1.本发明涉及文本识别技术领域,具体涉及一种基于课程学习的文本实体识别方法。
背景技术:
2.命名实体识别(named entity recognition,ner)是自然语言处理领域(natural language processing,nlp)的一项基本研究课题,其主要任务是从非结构化文本中识别出有意义的实体项,并将其归类于预先定义的实体类别。开放领域中一般包括人名、地名、组织名等,在不同的垂直领域,也有着不同的预定义实体类别。电力领域下的命名实体识别能够实现电力文本的自动化处理,从繁杂的电力文本数据中挖掘出大量有价值的电力领域知识,有助于研究人员更容易、更快地提取出关键的相关信息(例如,使用的相关电力技术和设备设施等)。
3.近年来,bert(bidirectional encoder representation from transformers)预训练语言模型在命名实体识别领域得到了广泛的应用,具有较高的识别准确率;但由于bert模型规模庞大、参数众多,导致基于bert嵌入的实体识别模型普遍存在难以训练及推理速度缓慢的问题。
4.而为了保证bert嵌入的实体识别模型的识别效果,需使其预先在训练文本上进行学习训练,目前常规的bert嵌入的实体识别模型训练方法为随机输入样本后进行模型训练,会造成训练缓慢的问题,受此影响,其识别准确度也有所下降。
5.综上所述,急需一种基于课程学习的文本实体识别方法以解决现有技术中存在的问题。
技术实现要素:
6.本发明目的在于提供一种基于课程学习的文本实体识别方法,以解决现有实体识别模型训练效率低的问题。
7.为实现上述目的,本发明提供了一种基于课程学习的文本实体识别方法,包括以下步骤:
8.步骤一:对训练项目文本中的文本数据进行预处理,并对预处理后的文本数据进行标注,构建文本标注数据集;
9.步骤二:将文本标注数据集划分为训练集、验证集和测试集;
10.步骤三:将训练集中的文本数据按照从易到难的顺序进行排列,通过自然断点分类算法将排序后的训练集中的文本数据划分为n个区块;
11.步骤四:使实体识别模型对训练集中n个区块的文本数据进行课程学习,直至模型收敛;学习训练过程中将实体识别模型在验证集上进行评估,获取最优模型参数设置;
12.步骤五:将最优模型参数设置对应的实体识别模型在测试集上进行测试,将符合训练效果的实体识别模型应用于真实项目文本实体识别场景中。
13.优选的,所述步骤一中,采用bioes标注模式对预处理后的文本数据进行标注,并在标注符号后添加实体类别表征符号。
14.优选的,所述步骤一中,bioes标注模式中的b代表标注实体开始,i代表实体内部标注,e代表标注实体结尾,s代表单字符实体,o代表非实体;实体类别表征符号中,g代表项目申请单位,f代表设施设备,t代表技术术语。
15.优选的,所述步骤三中,对训练集的文本数据按照从易到难的顺序进行排序时,通过领域实体占比进行难度排序,领域实体占比数值越大则学习难度越大,每个文本数据的领域实体占比通过表达式1)计算:
[0016][0017]
其中,s为训练集中的单个文本数据,n为文本数据s中实体词的总数,ej为s中的第j个需识别的实体词,d(s)为s的领域实体占比,len(s)为s的样本长度,len(ej)为ej的实体词长度。
[0018]
优选的,所述步骤三中,当训练集中的文本数据样本量为5000个以下时,1<n≤3;当训练集中的文本数据样本量介于5000个至100000个时,4≤n≤9;当训练集中的文本数据样本量为100000个以上时,n≥10。
[0019]
优选的,所述步骤三中,通过自然断点分类算法进行区块划分时,将训练集中排序后的各文本数据对应的领域实体占比依次放入领域实体占比集合中,选取领域实体占比集合中方差拟合优度gvf值最大的划分情形为最佳划分;方差拟合优度gvf通过表达式2)计算:
[0020][0021]
其中,sdamz是领域实体占比集合中所有领域实体占比值的偏差平方和,sdam1至sdamn分别为第1个区块至第n个区块对应的所有领域实体占比值的偏差平方和。
[0022]
优选的,所述步骤四中,建立bert-bilstm-crf实体识别模型,对排序后的训练集中的文本数据进行课程学习。
[0023]
优选的,所述步骤四中,实体识别模型先进行n个阶段的学习训练,在进行第i个阶段的学习训练时,将第1个区块至第i个区块的文本数据输入实体识别模型中进行学习训练,其中1≤i≤n;然后让实体识别模型反复学习整个训练集的文本数据,直到模型收敛即完成训练。
[0024]
优选的,所述步骤四中,在实体识别模型学习训练过程中,设置若干个模型检查点;在每个检查点,都将实体识别模型在验证集上进行评估,对比每个检查点时实体识别模型的识别准确率和收敛情况,获取最优模型参数设置。
[0025]
优选的,所述步骤五中,将最优模型参数设置对应的实体识别模型在测试集上进行测试,评估该实体识别模型的泛化能力是否满足使用需求。
[0026]
应用本发明的技术方案,具有以下有益效果:
[0027]
(1)本发明中,通过使实体识别模型进行课程学习,先用更简单的数据区块来训练神经网络模型,然后逐渐增加数据区块的难度级别,直到覆盖整个训练集,对于神经网络模型来说,初始阶段从较简单的数据区块开始学习,能够较为容易地找到目标函数的最小值,然后逐渐增加较复杂困难的数据区块,在训练过程中,模型对局部极小值的跟踪会引导其走向更优的参数空间,更有可能逼近全局最小值,使其具有更好的泛化性,从而达到提升训练效率和识别准确度的效果。
[0028]
(2)本发明中,通过领域实体占比对训练集中的文本数据进行排序,某样本领域实体占比高,包含的领域知识越多越丰富,则该样本越复杂,相应的,对于实体识别模型来说,该样本的学习难度也越高,可以为课程学习提供难度依次递增的样本排序。
[0029]
(3)本发明中,通过自然断点分类算法将训练集中的文本数据划分为多个区块,能够保证区块内样本难度的相似性最大化及不同区块间样本难度的相异性最大化。
[0030]
(4)本发明中,通过建立bert-bilstm-crf实体识别模型进行实体识别,bert嵌入层用于创建包含上下文信息的动态词向量;其次,bert嵌入层后添加bilstm模块用于获取双向信息;然后,在bilstm层输出后接一个必要的线性层调整输出维度;最后,再添加crf层用于学习标签间的约束关系,保证标签序列的合理性。
[0031]
(5)本发明中,在实体识别模型学习训练过程中,设置若干个模型检查点;在每个检查点,都将实体识别模型在验证集上进行评估,对比每个检查点时实体识别模型的识别准确率和收敛情况,可获取最优模型参数设置。
[0032]
(6)本发明中,通过本技术的学习训练方法对实体识别模型进行训练,能够提升基于bert嵌入的实体识别模型的训练效率和识别效果(具体地,在电力文本标注数据集上,模型训练时间减少了50%,模型的f1提升了2.37%)。
[0033]
(7)本发明中,将本技术中的实体识别模型应用于电力领域项目的实体识别中,有助于研究人员更容易、更快地提取出关键的相关信息,如使用的相关电力技术和设备设施等。
[0034]
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
[0035]
构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0036]
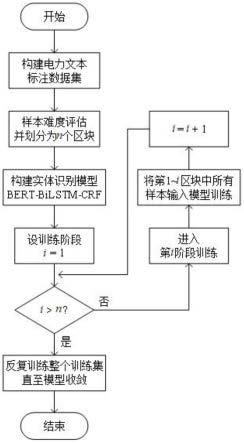
图1是本技术实施例中一种基于课程学习的文本实体识别方法的流程图;
[0037]
图2是本技术实施例中训练集的划分示意图;
[0038]
图3是本技术实施例中一种基于课程学习的文本实体识别方法与常规模型学习方法的效果对比图。
具体实施方式
[0039]
以下结合附图对本发明的实施例进行详细说明,但是本发明可以根据权利要求限定和覆盖的多种不同方式实施。
[0040]
实施例:
[0041]
参见图1至图3,一种基于课程学习的文本实体识别方法,本实施例应用于电力领域项目文本中的实体识别。
[0042]
一种基于课程学习的文本实体识别方法,包括以下步骤:
[0043]
步骤一:对训练项目文本中的文本数据进行预处理,并对预处理后的文本数据进行标注,构建文本标注数据集;
[0044]
本实施例中,从国家电网湖南省电力有限公司数据部门收集了312个已结项的电力项目相关的材料,对电力项目中的文本数据进行缺失值补全、去重替换等清洗操作,剔除冗余数据,最终得到了干净的电力项目文本数据;采用bioes标注模式对预处理后的文本数据进行标注,并在标注符号后添加实体类别表征符号。
[0045]
在分析了大量电力行业项目的可行性研究报告之后,发现电力行业项目文本不同于一般开放域的自由文本,其通常包含大量电力行业专业术语,具有较强的领域特征;因此,结合电力行业项目的文本特征,参考其他垂直领域的实体类别,最后定义了以下三种适合电力域的需识别的实体类别:
[0046]
1)项目申请单位(项目负责单位):使用实体类别表征符号g(group)来表示;
[0047]
2)设备设施(电力元件、电力相关装置等设备设施):使用实体类别表征符号f(facility equipment)来表示;
[0048]
3)技术术语(电力技术方法、研究算法策略等):使用实体类别表征符号t(technical term)来表示。
[0049]
采用bioes标注模式对上述三种实体类别进行标注时,b(begin)代表标注实体开始,i(intermediate)代表实体内部标注,e(end)代表标注实体结尾,s(single)代表单字符实体,o(other)代表非实体;对于单字符实体,用“s”进行标注;对于两个字符的实体,例如“导线”,用“b”标注实体开始,用“e”标注实体结尾;对于三个及以上字符的实体,例如“变压器”,依然用“b”和“e”分别标注实体的开始与结尾,实体内部则用“i”(表intermediate)进行标注;对于非实体,即不属于预定义类别的部分,用“o”(表other)进行标注。至此,结合之前定义的适合电力领域的3类实体类别表征符号,可以得到对电力文本的标注符号共3
×
4 1=13种,具体如表1所示。
[0050]
表1电力领域实体标注符号表
[0051]
[0052][0053]
标注示例如表2所示:
[0054]
表2项目文本数据标注示意
[0055]
负载谐振变换器由lc谐振电路组成。b-fi-fi-fi-fi-fi-fe-fob-ti-ti-ti-ti-te-tooo
[0056]
将清洗后的电力项目文本数据进行人工标注,将标注后的电力项目文本数据进行切割,得到18552个较干净和标准的电力文本数据,构建文本标注数据集。
[0057]
步骤二:将文本标注数据集划分为训练集、验证集和测试集;
[0058]
通过留出法(hold-out method)将文本标注数据集划分为训练集、验证集和测试集,其中训练集的样本量应足够大,以满足实体识别模型的学习训练要求。本实施例中,通过留出法将文本标注数据集中的文本数据按照8:1:1的比例随机切分成训练集(14841个样本)、验证集(1855个样本)和测试集(1856个样本)。
[0059]
步骤三:将训练集中的文本数据按照从易到难的顺序进行排列,通过自然断点分类算法将排序后的训练集中的文本数据划分为n个区块;
[0060]
在进行课程学习时,其主要目标是用更简单的数据区块(或者更简单的子任务)来训练神经网络模型,然后逐渐增加数据(或者子任务)的难度级别,直到覆盖整个训练数据集(或者目标任务)。简单地说,课程学习意味着从简单的数据到难度更大的数据的训练过程,类似于学生学习课程的过程:逐渐从更简单的课程学习到更复杂的课程。对于神经网络模型来说,初始阶段从较简单的数据区块开始学习,能够较为容易地找到目标函数的最小值,然后逐渐增加较复杂困难的数据区块,在训练过程中,模型对局部极小值的跟踪会引导其走向更优的参数空间,更有可能逼近全局最小值,使其具有更好的泛化性,从而达到提升训练效率和识别准确度的效果。
[0061]
在现有技术中,通常采用难度评估器根据样本难度的评估标准,去决定哪些样本更简单(容易)、哪些样本更复杂(困难);训练调度器则是用于决定何时增加多少更困难的样本输入到模型中,或者根据样本难度去决定某个阶段网络模型能够访问到哪些样本。
[0062]
本技术中,通过领域实体占比dep(domain entities proportion)来评估样本的学习难度,该评估标准可以解释为:某样本领域实体占比高,包含的领域知识越多越丰富,
则该样本越复杂,相应的,对于实体识别模型来说,该样本的学习难度也越高。
[0063]
对训练集的文本数据按照从易到难的顺序进行排序时,通过领域实体占比进行难度排序,领域实体占比数值越大则学习难度越大,每个文本数据的领域实体占比通过表达式1)计算:
[0064][0065]
其中,s为训练集中的单个文本数据(即单个样本),n为文本数据s中实体词的总数,ej为s中的第j个需识别的实体词(包括项目申请单位、设施设备和技术术语),d(s)为s的领域实体占比,len(s)为s的样本长度,len(ej)为ej的实体词长度。
[0066]
根据表达式1)求得训练集中所有文本数据的领域实体占比后,根据领域实体占比的数值大小进行排序,得到学习难度从易到难排列的训练集合x,训练集合x中共包括14841个样本,每个样本的学习难度(领域实体占比)依次增加。
[0067]
然后,需要根据样本难度将样本序列划分为多个难度相似的区块。目前,区块划分有多种方法,例如均匀地将数据划分为多个区块,即每个区块的样本数量相同;另外,也可以设置多个阈值进行划分等。但是,均匀划分的方法可能导致同一区块内的样本难度差异波动较大,而不同区块间的难度差异不够大;设置阈值的方法则是在划分的同时尽量保证同一区块内的样本数目相同,存在较难选择合理阈值的问题。
[0068]
本发明采用george frederick jenks教授提出的自然断点分类算法(jenks natural breaks)对样本集合进行划分,该方法常常被应用于地理信息系统中,将其引入此处样本划分中,能够保证区块内样本难度的相似性最大化及不同区块间样本难度的相异性最大化。
[0069]
通过自然断点分类算法进行区块划分时,n的取值范围如下:
[0070]
当训练集中的文本数据样本量为5000个以下时,1<n≤3;
[0071]
当训练集中的文本数据样本量介于5000个至100000个时,4≤n≤9;
[0072]
当训练集中的文本数据样本量为100000个以上时,n≥10。
[0073]
本实施例中,训练集合x中共包括14841个样本,n的取值优选为6,即通过自然断点分类算法将训练集合x分成6个区块。
[0074]
通过自然断点分类算法进行区块划分时,将训练集中排序后的各文本数据(即训练集合x)对应的领域实体占比依次放入领域实体占比集合d中,选取领域实体占比d集合中方差拟合优度gvf值最大的划分情形为最佳划分;方差拟合优度gvf通过表达式2)计算:
[0075][0076]
其中,sdamz是领域实体占比集合d中所有领域实体占比值的偏差平方和,sdam1至sdamn分别为第1个区块至第n个区块对应的所有领域实体占比值的偏差平方和。
[0077]
得到领域实体占比集合d的最佳划分后,将各个断点对应至训练集合x中,对训练集合x中的文本数据进行区块划分,如图2所示。按照上述自然断点分类算法的步骤,最后将
训练集划分为6个区块,从第1区块到第6区块的样本依次被认为学习难度逐渐递增:
[0078]
第1区块为:第1个样本到第2909个样本(样本数量2909个);
[0079]
第2区块为:第2910个样本到第6522个样本(样本数量3613个);
[0080]
第3区块为:第6523个样本到第10017个样本(样本数量3495个);
[0081]
第4区块为:第10018个样本到第12680个样本(样本数量2663个);
[0082]
第5区块为:第12681个样本到第14276个样本(样本数量1596个);
[0083]
第6区块为:第14277个样本到第14841个样本(样本数量565个)。
[0084]
步骤四:使实体识别模型对训练集中n个区块的文本数据进行课程学习,直至模型收敛;学习训练过程中将实体识别模型在验证集上进行评估,获取最优模型参数设置;
[0085]
本技术中,建立bert-bilstm-crf实体识别模型,对排序后的训练集中的文本数据(即训练集合x)进行课程学习。
[0086]
首先,bert嵌入层用于创建包含上下文信息的动态词向量;其次,bert嵌入层后添加bilstm模块用于获取双向信息;然后,在bilstm层输出后接一个必要的线性层调整输出维度;最后,再添加crf层用于学习标签间的约束关系,保证标签序列的合理性。
[0087]
经过多次实验,为实体识别模型中的各种参数都设置了合适的值。其中,对于电力文本标注数据训练集中每个样本,在其首尾分别添加标记[cls]和[sep],字符序列的最大长度设为256(包含首尾标记),长度不足256的序列则用标记[pad]填充,长度超过256的序列则进行缩减。另外,bert隐藏层大小设置为768,bilstm隐藏层参数则设置为bert输出词向量的维度,即768。在训练过程中,模型采用adamw优化算法进行优化,学习率设置为1e-3,同时,为了防止出现除0错误,adamw优化器设置epsilon值为1e-8。最终,模型的参数设置总结如表3所示:
[0088]
表3实体识别模型初始参数设置
[0089]
[0090][0091]
完成实体识别模型设置后,即可开始通过训练集合x进行实体识别模型的课程学习。
[0092]
实体识别模型先进行n个阶段的学习训练,在进行第i个阶段的学习训练时,将第1个区块至第i个区块的文本数据输入实体识别模型中进行学习训练,其中1≤i≤n;然后反复学习整个训练集的文本数据(即整个训练集合x),直到模型收敛即完成训练。具体学习训练过程为:第1个阶段时,将第1区块中所有样本输入bert-bilstm-crf模型中进行训练;第2个阶段时,将第1、2区块中所有样本输入模型中继续训练;第三个阶段时,将第1、2、3区块中所有样本输入模型中继续训练;以此类推,当进入第n个阶段时,将第1~n个区块所有样本(即整个训练集合x中的所有文本数据)输入模型中继续训练,完成第n个阶段的学习训练时,训练集中的所有文本数据均已输入至实体识别模型中,让实体识别模型对整个训练集合x中的所有文本数据(即第1~n个区块所有样本)进行反复学习,直到模型收敛即完成训练,如图1所示。
[0093]
按照上述训练策略,其初始阶段从较简单的区块开始学习,能够较为容易地找到目标函数的最小值,然后逐渐增加较复杂困难的区块,在训练过程中,模型对局部极小值的跟踪会引导其走向更优的参数空间,更有可能逼近全局最小值。因此,相比于不使用课程学习的方法(让样本随机输入到模型中训练),基于领域实体占比的课程学习方法将具有更好的泛化性,能够达到提升训练效率和识别准确度的效果。
[0094]
在实体识别模型学习训练过程中,设置若干个模型检查点;在每个检查点,都将实体识别模型在验证集上进行评估,对比每个检查点时实体识别模型的识别准确率和收敛情况,获取最优的实体识别模型参数设置。
[0095]
本实施例中,将16个样本设置为一个batch,每100个batch设置一个检查点(checkpoint),在模型训练过程中,对于每个检查点,都将实体识别模型在验证集上进行一次评估,以便输出识别准确率、观察模型的收敛情况等,保存效果较好的模型设置参数,直至获得最优模型参数设置。
[0096]
步骤五:将最优模型参数设置对应的实体识别模型在测试集上进行测试,评估该实体识别模型的泛化能力是否满足使用需求,将符合训练效果(即使用需求)的实体识别模型应用于真实项目文本实体识别场景中。
[0097]
参见图3,w/o-cl表示不使用课程学习的方法(without curriculum learning,w/o-cl),dep代表本技术中通过领域实体占比(dep)进行难度划分后再进行课程学习的模型学习方法,横坐标为检查点,纵坐标则是在对应检查点时模型在验证集上的f1值,反映了该时刻模型在电力文本标注数据验证集上的性能表现。从图3可知,本技术的实体识别模型学习后在验证集上评估的性能表现明显优于常规的模型学习方法。
[0098]
实验中,w/o-cl方法中模型训练迭代次数为472个检查点,dep方法训练迭代次数则为230个检查点,训练速度上dep方法是w/o-cl方法的2.05倍,即训练时间减少了50%左右。
[0099]
最后,两种方法的模型完成训练后,将分别在测试集上进行测试用于评估模型的泛化能力。w/o-cl方法在测试集上的f1值为85.73%,dep方法则为88.10%,比w/o-cl方法提升了2.37%。因此,实验表明,本技术提出的基于领域实体占比的课程学习方法能够帮助改善基于bert嵌入的实体识别模型在电力本文上的训练效率和识别效果,能够应用于真实项目文本中,有助于研究人员更容易、更快地提取出关键的相关信息(例如,使用的相关电力技术和设备设施等)。
[0100]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。