1.本技术涉及计算机视觉技术领域,特别是涉及一种视觉惯性里程计模型的训练方法、位姿估计方法及装置。
背景技术:
2.视觉里程计是视觉slam(simultaneous localization and mapping,同时定位与地图构建)问题中的一个子模块,它是利用机器人上相机在其运动过程中拍摄的相邻两帧图片计算两帧间的相对位姿。视觉里程计仅使用相机作为传感器,受光学性质影响较大,例如光照变化、运动物体、无纹理区域等。现有的一些方法采用惯性传感器imu(inertial measure unit,惯性测量单元)作为视觉的补充,设计出视觉惯性里程计,利用惯性传感器对机器人加速度和角速度的测定,融合视觉信息,获得更鲁棒的估计效果。
3.当前的视觉惯性里程计多采用非线性优化的方式,以紧耦合的形式融合相机和惯性传感器信息。然而这种方式存在初始化和标定复杂,优化迭代过程耗时长或发散,并且可能会出现跟踪丢失(即位姿无法估计)的情况。现有的利用深度学习的视觉惯性里程计一方面无法像传统方法一样恢复运动尺度,另一方面它将视觉和惯性部分视作互相独立的模块,它们没有充分地融合视觉和惯性信息,最终位姿估计准确率差于传统非线性优化算法。
技术实现要素:
4.本技术主要解决的技术问题是提供一种视觉惯性里程计模型的训练方法、位姿估计方法及相关装置。
5.本技术第一方面提供了一种视觉惯性里程计模型的训练方法,所述视觉惯性里程计模型的训练方法包括:获取样本图像集和样本imu数据集;其中,所述样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,所述样本imu数据集包括获取所述若干帧连续的样本彩色图像时获取得到的对应的样本imu数据;将所述样本图像集中的相邻两帧样本彩色图像以及所述相邻两帧样本彩色图像之间所对应的样本imu数据输入所述视觉惯性里程计模型,输出所述相邻两帧样本彩色图像所对应的两帧深度图像以及所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿;基于所述相邻两帧样本彩色图像所对应的两帧深度图像、所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿和所述相邻两帧样本彩色图像之间所对应的样本imu数据,确定所述视觉惯性里程计模型的目标损失函数;利用所述目标损失函数,调整所述视觉惯性里程计模型的网络参数。
6.因此,通过获取样本图像集和样本imu数据集,其中,样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,样本imu数据集包括获取若干帧连续的样本彩色图像时获取得到的对应的样本imu数据,在将样本图像集和样本imu数据集输入视觉惯性里程计模型后,可以利用视觉惯性里程计模型估计出场景深度和图像采集装置的位姿,具体可以输出相邻两帧样本彩色图像所对应的两帧深度图像以及图像采集装置获取相邻两帧样本彩色图像时的估计位姿,于是可以基于相邻两帧样本彩色图像所对应的两帧深度图
像、图像采集装置获取相邻两帧样本彩色图像时的估计位姿和相邻两帧样本彩色图像之间所对应的样本imu数据,来确定视觉惯性里程计模型的目标损失函数,因此将视觉信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的视觉惯性里程计模型;另外,采用深度学习的框架实现视觉惯性里程计,相较于传统基于ba(bundle-adjustment,束集调整)的非线性方法,无需复杂初始化和迭代过程,模型更加简洁,解决了传统基于ba的非线性优化算法中的初始化与优化复杂的问题,并且避免了在复杂场景中出现跟踪丢失的情况。
7.其中,所述视觉惯性里程计模型包括深度估计网络、视觉编码网络、imu编码网络和视觉惯性融合网络;所述将所述样本图像集中的相邻两帧样本彩色图像以及所述相邻两帧样本彩色图像之间所对应的样本imu数据输入所述视觉惯性里程计模型,输出所述相邻两帧样本彩色图像所对应的两帧深度图像以及所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿,包括:将所述样本图像集中的样本彩色图像输入所述深度估计网络,得到所述样本彩色图像对应的深度图像;以及将所述样本图像集中的前一帧样本彩色图像和当前帧样本彩色图像叠加后输入所述视觉编码网络,得到视觉特征编码;将所述前一帧样本彩色图像和所述当前帧样本彩色图像之间所对应的样本imu数据输入所述imu编码网络,得到imu特征编码;将所述视觉特征编码和所述imu特征编码输入所述视觉惯性融合网络,得到所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿。
8.因此,利用深度估计网络、视觉编码网络、imu编码网络和视觉惯性融合网络组成视觉惯性里程计模型,通过将样本图像集中的样本彩色图像输入深度估计网络来得到样本彩色图像对应的深度图像,从而实现对图像采集装置所处的环境深度图的估计;通过将样本图像集中的前一帧样本彩色图像和当前帧样本彩色图像叠加后输入视觉编码网络来得到视觉特征编码,同时将前一帧样本彩色图像和当前帧样本彩色图像之间所对应的样本imu数据输入imu编码网络来得到imu特征编码,之后将视觉特征编码和imu特征编码输入视觉惯性融合网络,可以得到图像采集装置获取当前帧样本彩色图像时的估计位姿,从而实现对图像采集装置自身位姿的估计。
9.其中,所述深度估计网络包括相互连接的编码器和解码器;所述将所述样本图像集中的样本彩色图像输入所述深度估计网络,得到所述样本彩色图像对应的深度图像,包括:将所述样本彩色图像输入所述深度估计网络,利用所述编码器的下采样层将所述样本彩色图像变换为深度特征图,再利用所述解码器的上采样层将所述深度特征图变换为所述样本彩色图像对应的深度图像。
10.因此,通过将样本彩色图像输入深度估计网络,深度估计网络采用编-解码器结构,利用编码器的下采样层将样本彩色图像变换为深度特征图,再利用解码器的上采样层将深度特征图变换为样本彩色图像对应的深度图像,从而可以使用深度学习的框架实现对图像采集装置所处的环境深度图的估计。
11.其中,所述视觉惯性融合网络采用注意力机制,所述视觉惯性融合网络包括前馈神经网络;所述将所述视觉特征编码和所述imu特征编码输入所述视觉惯性融合网络,得到所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿,包括:通过注意力机制将所述视觉特征编码和所述imu特征编码进行加权融合,得到优化特征编码;利用前馈神经网络对所述优化特征编码进行处理,得到所述图像采集装置获取所述当前帧样本彩色图像时
的估计位姿。
12.因此,通过注意力机制将视觉特征编码和imu特征编码进行加权融合,得到优化特征编码,并利用前馈神经网络对优化特征编码进行处理,可以得到图像采集装置获取当前帧样本彩色图像时的估计位姿,由于注意力机制关注了视觉信息和imu信息的互补性,即imu信息对于短时快速运动可以提供较好的运动估计,视觉信息相比于imu信息不会有漂移,所以在不同场景下,注意力机制能有效学习视觉特征和惯性特征之间的关系,使得在不同场景下视觉惯性里程计模型的性能鲁棒性更强。
13.其中,所述视觉惯性融合网络还包括第一多层感知机和第二多层感知机;所述通过注意力机制将所述视觉特征编码和所述imu特征编码进行加权融合,得到优化特征编码,包括:将所述imu特征编码分别输入所述第一多层感知机和所述第二多层感知机,得到若干个键值对,每个所述键值对包括一个键和一个值;获取所述视觉特征编码与每个键值对中的键的相似度,将所述相似度作为权重,将所述权重乘以对应的键值对中的值后求和,得到所述优化特征编码。
14.因此,通过将imu特征编码分别输入第一多层感知机和第二多层感知机,可以得到若干个键值对,每个所述键值对包括一个键和一个值,然后获取视觉特征编码与每个键值对中的键的相似度,将相似度作为权重乘以对应的键值对中的值后求和,得到优化特征编码,进而可以利用优化特征编码得到图像采集装置获取当前帧样本彩色图像时的估计位姿,因此,通过使用一种基于紧耦合的视觉惯性融合网络将视觉特征编码和imu特征编码融合,相较于现有将两者编码直接拼接的松耦合的网络,可以充分利用视觉信息的准确性和imu信息的高频性,使视觉信息和imu信息更好互补。
15.其中,所述目标损失函数包括深度损失函数、光度损失函数和imu损失函数;所述基于所述相邻两帧样本彩色图像所对应的两帧深度图像、所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿和所述相邻两帧样本彩色图像之间所对应的样本imu数据,确定所述视觉惯性里程计模型的目标损失函数,包括:根据所述前一帧样本彩色图像对应的深度图像和所述当前帧样本彩色图像对应的深度图像,确定所述深度损失函数;以及根据所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿和所述当前帧样本彩色图像对应的深度图像,确定所述光度损失函数;以及根据所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿和所述前一帧样本彩色图像和所述当前帧样本彩色图像之间所对应的样本imu数据,确定所述imu损失函数。
16.因此,在视觉惯性里程计模型的训练过程中,使用的视觉惯性里程计模型的目标损失函数包括深度损失函数、光度损失函数和imu损失函数,根据估计出的位姿和深度分别计算前后两帧图像经变换后的光度差异和深度图差异,计算视觉上的光度误差和几何误差,利用视觉上的深度损失函数和光度损失函数将深度估计和位姿估计约束起来,同时根据imu自身的运动学计算出的结果和位姿估计结果的差异,计算imu误差,使用了imu自身的两个约束,即速度约束和位置约束,将网络预测的位姿和imu的物理性质相关联,可以使得视觉惯性里程计模型训练过程收敛更快,并且获得绝对的尺度。
17.为了解决上述问题,本技术第二方面提供了一种位姿估计方法,所述位姿估计方法包括:利用图像采集装置获取若干帧连续的目标彩色图像,并确定所述图像采集装置获取所述若干帧连续的目标彩色图像时对应的目标imu数据;将所述若干帧连续的目标彩色
图像和对应的目标imu数据输入视觉惯性里程计模型,得到所述图像采集装置获取所述目标彩色图像时的估计位姿;其中,所述视觉惯性里程计模型是利用上述第一方面的视觉惯性里程计模型的训练方法训练得到的。
18.因此,利用图像采集装置获取若干帧连续的目标彩色图像,并确定图像采集装置获取若干帧连续的目标彩色图像时对应的目标imu数据,通过将若干帧连续的目标彩色图像和对应的目标imu数据输入视觉惯性里程计模型,得到图像采集装置获取目标彩色图像时的估计位姿,由于视觉惯性里程计模型是利用上述第一方面的视觉惯性里程计模型的训练方法训练得到的,即视觉惯性里程计模型将视觉信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的位姿估计结果。
19.为了解决上述问题,本技术第三方面提供了一种视觉惯性里程计模型的训练装置,所述视觉惯性里程计模型的训练装置包括:样本获取模块,用于获取样本图像集和样本imu数据集;其中,所述样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,所述样本imu数据集包括获取所述若干帧连续的样本彩色图像时获取得到的对应的样本imu数据;处理模块,用于将所述样本图像集中的相邻两帧样本彩色图像以及所述相邻两帧样本彩色图像之间所对应的样本imu数据输入所述视觉惯性里程计模型,输出所述相邻两帧样本彩色图像所对应的两帧深度图像以及所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿;损失函数确定模块,用于基于所述相邻两帧样本彩色图像所对应的两帧深度图像、所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿和所述相邻两帧样本彩色图像之间所对应的样本imu数据,确定所述视觉惯性里程计模型的目标损失函数;参数调整模块,用于利用所述目标损失函数,调整所述视觉惯性里程计模型的网络参数。
20.为了解决上述问题,本技术第四方面提供了一种位姿估计装置,所述位姿估计装置包括:数据获取模块,用于利用图像采集装置获取若干帧连续的目标彩色图像,并确定所述图像采集装置获取所述若干帧连续的目标彩色图像时对应的目标imu数据;位姿估计模块,用于将所述若干帧连续的目标彩色图像和对应的目标imu数据输入视觉惯性里程计模型,得到所述图像采集装置获取所述目标彩色图像时的估计位姿;其中,所述视觉惯性里程计模型是利用上述第一方面的视觉惯性里程计模型的训练方法训练得到的。
21.为了解决上述问题,本技术第五方面提供了一种电子设备,包括相互耦接的存储器和处理器,所述处理器用于执行所述存储器中存储的程序指令,以实现上述第一方面中的视觉惯性里程计模型的训练方法,或上述第二方面中的位姿估计方法。
22.为了解决上述问题,本技术第六方面提供了一种计算机可读存储介质,其上存储有程序指令,所述程序指令被处理器执行时实现上述第一方面中的视觉惯性里程计模型的训练方法,或上述第二方面中的位姿估计方法。
23.上述方案,通过获取样本图像集和样本imu数据集,其中,样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,样本imu数据集包括获取若干帧连续的样本彩色图像时获取得到的对应的样本imu数据,在将样本图像集和样本imu数据集输入视觉惯性里程计模型后,可以利用视觉惯性里程计模型估计出场景深度和图像采集装置的位姿,具体可以输出相邻两帧样本彩色图像所对应的两帧深度图像以及图像采集装置获取相邻两帧样本彩色图像时的估计位姿,于是可以基于相邻两帧样本彩色图像所对应的两帧深
度图像、图像采集装置获取相邻两帧样本彩色图像时的估计位姿和相邻两帧样本彩色图像之间所对应的样本imu数据,来确定视觉惯性里程计模型的目标损失函数,因此将视觉信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的视觉惯性里程计模型;另外,采用深度学习的框架实现视觉惯性里程计,相较于传统基于ba(bundle-adjustment,束集调整)的非线性方法,无需复杂初始化和迭代过程,模型更加简洁,解决了传统基于ba的非线性优化算法中的初始化与优化复杂的问题,并且避免了在复杂场景中出现跟踪丢失的情况。
附图说明
24.图1是本技术视觉惯性里程计模型的训练方法一实施例的流程示意图;
25.图2是图1中步骤s12一实施例的流程示意图;
26.图3是一应用场景中通过深度估计网络获取深度图像的原理示意图;
27.图4是图2中步骤s124一实施例的流程示意图;
28.图5是一应用场景中通过视觉惯性融合网络获取估计位姿的原理示意图;
29.图6是图4中步骤s1241一实施例的流程示意图;
30.图7是一应用场景中通过imu特征编码获得键值对的原理示意图;
31.图8是图1中步骤s13一实施例的流程示意图;
32.图9是一应用场景中视觉惯性里程计模型的训练过程的原理示意图;
33.图10是本技术位姿估计方法一实施例的流程示意图;
34.图11是一应用场景中通过视觉惯性里程计模型实现位姿估计的原理示意图;
35.图12是本技术视觉惯性里程计模型的训练装置一实施例的框架示意图;
36.图13是本技术位姿估计装置一实施例的框架示意图;
37.图14是本技术电子设备一实施例的框架示意图;
38.图15是本技术计算机可读存储介质一实施例的框架示意图。
具体实施方式
39.下面结合说明书附图,对本技术实施例的方案进行详细说明。
40.以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、接口、技术之类的具体细节,以便透彻理解本技术。
41.本文中术语“系统”和“网络”在本文中常被可互换使用。本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。此外,本文中的“多”表示两个或者多于两个。
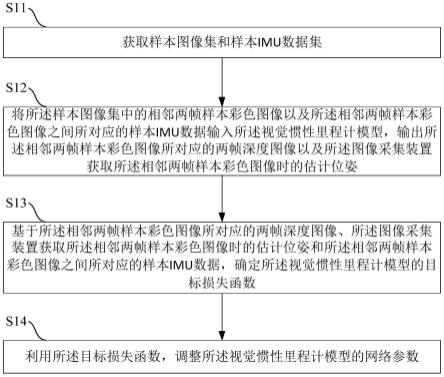
42.请参阅图1,图1是本技术视觉惯性里程计模型的训练方法一实施例的流程示意图。具体而言,可以包括如下步骤:
43.步骤s11:获取样本图像集和样本imu数据集。其中,所述样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,所述样本imu数据集包括获取所述若干帧连续的样本彩色图像时获取得到的对应的样本imu数据。
44.具体地,可以利用图像采集装置获取样本图像集和样本imu数据集,例如,在图像
采集装置的运动过程中,可以获取若干帧连续的样本彩色图像,作为样本图像集,而在图像采集装置上或者图像采集装置所处的运动设备上设置有惯性导航装置,在图像采集装置获取若干帧连续的样本彩色图像的过程中,惯性导航装置可以同步采集对应的样本imu数据,作为样本imu数据集。
45.步骤s12:将所述样本图像集中的相邻两帧样本彩色图像以及所述相邻两帧样本彩色图像之间所对应的样本imu数据输入所述视觉惯性里程计模型,输出所述相邻两帧样本彩色图像所对应的两帧深度图像以及所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿。
46.具体地,从样本图像集的若干帧连续的样本彩色图像中选取相邻两帧样本彩色图像,例如选取当前帧样本彩色图像和前一帧样本彩色图像,然后从样本imu数据集中找到当前帧样本彩色图像和前一帧样本彩色图像之间的样本imu数据,由于imu数据的采样频率一般大于图像的采样频率,因此,相邻两帧样本彩色图像之间可能对应有多组样本imu数据,于是,将选取的相邻两帧样本彩色图像以及该相邻两帧样本彩色图像之间所对应的所有样本imu数据组成当前批的训练数据输入视觉惯性里程计模型,输出相邻两帧样本彩色图像所对应的两帧深度图像以及图像采集装置获取相邻两帧样本彩色图像时的估计位姿。
47.步骤s13:基于所述相邻两帧样本彩色图像所对应的两帧深度图像、所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿和所述相邻两帧样本彩色图像之间所对应的样本imu数据,确定所述视觉惯性里程计模型的目标损失函数。
48.步骤s14:利用所述目标损失函数,调整所述视觉惯性里程计模型的网络参数。
49.可以理解的是,在得到相邻两帧样本彩色图像所对应的两帧深度图像、图像采集装置获取相邻两帧样本彩色图像时的估计位姿和相邻两帧样本彩色图像之间所对应的所有样本imu数据后,可以根据估计出的位姿和深度分别计算前后两帧图像经变换后的光度差异和深度图差异,得到视觉上的光度误差和几何误差,还可以根据imu自身的运动学计算出的结果和位姿估计结果的差异,计算imu误差,从而可以确定视觉惯性里程计模型的目标损失函数。
50.可以理解的是,在得到目标损失函数后,可以根据目标损失函数对视觉惯性里程计模型的网络参数进行调整,以实现对视觉惯性里程计模型进行更新。另外,在视觉惯性里程计模型的训练过程中,可以获取目标损失函数的收敛性,当目标损失函数收敛时,则可以停止对视觉惯性里程计模型的网络参数的更新,而当目标损失函数不收敛时,可以获取网络参数的调整次数,当调整次数达到预设次数时,则可以根据此时的网络参数确定最终的视觉惯性里程计模型,以避免损失函数不收敛而影响训练效率。
51.上述方案,通过获取样本图像集和样本imu数据集,其中,样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,样本imu数据集包括获取若干帧连续的样本彩色图像时获取得到的对应的样本imu数据,在将样本图像集和样本imu数据集输入视觉惯性里程计模型后,可以利用视觉惯性里程计模型估计出场景深度和图像采集装置的位姿,具体可以输出相邻两帧样本彩色图像所对应的两帧深度图像以及图像采集装置获取相邻两帧样本彩色图像时的估计位姿,于是可以基于相邻两帧样本彩色图像所对应的两帧深度图像、图像采集装置获取相邻两帧样本彩色图像时的估计位姿和相邻两帧样本彩色图像之间所对应的所有样本imu数据,来确定视觉惯性里程计模型的目标损失函数,因此将视觉
信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的视觉惯性里程计模型;另外,采用深度学习的框架实现视觉惯性里程计,相较于传统基于ba(bundle-adjustment,束集调整)的非线性方法,无需复杂初始化和迭代过程,模型更加简洁,解决了传统基于ba的非线性优化算法中的初始化与优化复杂的问题,并且避免了在复杂场景中出现跟踪丢失的情况。
52.请参阅图2,图2是图1中步骤s12一实施例的流程示意图。本实施例中,所述视觉惯性里程计模型包括深度估计网络、视觉编码网络、imu编码网络和视觉惯性融合网络;上述步骤s12具体可以包括如下步骤:
53.步骤s121:将所述样本图像集中的样本彩色图像输入所述深度估计网络,得到所述样本彩色图像对应的深度图像。
54.具体地,将前一帧样本彩色图像输入深度估计网络,可以得到前一帧样本彩色图像对应的深度图像,将当前帧样本彩色图像输入深度估计网络,可以得到当前帧样本彩色图像对应的深度图像。以当前帧样本彩色图像为例,深度估计网络的输入是当前帧的样本彩色图像(rgb图像),尺寸为h*w*3,深度估计网络的输出是网络预测当前帧的样本彩色图像对应的深度图像,尺寸为h*w*1。
55.在一实施例中,所述深度估计网络包括相互连接的编码器和解码器;上述步骤s121具体可以包括:将所述样本彩色图像输入所述深度估计网络,利用所述编码器的下采样层将所述样本彩色图像变换为深度特征图,再利用所述解码器的上采样层将所述深度特征图变换为所述样本彩色图像对应的深度图像。
56.请结合图3,图3是一应用场景中通过深度估计网络获取深度图像的原理示意图,深度估计网络采用编-解码器结构,将样本彩色图像输入深度估计网络,在编码器(encoder)中样本彩色图像通过下采样层变换为h/64*w/64*1024的特征图,而在解码器(decoder)中则将该特征图利用上采样层获得与样本彩色图像尺寸大小相同的深度图像,从而可以使用深度学习的框架实现对图像采集装置所处的环境的稠密深度图的估计。
57.步骤s122:将所述样本图像集中的前一帧样本彩色图像和当前帧样本彩色图像叠加后输入所述视觉编码网络,得到视觉特征编码。
58.步骤s123:将所述前一帧样本彩色图像和所述当前帧样本彩色图像之间所对应的样本imu数据输入所述imu编码网络,得到imu特征编码。
59.步骤s124:将所述视觉特征编码和所述imu特征编码输入所述视觉惯性融合网络,得到所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿。
60.可以理解的是,视觉编码网络可以利用样本彩色图像的图像信息获得含有像素运动和相机运动信息的编码,imu编码网络可以使用前一帧样本彩色图像和当前帧样本彩色图像之间的imu数据获得与视觉编码网络的输出相同通道数的编码。例如,视觉编码网络的输入为当前帧样本彩色图像和上一帧样本彩色图像的叠加,尺寸为h*w*6,输出是视觉特征编码,尺寸为1*1024;imu编码网络的输入为当前帧样本彩色图像和上一帧样本彩色图像之间的所有imu数据,imu数据可以包括加速度数据和角速度数据,当imu的频率是图像采集装置的10倍时,imu编码网络的输入尺寸为10*6,输出尺寸为10*1024。视觉惯性融合网络采用类似传统优化中紧耦合的方式,利用视觉编码网络输出的视觉特征编码和imu编码网络输出的imu特征编码,获得融合后的编码,最终输出估计位姿。
61.上述方案,利用深度估计网络、视觉编码网络、imu编码网络和视觉惯性融合网络组成视觉惯性里程计模型,通过将样本图像集中的样本彩色图像输入深度估计网络来得到样本彩色图像对应的深度图像,从而实现对图像采集装置所处的环境深度图的估计;通过将样本图像集中的前一帧样本彩色图像和当前帧样本彩色图像叠加后输入视觉编码网络来得到视觉特征编码,同时将前一帧样本彩色图像和当前帧样本彩色图像之间所对应的所有样本imu数据输入imu编码网络来得到imu特征编码,之后将视觉特征编码和imu特征编码输入视觉惯性融合网络,可以得到图像采集装置获取当前帧样本彩色图像时的估计位姿,从而实现对图像采集装置自身位姿的估计。
62.请参阅图4,图4是图2中步骤s124一实施例的流程示意图。本实施例中,所述视觉惯性融合网络采用注意力机制,所述视觉惯性融合网络包括前馈神经网络;上述步骤s124具体可以包括如下步骤:
63.步骤s1241:通过注意力机制将所述视觉特征编码和所述imu特征编码进行加权融合,得到优化特征编码。
64.步骤s1242:利用前馈神经网络对所述优化特征编码进行处理,得到所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿。
65.请结合图5,图5是一应用场景中通过视觉惯性融合网络获取估计位姿的原理示意图,视觉惯性融合网络接受的输入是视觉编码网络和imu编码网络的输出,尺寸分别为1*1024和10*1024,视觉惯性融合网络最终输出尺寸为1*6的位姿估计,其中6表示预测6自由度的相对位姿,包括3维的平移向量和3维的欧拉角。视觉惯性融合网络采用注意力机制,用注意力机制对视觉特征和惯性特征进行融合,注意力机制作为神经网络结构的重要组成部分,能够抑制通道中没有用的特征,增强需要用到的特征,让整体网络更好地进行特征选择与融合;其中“key,value”称作键值对,其中,key为键,value为值,是由imu特征编码经过处理得到的,k*1024个(例如k=10,与imu和图像的频率有关)imu特征编码拆成10个1*1024的编码,计算视觉特征编码(visual code)和每个键(key)的相似度,将相似度作为权重乘以各个值(value),再将结果相加,即得尺寸为1*1024的优化后的编码(refinedcode),即优化特征编码,优化特征编码经过前馈神经网络(feed forword),最终获得1*6的位姿pose。
66.进一步地,请结合图6,图6是图4中步骤s1241一实施例的流程示意图,在一实施例中,所述视觉惯性融合网络还包括第一多层感知机和第二多层感知机;上述步骤s1241具体可以包括:
67.步骤s12411:将所述imu特征编码分别输入所述第一多层感知机和所述第二多层感知机,得到若干个键值对,每个所述键值对包括一个键和一个值。
68.步骤s12412:获取所述视觉特征编码与每个键值对中的键的相似度,将所述相似度作为权重,将所述权重乘以对应的键值对中的值后求和,得到所述优化特征编码。
69.请结合图7,图7是一应用场景中通过imu特征编码获得键值对的原理示意图,键值对是由imu特征编码经过不同的多层感知机或者全连接层形成的,通过将imu特征编码分别输入第一多层感知机和第二多层感知机,可以得到若干个键值对,每个所述键值对包括一个键和一个值,然后获取视觉特征编码与每个键值对中的键的相似度,将相似度作为权重乘以对应的键值对中的值后求和,得到优化特征编码,进而可以利用优化特征编码得到图像采集装置获取当前帧样本彩色图像时的估计位姿,因此,通过使用一种基于紧耦合的视
觉惯性融合网络将视觉特征编码和imu特征编码融合,相较于现有将两者编码直接拼接的松耦合的网络,可以充分利用视觉信息的准确性和imu信息的高频性,使视觉信息和imu信息更好互补。
70.将视觉特征编码和键值对进行加权融合得到优化特征编码这个过程可以用下面这个公式表示:
[0071][0072]
其中,q代表视觉特征编码,d是归一化参数,ki为第i个键(key),vi为第i个值(value)。不同于传统直接将视觉特征编码和imu特征编码加权求平均的方法,本技术实施例中的融合方式充分利用了视觉的准确性和imu的高频性,是一种紧耦合的融合方式。
[0073]
上述方案,通过注意力机制将视觉特征编码和imu特征编码进行加权融合,得到优化特征编码,并利用前馈神经网络对优化特征编码进行处理,可以得到图像采集装置获取当前帧样本彩色图像时的估计位姿,由于注意力机制关注了视觉信息和imu信息的互补性,即imu信息对于短时快速运动可以提供较好的运动估计,视觉信息相比于imu信息不会有漂移,所以在不同场景下,注意力机制能有效学习视觉特征和惯性特征之间的关系,使得在不同场景下视觉惯性里程计模型的性能鲁棒性更强。
[0074]
请参阅图8,图8是图1中步骤s13一实施例的流程示意图。本实施例中,所述目标损失函数包括深度损失函数、光度损失函数和imu损失函数;上述步骤s13具体可以包括如下步骤:
[0075]
步骤s131:根据所述前一帧样本彩色图像对应的深度图像和所述当前帧样本彩色图像对应的深度图像,确定所述深度损失函数。
[0076]
步骤s132:根据所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿和所述当前帧样本彩色图像对应的深度图像,确定所述光度损失函数。
[0077]
步骤s133:根据所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿和所述前一帧样本彩色图像和所述当前帧样本彩色图像之间所对应的样本imu数据,确定所述imu损失函数。
[0078]
请结合图9,图9是一应用场景中视觉惯性里程计模型的训练过程的原理示意图,视觉惯性里程计模型包括深度估计网络(depthnet)、视觉编码网络(visualodom)、imu编码网络(imuodom)和视觉惯性融合网络(sensor fusion)。根据前一帧样本彩色图像(i
t-1
)对应的深度图像和当前帧样本彩色图像(i
t
)对应的深度图像确定深度损失函数(loss
geo
),根据图像采集装置获取当前帧样本彩色图像时的估计位姿(r,t)和当前帧样本彩色图像对应的深度图像确定光度损失函数(loss
pho
),根据图像采集装置获取当前帧样本彩色图像时的估计位姿(r,t)和前一帧样本彩色图像和当前帧样本彩色图像之间所对应的所有样本imu数据(imu
t-1,t
),确定imu损失函数(loss
imu
),其中,imu损失函数可以包括速度损失函数和位移损失函数。
[0079]
在视觉惯性里程计模型的训练过程中,使用的视觉惯性里程计模型的目标损失函数包括深度损失函数、光度损失函数和imu损失函数,根据估计出的位姿和深度分别计算前后两帧图像经变换后的光度差异和深度图差异,计算视觉上的光度误差和几何误差,利用
视觉上的深度损失函数和光度损失函数将深度估计和位姿估计约束起来,同时根据imu自身的运动学计算出的结果和位姿估计结果的差异,计算imu误差,使用了imu自身的两个约束,即速度约束和位置约束,将网络预测的位姿和imu的物理性质相关联,可以使得视觉惯性里程计模型训练过程收敛更快,并且获得绝对的尺度。
[0080]
请参阅图10,图10是本技术位姿估计方法一实施例的流程示意图。具体而言,可以包括如下步骤:
[0081]
步骤s101:利用图像采集装置获取若干帧连续的目标彩色图像,并确定所述图像采集装置获取所述若干帧连续的目标彩色图像时对应的目标imu数据。
[0082]
步骤s102:将所述若干帧连续的目标彩色图像和对应的目标imu数据输入视觉惯性里程计模型,得到所述图像采集装置获取所述目标彩色图像时的估计位姿。
[0083]
其中,所述视觉惯性里程计模型是利用上述任一种视觉惯性里程计模型的训练方法训练得到的。
[0084]
请结合图11,图11是一应用场景中通过视觉惯性里程计模型实现位姿估计的原理示意图,将采集的目标彩色图像和对应的目标imu数据输入视觉惯性里程计模型,视觉惯性里程计模型包括深度估计网络、视觉编码网络、imu编码网络和视觉惯性融合网络,可以输出稠密深度图d和相机位姿(r,t)。可以理解的是,利用图像采集装置获取若干帧连续的目标彩色图像,并确定图像采集装置获取若干帧连续的目标彩色图像时对应的目标imu数据,通过将若干帧连续的目标彩色图像和对应的目标imu数据输入视觉惯性里程计模型,得到图像采集装置获取目标彩色图像时的估计位姿,由于视觉惯性里程计模型是利用上述第一方面的视觉惯性里程计模型的训练方法训练得到的,即视觉惯性里程计模型将视觉信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的位姿估计结果。
[0085]
进一步地,利用视觉惯性里程计模型可以得到图像采集装置采集连续的目标彩色图像时的估计位姿,将连续的估计位姿连接起来,可以获得图像采集装置的运动轨迹估计。
[0086]
本技术的位姿估计方法的执行主体可以是位姿估计装置,例如,位姿估计方法可以由定位设备或服务器或其它处理设备执行,其中,定位设备可以为机器人、无人车、无人机等移动设备,也可以是用户设备(user equipment,ue)、用户终端、无绳电话、个人数字助理(personal digital assistant,pda)、手持设备、计算设备、车载设备、可穿戴设备等。在一些可能的实现方式中,该位姿估计方法可以通过处理器调用存储器中存储的计算机可读指令的方式来实现。
[0087]
请参阅图12,图12是本技术视觉惯性里程计模型的训练装置一实施例的框架示意图。本实施例中,视觉惯性里程计模型的训练装置120包括:样本获取模块1200,用于获取样本图像集和样本imu数据集;其中,所述样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,所述样本imu数据集包括获取所述若干帧连续的样本彩色图像时获取得到的对应的样本imu数据;处理模块1202,用于将所述样本图像集中的相邻两帧样本彩色图像以及所述相邻两帧样本彩色图像之间所对应的样本imu数据输入所述视觉惯性里程计模型,输出所述相邻两帧样本彩色图像所对应的两帧深度图像以及所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿;损失函数确定模块1204,用于基于所述相邻两帧样本彩色图像所对应的两帧深度图像、所述图像采集装置获取所述相邻两帧样本彩色图
像时的估计位姿和所述相邻两帧样本彩色图像之间所对应的样本imu数据,确定所述视觉惯性里程计模型的目标损失函数;参数调整模块1206,用于利用所述目标损失函数,调整所述视觉惯性里程计模型的网络参数。
[0088]
上述方案,通过样本获取模块1200获取样本图像集和样本imu数据集,其中,样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,样本imu数据集包括获取若干帧连续的样本彩色图像时获取得到的对应的样本imu数据,在处理模块1202将样本图像集和样本imu数据集输入视觉惯性里程计模型后,可以利用视觉惯性里程计模型估计出场景深度和图像采集装置的位姿,具体可以输出相邻两帧样本彩色图像所对应的两帧深度图像以及图像采集装置获取相邻两帧样本彩色图像时的估计位姿,于是损失函数确定模块1204可以基于相邻两帧样本彩色图像所对应的两帧深度图像、图像采集装置获取相邻两帧样本彩色图像时的估计位姿和相邻两帧样本彩色图像之间所对应的所有样本imu数据,来确定视觉惯性里程计模型的目标损失函数,因此将视觉信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的视觉惯性里程计模型;另外,采用深度学习的框架实现视觉惯性里程计,相较于传统基于ba(bundle-adjustment,束集调整)的非线性方法,无需复杂初始化和迭代过程,模型更加简洁,解决了传统基于ba的非线性优化算法中的初始化与优化复杂的问题,并且避免了在复杂场景中出现跟踪丢失的情况。
[0089]
在一些实施例中,所述视觉惯性里程计模型包括深度估计网络、视觉编码网络、imu编码网络和视觉惯性融合网络;处理模块1202执行将所述样本图像集中的相邻两帧样本彩色图像以及所述相邻两帧样本彩色图像之间所对应的样本imu数据输入所述视觉惯性里程计模型,输出所述相邻两帧样本彩色图像所对应的两帧深度图像以及所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿的步骤,具体包括:将所述样本图像集中的样本彩色图像输入所述深度估计网络,得到所述样本彩色图像对应的深度图像;以及将所述样本图像集中的前一帧样本彩色图像和当前帧样本彩色图像叠加后输入所述视觉编码网络,得到视觉特征编码;将所述前一帧样本彩色图像和所述当前帧样本彩色图像之间所对应的样本imu数据输入所述imu编码网络,得到imu特征编码;将所述视觉特征编码和所述imu特征编码输入所述视觉惯性融合网络,得到所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿。
[0090]
在一些实施例中,所述深度估计网络包括相互连接的编码器和解码器;处理模块1202执行将所述样本图像集中的样本彩色图像输入所述深度估计网络,得到所述样本彩色图像对应的深度图像的步骤,具体包括:将所述样本彩色图像输入所述深度估计网络,利用所述编码器的下采样层将所述样本彩色图像变换为深度特征图,再利用所述解码器的上采样层将所述深度特征图变换为所述样本彩色图像对应的深度图像。
[0091]
在一些实施例中,所述视觉惯性融合网络采用注意力机制,所述视觉惯性融合网络包括前馈神经网络;处理模块1202执行将所述视觉特征编码和所述imu特征编码输入所述视觉惯性融合网络,得到所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿的步骤,具体包括:通过注意力机制将所述视觉特征编码和所述imu特征编码进行加权融合,得到优化特征编码;利用前馈神经网络对所述优化特征编码进行处理,得到所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿。
[0092]
在一些实施例中,所述视觉惯性融合网络还包括第一多层感知机和第二多层感知
机;处理模块1202执行通过注意力机制将所述视觉特征编码和所述imu特征编码进行加权融合,得到优化特征编码的步骤,具体可以包括:将所述imu特征编码分别输入所述第一多层感知机和所述第二多层感知机,得到若干个键值对,每个所述键值对包括一个键和一个值;获取所述视觉特征编码与每个键值对中的键的相似度,将所述相似度作为权重,将所述权重乘以对应的键值对中的值后求和,得到所述优化特征编码。
[0093]
在一些实施例中,所述目标损失函数包括深度损失函数、光度损失函数和imu损失函数;损失函数确定模块1204执行基于所述相邻两帧样本彩色图像所对应的两帧深度图像、所述图像采集装置获取所述相邻两帧样本彩色图像时的估计位姿和所述相邻两帧样本彩色图像之间所对应的样本imu数据,确定所述视觉惯性里程计模型的目标损失函数的步骤,包括:根据所述前一帧样本彩色图像对应的深度图像和所述当前帧样本彩色图像对应的深度图像,确定所述深度损失函数;以及根据所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿和所述当前帧样本彩色图像对应的深度图像,确定所述光度损失函数;以及根据所述图像采集装置获取所述当前帧样本彩色图像时的估计位姿和所述前一帧样本彩色图像和所述当前帧样本彩色图像之间所对应的样本imu数据,确定所述imu损失函数。
[0094]
请参阅图13,图13是本技术位姿估计装置一实施例的框架示意图。本实施例中,位姿估计装置130包括:数据获取模块1300,用于利用图像采集装置获取若干帧连续的目标彩色图像,并确定所述图像采集装置获取所述若干帧连续的目标彩色图像时对应的目标imu数据;位姿估计模块1302,用于将所述若干帧连续的目标彩色图像和对应的目标imu数据输入视觉惯性里程计模型,得到所述图像采集装置获取所述目标彩色图像时的估计位姿;其中,所述视觉惯性里程计模型是利用上述任一种视觉惯性里程计模型的训练方法训练得到的。
[0095]
上述方案,数据获取模块1300利用图像采集装置获取若干帧连续的目标彩色图像,并确定图像采集装置获取若干帧连续的目标彩色图像时对应的目标imu数据,位姿估计模块1302通过将若干帧连续的目标彩色图像和对应的目标imu数据输入视觉惯性里程计模型,得到图像采集装置获取目标彩色图像时的估计位姿,由于视觉惯性里程计模型是利用上述第一方面的视觉惯性里程计模型的训练方法训练得到的,即视觉惯性里程计模型将视觉信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的位姿估计结果。
[0096]
请参阅图14,图7是本技术电子设备一实施例的框架示意图。电子设备140包括相互耦接的存储器141和处理器142,处理器142用于执行存储器141中存储的程序指令,以实现上述任一视觉惯性里程计模型的训练方法,或上述任一位姿估计方法。在一个具体的实施场景中,电子设备140可以包括但不限于:微型计算机、服务器。
[0097]
具体而言,处理器142用于控制其自身以及存储器141以实现上述任一视觉惯性里程计模型的训练方法,或上述任一位姿估计方法实施例中的步骤。处理器142还可以称为cpu(central processing unit,中央处理单元)。处理器142可能是一种集成电路芯片,具有信号的处理能力。处理器142还可以是通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field-programmable gate array,fpga)或者其他可编程逻辑器件、分立
门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。另外,处理器142可以由集成电路芯片共同实现。
[0098]
上述方案,处理器142通过获取样本图像集和样本imu数据集,其中,样本图像集包括利用图像采集装置获取的若干帧连续的样本彩色图像,样本imu数据集包括获取若干帧连续的样本彩色图像时获取得到的对应的样本imu数据,在将样本图像集和样本imu数据集输入视觉惯性里程计模型后,可以利用视觉惯性里程计模型估计出场景深度和图像采集装置的位姿,具体可以输出相邻两帧样本彩色图像所对应的两帧深度图像以及图像采集装置获取相邻两帧样本彩色图像时的估计位姿,于是可以基于相邻两帧样本彩色图像所对应的两帧深度图像、图像采集装置获取相邻两帧样本彩色图像时的估计位姿和相邻两帧样本彩色图像之间所对应的所有样本imu数据,来确定视觉惯性里程计模型的目标损失函数,因此将视觉信息与imu信息在网络中融合起来,利用二者各自的优点,可以获得更准确、更鲁棒的视觉惯性里程计模型;另外,采用深度学习的框架实现视觉惯性里程计,相较于传统基于ba(bundle-adjustment,束集调整)的非线性方法,无需复杂初始化和迭代过程,模型更加简洁,解决了传统基于ba的非线性优化算法中的初始化与优化复杂的问题,并且避免了在复杂场景中出现跟踪丢失的情况。
[0099]
请参阅图15,图15是本技术计算机可读存储介质一实施例的框架示意图。计算机可读存储介质150存储有能够被处理器运行的程序指令1500,程序指令1500用于实现上述任一视觉惯性里程计模型的训练方法,或上述任一位姿估计方法实施例中的步骤。
[0100]
在本技术所提供的几个实施例中,应该理解到,所揭露的方法、装置,可以通过其它的方式实现。例如,以上所描述的装置实施方式仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性、机械或其它的形式。
[0101]
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施方式方案的目的。
[0102]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0103]
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本技术各个实施方式方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。