基于bilstm的老挝语文本正则化方法
技术领域
1.本发明涉及基于bilstm的老挝语文本正则化方法,属于自然语言处理技术领域。
背景技术:
2.文本正则化作为语音合成的上游任务,正则化后的序列作为语音合成的输入,致使文本预处理过程显得尤为重要。该任务通常需要大量的非规范词和正则化词的数据对来训练模型。其中富资源语言的文本正则化任务已经成熟,英语、中文、俄语等富资源语言的训练数据已经达到上亿规模,但是稀缺资源语言的文本正则化任务少有学者研究。
3.该任务最早可以追溯到文本到语音的合成系统mitalk,完全基于规则的正则化方式,但是基于匹配的方式难以胜任一词多义的情况,sproat等人总结了文本正则化的难点和挑战,例如符号“%”读作百分数,货币符号“$15”读作“十五美元”,“2021”既可以读作数字“两千零一十九”或者年份“二零一九年”,“9:10”读作时间“九点十分”或比分“九比十”,“4/5”既可以表示分数,又可以表示日期,同样还可以表示比分,不同语境对不可读词的含义的确定起着至关重要的作用,而大部分不可读词表达的意思模棱两可,因此上下文是文本正则化任务中判断这类词含义的决定因素,完全基于规则的方式不足以胜任该任务,而神经网络能够通过大量的训练数据学习到不可读词与上下文语境间的关系,预测出符合语境的正则化后的词。
技术实现要素:
4.本发明提供了基于bilstm的老挝语文本正则化方法,首次提出了老挝语文本正则化任务,解决了低资源下老挝语文本正则化面临的特定语法结构、一词多义的问题,为下游老挝语语音合成任务提供了可用的老挝语文本。
5.本发明的技术方案是:基于bilstm的老挝语文本正则化方法,所述方法的具体步骤如下:
6.step1、老挝语文本正则化数据预处理:将老挝语文本数据进行数据清洗、编码转换、语料标注、长度比过滤、分词;
7.step2、基于bilstm神经网络的文本正则化处理:采用序列标注的思想,将bilstm作为编码器,结合不可读词的上下文文本向量,并将线性层和softmax作为解码器,预测不可读词可能的标签,并在bilstm后接自注意力机制加深序列词间关注度,使模型更好的理解上下文语义预测标签。
8.作为本发明的进一步方案,所述step1的具体步骤如下:
9.step1.1、老挝语文本数据清洗:去除老挝语文本中的乱码字符,规范标点符号表示方法;
10.step1.2、老挝语编码转换:老挝语lao字体统一编码转换变成unicode字体;
11.step1.3、句子长度过滤:保留老挝语句子长度小于250字符的句子,用于提升模型训练效率;
12.step1.4、语料标注:对老挝语文本正则化语料标注,具体包括:文本序列中的需要正则化的字符被使用
“▁”
标记,每次只标记单个字符,标记后的文本序列被分为多个序列,每个序列中只有一个字符被
“▁”
标记,标记后的字符由专业的语言专家标注对应老挝语文本,每个标注后的老挝语字符进行分类,并对每个标注后的老挝语字符进行分类,所有标注后的老挝语文本构成标签词典,标签词典大小为112;
13.step1.5、老挝语文本分词:对标记后的老挝语文本单个字符进行分词处理,分词前去掉被
“▁”
标记的字符。
14.作为本发明的进一步方案,所述step2的具体步骤为:
15.step2.1、首先将文本正则化任务当作序列标注任务完成,在bilstm中,文本序列经过词嵌入表示为:经过词嵌入表示为:为分词编码后的字符,h=12
…
l,l为输入序列句子长度,n为词嵌入维度;前向隐藏层和后向隐藏层的输出维度均为n维,定义为和bilstm输出表示为:
16.step2.2、bilstm后接自注意力机制,使用自注意力机制关注序列词间的深层关系,使模型更好的理解输入序列的上下文语义信息;将自注意力机制的输出送入线性层,该线性层输出维度为正则化标签数,经过softmax计算每个标签的得分。
17.作为本发明的进一步方案,所述step2.2的具体步骤为:
18.step2.2.1、用attn(q,k,v)表示自注意力机制,q,k,v分别表示query,key,value,将bilstm的输出分别作为q,k,v;下式中,ki∈k和vi∈v,|q|=|k|=|v|;自注意力机制原理如下:
[0019][0020][0021]
其中wk,wq和wv为随机初始化权重,并在迭代中学习更新,z为注意力头个数;bilstm输出序列的隐态表征表示为其中自注意力机制输出其中
[0022]
step2.2.2、自注意力机制最后计算得出结合句子文本向量表征向量c,该序列表征作为编码器的输出,送入到线性层分类,然后通过softmax层计算每个分类得分。
[0023]
本发明的有益效果是:本发明解决了老挝语文本正则化数据稀缺的问题,本发明包括对老挝语文本正则化数据预处理、基于自注意力机制的bilstm网络文本正则化处理两个部分;本发明所提的方法将文本正则化任务当作序列标注任务完成,在bilstm神经网络中输入标注好的文本序列,根据上下文预测正确结果,增加自注意力机制加深模型对序列语义的理解,在老挝语文本正则化任务中表现较为优异,为下游老挝语语音合成任务提供
了可用的老挝语文本。
附图说明
[0024]
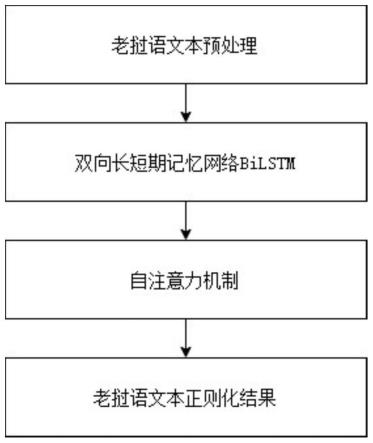
图1为本发明中的双向长短期记忆网络bilstm原理图;
[0025]
图2为本发明中的自注意力机制原理图;
[0026]
图3为本发明中的方法流程框图;
具体实施方式
[0027]
实施例1:如图1-图3所示,基于bilstm的老挝语文本正则化方法,所述方法的具体步骤如下:
[0028]
step1、老挝语文本正则化数据预处理:将老挝语文本数据进行数据清洗、编码转换、语料标注、长度比过滤、分词;
[0029]
step2、基于bilstm神经网络的文本正则化处理:采用序列标注的思想,将bilstm作为编码器,结合不可读词的上下文文本向量,并将线性层和softmax作为解码器,预测不可读词可能的标签,并在bilstm后接自注意力机制加深序列词间关注度,使模型更好的理解上下文语义预测标签。
[0030]
作为本发明的进一步方案,所述step1的具体步骤如下:
[0031]
step1.1、老挝语文本数据清洗:去除老挝语文本中的乱码字符,规范标点符号表示方法;
[0032]
step1.2、老挝语编码转换:老挝语lao字体统一编码转换变成unicode字体;
[0033]
step1.3、句子长度过滤:保留老挝语句子长度小于250字符的句子,用于提升模型训练效率;
[0034]
step1.4、语料标注:对老挝语文本正则化语料标注,具体包括:文本序列中的需要正则化的字符被使用
“▁”
标记,每次只标记单个字符,标记后的文本序列被分为多个序列,每个序列中只有一个字符被
“▁”
标记,标记后的字符由专业的语言专家标注对应老挝语文本,每个标注后的老挝语字符进行分类,并对每个标注后的老挝语字符进行分类,所有标注后的老挝语文本构成标签词典,标签词典大小为112;
[0035]
step1.5、老挝语文本分词:对标记后的老挝语文本单个字符进行分词处理,分词前去掉被
“▁”
标记的字符。
[0036]
作为本发明的进一步方案,所述step2的具体步骤为:
[0037]
step2.1、首先将文本正则化任务当作序列标注任务完成,在bilstm中,文本序列经过词嵌入表示为:经过词嵌入表示为:为分词编码后的字符,h=12
…
l,l为输入序列句子长度,n为词嵌入维度;前向隐藏层和后向隐藏层的输出维度均为n维,定义为和bilstm输出表示为:
[0038]
step2.2、bilstm后接自注意力机制,使用自注意力机制关注序列词间的深层关系,使模型更好的理解输入序列的上下文语义信息;将自注意力机制的输出送入线性层,该线性层输出维度为正则化标签数,经过softmax计算每个标签的得分。
[0039]
作为本发明的进一步方案,所述step2.2的具体步骤为:
[0040]
step2.2.1、用attn(q,k,v)表示自注意力机制,q,k,v分别表示query,key,value,将bilstm的输出分别作为q,k,v;下式中,ki∈k和vi∈v,|q|=|k|=|v|;自注意力机制原理如下:
[0041][0042][0043]
其中wk,wq和wv为随机初始化权重,并在迭代中学习更新,z为注意力头个数;bilstm输出序列的隐态表征表示为其中自注意力机制输出其中
[0044]
step2.2.2、自注意力机制最后计算得出结合句子文本向量表征向量c,该序列表征作为编码器的输出,送入到线性层分类,然后通过softmax层计算每个分类得分。
[0045]
为了说明本发明的效果,本发明进行了如下实验:实验测试在老挝语上完成文本正则化任务,标注数据格式为一段序列只标注一个需要正则化的词,并对该词标注正则化后的老挝语文本。本发明总共使用了36k的数据对,训练集和数据集大小分别为32.2k和3.8k。该数据集为内部数据集,文本来自cri网页爬取获得,数据标注工作由老挝语为母语的语言学家完成。使用字符准确率(character accuracy)来评级本发明的效果。本发明在基于长短期记忆网络bilstm完成文本正则化任务的模型作为基准模型。使用参数β1=0.9,β2=0.999,ε=10-6
的adam优化器,学习率为,所有实验均在一张nvidia tesla t4上完成训练。
[0046]
表1:训练数据部分数据类别
[0047][0048]
训练数据包含32.2k个分类标签,全为新闻语料,该语料中,包含12类标签,表1列
出部分例子,其中数字、日期和时间类别占比大部分,其余英文缩写、度量单位、货币单位等类别占比少数。
[0049]
为了验证本发明提出的发明方法的效果,设计以下对比实验进行分析。在该数据集上进行了3组实验。
[0050]
实验一:对比五种模型在测试集上的模型准确率。模型1:rnn序列生成模型。基于序列生成的rnn神经网络模型做编码器,sproat等人使用该方法在富资源上完成了文本正则化任务;模型2:bilstm模型。基于序列标注的lstm神经网络模型做编码器,该方法来自park等人在中文多音字预测任务中提出的方法;模型3:本发明bilstm self-attn模型。基于自注意力机制的bilstm做编码器;模型4:xlm模型。基于老挝语字符粒度的xlm-reberta预训练语言模型做编码器;模型5:bilstm xlm模型。基于交叉注意力机制融合bilstm和xlm-roberta预训练语言模型做编码器。上述5种模型在数据集上的实验结果见表2。
[0051]
表2:五种不同模型文本正则化准确率
[0052][0053]
由表可以分析出基于序列生成的rnn神经网络模型在该数据集表现较差,基于序列标注的bilstm神经网络的模型在预测结果上能获取相对较好的结果。这是因为该方法结合了上下文文本向量,而模型3加入了自注意力机制,加深序列中各个字符间的关系,使得模型更好的理解语义信息,预测结果能到达较好的效果。但是基于老挝语字符粒度的xlm-roberta预训练语言模型没能达到理想的效果,甚至效果极差,其存在以下几点原因:第一,用于训练出该预训练语言模型的原数据集没有注重数字和字符,导致预训练语言模型在该任务中的表现堪忧;第二,xlm-roberta预训练语言模型是在上百种语言上联合训练的跨语言模型,在多语言任务上可能表现更好,而在老挝语单语言上,模型参数存在偏置,导致模型性能反而下降。模型5进一步证明了基于预训练语言模型的方式难以在文本正则化任务中承担任务。结果上本发明的基于自注意力机制的bilstm模型方法效果更好。
[0054]
实验二:本发明基于自注意力机制的bilstm方法在测试集上的部分类别的模型准确率。在整体的数据集上,对每个分类组进行了准确率测试。表3为表1中各类在测试集上的占比和准确率。该结果有助于确定从神经网络中哪些类别更容易预测。
[0055]
表3:训练数据部分数据准确率
[0056][0057]
模型在测试集上的表现上,对不同类别的预测准确率有较大偏差,相对于比较复杂日期、时间、比分等几个类别效果较差,基于特定符号的类别,模型更容易预测,特别对于“%”这类没有歧义的符号预测极为准确。原因在于该实验数据集较少,难以在少量数据集下学习到复杂的文本规范变换,而特定的符号转换不需要复杂变换,故而模型预测更加容易。
[0058]
实验三:对比实验。为了进一步体现出本发明在该数据集下的性能,本发明对比了sproat等人提出的基于rnn神经网络完成序列生成任务的模型和park等人提出的基于bilstm神经网络完成序列生成任务的模型,sproat等人的工作是在英文和俄语的文本正则化,将需要正则化的标签单独取出,输入词典为构成所有需要正则化的字符,输出词典为构成所有正则化字符对应标签的字符。park等人的方法为表2的bilstm模型方法。表4展示了上述两种模型在稀缺资源老挝语文本正则化任务中各个类别的准确率。
[0059]
表4:基于神经网络模型的序列生成和序列标注任务方法在部分数据准确率
[0060][0061][0062]
表3的准确率与表4对比,表明了本发明在老挝语文本正则化任务中的性能要优于sproat等人和park等人的方法。
[0063]
为了体现本发明的效果,我们将结果文本正则化结果可视化,表5展示了基于自注意力机制的bilstm神经网络模型在文本正则化任务中的序列结果,并将几种类别的正则化结果放在该表中。
[0064]
表5:五种不同数据类别文本正则化结果
[0065][0066]
从表5可以看到,第一段序列标记为范围类别,
“‑”
被预测为包括第二、三序列被标记为数字类别,该类别复杂繁琐,容易在对“.”和“,”的预测上出错,第二段序列只展示了“2”预测正确的结果,这个点在这里表示科学计数法的点,故而“2”被预测为“两千”,这点和中文的读法相似。序列三为正确预测的“.”作为科学计数法使用,因为此时“.”不发音,将其预测为“none”,第四段序列为“%”预测为在百分号上的预测完全准确。
[0067]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。