1.本发明属于智能视频教学技术领域,尤其涉及一种实现动作识别的智能视频教学方法及系统。
背景技术:
2.本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
3.在知识经济时代,人们快速学习和掌握新知识的需求与日俱增,如何利用先进的信息技术,构建适合不同人群需求的学习体系,形成人人可学、处处可学、时时能学的学习型社会是当前面临的重大课题。
4.基于计算机技术的学习形式是目前推荐使用的主要形式之一,将严肃的学习活动和计算机互动学习相结合,利用寓教于乐的思想,使学习过程不再枯燥。传统的学习方式主要以观看学习内容为主,存在学习者长期久坐或长时间盯着屏幕不利于视力的问题,需要探索新的学习模式,不仅注重学习者的学习效果,而且更要关注学习过程中的身心健康。教育学和心理学的研究表明,即使是最低限度的身体活动也能支持学习过程,因为主动完成的任务比被动接受的信息更能被记住,而且,肢体运动、走动、姿态互动也是现实生活中较自然的交互方式,因此,在学习过程中使用走动、肢体运动方式不仅与虚拟对象交互能够实现自然性,而且有利于提高学习效率。
5.但是,由于不同学习者的个体差异、学习时间差异及有限性,现有的方法难以提供个性化、自适应的学习内容,也不能实现视频播放内容的自主更新,缓解学生疲劳。
技术实现要素:
6.为了解决上述背景技术中存在的技术问题,本发明提供一种实现动作识别的智能视频教学方法及系统,不仅实现了线上教育中视频播放内容的自主更新,缓解学生疲劳,而且使用走动、动作交互等常见的交互方式实现了与学习内容的交互。
7.为了实现上述目的,本发明采用如下技术方案:
8.本发明的第一个方面提供一种实现动作识别的智能视频教学方法,其包括:
9.获取学习者的历史学习信息;
10.基于学习者的历史学习信息,获取并播放学习视频;
11.其中,在播放学习视频的过程中,实时获取学习者的身体关节点的位置,判断学习者肢体动作,基于学习者肢体动作控制所述学习视频的播放进度;同时,获取学习者的人脸彩色图像,基于学习者的人脸彩色图像,识别人脸彩色图像中的人脸关键点,基于人脸关键点计算左右眼睛闭合度均值和嘴部张角,基于人脸彩色图像计算头部转角,基于左右眼睛闭合度均值、嘴部张角和头部转角,更新视频播放内容。
12.进一步地,所述获取学习者的历史学习信息的具体方法为:
13.获取学习者的人脸彩色图像,并在人脸库中进行人脸搜索,若搜索到一致的人脸
彩色图像,则获取学习者编号,并基于学习者编号在数据库中进行遍历,得到学习者的历史学习信息;否则,在人脸库中添加学习者的人脸彩色图像,并初始化数据库中学习者的历史学习信息。
14.进一步地,所述获取学习者的人脸彩色图像的具体方法为:
15.获取学习者的彩色图像和深度图像;
16.基于学习者的彩色图像和深度图像,得到学习者的鼻子关节点和脖子关节点的三维位置;
17.将鼻子关节点和脖子关节点的三维位置映射到所述彩色图像,得到彩色图像中鼻子关节点和脖子关节点的二维位置;
18.基于彩色图像中鼻子关节点和脖子关节点的二维位置,计算人脸裁剪正方形的边长和裁剪原点;
19.基于所述边长和裁剪原点,在所述彩色图像裁剪出所述人脸彩色图像。
20.进一步地,若所述学习者的历史学习信息非空,在获取并播放学习视频之前还需要,基于学习者的历史学习信息,获取若干个练习题并依次进行推送。
21.进一步地,还包括:在所述获取并播放学习视频之后,基于所述学习视频的内容,获取若干个练习题并依次进行推送。
22.进一步地,在每个练习题推送后,获取学习者在三维空间的实际位置并转换为虚拟形象在显示设备中的位置,根据虚拟形象在显示设备中的位置,得到学习者的答案。
23.进一步地,还包括:所述虚拟形象在显示设备中的位置的获取方法为:
24.设定活动区域参数;
25.基于活动区域参数,将所述学习者在三维空间的实际位置转化为二维活动空间的相对位置,并将所述二维活动空间的相对位置映射为虚拟卡通形象在显示设备中的位置。
26.本发明的第二个方面提供一种实现动作识别的智能视频教学系统,其包括:
27.历史学习信息获取模块,其被配置为:获取学习者的历史学习信息;
28.学习视频播放模块,其被配置为:基于学习者的历史学习信息,获取并播放学习视频;
29.其中,在播放学习视频的过程中,实时获取学习者的身体关节点的位置,判断学习者肢体动作,基于学习者肢体动作控制所述学习视频的播放进度;同时,获取学习者的人脸彩色图像,基于学习者的人脸彩色图像,识别人脸彩色图像中的人脸关键点,基于人脸关键点计算左右眼睛闭合度均值和嘴部张角,基于人脸彩色图像计算头部转角,基于左右眼睛闭合度均值、嘴部张角和头部转角,更新视频播放内容。
30.本发明的第三个方面提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的一种实现动作识别的智能视频教学方法中的步骤。
31.本发明的第四个方面提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的一种实现动作识别的智能视频教学方法中的步骤。
32.与现有技术相比,本发明的有益效果是:
33.本发明提供了一种实现动作识别的智能视频教学方法,其能够监测学习者的动作,自主更新播放内容,有效缓解学生疲劳。
34.本发明提供了一种实现动作识别的智能视频教学方法,其使用走动、动作交互等常见的交互方式与学习内容进行交互,交互操作简单、自然,学习者不需要额外的训练,符合用户心理和习惯;受众广泛,面向大众群体,能够保证学习者主动学习的积极性和运动量。
35.本发明提供了一种实现动作识别的智能视频教学方法,其不受时间和地点的约束、关注学习者的个体特征和长期学习性,构建了适合不同人群需求的学习体系,实现了人人可学、处处能学、时时能学的新模式。
附图说明
36.构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
37.图1是本发明实施例一的一种实现动作识别的智能视频教学方法流程图;
38.图2是本发明实施例一的学习者鼻子和脖子关节点的示意图;
39.图3是本发明实施例一的利用运动与肢体方式对内容进行交互的方法流程图;
40.图4是本发明实施例一的人脸关键点示意图;
41.图5是本发明实施例一的数据库结构示意图。
具体实施方式
42.下面结合附图与实施例对本发明作进一步说明。
43.应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步地说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
44.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
45.实施例一
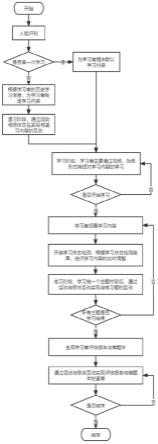
46.本实施例提供了一种实现动作识别的智能视频教学方法,如图1所示,包括以下步骤:
47.步骤1、获取学习者的人脸彩色图像,采用人脸识别算法在人脸库搜索学习者,若在人脸库中搜索到学习者,则获取学习者用户id,在系统数据库中获取学习者的历史学习信息(包括姓名、性别、年龄、学习时间、学习积分、学习进度、学习效率等),并上传至显示界面,呈现出来,此时显示界面显示学习者的人脸彩色图像,并显示学习者历史学习信息,包括姓名、年龄、上次学习时间等基本信息,呈现的方式可以是电脑显示器、大屏幕、投影显示等;否则,将学习者的人脸图像添加到人脸库中,并在数据库中添加学习者并初始化学习者的历史学习信息。
48.其中,利用rgb-d相机捕捉学习者的彩色图像和深度图像,计算人脸图像区域(人脸彩色图像),rgb-d相机采用微软kinect传感器。
49.如图5所示,数据库中主要有user表、class表、classhistory表、question表、
misans表。
50.其中,user表保存学习者的id、姓名、信息、年龄、上次登陆时间、学习天数、运动量、积分等信息。class表保存课程id、课程名、课程视频地址。classhistory表保存学习者学习课程的历史以及课程练习的分数、学习的时间。question表保存练习题的题目、练习题所属的课程、练习题的正确答案、练习题的选项。misans表保存学习者错题的信息,主要包括错题id、学习者的选项、做题时间等信息。
51.人脸识别后从人脸库中获取学习者id,根据学习者id到系统数据库中的user表中检索学习者的姓名、信息、年龄、上次登陆时间、学习天数、运动量、积分,根据学习者id到classhistory表中检索学习者的学习历史,根据学习者id到misans表中检索学习者的历史错题。
52.其中,获取学习者的人脸彩色图像,采用人脸识别算法在人脸库搜索学习者的具体步骤为:
53.步骤101、利用rgb-d相机,基于学习者的彩色图像和深度图像,获取学习者鼻子和脖子关节点的位置坐标,如图2所示,使用kinect传感器定位三维空间中学习者的鼻子关节点pnose_3d(nose_x_3d,nose_y_3d,nose_z_3d)、脖子关节点pneck_3d(neck_x_3d,neck_y_3d,neck_z_3d);
54.步骤102、将鼻子关节点和脖子关节点的三维位置映射到彩色图像,得到彩色图像中鼻子关节点和脖子关节点的二维位置,具体地,使用kinectbase.calibration.transformto2d()函数将关键点pnose(nose_x_3d,nose_y_3d,nose_z_3d)和关键点pneck(neck_x_3d,neck_y_3d,neck_z_3d)从三维空间映射到二维空间得到点pnose_2d(nose_x_2d,nose_y_2d)和点pneck_2d(neck_x_2d,neck_y_2d);
55.步骤103、计算人脸裁剪正方形的边长d,并计算裁剪原点p(px,py);
[0056][0057]
px=nose_x_2d-d
[0058]
py=nose_y_2d-d
[0059]
步骤104、基于边长和裁剪原点,在彩色图像裁剪出所述人脸彩色图像。即利用rgb-d相机捕获的彩色图,将彩色图以点p为原点,d为边长裁剪出正方形得到学习者人脸图像;
[0060]
步骤105、将裁剪得到的人脸图像进行编码,具体地,使用convert.tobase64string()函数将裁剪出的人脸图像编码成base64字符串;
[0061]
步骤106、将上述获取的人脸图像编码以字符串的形式作为参数,采用人脸识别算法在人脸库中进行人脸搜索;具体地,本发明使用百度人脸应用提供的search函数在人脸库中进行人脸搜索;
[0062]
步骤107、根据人脸识别结果,进行相应的操作,如果在人脸库中搜索到该学习者,则返回该学习者的编号id,通过学习者id在数据库中检索出该学习者的历史学习信息,包括姓名、年龄、信息、上次登陆时间、学习天数、运动量、积分、学习历史等;如果在人脸库中没有搜索到该学习者,则将该学习者的人脸图像添加到人脸库中,并在人脸库中添加该学习者的人脸彩色图像,并初始化数据库中学习者的历史学习信息,此时,学习者的历史学习
信息为空。
[0063]
步骤2、基于步骤1得到的学习者的学习信息,判断学习者是否是第一次进行学习,即判断学习者的历史学习信息是否为空;如果是第一次学习,则为学习者提供默认的学习内容(可以对学习者之前学习不足60分的课程进行复习,然后根据学习者复习题回答的情况对学习者进行课程推荐,如果学习者之前60分以下的课程复习仍然不足60分,此门课程会推荐给学习者继续进行复习),并跳转至步骤4;如果不是第一次学习,即学习者的历史学习信息非空,则根据学习者的历史学习信息,为学习者制定学习内容(可以按照课程的顺序,推荐前三节课给学习者学习),跳转至步骤3。本实例中,一次学习最多推荐两节复习课程,如果学习者超过两节课程的复习题不足60分则从中选取分数最低的两节推荐给学习者复习。
[0064]
步骤3、温习阶段,学习者在学习课程之前,通过运动与肢体交互的方式对之前所学内容进行复习(题型主要包括判断题、单选题、多选题等),并考察学生对所学内容的掌握情况。即,根据学习者的历史学习信息,获取若干个练习题并依次进行推送,对于每个练习题,获取学习者的实际位置,根据学习者的实际位置,判断学习者给出的答案是否正确,当学习者答完所有练习题后,跳转至步骤4。
[0065]
其中,如图3所示,获取学习者的实际位置,根据学习者的实际位置,判断学习者给出的答案是否正确的具体方法是:
[0066]
(1)初始化阶段,标记rgb-d相机的捕获区域,即学习者的有效活动区域,本发明以微软kinect传感器为例进行说明。设定活动区域参数(area_height、area_width、d1、d2),具体地,在kinect传感器前方标记长为area_height、宽为area_width的学习者活动区域,确定活动区域距离kinect传感器的距离d1,活动区域中心距离kinect的水平偏移d2,此外,显示设备的分辨率为screen_height*screen_width。
[0067]
(2)利用kinect获取学习者在三维空间的实际位置preal(x_real,y_real,z_real),将其转化为二维活动空间的相对位置prelative(x_relative,y_relative):
[0068]
x_relative=d2 area_width/2-x_real
[0069]
y_relative=z_real-d1
[0070]
(3)将二维活动空间相对位置prelative(x_relative,y_relative)映射为虚拟形象在显示设备中的位置pscreen(x_screen,y_screen),其中:
[0071]
x_screen=x_relatie/area_width*screen_width
[0072]
y_screen=y_relative/area_height*screen_height
[0073]
(4)使用虚拟卡通形象来表示学习者,将虚拟卡通形象在显示设备中的坐标设置为pscreen(x_screen,y_screen),从而将学习者的运动位置实时转换为学习内容中虚拟形象的运动位置,实现学习者与学习内容的互动。
[0074]
(5)判断学习者答题是否正确:通过pscreen的位置与数据库中答案信息进行比对,具体的,根据虚拟形象在显示设备中的位置,得到学习者的答案,将学习者的答案与数据库中存储的标准答案进行对比,如果回答正确,则给出声音、图像提示,并增加学习者积分;否则,给出错误的答题声音和图像提示,并给出正确答案,同时将错题信息记录到学习者数据库的错题本中,保证后续进行复习与巩固。
[0075]
步骤4、学习阶段,学习者主要通过视频、动画等形式对学习内容进行学习。即,基
于学习者的学习信息,推送学习视频。
[0076]
步骤5、判断学习者是否开始学习,如果开始学习,则播放学习视频,学习者观看学习视频;否则,不播放学习视频。在课程学习过程中学习者可以控制教学视频的播放与暂停,控制教学视频的音量,控制教学视频的播放进度,对某一知识点反复进行学习,加强理解。在播放学习视频的过程中,实时获取体关节点的位置,判断学习者肢体动作,基于学习者肢体动作控制所述学习视频的播放进度,具体的,利用学习者肢体进行交互主要包括在视频学习过程中学习者可以控制视频播放与暂停,即当学习者举起右手时播放视频,当举起左手时暂停视频,当学习者右手向右伸平时视频快进,当学习者左手向左伸平时视频后退。即,使用kinect得到学习者的身体关节点的位置,通过对关节点的相对位置进行判断完成肢体动作的定义:
[0077]
右手举起动作:如果右手关节点hand_right的y坐标小于右肩膀坐标shoulder_right的y坐标,此时学习者的右手是举起的状态;
[0078]
左手举起动作:如果左手关节点hand_left的y坐标小于左肩膀坐标shoulder_left的y坐标,此时学习者的左手是举起的状态;
[0079]
右手伸平动作:如果右手关节点hand_right的x坐标小于右肩膀shoulder_right的x坐标并且右手关节点hand_right的y坐标在右肩膀shoulder_right和脊椎中心spine_naval的y坐标之间,此时学习者右手是伸平的状态;
[0080]
左手伸平动作:如果左手关节点hand_left的x坐标大于左肩膀shoulder_left的x坐标并且左手关节点hand_left的y坐标在左肩膀shoulder_left和脊椎中心spine_naval的y坐标之间,此时学习者左手是伸平的状态;
[0081]
步骤6、获取学习者的人脸彩色图像,基于学习者的人脸彩色图像,识别人脸彩色图像中的人脸关键点,基于人脸关键点计算左右眼睛闭合度均值和嘴部张角,基于人脸彩色图像计算头部转角,基于左右眼睛闭合度均值、嘴部张角和头部转角,更新视频播放内容。
[0082]
例如,首次检测到学习者左右眼睛闭合度均值ear小于阈值、或者嘴部张角大于阈值、或者头部转角大于阈值,更新视频播放内容,例如,对学习者进行视频放松,通过美丽的自然风景和舒缓的音乐来使学习者放松,放松结束后继续进行课程学习;继续学习过程中,如果学习者再次出现左右眼睛闭合度均值ear小于阈值、或者嘴部张角大于阈值、或者头部转角大于阈值时,可以再次更新视频播放内容,例如,播放体操或者在屏幕上会随机在4个位置出现地鼠图标,学习者通过自身移动来驱动屏幕上的虚拟形象来击打地鼠,打中则积分加10分,没有被打到的地鼠会在出现5秒钟后消失,当学习者积分达到100分时,放松结束,学习者继续进行课程学习。
[0083]
其中,识别人脸彩色图像中的人脸关键点,基于人脸关键点计算左右眼睛闭合度均值和嘴部张角,基于人脸彩色图像计算头部转角的具体方法为:
[0084]
步骤601、使用kinect获取连续的彩色图像与深度图像序列,在彩色图像中截取学习者的人脸彩色图像。其中,获取学习者的人脸彩色图像与步骤101-104相同。
[0085]
步骤602、使用人脸识别算法进行人脸关键点定位,获取人脸关键点,如图4所示,本发明使用的是百度人脸api。
[0086]
步骤603、获取右眼上下眼睑关键点eye_right_upper(x32,y32)、eye_right_
lower(x36,y36),右眼左右眼角关键点eye_right_corner_left(x30,y30)、eye_right_corner_right(x34,y34);获取左眼上下眼睑关键点eye_left_upper(x15,y15)、eye_left_lower(x19,y19),左眼左右眼角关键点eye_left_corner_left(x13,y13)、eye_left_corner_right(x17,y17)。
[0087]
步骤604、计算左右眼闭合度ear_left、ear_right,其中:
[0088][0089][0090]
步骤605、计算左右眼睛闭合度均值ear:
[0091]
ear=(ear_left ear_right)/2
[0092]
当ear值小于阈值时,眼睛为闭合状态,则学习者可能处于疲劳状态;根据经验值,本发明中阈值设置为0.2。
[0093]
步骤606、获取左嘴角关键点mouse_corner_left_outter(x58,y58),上嘴角关键点mouse_lip_upper_outer(x60,y60),下嘴角关键点mouse_lip_lower_outer(x64,y64)。
[0094]
步骤607、计算得向量v1,v2,其中:
[0095]
v1=(x60-x58,y60-y58)
[0096]
v2=(x64-x58,y64-y58)
[0097]
步骤608、计算向量v1、v2的夹角θ,即为嘴部张角:
[0098]
θ=arccos(v1
·
v2/(||v1||
×
||v2||))
[0099]
如果θ大于阈值,则表明学习者可能正在打哈欠,即学习者处于疲劳状态。根据经验值,本发明中阈值设置为60
°
。
[0100]
步骤609、把获取的人脸彩色图像使用人脸识别算法(如百度人脸api)进行图像分析,获取头部在x、y、z方向上的转角pitch、yaw、roll。本发明主要利用了yaw角的变化来判断,即如果yaw角大于60
°
或小于-60
°
,表明学习者此时可能注意力不集中,处于分心状态。
[0101]
步骤610、本发明以20s为一个状态判断周期,采集彩色图像与深度图像。
[0102]
作为一种实施方式,如果学习者在一个周期内处于分心的帧数超过50%,则学习者此时学习状态较差,需对学习者进行状态调节。
[0103]
步骤7、练习阶段,在获取并播放学习视频之后,基于学习视频的内容,获取若干个练习题并依次进行推送,即学习者学习完一个主题内容后,配套进行练习题的训练。通过学习者运动与肢体互动的方式实现对练习题的解答,具体方式与步骤3中相同。
[0104]
具体的,针对学习的课程推送对应的练习题给学习者练习,巩固所学课程。学习者阅读完题目后通过自身在物理空间的移动驱动屏幕上的虚拟形象来选择答案;如果选择了正确的答案,提示回答正确,同时积分加1;如果选择了错误的答案,提示学习者回答错误并提示正确答案;学习者在移动时,不断计算学习者当前位置与上一时刻学习者位置之间的距离,对学习者的运动量进行统计。
[0105]
步骤8、判断系统制定的学习内容是否学习结束,如果还未学习完,则跳转步骤5;否则,生成学习者本次的学习评估报告,以及错题本。
[0106]
评估报告会显示学习者的基本信息、学习的积分、本次学习过程中的运动量、学习的总运动量、专注程度、已经学习的课程及掌握程度。其中,本发明中专注程度指的是学习
者专注时间在总学习时间中的占比,学习课程的掌握程度是根据学习者每一节课练习题的作答情况分析得出。在评估报告界面学习者可以通过自身的移动驱动屏幕上的虚拟形象来点击退出程序按钮回退到开始界面,继续进行学习。学习者还可以用肢体运动打开错题本按钮打开错题本,对本次学习过程中做错的练习题进行加强学习。错题本中会显示原题目的问题和选项,正确答案以及学习者当时做出的选择,供学习者进行错题分析。学习者选择上一题和下一题按钮来切换题目。点击返回报告按钮可以回退到评估报告页面。点击退出程序按钮可以跳转到开始界面继续进行学习。
[0107]
步骤9、学习者可通过运动与肢体交互实现评估报告和错题本的查看。
[0108]
步骤10、判断查看是否结束,如果结束,则本次学习结束;否则,跳转步骤9。
[0109]
本发明根据当前学习者的历史学习信息,为学习者制定温习、学习、练习的相应内容。学习者根据制定的学习路径,进行不同阶段的学习。在温习和练习阶段,获取学习者的彩色图像和深度图像,进行位置跟踪和动作识别,实现与内容的互动;在学习阶段,获取学习者的彩色图像,进行学习者学习状态的检测,检测学习者是否长时间处于东张西望、犯困、打哈欠等学习不佳的状态,根据检测结果,实时调整学习者当前的内容,包括不同难度学习内容的调整、调动学习者学习积极性或放松内容等形式的引入。在评价阶段,学习者对推荐的学习内容学习结束,根据学习者学习过程中的学习状态、温习和练习阶段的互动率与答题准确率等,给出学习者对应的学习报告。
[0110]
本发明考虑到不同学习者的个体差异、学习时间差异及有限性,关注学习者的个体特征和长期学习性,提供个性化、自适应的学习内容,构建适合不同人群需求的学习方法。本发明提供了一种温习、学习、练习和评价的自主学习方式,通过对学习者进行人脸识别获取学习者的已学习知识,并根据已学习知识和学习效果为学习者制定个性化的学习内容。同时,时刻关注学习者的学习状态(如东张西望、犯困、打哈欠等),根据学习状态的不同,进行对应的内容调整,保证学习者的学习效率;支持学习者通过走动、手势交互的方式实现与内容的互动,保证学习者主动学习积极性。
[0111]
实施例二
[0112]
本实施例提供了一种实现动作识别的智能视频教学系统,其具体包括如下模块:
[0113]
历史学习信息获取模块,其被配置为:获取学习者的历史学习信息;
[0114]
学习视频播放模块,其被配置为:基于学习者的历史学习信息,获取并播放学习视频;
[0115]
其中,在播放学习视频的过程中,基于状态判断周期,获取学习者的人脸彩色图像,识别人脸彩色图像中的人脸关键点,基于人脸关键点计算左右眼睛闭合度均值和嘴部张角,基于左右眼睛闭合度均值和嘴部张角判断学习者是否处于疲劳状态;同时,捕获学习者的头部关键点,计算头部转角来判断学习者是否处于分心状态。
[0116]
此处需要说明的是,本实施例中的各个模块与实施例一中的各个步骤一一对应,其具体实施过程相同,此处不再累述。
[0117]
实施例三
[0118]
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的一种实现动作识别的智能视频教学方法中的步骤。
[0119]
实施例四
[0120]
本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的一种实现动作识别的智能视频教学方法中的步骤。
[0121]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
[0122]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0123]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0124]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0125]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random accessmemory,ram)等。
[0126]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。