中nj为十字路口中第j个进车道上的车辆数量,mj为第j个出车道上的车辆数量;j=1,2,3,4。
[0017]
进一步地,所述主网络和目标值网络的动作空间中的动作值有三种取值,分别为:ac1:当前相位时长加t秒;ac2:当前相位时长减t秒;ac3:当前相位时长不变。本发明中,t为5秒。
[0018]
进一步地,本发明中生成随机数p的区间下限p1=0.7,区间上限p2=0.9。
[0019]
进一步地,奖励函数值为:
[0020]
进一步地,所述第一经验池和第二经验池均采用容量固定的队列存储记录。
[0021]
进一步地,所述步骤s5计算当前历史经验平均奖励
[0022]
有益效果:本发明公开的交通信号灯控制方法采用双经验池和dqn相结合,其中双经验池机制能够使网络参数训练快速收敛,获得的交通信号灯控制策略快速优化,从而更好地实现交通灯的智能调控。
附图说明
[0023]
图1为本发明公开的交通信号灯控制方法的流程图;
[0024]
图2为实施例中路口示意图;
[0025]
图3为本发明网络架构示意图。
具体实施方式
[0026]
下面结合附图和具体实施方式,进一步阐明本发明。
[0027]
本发明公开了一种基于双经验池dqn的交通信号灯控制方法,如图1所示,包括步骤:
[0028]
s1、建立基于dqn算法的交通信号灯控制主网络和目标值网络;所述交通信号灯控制主网络和目标值网络的结构相同,输入为状态值,输出为在输入状态值下执行各种动作的q值;所述主网络和目标值网络的状态空间为交通路口各车道上车辆的数量构成的向量,动作空间为对交通路口当前所有交通信号灯相位的调控操作构成的向量,奖励函数为交通路口所有进车道上车辆数量与出车道上车辆数量之差;
[0029]
当交通路口为十字路口时,如图2中的路口a所示,其四个路口均有进入路口和驶离路口的车道,如图中n1-n4为进入路口的车道,m1-m4为驶离路口的车道,则主网络和目标值网络的状态空间中的状态值为[n1,m1,n2,m2,n3,m3,n4,m4],其中nj为十字路口中第j个进车道上的车辆数量,mj为第j个出车道上的车辆数量;j=1,2,3,4。可以通过各个方向道路
设置的传感器或摄像头捕捉上述数据。奖励函数值为:即进车道上车辆数量与出车道上车辆数量之差。网络和目标值网络的动作空间中的动作值有三种取值,分别为:ac1:当前相位时长加t秒;ac2:当前相位时长减t秒;ac3:当前相位时长不变,即按照预设的交通信号灯相位变化来改变当前相位的状态。
[0030]
s2、对主网络的参数θ进行随机初始化,将目标值网络的参数θ
′
初始化为θ,初始化时间步t=0,采集交通路口的路况信息,建立初始状态值s
t
,初始化
[0031]
s3、将s
t
输入主网络中,选择使q(s
t
,a;θ)取最大值的动作a
t
作为当前时间对交通信号灯的调控操作,即:a
t
=argmaxaq(s
t
,a;θ),其中q(s
t
,a;θ)表示主网络在参数θ下根据状态s
t
动作a输出的q值;
[0032]
s4、执行动作a
t
并计算奖励r
t
和状态s
t 1
;将(s
t
,a
t
,r
t
,s
t 1
)存储到第一经验池中;
[0033]
s5、当t>0时计算当前历史经验平均奖励如果将(s
t
,a
t
,r
t
,s
t 1
)存储到第二经验池中;
[0034]
当前历史经验平均奖励即根据上一时间步的平均奖励和当前时间步数t和奖励r
t
来计算。
[0035]
本发明中第一经验池和第二经验池均采用容量固定的队列存储记录,当满队时,将队头的记录删除,新的记录存储至队尾,以此来更新经验池。
[0036]
s6、在(p1,p2)区间内生成随机数p,以1-p作为概率选择第一经验池,以p作为概率选择第二经验池;在选中的经验池中随机抽样b个记录,通过最小化损失函数训练主网络的参数θ;p1,p2为预设的区间下限和上限,0<p1<p2<1。本实施例中,p1=0.7,p2=0.9,即选择第二经验池的概率大于第一经验池。由于第二经验池中的记录奖励较大,其表现优于第一经验池,采用第二经验池内的记录训练能够加快收敛速度。同时保留了以较低概率(1-p)选择第一经验池,是为了降低网络进入过拟合的概率。
[0037]
所述损失函数为:
[0038]
其中(si,ai,ri,s
i 1
)为在选中的经验池中随机抽样的记录,γ为折扣因子,maxa′q′
(s
i 1
,a
′
,θ
′
)表示目标值网络在输入状态s
i 1
时输出的最大的q值,maxaq(si,a,θ)表示主网络在输入状态si时输出的最大的q值;
[0039]
本实施例中,采用梯度下降法最小化损失函数得到主网络的参数。如图3所示,为本发明网络架构示意图。
[0040]
s7、令t加一,如果mod(t,c)为0,将目标值网络的参数θ
′
更新为主网络的参数θ;mod为取余运算,c为预设的参数更新时间步;根据t-1时刻和t时刻之间的时长、c的值,可以控制目标值网络参数更新的频率;根据当前路况信息更新s
t
,跳转至步骤s3继续执行。
[0041]
本发明采用的双经验池的形式,加快了dqn训练时网络的收敛速度,从而更好地缓解了交通拥堵的情况,推进了智能交通和深度强化学习领域的发展。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。