1.本发明属于水文数据挖掘技术,具体涉及一种基于加权相关马氏距离的水文时间序列模式库构建方法。
背景技术:
2.随着大数据时代的蓬勃发展,水文数据挖掘受到的重视程度也越来越高,水文数据包括了流域流量信息,测站雨量信息等重要数据,在环境、地理、以及人类活动的影响下,这些信息之间必然存在着一些规律。如何从这些数据当中挖掘出一些有利的信息以及它们之间相关的联系,并参照它们的发展规律发现序列的演变趋势同时将之应用于水文预报当中是当下研究的重点之一。
3.数据挖掘又称之为知识发现,是指从大量数据中抽取出那些隐含的、令人感兴趣的、有价值的知识的过程。数据挖掘是数据库技术的深层次应用,可以进一步提高信息资源的使用价值和使用效益,能更好的解决日益复杂多变的决策问题,进一步提高了决策的准确性和可靠性,为科学决策提供依据。在水文领域应用数据挖掘技术有着十分重要的意义,数据挖掘技术可以从海量的数据当中寻找出有用的信息,并构建准确的模型,因此研究数据挖掘技术以及方法,为水文科学的发展延伸了一个全新的方向。数据挖掘是构建模式库的方法,从大量时间序列中找到它们之间相似的规律,并把相似规律进行聚类得到的集合称为模式库。
4.目前,中小河流水文时间序列模式库构建方法大多是基于一元水文时间序列,多元水文时间序列模式库构建方法较少,因此提出一种中小河流多元水文时间序列模式库构建方法是十分有意义的。
技术实现要素:
5.发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于加权相关马氏距离的水文时间序列模式库构建方法,通过数据挖掘的相关技术,对多元水文时间序列进行相似性分析和聚类。
6.技术方案:本发明的一种基于加权相关马氏距离的水文时间序列模式库构建方法,包括以下步骤:
7.步骤s1、对原始多元水文时间序列进行数据预处理,补全水文时间序列当中的空缺值。
8.步骤s2、利用分段线性表示(paa)方法,将多元时间序列分段,对于每一个特征,提取每个分段子序列的平均值,然后把每个分段的所有特征的特征向量进行组合形成多元时间序列特征向量,这种做法不但能抓取时间序列的主要特征,而且也降低了时间序列的维度。
9.步骤s3、对马氏距离进行优化,使用critic权重法对不同时间序列的协方差矩阵中的变量加权处理,对加权后的矩阵求平均矩阵得到加权相关协方差矩阵,将加权相关协
方差矩阵替代马氏距离中的协方差矩阵获得加权相关马氏距离。
10.步骤s4、在获取多元时间序列的特征向量之后,使用基于加权相关马氏距离的层次聚类算法对数据集中的特征向量聚类并符号化表示,记录每个符号之间的距离构建符号距离表。
11.步骤s5、利用动态时间弯曲距离算法计算符号化表示的时间序列之间的距离值,其中依据符号距离表替换动态时间弯曲距离算法中的欧氏距离度量,根据距离值进行聚类构建多元水文时间序列模式库。
12.进一步,所述步骤s3中对马氏距离进行优化得到加权相关马氏距离的具体步骤为:
13.步骤s3.1、输入多元时间序列数据集r={x1,x2,x3,...,x
t
,将数据集r中的所有多元时间序列标准化预处理,去除序列中每个特征之间的量纲影响。
14.步骤s3.2、计算数据集r中所有多元时间序列的协方差矩阵,设其特征维度依次记为x,y,z,记为u={m1,m2,m3,...,mi,...,mn},其表达式为:
[0015][0016]
该矩阵中cov(x,y)表示特征x与y的协方差,其计算公式为:
[0017][0018]
其中各维度的数据长度为n,表示x特征的平均值,表示y特征的平均值。
[0019]
步骤s3.3、对于需要计算的时间序列特征向量k1、k2,它们属于两个不同的时间序列数据集x
p
、xq,其对应的协方差矩阵为m
p
、mq,利用critic权重法计算出各个指标的权重,critic权重法是一种利用数据波动性大小计算权重的方法,它有两个指标分别为对比强度与冲突性指标,使用标准差表示对比强度指标,计算公式如下:
[0020][0021]
其中,表示第t个变量的平均值,s
t
表示第t个变量的标准差,n表示矩阵的行数,如果数据标准差越小则说明波动越小,权值也越小,使用相关系数表冲突性指标,计算公式如下:
[0022][0023]
其中,r
t
表示第t个变量的冲突性指标,r
gt
表示第g个变量与第t个变量之间的相关系数,如果与其他变量的相关系数值越小,说明冲突性越大,权值则越大,计算权值时,将对
比强度s
t
与冲突性指标r
t
相乘获得信息量f
t
,则第t个变量的权重计算公式为:
[0024][0025]
将计算出的权值与协方差矩阵中对应的变量相乘并替换原始协方差矩阵中的数据,最后对加权后的两个协方差矩阵求平均矩阵获得加权相关协方差矩阵。
[0026]
步骤s3.4、将马氏距离公式中的协方差矩阵替换成加权相关协方差矩阵计算多元特征向量之间的加权相关马氏距离,马氏距离如下:
[0027][0028]
其中s-1
为协方差矩阵,gi,gj为样本向量。
[0029]
进一步,所述步骤s4的详细内容为:
[0030]
步骤s4.1、获得将全部的多元时间序列特征向量视为单独的类,分别计算类与类之间的加权相关马氏距离。
[0031]
步骤s4.2、将加权相关马氏距离数值最小的两个类归并成一个新类。
[0032]
步骤s4.3、继续计算新类与其它类之间的距离。
[0033]
步骤s4.4、重复操作步骤s4.2与s4.3,当聚类稳定以后停止重复操作。
[0034]
步骤s4.5、输出聚类的结果和聚类中心。
[0035]
步骤s4.6、根据聚类中心的每个特征向量,计算两两特征向量之间的加权相关马氏距离作为相应符号之间的距离,从而构建符号距离表。
[0036]
步骤s4.7、对聚类中心赋予符号,属于同一类的特征向量符号一致,最终将多元特征向量符号化。
[0037]
有益效果:与现有技术相比,本发明具有以下优点。
[0038]
(1)本发明中对马氏距离进行改进优化,将各多元时间序列集合之间的协方差矩阵关联性以及协方差矩阵中各个维度之间的协方差在计算过程中的影响程度考虑在内,让马氏距离可以度量不同多元时间序列之间的相似性。
[0039]
(2)本发明层次聚类算法进行改进优化,将其中的相似性度量方法换为加权相关马氏距离,提高了多元时间序列聚类的准确性。
附图说明
[0040]
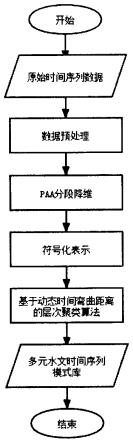
图1为本发明中模式库构建方法的整体工作流程图。
[0041]
图2为本发明中基于加权相关马氏距离的层次聚类算法的工作流程图。
[0042]
图3为模式库中一种模式的结果图。
[0043]
图4为模式库中一种模式的结果图。
[0044]
图5为本发明与其他模式库构建方法的聚类准确性对比图。
具体实施方式
[0045]
下面对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
[0046]
如图1所示,本实施例的一种基于加权相关马氏距离的水文时间序列模式库构建方法,包括以下步骤:
[0047]
步骤s1、选取屯溪流域的屯溪水文测站流量数据以及屯溪流域的时段降雨量数据作为实验数据,对原始多元水文时间序列进行数据预处理,补全水文时间序列当中的空缺值。
[0048]
步骤s2、利用分段线性表示(paa)方法,将多元时间序列分段,对于每一个特征,提取每个分段子序列的平均值,然后把每个分段的所有特征的特征向量进行组合形成多元时间序列特征向量,这种做法不但能抓取时间序列的主要特征,而且也降低了时间序列的维度。
[0049]
步骤s3、对马氏距离进行优化,使用critic权重法对不同时间序列的协方差矩阵中的变量加权处理,对加权后的矩阵求平均矩阵得到加权相关协方差矩阵,将加权相关协方差矩阵替代马氏距离中的协方差矩阵获得加权相关马氏距离。
[0050]
步骤s4、如图2所示,在获取多元时间序列的特征向量之后,使用基于加权相关马氏距离的层次聚类算法对数据集中的特征向量聚类并符号化表示,记录每个符号之间的距离构建符号距离表。
[0051]
步骤s5、利用动态时间弯曲距离算法计算符号化表示的时间序列之间的距离值,其中依据符号距离表替换动态时间弯曲距离算法中的欧氏距离度量,根据距离值进行聚类构建多元水文时间序列模式库。
[0052]
实施例1:本实施例对安徽省屯溪流域的屯溪水文测站流量数据以及屯溪流域的时段降雨量数据进行模式库构建,如图2和图3所示,包括以下步骤:
[0053]
步骤s1、本实施例数据集选取安徽省屯溪流域屯溪水文站2008年至2020年的洪水场次的每小时流量数据以及屯溪流域2008年至2020年的洪水场次的每小时的时段降雨量,时段降雨量指同一流域当中所有雨量站相同时间段降雨量的总和,将实例数据进行预处理补全水文时间序列当中的空缺值。
[0054]
步骤s2、利用分段线性表示(paa)方法,将多元时间序列分段,对于每一个特征,提取每个分段子序列的平均值,设置子序列分段数目为9,然后把每个分段的所有特征的特征向量进行组合形成多元时间序列特征向量。
[0055]
步骤s3.1、输入多元时间序列数据集r={x1,x2,x3,...,x
t
,将数据集r中的所有多元时间序列标准化预处理,去除序列中每个特征之间的量纲影响。
[0056]
步骤s3.2、计算数据集r中所有多元时间序列的协方差矩阵,设其特征维度依次记为x,y,z,记为u={m1,m2,m3,...,mi,...,mn},其表达式为:
[0057][0058]
该矩阵中cov(x,y)表示特征x与y的协方差,其计算公式为:
[0059]
[0060]
其中各维度的数据长度为n,表示x特征的平均值,表示y特征的平均值;
[0061]
步骤s3.3、对于需要计算的时间序列特征向量k1、k2,它们属于两个不同的时间序列数据集x
p
、xq,其对应的协方差矩阵为m
p
、mq,利用critic权重法计算出各个指标的权重,critic权重法是一种利用数据波动性大小计算权重的方法,它有两个指标分别为对比强度与冲突性指标,使用标准差表示对比强度指标,计算公式如下:
[0062][0063]
其中,表示第t个变量的平均值,s
t
表示第t个变量的标准差,n表示矩阵的行数,如果数据标准差越小则说明波动越小,权值也越小,使用相关系数表示冲突性指标,计算公式如下:
[0064][0065]
其中,r
t
表示第t个变量的冲突性指标,r
gt
表示第g个变量与第t个变量之间的相关系数,如果与其他变量的相关系数值越小,说明冲突性越大,权值则越大,计算权值时,将对比强度s
t
与冲突性指标r
t
相乘获得信息量f
t
,则第t个变量的权重计算公式为:
[0066][0067]
将计算出的权值与协方差矩阵中对应的变量相乘并替换原始协方差矩阵中的数据,最后对加权后的两个协方差矩阵求平均矩阵获得加权相关协方差矩阵;
[0068]
步骤s3.4、将马氏距离公式中的协方差矩阵替换成加权相关协方差矩阵计算多元特征向量之间的加权相关马氏距离,马氏距离如下:
[0069][0070]
其中s-1
为协方差矩阵,gi,gj为样本向量。
[0071]
步骤s4.1、将全部的多元时间序列特征向量视为单独的类,根据加权相关马氏距离公式计算类与类之间的加权相关马氏距离。
[0072]
步骤s4.2、将加权相关马氏距离数值最小的两个类归并成一个新类。
[0073]
步骤s4.3、继续计算新类与其它类之间的距离。
[0074]
步骤s4.4、重复操作步骤s4.2与s4.3,当聚类稳定以后停止重复操作。
[0075]
步骤s4.5、输出聚类的结果和聚类中心。
[0076]
步骤s4.6、根据聚类中心的每个特征向量,计算两两特征向量之间的加权相关马氏距离作为相应符号之间的距离,从而构建符号距离表。
[0077]
步骤s4.7、对聚类中心赋予符号,属于同一类的特征向量符号一致,最终将多元特征向量符号化。
[0078]
步骤s5、利用动态时间弯曲距离算法计算符号化表示的时间序列之间的距离值,其中依据符号距离表替换动态时间弯曲距离算法中的欧氏距离度量,根据距离值进行聚类构建多元水文时间序列模式库。
[0079]
利用一致性字符串方法表示各类中的模式,模式中各个字符所表示的值规则如下:对于类中位于相同列的字符,将每个字符表示的原始水文时间序列值一一相加再求其平均值,该平均值作为模式对应列字符的值。模式库构建结果中部分模式如图3和图4所示。图中有两个纵坐标,左边的纵坐标代表该模式某一时刻的时段降雨量,右边纵坐标代表该模式的流量值,柱状图表示同一时刻流域时段降雨量,线状图表示测站流量。
[0080]
本实例使用传统多元时间序列符号化模式库构建方法、基于欧式距离符号化模式库构建方法以及基于共同马氏距离符号化模式库构建方法进行对比试验,分别设置paa分段数目为5、6、7、8、9、10、12。模型聚类准确性的评价指标采用accuracy精确度。四种方法的评价对比图如图5所示。
[0081]
通过图5可以看出,本发明构建的模式库聚类准确率高于其他三个方法,此发明方法更适合于多元水文时间序列模式库。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。