一种基于xgboost的水文预报误差校正方法
技术领域
1.本发明涉及水文模型预报误差校正技术,具体涉及一种基于xgboost的水文预报误差校正方法。
背景技术:
2.洪水预报作为流域抗洪减灾的重要技术,是最重要的防洪非工程措施之一,担负着防汛工作中的“耳目”、“参谋”与“尖兵”。实时洪水预报就是为了预测未来将要发生的洪水信息,以当前阶段观测得到的最新降雨等水文要素为输入,选择适合的水文预报模型进行预报计算,对未来洪水水位或流量进行预测的过程。洪水预报不仅有助于降低洪水风险,而且对水资源系统的统一规划管理起到显著作用。预见期越长、预报误差越低、对环境的适应程度越高且滚动预报能力越强的实时洪水预报越有可能做出科学合理的防洪决策,为减免洪涝损失和保障社会经济效益提供重要支撑。
3.洪水预报过程由模型输入、模型结构及参数、状态变量初值和测量等诸多环节组成,产生于这些环节的误差,逐步累积使得最终的预报结果与实际观测值有所偏差,进而影响洪水预报的精度。为了提高实时洪水预报准确性,为防洪抗洪提供更为可靠的科学支撑,就需要在使用水文模型进行水文预报的基础上开展实时误差校正研究。
4.目前,根据预报误差特点,洪水预报实时校正的技术与方法,大体上可以归纳为两类:一是终端误差校正方法,二是过程误差校正方法。终端误差校正即不考虑预报子过程的误差以及误差在子过程中的传播,直接对最终预测的水位或流量的误差进行校正。过程误差校正即通过降低预报过程中各子过程(如降雨、汇流、产流等)的误差,通常是对预报模型的状态变量或参数变量等进行误差校正,从而达到降低最终误差的目的。
5.近年来,随着机器学习的发展,其在水文领域的应用也越来越广泛。机器学习技术不仅可以应用于水文预报,建立基于数据驱动的预报模型,也能进行预报结果的校正。如:结合小波分析的arima修正预测模型、结合相似性搜索的改进正则化gru模型、基于k均值聚类分析的实时分类修正方法等,上述误差修正方法也都取得了较好的效果,但同时也存在一些问题:多数方法割裂了模型预测时会产生误差的连续影响,因此需要寻找一种效率与误差修正率兼顾的预测模型。
技术实现要素:
6.发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于xgboost的水文预报误差校正方法,通过数据挖掘的相关技术,对已有的预报值误差序列进行分析和预测研究。
7.技术方案:本发明的一种基于xgboost的水文预报误差校正方法,包括以下步骤。
8.步骤s1、采集一水系流域对应预报站点一定时间段内的实况水位值及使用相关水文模型预报后的预报水位值,按照对应时间点组织成水文时间序列数据集;
9.步骤s2、对数据进行预处理,依据预报值、实况值和对应时间形成误差数据集,将
其进一步划分为训练集和测试集并确定模型最终的输入;
10.步骤s3、采用混合遗传优化算法(spga)对xgboost的学习率lr、弱学习器个数n_estimators、惩罚项系数gamma、决策树最大深度max_depth这四项超参进行优化,同时利用样本数据集对xgboost模型进行训练,最终得到spga优化的xgboost预报误差校正模型;
11.步骤s4、对所述spga优化的xgboost预报误差校正模型进行测试。
12.本发明还公开了一种基于xgboost的水文预报误差校正方法,依次包括以下步骤。
13.所述步骤s1是获取初始数据集和相应的标签信息,所述步骤s1进一步为:采集一水系流域对应预报站点一定时间段内的实况水位值及使用相关水文模型预报后的预报水位值,按照对应时问点组织成水文时间序列数据集。初始水文时间序列数据集共有两个,其中一个包括该水系流域对应预报站点的实况水位值、实况流量值及对应的时间;另一个包括预报依据时间、预报时间及预报水位值。
14.所述步骤s2是对数据进行预处理,依据预报值、实况值和对应时间形成样本数据集,将其进一步划分为训练集和测试集并确定模型最终的输入,所述步骤s2进一步为:
15.步骤s2.1、将步骤s1中的两组数据集中的数据进行缺失值处理、错误值更正,并根据模型构建所需重新构建样本数据集,该数据集包含:预报依据时间、预报时间、预报水位值、实况水位值及对应的误差值,误差数据集整理完毕后对其进行归一化处理,采用的归一化公式如下:
[0016][0017]
其中,x(t)是样本数据,n(t)为输入样本;
[0018]
步骤s2.2、将误差数据集划分为训练数据集l和测试数据集t的方法为:样本数据集的前70%作为训练数据集l,余下的30%数据作为测试数据集t;
[0019]
步骤s2.3、设为第n次实时预报预见期j的预报误差,tn为第n次实时预报的预报时间;误差序列长度经逐步回归确定为用前3次水文预报得到的误差序列来预测预见期j的水文预报值的误差。
[0020]
xgboost模型有众多参数,更优的参数能提高序列预测的精度,因此采用spga算法对xgboost模型的学习率lr、弱学习器个数n_estimators、惩罚项系数gamma、决策树最大深度max_depth这四项超参进行优化,所属步骤s3具体包括:
[0021]
步骤s3.1、初始化xgboost模型的学习率lr、弱学习器个数n_estimators、惩罚项系数gamma、决策树最大深度max_depth参数的取值范围;
[0022]
步骤s3.2、初始化m个子群,每个子群中粒子的染色体就相当于一组xgboost的参数(lr,n_estimators,gamma,max_depth),初始化spga算法中最大迭代次数t
max
、变异概率、交叉概率、惯性权重ω、学习因子c1、c2及模拟退火初始温度t;
[0023]
步骤s3.3、对一组参数进行编码并进行计算个体适应度值,即xgboost模型的均方根误差rmse,根据适应度值继续对种群进行筛选;
[0024]
步骤s3.4、判断是否满足终止条件,若达到最大迭代次数t
max
则终止迭代并用该适应度值最佳的最优解作为模型参数进行xgboost误差校正模型的建立,否则进入步骤s3.5;
[0025]
步骤s3.5、对个体进行解码,把解码参数代入训练与测试样本,计算得到每个个体
的适应度值;
[0026]
步骤s3.6、更新种群最优个体和历史最优个体,分别用一个变量把每个个体的当前解码后的值保留下来,把每一代的最优解也用单独的变量保留下来,从第二代迭代开始,如果产生的新个体的适应度值比前一次保留的个体的适应度值大,则把新个体存储在变量中并替换前一代的个体,否则不替换,同样地,如果这一代的历史最优个体适应度值比前一代的大,则更新每一代的最优解,否则不更新;
[0027]
步骤s3.7、用赌轮盘算法进行选择,即按照适应度值对应的选择概率进行随机选取,直到选出满足设定数量的个体数;
[0028]
步骤s3.8、种群交叉;然后进行变异,在变异之前要先解码,在变异完成之后再重新编码;
[0029]
其中,粒子变异过程引入pso公式作为变异算子,让种群内个体可以根据自身迄今最优解和种群内最优解以及个体进化的速度来确定变异的方向和幅度,使变异操作具有方向指导作用,不再是简单的随机变异。变异的具体操作是:用代替粒子群中的第i个粒子在d维空间的位置x
id
,用历史最优个体代替粒子群算法中的个体最佳位置pbest
id
;用种群最优代替全局最优位置gbest
id
;用的累计差的算数平均来代替v
id
,其中的累计差由下式求得:
[0030][0031]
引入的粒子群算法的粒子更新公式为:
[0032][0033]
其中第一部分通过权重因子c1,c2和随机数r1,r2以及信息反馈预测了变异的幅度和方向;第二部分则具体实施了变异操作。
[0034]
步骤s3.9、判断是否满足模拟退火的sa判断函数,若满足,则说明种群进化到了后期趋于同一,进行模拟退火操作,否则直接转步骤s3.4、。
[0035]
引入的sa判断函数具体为:
[0036]fave-f
min
<a
[0037]
通过该式来判断是否执行sa操作。其中f
ave
表示种群中平均适应度值,f
min
表示种群中最优个体所对应的适应度值,a为判断种群趋于稳定时的阈值a。
[0038]
所述步骤s4中的xgboost是一个树集成模型,内部的决策树使用的是回归树,所述步骤s4进一步为:
[0039]
xgboost可以自定义模型的损失函数:
[0040][0041]
其中,为损失函数,度量预测值与实际值yi之间的差距;k表示模型中包含
的决策树个数;为正则项,式中γ为分割叶子节点的收益函数的惩罚常数,t为叶子节点个数,λ为l2正则项惩罚函数系数。
[0042]
第t轮模型即第i个样本在第t次训练中的预测值为:
[0043][0044]
第t次训练模型的简化的目标函数为:
[0045][0046]
式中,为损失函数的一阶导数,为损失函数的二阶导数。
[0047]
有益效果:本发明提供的一种基于xgboost的水文预报误差校正方法,与现有方法相比,本发明的优点在于:本发明采用spga优化算法对xgboost模型的参数进行优化,避免了在寻找最优参数时会陷入局部最优的情况,利用最优参数得到的模型进行模拟误差计算,有更好的校正效果。并且能在保证误差校正能力基础上,具有更高的收敛速度,对于大规模的训练样本,计算速度也有一定的提升。
附图说明
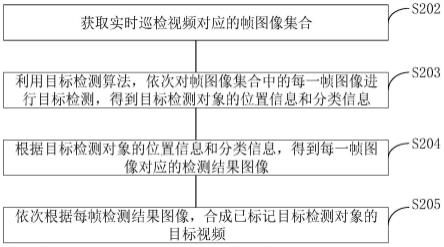
[0048]
图1为本发明实施例里的整体步骤图;
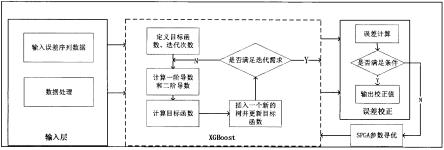
[0049]
图2为本发明具体示例spga优化方法的流程图;
[0050]
图3为实施例中预见期6h时使用xgboost模型对预测值校正前后的对比展示图;
[0051]
图4为实施例中spga、ga、pso、cs优化算法的适应度值变化曲线对比图。
具体实施方式
[0052]
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0053]
如图1所示,发明的一种基于xgboost的水文预报误差校正方法,主要包括4个步骤:
[0054]
步骤s1、采集一水系流域对应预报站点一定时间段内的实况水位值及使用相关水文模型预报后的预报水位值,按照对应时间点组织成水文时间序列数据集;
[0055]
步骤s1.1、选取螺山实况水位数据组织成水文时间序列数据集data_1,时间从2018年1月1日8点到2020年12月31日8点,共1096条数据,该数据集包括时间、水位值、流量值。再根据相同时间点截取通过大湖演算模型得到的预报值组织成水文时间序列数据集data_2,该数据集包括预报依据时间、预报时间、预报水位值。
[0056]
步骤s2、对数据进行预处理,依据预报值、实况值和对应时间形成误差数据集,将具进一步划分为训练集和测试集并确定模型最终的输入,具体步骤如下:
[0057]
步骤s2.1、将步骤s1中的两组数据集中的数据进行缺失值处理、错误值更正,并根据模型构建所需重新构建样本数据集,该数据集包含:预报依据时间、预报时间、预报水位值、实况水位值及对应的误差值。误差数据集整理完毕后对其进行归一化处理,采用的归一
化公式如下:
[0058][0059]
其中,x(t)是样本数据,n(t)为输入样本。
[0060]
步骤s2.2、将样本数据集划分为训练数据集l和测试数据集t的方法为:样本数据集的约前70%共767条数据作为训练数据集l,余下的30%数据共329条作为测试数据集t。
[0061]
步骤s2.3、重新构建好的误差数据集中均为预见期为6h的数据,误差序列长度经逐步回归确定为用前3次水文预报得到的误差序列来预测预见期j的水文预报值的误差。
[0062]
步骤s3、采用spga优化算法对xgboost的学习率lr、弱学习器个数n_estimators、惩罚项系数gamma、决策树最大深度max_depth这四项超参进行优化,同时利用样本数据集对xgboost模型进行训练,最终得到spga优化的xgboost预报误差校正模型,使用spga对xgboost模型的参数进行寻优,具体流程如图2所示,具体步骤为;
[0063]
步骤s3.1、初始化xgboost模型的学习率lr、弱学习器个数n_estimators、惩罚项系数gamma、决策树最大深度max_depth参数的取值范围,设置1r范围是(0.01,0.4),n_estimators范围是(10,220),gamma范围是(3,10),max_depth范围是(0,0.2)。
[0064]
步骤s3.2、初始化m=50个子群,每个子群中粒子的染色体就相当于一组xgboost的参数(lr,n_estimators,gamma,max_depth),初始化spga遗传算法中最大迭代次数t
max
=50、ω=0.5、c1=0.2、c2=0.5,基本ga中变异概率为0.05,交叉概率为0.8,以及模拟退火初始温度t=100,;
[0065]
步骤s3.3、对一组参数进行编码并进行计算个体适应度值,即xgboost模型的均方根误差rmse,根据适应度值继续对种群进行筛选;
[0066]
步骤s3.4、判断是否满足终止条件,若达到最大迭代次数t
max
则终止迭代并用该适应度值最佳的最优解作为模型参数进行xgboost误差校正模型的建立,否则进入s3.5;
[0067]
步骤s3.5、对个体进行解码,把解码参数代入训练与测试样本,计算得到每个个体的适应度值;
[0068]
步骤s3.6、更新种群最优个体和历史最优个体。分别用一个变量把每个个体的当前解码后的值保留下来,把每一代的最优解也用单独的变量保留下来。从第二代迭代开始,如果产生的新个体的适应度值比前一次保留的个体的适应度值大,则把新个体存储在变量中并替换前一代的个体,否则不替换。同样地,如果这一代的历史最优个体适应度值比前一代的大,则更新每一代的最优解,否则不更新;
[0069]
步骤s3.7、用赌轮盘算法进行选择,即按照适应度值对应的选择概率进行随机选取,直到选出满足设定数量的个体数;
[0070]
步骤s3.8、种群交叉;然后进行变异。在变异之前要先解码,在变异完成之后再重新编码;
[0071]
变异的具体操作是:用代替粒子群中的第i个粒子在d维空间的位置x
id
,用历史最优个体代替粒子群算法中的个体最佳位置pbest
id
;用种群最优代替全局最优位置gbest
id
;用的累计差的算数平均来代替v
id
,其中的累计差由下式求得:
[0072][0073]
引入的粒子群算法的粒子更新公式为:
[0074][0075]
其中第一部分通过权重因子c1,c2和随机数r1,r2以及信息反馈预测了变异的幅度和方向;第二部分则具体实施了变异操作。
[0076]
步骤s3.9、判断是否满足模拟退火的sa判断函数,若满足,则说明种群进化到了后期趋于同一,进行模拟退火操作,否则直接转s3.4;
[0077]
引入的sa判断函数具体为:
[0078]fave-f
min
<a
[0079]
通过该式来判断是否执行sa操作。其中f
ave
表示种群中平均适应度值,f
min
表示种群中最优个体所对应的适应度值,a为判断种群趋于稳定时的阈值a。
[0080]
步骤s4、对所述spga优化的xgboost预报误差校正模型进行测试。
[0081]
设spga优化的xgboost水文时间序列预测模型的损失函数如下:
[0082][0083]
其中,为损失函数,度量预测值与实际值yi之间的差距;k表示模型中包含的决策树个数;为正则项,式中γ为分割叶子节点的收益函数的惩罚常数,m为叶子节点个数,λ为l2正则项惩罚函数系数;
[0084]
第j轮模型即第i个样本在第j次训练中的预测值为:
[0085][0086]
第j次训练模型的简化的目标函数为:
[0087][0088]
式中,为损失函数的一阶导数,为损失函数的二阶导数。
[0089]
本实施例中,经spga优化算法优化过参数的xgboost模型在预见期为6h时最佳参数为:lr=0.446、n_estimators=122、gamma=0.014、max_depth=4;
[0090]
使用该最优模型对螺山的预测水位值产生的误差进行预测,从而达到校正目的。将螺山的实况水位、大湖演算模型得到的预报值及校正后的预报值三者进行对比,最终的对比结果如下图3所示,对预测结果的评价指标采用rmse,r2两种,计算公式如下:
[0091]
[0092][0093]
式中,yi为实测值,为预报值,为平均值,n为样本个数。
[0094]
下表展示预见期为6h时校正前后结果评价指标的对比。
[0095] rmser2校正前预报值0.4490.9895校正后预报值0.1060.9994
[0096]
图3展示使用xgboost模型对预测值校正前后的对比图,预见期为6h,图4展示spga优化算法在预见期为6h的适应度值变化曲线,与ga、pso和cs进行对比。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。