基于xception网络改进的手势图像特征提取方法
技术领域
1.本发明涉及一种手势图像的提取方法,具体涉及了一种基于xception网络所改进的手势图像特征提取方法。
背景技术:
2.手势识别是近年来大热的人机交互方式,广泛应用在手语识别、车辆自动驾驶和虚拟现实等各个领域。其研究发展给人们的生活带来了极大的便利性,存在着巨大的社会价值,它逐渐改变着人们的生活方式。传统的手势识别主要是基于硬件设备,通过穿戴的硬件设备上的感应器检测手部的各种动作,这些可穿戴设备的复杂性以及昂贵性,使这种识别方法不能很好地普及。近年来手势识别技术从可穿戴设备转向机器视觉的手势识别方法以及基于深度学习的手势识别方法两大类。基于机器视觉的手势特征融合方法能在一定程度上实现对复杂手势特征提取和融合,但是这种方法受光照和背景的影响较大,难以精确识别手势图像,且处理速度较慢。目前基于深度学习的手势图像识别方法逐渐成为主流,卷积神经网络具有权值共享,局部感知,平移不变性等特征,能够快速提取目标手势图像的重要特征,但通过单一卷积神经网络难以提取到多种复杂背景下手势图像的多尺度特征,准确率表现不佳。
技术实现要素:
3.针对传统手势图像特征融合与识别方法得到的特征难以精确识别类肤色复杂背景下的手势图像,xception网络参数量庞大,不能较好地应用到移动端进行手势识别,xception缺少融合多尺度特征识别等问题,本发明的目的在于提出一种适应多种复杂背景下手势图像特征有效提取与融合方法,能够满足应用到移动端进行手势图像识别需求的小型深度学习网络。
4.本发明含有密集深度可分离卷积模块,能够对特征张量中空间相关性和跨通道相关性完全解耦,并通过特征再利用密集减小网络的深度,减少网络的计算参数量,抑制过拟合,同时融合压缩激励模块和特征金字塔结构,重标定各个通道的权重,强化重要特征,融合多尺度特征信息,提高模型的性能,进而提高了手势识别的准确率。
5.本发明的技术方案包括如下步骤:
6.1)对手势进行图像采集获得原始图像,对原始图像进行尺寸归一化和标准化处理获得原始手势图像;
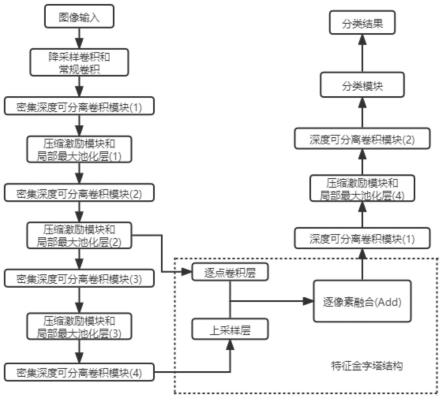
7.2)构建卷积神经网络,包括浅层特征提取结构、深层特征提取结构、特征金字塔结构、高阶特征提取结构和输出结构;
8.浅层特征提取结构主要由降采样卷积模块和常规卷积模块组成;深层特征提取结构包括四个依次连接的密集深度可分离卷积模块和三个依次连接的压缩激励模块,相邻两个密集深度可分离卷积模块之间连接有一个压缩激励模块,每个压缩激励模块经局部最大池化层后输出;特征金字塔结构包括逐点卷积层和上采样层;高阶特征提取结构包括依次
连接的深度可分离卷积模块、压缩激励模块和局部最大池化层;输出结构包括依次连接的深度可分离卷积模块和分类模块;
9.3)将原始手势图像输入卷积神经网络进行特征提取,输出分类结果;所述步骤3)具体为:
10.3.1)浅层特征提取结构:原始手势图像经过降采样卷积模块降低维度,再经常规卷积模块提取浅层特征,得到浅层特征张量;
11.3.2)深层特征提取结构:
12.浅层特征张量依次通过四个密集深度可分离卷积模块,密集深度可分离卷积模块对特征张量中空间相关性和跨通道相关性完全解耦;其中,压缩激励模块对输入的特征进行重标定后再经局部最大池化层缩小尺寸;
13.3.3)特征金字塔结构:
14.第四个密集深度可分离卷积模块的输出经上采样层扩大尺度得到第一融合特征张量,第二个压缩激励模块经局部最大池化层的输出经逐点卷积层改变通道数得到第二融合特征张量,两个融合特征张量进行逐像素叠加操作,得到特征金字塔结构的输出;
15.3.4)高阶特征提取结构:
16.融合多尺度特征的张量依次经过深度可分离卷积模块、压缩激励模块和局部最大池化层,得到高阶多维特征张量;
17.3.5)输出结构:
18.高阶多维特征张量经过深度可分离卷积模块和分类模块得到手势图像的分类结果。
19.所述的浅层特征提取结构中:
20.降采样卷积模块主要由进行降采样的步长为2
×
2的卷积层、批量归一化层和relu激活层依次连接组成,具体由以下公式设置表示:
[0021][0022]
常规卷积模块主要由步长为1
×
1的卷积层、批量归一化层和relu激活层依次连接组成,具体由以下公式设置表示:
[0023][0024]
其中,f1表示降采样卷积模块,f2表示常规卷积模块;z代表输入的图像,代表卷积核尺寸为i
×
i,步长为n的卷积函数,bn(*)代表批量归一化函数,δ(*)代表relu激活函数。
[0025]
所述的密集深度可分离卷积模块主要由多个深度可分离卷积模块密集连接组成,密集连接表示每个深度可分离卷积模块的输入为密集深度可分离卷积模块的输入和所有前继深度可分离卷积模块的输出张量经通道叠加形成;前继深度可分离卷积模块为当前深度可分离卷积模块之前的所有深度可分离卷积模块;具体公式设置如下:
[0026][0027]
其中,x0表示密集深度可分离卷积模块的输入,x
l
表示第l个深度可分离卷积模块的输出,表示通道维度上的叠加,f3(*)表示深度可分离卷积模块。
[0028]
密集连接能够压缩网络的深度,得到包含丰富特征语义信息的深层特征张量。
[0029]
四个依次连接的密集深度可分离卷积模块中:前三个密集深度可分离卷积模块由三个深度可分离卷积模块密集连接组成,第四个密集深度可分离卷积模块由两个深度可分离卷积模块密集连接组成;
[0030]
密集深度可分离卷积模块的深度可分离卷积模块f3主要由relu激活层、深度可分离卷积层和批量归一化层依次连接组成,具体由以下公式设置表示:
[0031][0032]
其中,z代表输入的图像,δ(*)代表relu激活函数,代表卷积核尺寸为i
×
i,步长为n的深度可分离卷积函数,bn(*)代表批量归一化函数;
[0033]
高阶特征提取结构中的深度可分离卷积模块主要由深度可分离卷积层、relu激活层和批量归一化层依次连接组成。
[0034]
所述的压缩激励模块包括压缩模块f
sq
、激励模块f
ex
和重标定模块f
scale
,主要由全局平均池化层、全连接层、relu激活层、全连接层、sigmoid激活层依次连接组成;具体由以下公式设置表示:
[0035]fsa
(z)=gap(z)
[0036]fex
(x)=σ(w(δ(w(x))))
[0037]fscale
(q,d)=q
×d[0038]
其中,z代表输入的图像,gap(*)代表全局平均池化函数,x代表压缩模块获得的全局描述,w(*)全连接函数,δ(*)代表relu激活函数,σ(*)代表sigmoid激活函数,q代表输入压缩激励模块的特征张量,d代表激励模块获得的各个通道的权重(激励模块的输出);
[0039]
重标定模块f
scale
的输出再经局部最大池化层输出。
[0040]
所述特征金字塔结构中:上采样层采用最近邻插值算法。
[0041]
所述输出结构中的分类模块包括依次连接的全局平均池化层、全连接层和softmax分类器。
[0042]
本发明的有益效果:
[0043]
(1)本发明提出了密集深度可分离卷积模块,由多个深度可分离卷积模块通过密集连接组成,深度可分离卷积由逐点卷积和深度卷积组成,对空间相关性和跨通道相关性完全解耦,深度可分离卷积模块之间通过特征再利用进行密集连接,最大化保证层级之间的信息流动,可以大大减小网络的深度,减少模型的计算参数量,加快模型收敛的速度,使网络模型在深度较小时就能达到极高的手势图像识别率。
[0044]
(2)本发明嵌入了压缩激励模块,利用注意力机制的思想,显式建模特征通道之间的相互依赖关系,对特征张量的各个通道重新分配权重,强化重要特征,抑制次要特征,增强网络模型对于重要特征的敏感性,有效帮助网络模型学习手势图像的重要特征,提高模型的性能。
[0045]
(3)本发明采用了特征金字塔结构,融合浅层特征张量与深层特征张量的空间几何特征信息和特征语义信息,采用逐像素叠加融合,通过不同感受野的融合使用,有效提取不同大小手势目标的重要特征,产生多尺度的特征表示,进一步提高对不同大小手势目标的识别准确率。
附图说明
[0046]
图1为本发明的技术方案流程图;
[0047]
图2为本发明方法所用到的手语数据集的部分手势图像;
[0048]
图3为本发明采用的降采样卷积模块和常规卷积模块结构示意图;
[0049]
图4为本发明采用的密集深度可分离卷积模块结构示意图;
[0050]
图5为本发明采用的深度可分离卷积模块结构示意图;
[0051]
图6为本发明采用的压缩激励模块和局部最大池化层结构示意图;
[0052]
图7为本发明采用的分类模块结构示意图;
[0053]
图8为模块消融实验中测试集平均准确率的对比结果图;
[0054]
图9为模块消融实验中参数量的对比结果图。
具体实施方式
[0055]
下面结合附图和实施例对本发明做进一步说明。
[0056]
本发明的技术方案流程图如图1所示。
[0057]
本发明所使用的数据集是开源的nus hand posture dataset
‑ⅱ
(national university of singapore)手势数据集,该数据集的部分手势图像如图2所示。该手势数据集是由40名年龄在22~56岁的不同种族的男性和女性在不同复杂背景下拍摄完成,共包含10类手势,采集者的肤色存在巨大差异且存在类肤色背景因素的干扰。该数据集包括两个子集,一个子集是在不同自然背景下制作完成的,共有2000幅rgb图像,另一个子集包含类肤色背景因素的干扰,背景包含人脸和行人等,共有750幅rgb图像,实验中将两个子集中的所有手势图像合并为一个数据集,按照7:2:1的比例将数据集随机划分为训练集、测试集和验证集,并使用随机旋转、平移等实时数据增强方式来避免过拟合。
[0058]
本发明的具体技术方案如下:
[0059]
1)将原始手势图像尺寸归一化为224
×
224
×
3的rgb图像,再对原始手势图像进行标准化,将原始手势图像从0~255之间的整数映射到0~1之间的浮点数作为神经网络的输入。
[0060]
2)将标准化的手势图像输入图3所示的降采样卷积模块和常规卷积模块中,降采样卷积模块和常规卷积模块的结构相同,都是卷积层、批量归一化层和relu激活层依次连接,两个模块的区别仅仅是卷积层的步长不同,降采样卷积模块的卷积层步长为2
×
2,起到缩小特征张量尺寸,降低维度,提取显著特征,缓解过拟合的作用;常规卷积模块的卷积层步长为1
×
1,起到整合空间和通道信息,提取浅层特征的作用。
[0061]
降采样卷积模块卷积层的卷积核尺寸为3
×
3,卷积核个数为32,标准化的手势图像输入降采样卷积模块得到尺寸为112
×
112
×
32的特征张量;常规卷积模块卷积层的卷积核尺寸为3
×
3,卷积核个数为64,输出尺寸为112
×
112
×
64的浅层特征张量。
[0062]
3)如图4所示,浅层特征张量依次输入四个密集深度可分离卷积模块,前三个密集深度可分离卷积模块包括三个深度可分离卷积模块,第四个密集深度可分离卷积模块包括两个深度可分离卷积模块,图4中x0表示输入密集深度可分离卷积模块的特征张量,x
l
表示密集深度可分离卷积模块中第l个深度可分离卷积模块的输出特征张量,密集深度可分离卷积模块通过所有前馈深度可分离卷积模块的输出特征再利用,每个深度可分离卷积模块
与前馈模块直接相连接,保证各个层际之间最大化的信息流动,能够密集压缩网络的深度,抑制过拟合,在网络模型深度较小下提高手势识别的准确率。
[0063]
密集深度可分离卷积模块中使用的深度可分离卷积模块结构如图5所示,深度可分离卷积模块中的深度可分离卷积层实际上是由两个卷积操作组成,先对特征张量进行逐点卷积,再进行深度卷积,这样做能够使特征张量中空间相关性和跨通道相关性完全解耦,使模型参数更有效地被网络模型使用,提高网络模型的性能。
[0064]
第一个密集深度可分离卷积模块包含的三个深度可分离卷积模块中的深度可分离卷积层的卷积核尺寸都是3
×
3,卷积核个数都是128(实际上是逐点卷积卷积核个数是128,深度卷积卷积核尺寸是3
×
3),第二个密集深度可分离卷积模块包含的三个深度可分离卷积模块中的深度可分离卷积层的卷积核尺寸都是3
×
3,卷积核个数都是256,第三个密集深度可分离卷积模块包含的三个深度可分离卷积模块中的深度可分离卷积层的卷积核尺寸都是3
×
3,卷积核个数都是512,前三个密集深度可分离卷积模块的输出张量直接与压缩激励模块和局部最大池化层连接。
[0065]
压缩激励模块和局部最大池化层的结构示意图如图6所示,输入尺寸为h
×w×
c的特征张量,经过全局平均池化层得到相对于每一个通道的全局描述,尺寸为1
×1×
c,它表征着在特征通道上响应的全局分布,接着经过两个全连接层去建模通道间的相关性,首先将通道数量降低到输入的1/16,然后通过relu激活,再通过一个全连接层恢复为原来的通道数量,使用sigmoid激活函数返回对应于每一个通道的0~1之间的归一化权重,最后通过一个重标定操作将归一化后的权重加权到每一个通道的特征上并利用局部最大池化层进一步缩小特征张量的尺寸,提高感受野,使用两层全连接层的作用在于1)具有更多的非线性,可以更好地拟合通道间复杂的相关性,2)极大地减少模型的计算参数量。第一个压缩激励模块和局部最大池化层输出尺寸为56
×
56
×
128的特征张量,第二个压缩激励模块和局部最大池化层输出尺寸为28
×
28
×
256的特征张量,第三个压缩激励模块和局部最大池化层输出尺寸为14
×
14
×
512的特征张量。
[0066]
4)第四个密集深度可分离卷积模块的第一个深度可分离卷积模块的深度可分离卷积层的卷积核尺寸为3
×
3,卷积核个数为512,第二个深度可分离卷积模块的深度可分离卷积层的卷积核尺寸为3
×
3,卷积核个数为728,输出张量不直接与压缩激励模块和局部最大池化层连接,而是输入特征金字塔结构中经过上采样层输出尺寸为28
×
28
×
728的特征张量,作为第一融合特征张量,第二个压缩激励模块和局部最大池化层的输出张量经过逐点卷积改变通道数得到尺寸为28
×
28
×
728的特征张量,作为第二融合特征张量,如图1所示,两个融合特征张量进行逐像素叠加操作,得到特征金字塔结构尺寸为28
×
28
×
728的输出张量,特征金字塔结构的输出张量具有网络模型浅层的空间几何信息和深层的丰富特征语义信息,能够更容易提取到不同大小手势目标的有效特征信息,能够更好地适应目标手势大小不同的图像识别,提高手势识别的准别率。
[0067]
5)如图1所示,特征金字塔结构的输出张量依次输入第一个深度可分离卷积模块、第四个压缩激励模块和局部最大池化层和第二个深度可分离卷积模块,与密集深度可分离卷积模块中的深度可分离卷积模块略有不同的是此处的两个深度可分离卷积模块结构中的relu激活层和深度可分离卷积层互换了位置,有助于手势图像的分类,第一个深度可分离卷积模块的输出尺寸为28
×
28
×
1024的特征张量,第四个压缩激励模块和局部最大池化
层的输出尺寸为14
×
14
×
1024的特征张量,第二个深度可分离卷积模块输出尺寸为14
×
14
×
512的特征张量。
[0068]
6)最终,将包含多尺度信息的高维度特征张量输入分类模块,分类模块的结构如图7所示,特征张量在分类模块中经过全局平均池化层之后再通过一个全连接层,将通道数映射到10,最后输入softmax分类器中,获得手势图像的分类结果。
[0069]
如图8和图9所示,网络1为xception网络,网络2为使用压缩激励模块的改进xception网络,网络3为使用特征金字塔结构的改进xception网络,网络4为使用密集深度可分离卷积模块的改进xception网络,网络5为本发明方法改进的xception网络,网络1的参数量为2.09e 07,平均准确率达98.54%,网络2的参数量为3.50e 06,平均准确率达99.09%,网络3的参数量为3.58e 06,平均准确率达99.27%,网络4的参数量为4.53e 06,平均准确率达99.45%,网络5的参数量为4.31e 06,平均准确率达99.64%。
[0070]
将本发明网络与常用手势识别网络resnet50和densenet121在本发明所使用的是数据集上训练40个迭代周期,并在测试集上验证,比较模型之间的训练时间、模型大小、参数量和在测试集上的平均准确率,结果见表1。
[0071]
表1常用手势识别网络模型在本发明使用的数据集上的模型训练时间、模型大小、模型参数量和在测试集上的平均准确率结果对比情况
[0072][0073]
通过实验可以验证,本发明中设计的密集深度可分离卷积模块能够压缩网络的深度,从而减少网络模型的计算参数量,保证最大化层际之间的信息流动,同时其中的深度可分离卷积模块将空间相关性和跨通道相关性完全解耦,使网络参数更加有效地被利用,显著提高了手势识别的准确率,本发明中融合的压缩激励模块和特征金字塔结构能够强化重要特征,抑制次要特征,融合多尺度信息,获得不同感受野,有效提取不同大小手势目标的特征,提高了识别准确率。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。