1.本技术涉及机器学习技术领域,更具体地,涉及一种基于机器学习的类风湿关节炎预测方法及装置。
背景技术:
2.类风湿性关节炎(rheumatoid arthritis,ra)是一种慢性多系统自身免疫疾病,是由持续的炎症性炎性滑膜炎和随后的关节结构侵蚀引起的。它被认为是一种复杂的疾病,其病因受到遗传和环境风险因素的影响。ra通常根据两个实验室指标来预测患ra的概率:类风湿因子(rf)和抗环瓜氨酸肽抗体(anti-ccp)。现有预测方法中,使用每一指标的阈值将该指标的检测值划分为阴性/阳性,然后综合二者的划分结果确定预测结果,但是这样的方法不能很好地指示ra的风险概率。
3.另外,现有的方法未将与ra高度相关的其他指标纳入考量,导致ra的预测准确率和预测效率较低。
技术实现要素:
4.本技术提供一种基于机器学习的类风湿关节炎预测方法及装置,利用机器学习模型综合多个特征预测类风湿关节炎的风险概率,相对于通过简单综合两个特征的阴性/阳性划分结果进行预测的方法,本技术大大提高了预测的准确率。
5.本技术提供了一种基于机器学习的类风湿关节炎预测方法,包括:
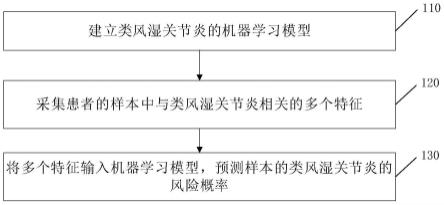
6.建立类风湿关节炎的机器学习模型;
7.采集患者的样本中与类风湿关节炎相关的多个特征;
8.将多个特征输入机器学习模型,预测样本的类风湿关节炎的风险概率。
9.优选地,多个特征包括类风湿因子和抗环瓜氨酸肽抗体。
10.优选地,多个特征还包括患者的年龄和性别。
11.优选地,建立机器学习模型包括如下步骤:
12.利用相同的第一样本集的所有样本中与类风湿关节炎相关的多个特征获得多个数据分析方法的预测准确率,从而获得预测准确率最高的数据分析方法;
13.基于预测准确率最高的数据分析方法构建初始机器学习模型;
14.利用第二样本集对初始机器学习模型进行训练,获得机器学习模型。
15.优选地,多个数据分析方法包括朴素贝叶斯分类器、logistic回归分析法、支持向量机算法、k近邻算法、人工神经网络、随机森林算法、梯度提升决策树算法中的至少两个。
16.本技术还提供一种基于机器学习的类风湿关节炎预测装置,包括模型建立模块、特征值采集模块和预测模块;
17.模型建立模块用于建立类风湿关节炎的机器学习模型;
18.特征值采集模块用于采集患者的样本中与类风湿关节炎相关的多个特征;
19.预测模块用于将多个特征输入机器学习模型,预测样本的类风湿关节炎的风险概
率。
20.优选地,多个特征包括类风湿因子和抗环瓜氨酸肽抗体。
21.优选地,多个特征还包括患者的年龄和性别。
22.优选地,模型建立模块包括准确率获得模块、初始模型构建模块和训练模块;
23.准确率获得模块用于利用相同的第一样本集的所有样本中与类风湿关节炎相关的多个特征获得多个数据分析方法的预测准确率;
24.初始模型构建模块用于基于预测准确率最高的数据分析方法构建初始机器学习模型;
25.训练模块用于利用第二样本集对初始机器学习模型进行训练,获得机器学习模型。
26.优选地,多个数据分析方法包括朴素贝叶斯分类器、logistic回归分析法、支持向量机算法、k近邻算法、人工神经网络、随机森林算法、梯度提升决策树算法中的至少两个。
27.通过以下参照附图对本技术的示例性实施例的详细描述,本技术的其它特征及其优点将会变得清楚。
附图说明
28.被结合在说明书中并构成说明书的一部分的附图示出了本技术的实施例,并且连同其说明一起用于解释本技术的原理。
29.图1为本技术提供的基于机器学习的类风湿关节炎预测方法的流程图;
30.图2为本技术提供的建立机器学习模型的流程图;
31.图3为本技术提供的基于机器学习的类风湿关节炎预测装置的结构图。
具体实施方式
32.现在将参照附图来详细描述本技术的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本技术的范围。
33.以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本技术及其应用或使用的任何限制。
34.对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,技术、方法和设备应当被视为说明书的一部分。
35.在这里示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。
36.本技术提供一种基于机器学习的类风湿关节炎预测方法及装置,利用机器学习模型综合多个特征预测类风湿关节炎的风险概率,相对于通过简单综合两个特征的阴性/阳性划分结果进行预测的方法,本技术大大提高了预测的准确率。
37.实施例一
38.如图1所示,本技术提供的基于机器学习的类风湿关节炎预测方法包括如下步骤:
39.s110:建立类风湿关节炎的机器学习模型。
40.具体地,作为一个实施例,如图2所示,建立机器学习模型包括如下步骤:
41.s210:利用相同的第一样本集的所有样本中与类风湿关节炎相关的多个特征获得多个数据分析方法的预测准确率,从而获得预测准确率最高的数据分析方法。
42.具体地,第一样本集包括类风湿关节炎患者组与对照组的样本,其中对照组包括健康对照组和其他免疫疾病对照组两类。
43.在第一样本集中设置健康样本和其他疾病样本,有助于更清楚地区分类风湿关节炎人群与健康人群以及类风湿关节炎人群与其他疾病人群,提高分类的准确度。
44.作为一个实施例,多个特征包括现有技术的两种指标:类风湿因子(rf)和抗环瓜氨酸肽抗体(anti-ccp)。
45.优选地,多个特征还包括患者的年龄和性别。
46.更优选地,多个特征还包括人抗氨甲酰化蛋白anti-carp和14-3-3η蛋白,由此,在该优选实施例中,多个特征包括年龄、性别、类风湿因子(rf)和抗环瓜氨酸肽抗体(anti-ccp)、人抗氨甲酰化蛋白anti-carp和14-3-3η蛋白。
47.在此基础上,多个特征还包括患者的图像(包括b超图像、x光图像、核磁共振图像等)、症状以及自我评估结果中的至少一者。
48.将尽可能多的与疾病相关的特征作为输入数据,可以更准确有效地预测疾病的风险概率。
49.作为一个实施例,多个数据分析方法包括朴素贝叶斯分类器、logistic回归分析法、支持向量机算法、k近邻算法、人工神经网络、随机森林算法、梯度提升决策树算法中的至少两个。
50.优选采用所有适合的数据分析方法。作为一个实施例,获得上述所有数据分析方法(朴素贝叶斯分类器、logistic回归分析法、支持向量机算法、k近邻算法、人工神经网络、随机森林算法、梯度提升决策树算法)的预测准确率。
51.具体地,将从每个样本提取的上述特征输入基于每一种数据分析方法的预测模型(例如基于python的开源工具包scikit-learn构建预测模型),获得该样本的类风湿关节炎的风险概率预测结果,并使用五折交叉验证方法对每一个预测模型的预测结果进行准确率评估,从而获得预测准确率最高的数据分析方法。
52.可以理解地,首先将上述特征中除性别之外的特征进行归一化(例如z-score)处理,然后将归一化后的特征值输入各个预测模型进行数据分析,获得各个预测结果。
53.s220:基于预测准确率最高的数据分析方法构建初始机器学习模型。
54.s230:利用第二样本集对初始机器学习模型进行训练,获得机器学习模型。
55.可以理解地,第二样本集可以与第一样本集相同,也可以不同。
56.优选地,在第二样本集与第一样本集不同的实施例中,第二样本集的数量级大于第一样本集的数量级,并且第二样本集至少包括类风湿关节炎患者组、健康对照组和其他免疫疾病对照组。利用较大的样本集对模型进行训练,可以提高模型的预测准确性。
57.将第二样本集作为训练集对初始机器学习模型进行训练,使得机器学习模型准确地区分类风湿关节炎人群和非类风湿关节炎人群。
58.s120:采集患者的样本中与类风湿关节炎相关的多个特征。
59.机器学习模型训练完成后,将个体患者的样本输入机器学习模型即可获得该患者的类风湿关节炎的风险概率。
60.可以理解地,作为一个实施例,多个特征包括现有技术的两种指标:类风湿因子(rf)和抗环瓜氨酸肽抗体(anti-ccp)。
61.优选地,多个特征还包括患者的年龄和性别。
62.更优选地,多个特征还包括人抗氨甲酰化蛋白anti-carp和14-3-3η蛋白,由此,在该优选实施例中,多个特征包括年龄、性别、类风湿因子(rf)和抗环瓜氨酸肽抗体(anti-ccp)、人抗氨甲酰化蛋白anti-carp和14-3-3η蛋白。
63.在此基础上,多个特征还包括患者的图像(包括b超图像、x光图像、核磁共振图像等)、症状以及自我评估结果中的至少一者。
64.s130:将多个特征输入机器学习模型,预测样本的类风湿关节炎的风险概率。
65.机器学习模型训练完成后,将患者的样本中提取的特征输入模型即可获得准确的预测结果。
66.实施例二
67.基于上述的类风湿关节炎预测方法,本技术还提供了一种类风湿关节炎预测装置。如图3所示,类风湿关节炎预测装置包括模型建立模块310、特征值采集模块320和预测模块330。
68.模型建立模块310用于建立类风湿关节炎的机器学习模型。
69.特征值采集模块320用于采集患者的样本中与类风湿关节炎相关的多个特征。
70.预测模块330用于将多个特征输入机器学习模型,预测样本的类风湿关节炎风险概率。
71.具体地,模型建立模块310包括准确率获得模块3101、初始模型构建模块3102和训练模块3103。
72.准确率获得模块3101用于利用相同的第一样本集的所有样本中与类风湿关节炎相关的多个特征获得多个数据分析方法的预测准确率。
73.初始模型构建模块3102用于基于预测准确率最高的数据分析方法构建初始机器学习模型。
74.训练模块3103用于利用第二样本集对初始机器学习模型进行训练,获得机器学习模型。
75.实例:
76.采集对照组379例,类风湿关节炎患者271例,共670例样本数据。从每个样本中提取年龄、性别、类风湿因子、抗环瓜氨酸多肽抗体、14-3-3η、anti-carp六个维度的特征,并对除性别外的五个维度的特征进行z-score归一化处理。
77.随后将上述六个维度的特征输入基于下述七种数据分析方法构建的预测模型,再利用五折交叉验证方法进行准确率评估,结果如下:
78.方法五折交叉验证准确率朴素贝叶斯分类器0.872
±
0.020梯度提升决策树算法0.904
±
0.025k近邻算法0.879
±
0.013logistic回归分析法0.903
±
0.013随机森林算法0.903
±
0.019
人工神经网络0.899
±
0.017支持向量机算法0.890
±
0.016
79.由上表可知,梯度提升决策树获得的结果最佳。利用所有样本对基于这种方法建立的模型进行训练,获得了92.4%的总准确率,相比现有技术有了较大提升。
80.虽然已经通过例子对本技术的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上例子仅是为了进行说明,而不是为了限制本技术的范围。本领域的技术人员应该理解,可在不脱离本技术的范围和精神的情况下,对以上实施例进行修改。本技术的范围由所附权利要求来限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。